S3서버에 이미지 업로드하기

오픈그래프를 위한 Post의 이미지를 수동으로 S3서버에 넣어보자.🧐
S3서버에 이미지 업로드하기
❓ 문제상황 : A 페이지의 여러 posts들을 카톡 등으로 공유할 때 meta data 이미지가 뜨지 않는 문제
❗️ 원인 : 이미지 서버에 각 post의 오픈그래프 이미지가 없기 때문이었다.
✍️ 정리
- 프론트 코드에서 Dynamic Open Graph를 생성하고, meta 태그에서 해당 페이지의 각 post 오픈그래프 데이터를 입력해줄 수 있도록 한다.
형태는 아래와 같다.https://d29p1x0xwubx6w.cloudfront.net/thumbnail/는 이미지 서버의 폴더 경로 이며, 이미지의 이름과.jpg를 붙여서 가져올 전체경로를 입력시킨다.
{ property: 'og:image',
content: 'https://seul.cloudfront.net/thumbnail/' + pid + '.jpg'}-
A 페이지의 개발자도구 elements탭에서
head태그의meta태그에서 이미지 주소를 GET요청 해보면 (url입력창에서 GET 요청) 해당 이미지가 없다는 것을 알 수 있었다. -
이것은 이미지서버에서 위에서 정의한 경로에 해당 데이터를 가지고있지 않기 때문이다. 🧐
-
따라서 클라이언트에서 정의한 이미지의 경로에 맞도록 AWS의 S3에서 정확한 위치에 정확한 이름의 경로를 생성해야한다. → 즉 이미지를 넣어줘야한다.
👉 해결과정
-
우선 프론트 코드에서 meta 태그에 이미지 주소가 잘 나오는지 확인한다. url주소창에 검색을 했을때 이미지가 제대로 뜨지 않을 경우, 이미지 서버에 해당 데이터가 없다는 뜻이다.

-
이 url주소를 참고해서 AWS 서버에 들어가서 확인해보자
AWS / S3 / seul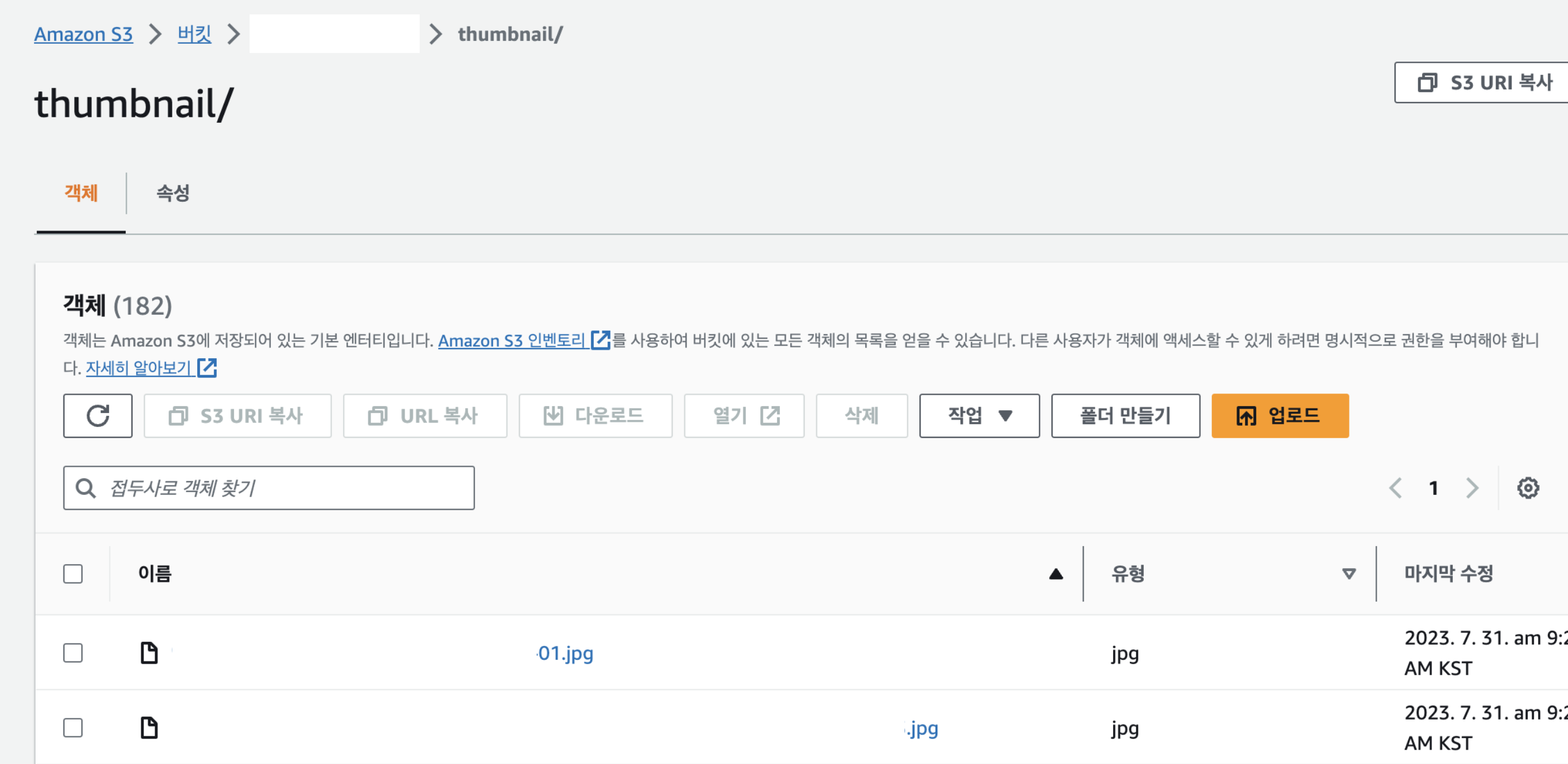
/ thumbnail 폴더 안을 살펴보면 여러 이미지 파일이 있는 것을 알 수 있고 여기에 해당 데이터명 pid.jpg 이미지가 없는 것을 알 수 있다. -
업로드 버튼을 눌러서 해당 jpg 이미지파일을 드래그앤드랍으로 업로드 해준다.
❓해당 jpg 이미지파일은 어디서 가져올까?
API에서 데이터를 가져와 이미지 파일을 로컬에 저장하는 작업을 수행하는 코드를 작성한다. (더 고도화 해서 자동으로 업로드 하도록 만들 수도 있다고 한다.)
python code👇
import io
import requests
import string
res = requests.get("https://api.seul.com/api/Apage?per_page=200")
data = res.json()
thumbnails = list(map(lambda x: {'url': x['img_url'], 'slug': x['link']}, data['data']['_postList']))
print(len(thumbnails))
try:
for thumbnail in thumbnails:
# Download Image
response = requests.get(thumbnail['url'])
image_content = response.content
filename = thumbnail['slug'] + '.jpg'
with open(filename, 'wb') as f:
f.write(image_content)
print(filename)
except:
print("Error: ", filename)이 제목을 기반으로 tumbnail url 이미지 컨텐츠를 저장을 한다. (따라서 지금 실행시키는 위치의 폴더안에 이미지 컨텐츠가 수많이 저장이 될것이다.
requests.get 함수를 사용하여 API에서 데이터를 요청한다. 이때 더 적어도 상관없지만 200개 가져와보기로 하자.
data의 postList를 map으로 돌려서 그 안의 imgurl 을 url 변수명으로 바꿔서, link 는 slug 로 바꿔서 리스트에 저장한다.
❗️주의할점
특정 상황에서 이 이미지 링크(…seul.net…)로 들어갔을 때 이미지가 안보이고 다운로드가 되는 경우가 있다.
jpg파일은 자동으로 타입을 이미지로 잡는다. 즉 파일의 타입이 이미지로 되어있기 때문에 문제 없지만, 만약 타입이 이미지가 아닐 경우에는 다운로드된다. (알 수 없는 파일이라고 인지를 하기 때문 🤔)
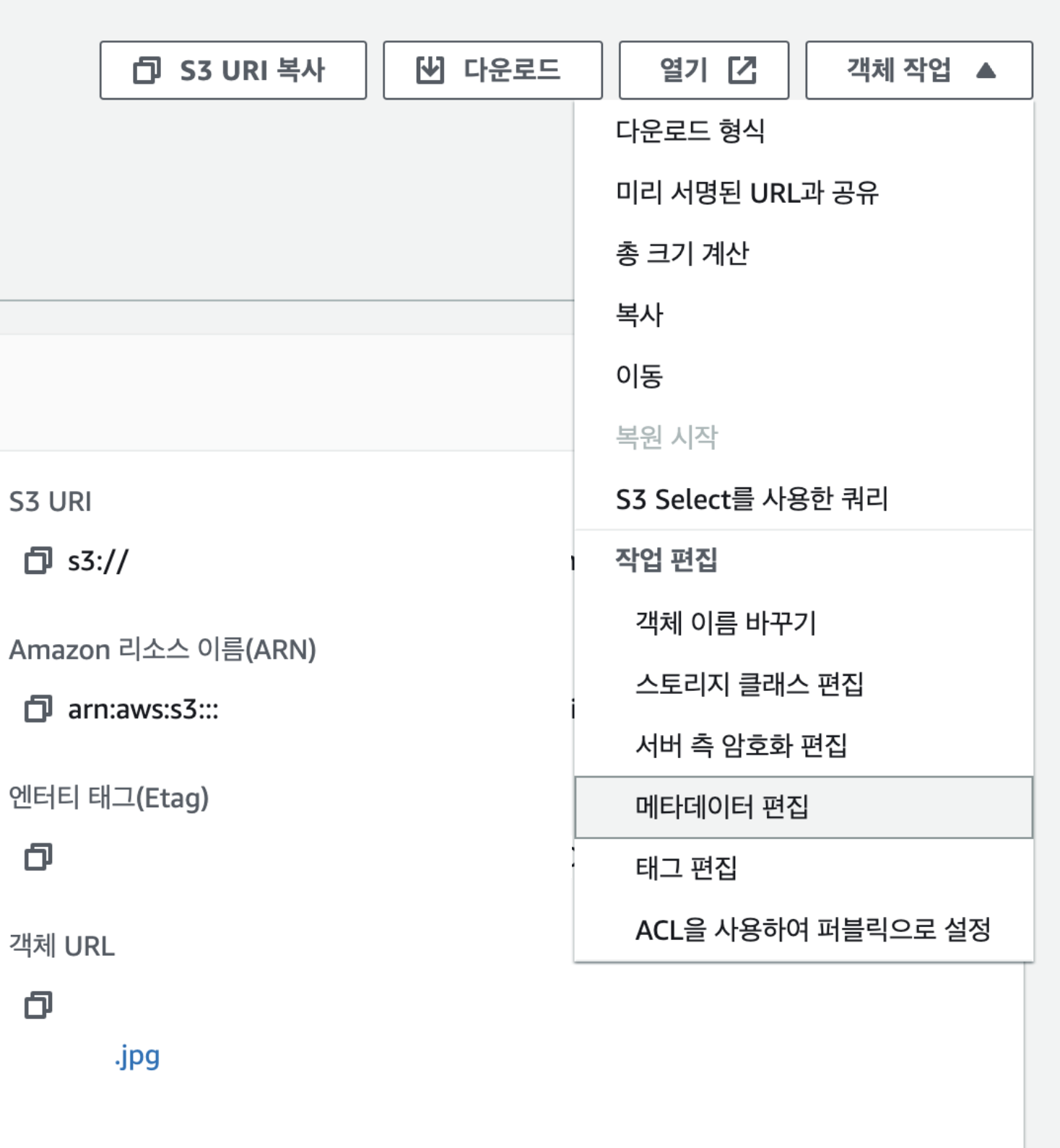
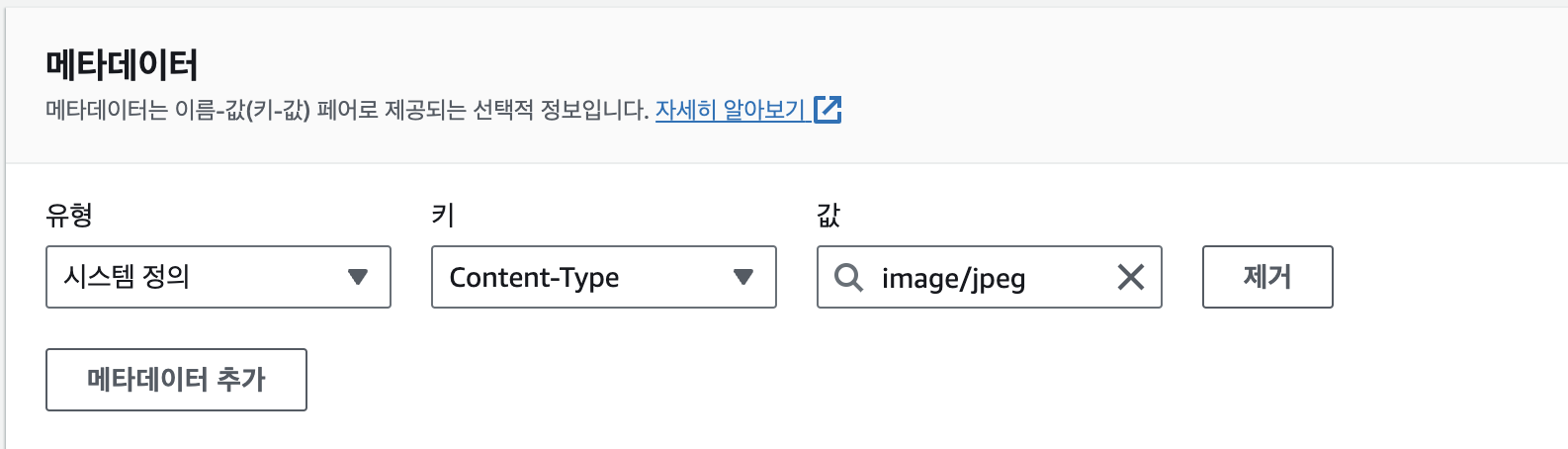
이때 메타데이터 편집에서 키 Content-Type , 값이 image/jpeg 가 선택 되어있는지 확인이 필요하고, 만일 설정이 잘못되어있다면 편집을 해준다.
각각의 이미지 주소에 대해 조금 더 알아보자😀
❓ 링크 앞의 호스트가 다른 점
예를들면 aws에서 보이는 객체 url은 아래와 같다.
1)
https://seul-contents-dev.s3.ap-northeast-2.amazonaws.com/thumbnail/seulVelogImg.jpg
하지만 실제로 렌더링 될 경우 Network 탭에서 GET요청을 통해 확인해 보면 아래와 같다.
2)
https://seul.cloudfront.net/content/uploads/2000/01/main-01.jpg
왜 링크 앞의 호스트가 서로 다를까? 🤔
첫 번째 링크는Amazon S3의 URL이고, 두 번째 링크는 Amazon CloudFront의 URL이다. 이 두 서비스는 AWS(Amazon Web Services)의 서비스 중 일부이지만, 각각의 목적과 기능이 다르다!
Amazon CloudFront
CloudFront는 AWS에서 제공하는 콘텐츠 전송 네트워크 (CDN) 서비스이다.
사용자에게 빠르게 콘텐츠를 제공하기 위해 전 세계에 있는 여러 위치의 서버에 콘텐츠의 복사본을 저장한다.
CloudFront는 주로 S3와 같은 소스에서의 콘텐츠를 가져와서 전세계의 사용자에게 빠르게 제공하기 위해 사용된다.
https://seul.cloudfront.net/content/uploads/2000/01/main-01.jpg
Amazon S3 (Simple Storage Service):
S3는 AWS에서 제공하는 객체 저장 서비스이다.
사용자는 S3 버킷에 데이터를 저장하고, 웹에 직접 접근할 수 있는 링크를 제공받을 수 있다.
https://seul-contents-dev.s3.ap-northeast-2.amazonaws.com/thumbnail/seulVelogImg.jpg
위의 두 URL이 다르게 나타나는 이유는 S3의 원본 콘텐츠가 CloudFront CDN을 통해 전달되었기 때문이다.
즉 위의 예시에서, S3의 이미지가 CloudFront를 통해 전달되었기 때문!😄
CDN에 대해서는 이전에도 여러번 알아보았지만 한번 더 점검해보자!
CDN
CDN (Content Delivery Network)은 전세계 여러 지역에 데이터 센터와 서버를 보유하고 있는 네트워크 시스템을 말한다.
- CDN은 사용자가 웹 콘텐츠에 빠르게 액세스 할 수 있도록 도와주는 서비스로, 콘텐츠를 전 세계 여러 위치에 분산된 서버에 복제해 놓아 사용자가 가장 가까운 위치의 서버에서 콘텐츠를 가져올 수 있게 한다.
-
이 네트워크는 웹사이트의 정적 콘텐츠(이미지, CSS, JavaScript 파일 등)를 전 세계의 사용자에게 빠르게 제공하기 위해 설계되었다.
-
사용자가 콘텐츠를 요청하면 CDN은 사용자에게 가장 가까운 서버를 선택하여 해당 콘텐츠를 제공하게 된다. 이로 인해 웹사이트의 로드 시간이 단축되며, 서버에 대한 부하가 줄어든다.
📌 장점
1. 속도
사용자는 가장 가까운 위치의 서버에서 콘텐츠를 다운로드 받기 때문에 전송 속도가 빠르다.
2. 내구성 및 가용성
만약 한 서버에 문제가 생겨도 다른 서버에서 콘텐츠를 제공할 수 있다.
3. 비용 절감
트래픽이 가장 가까운 서버로 이동하므로 원본 서버에 가해지는 부하가 줄어든다.
📌 정리하자면
CloudFront는 Amazon S3와 같은 AWS 서비스와 통합되어 작동한다. 따라서, 원래의 이미지 파일은 Amazon S3에 저장되고, CloudFront는 이 이미지를 전 세계의 여러 서버에 배포한다.
두 URL에 대한 설명:
-
https://seul.cloudfront.net/content/uploads/2000/01/main-01.jpg
: 이 주소는 CloudFront를 통해 제공되는 이미지의 주소. -
https://seul-contents-dev.s3.ap-northeast- amazonaws.com/thumbnail/seulVelogImg.jpg
: 이 주소는 원본 이미지가 저장된 Amazon S3의 주소.
두 주소 중 어느 주소를 사용해야 할지는 상황에 따라 다르다고 한다.
-
웹사이트에 이미지를 표시하거나 사용자에게 제공해야 할 때는 CloudFront URL(
cloudfront.net)을 사용하는 것이 좋다. 이렇게 하면 CDN의 장점을 활용할 수 있다. -
직접적인 파일 작업(예: 백업, 수정, 삭제)이 필요한 경우 원본 파일이 저장된 Amazon S3의 URL(
amazonaws.com)을 사용하는 것이 좋다.
결론적으로, 둘 다 "정확한" 주소이지만, 사용 목적에 따라 적절한 주소를 선택해야 한다고 한다. 🧐
❓그럼 주소의 내용중 https://abcdeee1x0x55gw.cloudfront.net 에서 'abcdeee1x0x55gw' 은 뭘까? 이 알수없는 주소는 어디로부터 정의될까? 🤔
👉 abcdeee1x0x55gw는 Amazon CloudFront 배포의 고유한 식별자이다. 이것은 CloudFront 배포를 생성할 때 AWS에 의해 자동으로 할당되는 값이다.
Amazon CloudFront에서 콘텐츠를 전송하기 위해 여러 배포를 생성할 수 있다. 각 배포는 고유한 도메인 이름(예: abcdeee1x0x55gw.cloudfront.net)을 가진다. 이 도메인 이름을 사용하여 CloudFront 배포에 저장된 콘텐츠에 액세스할 수 있다.
abcdeee1x0x55gw와 같은 식별자는 AWS에서 자동으로 생성되며, 사용자가 직접 지정할 수 없다. 이 식별자는 고유하게 CloudFront 배포를 식별하기 위한 목적으로 사용된다.
사용자는 CloudFront 콘솔 또는 AWS SDK/CLI를 통해 배포를 생성, 관리 및 삭제할 수 있다. 배포를 생성할 때마다 새로운 고유한 도메인 이름이 할당된다.
S3 서버란?
Amazon S3 (Simple Storage Service) 는 AWS에서 제공하는 확장 가능한 객체 저장 서비스이다.
- 사용자는 S3에 데이터를 저장하고, 웹에서 직접 접근할 수 있는 링크를 제공받을 수 있다.
- S3는 높은 내구성과 가용성을 제공하며, 웹 호스팅, 백업, 데이터 분석 등 다양한 용도로 사용된다.
Amazon S3 주요 특징 및 기능
-
객체 저장 서비스
S3는 객체 저장 서비스로서, 파일을 객체로 간주하고 각 객체에 대한 키와 값의 형태로 저장한다. 여기서 "키"는 파일의 이름 또는 경로를 나타내며 "값"은 실제 데이터 자체이다. -
확장성
사용자는 S3에 무한한 양의 데이터를 저장할 수 있다. 개별 객체의 크기는 최대 5TB까지 가능하다. -
버킷
모든 S3 객체는 "버킷"이라는 컨테이너에 저장된다. 버킷은 고유한 이름을 가져야 하며, AWS 전체에서 유일해야 한다. -
데이터 보호
S3는 자동 복제 기능을 제공하여 데이터의 내구성과 가용성을 보장한다. 기본적으로 모든 객체는 최소 3개의 물리적 장소에 복제되어 저장된다.
또한, 다양한 수준의 접근 제어와 버전 관리 기능을 제공하여 데이터의 보호 및 복구를 지원한다. -
데이터 전송
AWS의 다른 서비스와 통합되어, EC2, Lambda, Redshift 등의 서비스와 데이터를 쉽게 전송하고 처리할 수 있다. -
이벤트 알림
S3 버킷에 객체가 추가되거나 수정될 때 Lambda 함수와 같은 다른 서비스로 알림을 보낼 수 있다. -
생명주기 관리
객체의 생명주기 정책을 설정하여 오래된 데이터를 자동으로 S3 Infrequent Access, S3 Glacier, 또는 S3 Glacier Deep Archive와 같은 저렴한 스토리지 클래스로 이동하거나 삭제할 수 있다. -
웹 호스팅
S3는 정적 웹 사이트 호스팅도 지원한다. 이를 통해 HTML, CSS, JavaScript 파일 등을 호스팅하여 웹사이트를 운영할 수 있다. -
고급 분석 기능
S3 Select와 같은 기능을 사용하여 S3의 데이터에 대한 SQL 스타일의 쿼리를 실행할 수 있다. -
통합과 호환성
S3는 AWS의 다른 서비스, 예를 들어 AWS Lambda, Amazon Redshift, Amazon EMR 등과 원활하게 통합된다.
S3는 이러한 특징 및 기능 덕분에 데이터 백업, 아카이브, 콘텐츠 배포, 웹사이트 호스팅, 빅 데이터 분석 및 모바일, 게임, IoT 애플리케이션에 이르기까지 다양한 사용 사례에서 활용되고 있다고 한다.😀
S3에서 CloudFront로 콘텐츠 전달 과정
-
원본 생성
먼저, Amazon S3에서 데이터 (예: 이미지, 동영상, 웹 페이지 등)를 저장한다. 이 S3 버킷은 CloudFront와 연결되어 CDN의 "원본"으로 사용된다. -
CloudFront 배포 생성
AWS 관리 콘솔 또는 AWS CLI/API를 사용하여 CloudFront 배포를 생성한다.
이 배포 과정에서 S3 버킷을 원본으로 지정하고, 다른 설정들(예: SSL 인증서, CNAME 등)을 구성한다. -
콘텐츠 요청
사용자가 웹 브라우저나 앱을 통해 이미지나 다른 콘텐츠를 요청하면, 해당 요청은 CloudFront의 가장 가까운 엣지 로케이션(지역 서버)으로 전달된다. -
캐싱 및 전달
CloudFront는 해당 엣지 로케이션의 캐시를 확인한다.
이미 캐시에 콘텐츠가 있으면 즉시 사용자에게 전달한다.
캐시에 콘텐츠가 없으면, 원본 S3 버킷에서 콘텐츠를 가져온 후 사용자에게 전달하고, 동시에 엣지 로케이션의 캐시에도 저장한다. -
캐시 만료
캐싱된 콘텐츠는 설정된 TTL(Time-to-Live) 동안 엣지 로케이션에 보관된다. TTL이 만료되면, 다음 사용자의 요청 시 콘텐츠는 다시 원본 S3 버킷에서 가져와 캐시가 갱신된다.
이러한 방식으로, CloudFront는 전세계의 사용자에게 콘텐츠를 빠르게 제공할 수 있으며, S3의 트래픽 비용을 절약할 수 있다.
버킷
Amazon S3에서 "버킷"은 데이터를 저장하는 기본 컨테이너이다. 각 버킷은 고유한 이름을 가지며, 그 안에 여러 파일(객체)을 저장할 수 있다.
- S3 버킷은 AWS의 S3 서비스에서 데이터를 저장하고 조직화하는 데 사용되는 기본적인 컨테이너이다.
버킷의 특징
-
고유성
S3 버킷의 이름은 전 세계 AWS의 모든 S3 버킷 중에서 고유해야 한다. 다시 말해, 한 사용자가 "my-images"라는 이름으로 버킷을 생성했다면, 다른 사용자는 동일한 이름의 버킷을 생성할 수 없다. -
저장소
버킷은 S3에서 데이터를 저장하기 위한 컨테이너 역할을 한다. 이 안에는 여러 객체 (예: 이미지, 동영상, 문서 등)를 저장할 수 있으며, 각 객체는 고유한 키를 통해 식별된다. -
리전 설정
버킷은 특정 AWS 리전(지역)에 생성된다. 한번 선택한 리전은 나중에 변경할 수 없다. 리전을 선택할 때는 데이터의 거주 위치, 레이턴시, 비용 및 준수 사항을 고려해야 한다. -
정책 및 설정
각 버킷은 별도로 설정 및 정책을 가질 수 있다. 예를 들어, 특정 버킷에 대한 액세스 권한, CORS 설정, 버전 관리, 로깅 및 라이프사이클 정책 등을 설정할 수 있다. -
URL
S3 버킷 및 그 안의 객체는 고유한 URL을 통해 접근될 수 있다. 예를 들어, "my-images"라는 버킷에 "sunset.jpg"라는 이미지가 있다면, 해당 이미지에 대한 URL은 다음과 같은 형태가 될 수 있다.
https://my-images.s3.amazonaws.com/sunset.jpg
