💡 총정리
서버를 어떻게 하면 효과적으로 무중단 운영을 할 수 있을지 고민하고, 관련된 이론을 배우는 뜻깊은 시간이었다. 공부하면서 인프라와 클라우드 구성에도 정답이 없고, 상황에 따라 효과적인 전략을 잘 짜는 게 중요하다는 것을 점점 더 깊게 깨닫는 중이다. 💪🏻
1. vSphere Cluster
1-1. Cluster가 무엇이고, 왜 사용하는가?
Cluster 는 여러 개의 ESXi 호스트가 하나처럼 동작하게 하는 것이다. 단순하게 가상머신을 여러 대 사용하는 것을 넘어, Cluster를 사용하는 이유는 시스템에 장애가 발생하더라도 서비스가 중단되지 않도록 설계하기 위함이다. Cluster를 사용하게 되면 논리적으로 여러 대의 서버를 묶어서, 하나의 서버가 중단되면 자동으로 VM이 다른 ESXi 호스트에서 재시작함으로써 서비스 Down time을 최적화할 수 있다.
이 때, Cluster 에서 사용하는 ESXi 호스트들은 동일한 네트워크 안에서 동작해야 원하는대로 활용이 가능하다.
또한, 클러스터에 한 번 참여한 ESXi 호스트들은 바로 클러스터를 나갈 수 없고 유지보수 모드로 만들어야 클러스터에서 제거가 가능하다.
2. vMotion, vSphere H.A
2-2. 고가용성(HA) 사용하기
그럼 Cluster 를 어떻게 활용해야 목적대로 Down time이 최소화된 무중단 시스템을 운영할 수 있을까? 대표적으로 두 가지 방법을 사용할 수 있다. 첫째로는 vSphere의 HA를 사용하는 방법이다. Cluster 내의 하나의 ESXi 호스트가 장애가 나면 다른 ESXi 호스트로 VM을 옮겨서 실행시켜줌으로써 운영 중단을 최소화시킬 수 있다.
vSphere HA는 VM을 새로운 호스트에서 "재부팅"하는 방식이므로, vMotion이 없어도 동작이 가능하다.
2-1. Migration 하여 ESXi 호스트 옮기기
둘째로는, Cluster 로 묶었을 때, VM이 존재하는 ESXi 호스트를 바꿀 수 있는 매커니즘을 활용할 수 있다. 이를 vMotion이라고 하는데, 실행 중인 가상머신을 새로운 환경으로 중단없이 옮길 수 있다. vMotion을 사용하게 되면 VM의 위치를 변경하는 것이므로 vSphere HA와 달리 VM이 추가로 필요하지 않다.
이 때, 가상머신을 중단시킨 상태로 Migration하면 Cooled Migration 이라고 하고 가상머신을 실행하는 상태로 Migration하면 Hot Migration 이라고 한다.
3. DRS
3-1. 🤔 Cluster를 활용해서 자동으로 부하를 분산시키는 방법
이로써 서버 운영자의 필수 과제인 안정적으로 서버를 중단시키지 않고 운영할 수 있는 방법에 한 발자국 가까워졌다. 그러나, vMotion만을 활용하면 서버 운영자가 수동으로 무중단 시스템을 구현하기 위해서 24시간 서버실에 앉아있어야 할 것이다. 그러면 오히려 인적자원, 리소스가 낭비되고 서버를 효과적으로 운영하기 어려워진다.

DRS(Distributed Resource Scheduler) 를 사용하면 시스템이 자동으로 리소스를 균등하게 배분해줌으로써 성능을 최적화시키고, 수동으로 관리해야하는 문제를 해결할 수 있다. 부하가 높은 호스트의 VM을 자동으로 부하가 적은 호스트로 Migration 하여, 서버가 다운되기 이전에 예방하는 방식이다.
자동화의 적용 범위에 따라서 DRS의 동작 모드가 3가지로 나뉘게 된다.
✅ DRS의 동작 모드
1. 완전 자동 모드 (Fully Automated Mode)
: DRS가 모든 과정을 자동으로 수행하는 모드
2. 부분 자동 모드 (Partially Automated Mode)
: VM의 초기 배치는 자동이지만, 부하 분산(VM 이동)은 관리자 승인 후 실행하는 모드
3. 수동 모드 (Manual Mode)
: DRS가 부하 분산을 추천만 하고, 실행 여부는 전적으로 관리자가 결정하는 모드
Automated 모드에서는 VM의 초기 배치는 모두 자동이며, 이후에 DRS가 자동으로 VM을 이동시키려고 할 때 관리자의 승인 여부에 따라서 완전, 부분 자동 모드가 구분된다.
3-2. vCenter Client에서 DRS 테스트 해보기
1️⃣ Cluster 구성하기
우선, DRS 옵션과 HA(고가용성) 옵션은 주지 않고 클러스터를 구성한 이후 DRS 옵션을 추가해야한다. 처음부터 설정해주면 설정이 꼬일 수 있고, Cluster에 ESXi 호스트가 포함될 때 추가적인 설정들을 더 해줘야한다. 그렇기 때문에 후순위로 미뤄두는 것을 추천한다.
2️⃣ VMKernel에 Storage 연결하기
Cluster에 포함되어있는 호스트, VM들은 모두 동일한 스토리지를 사용해야한다. 왜냐하면 vMotion으로 마이그레이션을 진행해야할 때 공유 스토리지가 필요하며, VM을 재시작해주는데에 동일한 스토리지를 사용해야하기 때문이다. 이 때, 외부 스토리지가 필요하기 때문에 당연히 VMFS가 아닌 NFS나 iSCSI 스토리지를 연결해주어야 한다.
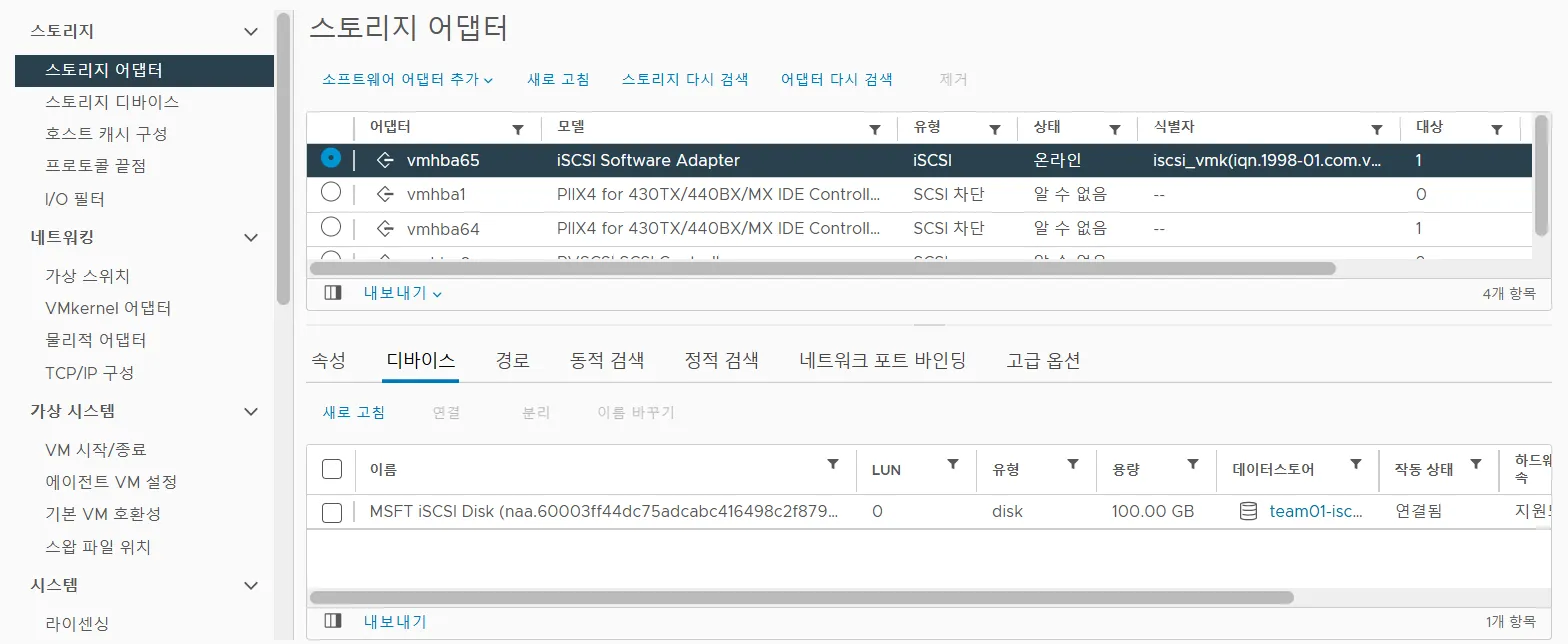
나의 경우는 공통 DNS Server에 있는 iSCSI 스토리지를 연결해주었다.
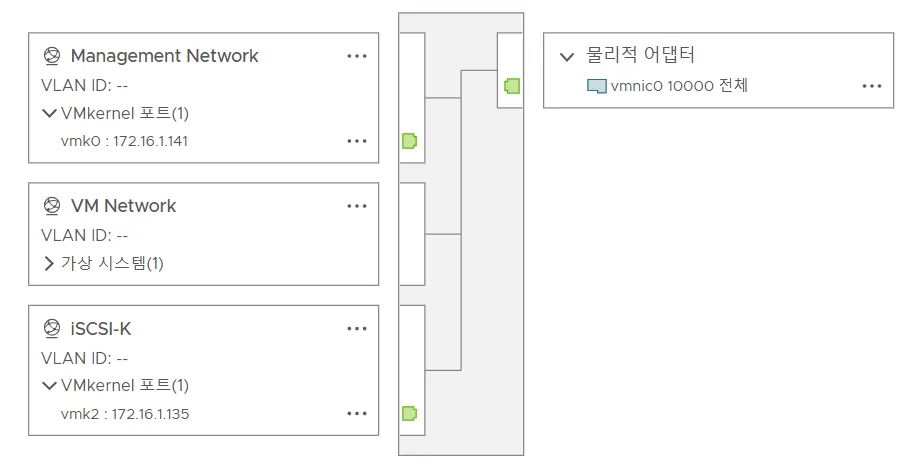
그리고 Mgt Port가 있는 vSwitch에 iSCSI 용 VMKernel을 연결해주었다.
3️⃣ DRS 동작 모드 설정하기
DRS가 자동으로 VM을 옮길 수 있도록 동작 모드를 설정한다. 처음 VM을 할당할 때는 수동 동작 모드로 설정해주고, VM이 할당되고 난 이후에는 완전 자동 모드로 설정해주어 초기 VM 위치를 내가 설정할 수 있게 했다.
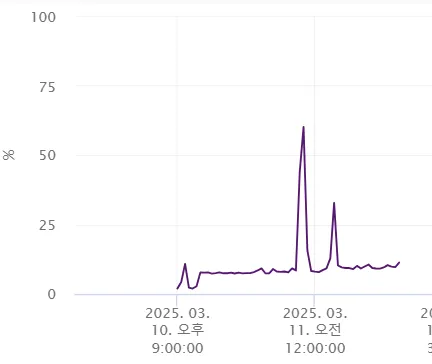
4️⃣ 가상머신(VM)에 과부하 주기
마지막으로 VM에 과부하를 주어서 ESXi 호스트의 성능이 저하되고, DRS가 정상적으로 실행되어 VM이 이동하는 것을 확인할 수 있었다.
4. F.T (Fault Tolerance)
vSphere HA, vMotion 은 모두 Down Time을 최소화시켜주지만, 운영체제가 재실행되는 시간이 필요하기 때문에 어느 정도 서비스가 중단되는 시간이 존재한다.
Down Time을 아예 제거하는 방법은 Fault Tolerance 기술이 있는데, 이는 가상머신을 실시간으로 복제하여 장애 발생 시에도 Down time이 없이 운영을 지속하는 기술이다. 복제 후 바로 Secondary 서버를 실행시키기 때문에 HA보다 한단계 높은 고가용성을 제공한다고 할 수 있다.
그러나, Fault Tolerance는 쉽게 말하자면 미러링 서버를 사용하는 것인데, 이를 구현하는 데에는 최소한 2개 이상의 EXSi 호스트가 반드시 존재해야하기 때문에 리소스가 많이 필요하다. 현재 기술로는 최대 8대의 서버 사용이 최대라고 한다. 또한, 사용하지 않고 노는 서버가 늘어나기 때문에, 한정된 자원 안에서는 F.T를 사용하는 것이 무조건적으로 최선은 아니다.
Fault Tolerance를 사용할 때는 아래와 같이 무조건 공유 데이터스토리지를 이용해야한다.