Persistence Context
1차캐시에 객체가 관리가 될때 키와 실제 메모리(번지수) value가 저장된다.
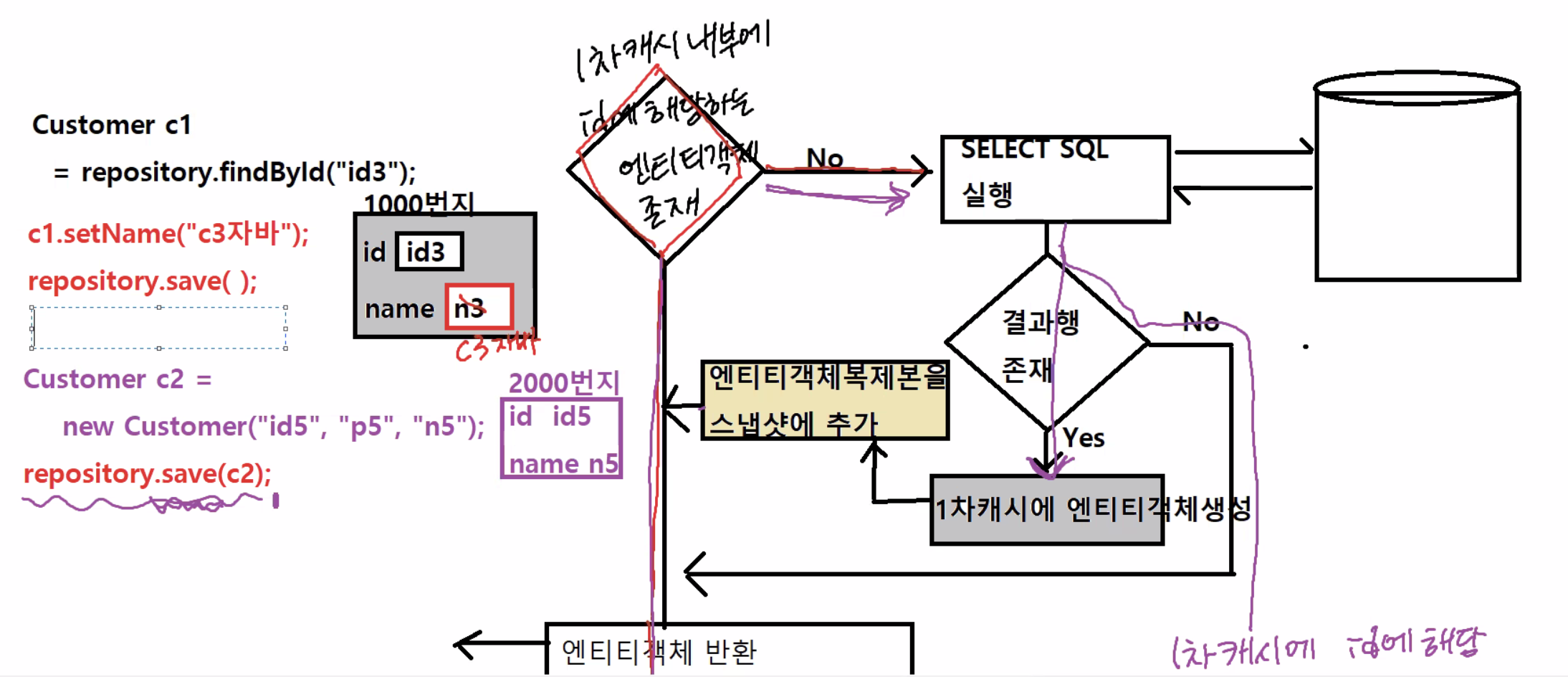
1.Customer c1 = repository.findById("id3");
- select에 해당하는 존재하면 결과행이 존재하면 1차캐시에 엔티티 객체를 생성하고, 엔티티 객체를 그대로 복제해서 스냅샷에 추가함. (persistence context 외부에는 객체가 만들어지지 않음, 내부에서만 작동)
결과행이 존재하지 않으면 null 반환
➡︎ 엔티티 객체를 반환.
c1.setName("c3자바");,repository.save();
- id에 해당하는 객체를 존재 확인 다시함(select) -> 만들어져있으니
-> 존재하면 entity 객체의 내용과 스냅샷의 내용을 비교함.
-> 같을 경우 아무일도 일어나지 않음
-> 하지만 setName으로 값을 바꿔버렸으니 두개의 값은 다를것임.
-> SQL저장소에 UPDATE SQL저장
-> 1차캐시의 값만 변경, 엔티티의 값은 변경 없음
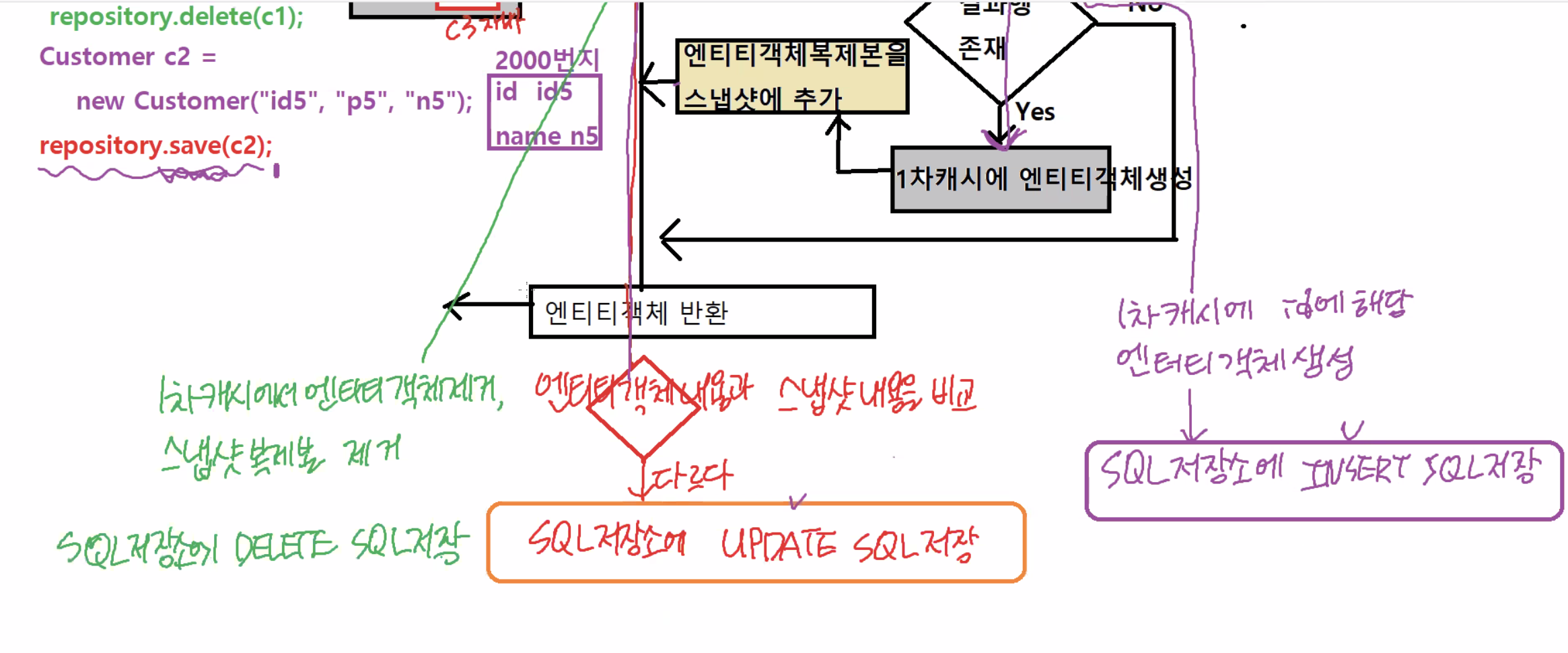
Customer c2 = new Customer("id5", "p5", "n5");
repository.save(c2)
-
1차캐시에 존재하는지 확인
-> 엔티티객체 존재하지 않음
-> SELECT 구문 -> 결과행 존재 X -> 1차캐시의 id에 해당하는 엔티티객체 생성
-> SQL저장소에INSERTSQL 저장 -
save()를 했을 때 엔티티객체내용과 스냅샷의 내용이 같을 경우 아무 작업도 하지 않는다.
repository.delete(c1);
- 1차캐시에 존재하는지 여부 확인
-> 없으면 아무작업도 하지 않음.
-> 있으면 1차캐시에서 제거하고 스냅샷의 복제본도 제거하고 SQL저장소에 delete sql문도 저장함
- findBy 하고 save()하는 경우가 있고,
find안하고 save하면 1차캐시에 엔티티가 없을 경우가 높음
-> 경우에 따라 insert를 할 수도 update를 할 수도 있음 - delete메서드를 호출하기 위해서는 반드시 find를 먼저 해야한다.
-> 아니면 아무작업도 일어나지 않음 - save로 업데이트 작업을 하기 위해서도 find를 먼저 해야한다.
-> 그래야 update구문 생김
-> 안하면 insert작업을 하려고 할 것임! - commit()을 하지않으면 아무리 save()를 하더라도 DB에 변경사항이 전달되지 않음
- spring data jpa에서 save나 delete를 호출하면 자동 commit되게 돼있기 때문에 우리가 해줄 필요가 없던 것!
- 왜 한꺼번에 커밋, 롤백을 해야하는가?
- 독립적인객체가 아니라 has-a관계를 맺고있는 객체라고 가정했을 때,
엔티티객체에 has-a로 여러개의 관계를 가지고 있을텐데, 엔티티 객체들의 어느부분이라도 set으로 값을 변경해서 그때그때마다 commmit하게 되면 롤백을 할수도 없고 퍼포먼스도 떨어진다. - 엔티티객체단위로 커밋,롤백하기 위해서는 SQL 저장소가 마련돼서 엔티티객체에서 이루어지는 작업들이 쌓여있다가 한꺼번에 처리돼야한다.
- 독립적인객체가 아니라 has-a관계를 맺고있는 객체라고 가정했을 때,

백엔드를 공부하고 있습니다.