JAP를 사용하는 이유는 무엇일까?
JAP 발생배경
- SQL 중심적인 개발의 문제점
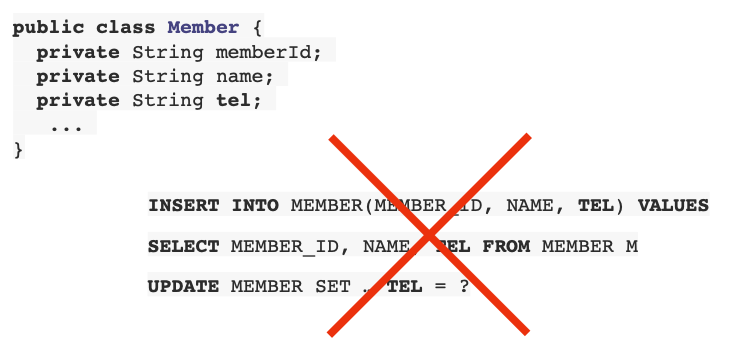
CRUD쿼리, 자바 객체를 SQL로.., SQL을 자바 객체로 등의 의 무한 반복, 지루한 코드가 이어지는 등 SQL에 의존적인 개발을 피하기 어렵다.
- 패러다임의 불일치 : 객체 VS 관계형 데이터베이스
-
반복적인 SQL매핑작업
객체를 영구 보관하기위해 관계형 데이터 베이스에 저장하게 되는데 새로운 컬럼이 추가되면 객체에 추가해줘야하는 등 개발자는 SQL매퍼가 아닌가?라는 생각이 들정도로 반복적인 매핑작업을 하게된다. -
객체답게 모델링 할 수 없는 한계
-
엔티티 신뢰 문제 발생
class MemberService { public void process() { Member member = memberDAO.find(memberId); member.getTeam(); //??? member.getOrder().getDelivery(); // ??? } }이와 같이 member.getTeam()와 member.getOrder().getDelivery()를 사용할 수 있는지는 직접 sql쿼리를 가서 분석해야만 알 수 있는 엔티티 신뢰 문제가 발생한다.
이처럼 객체답게 모델링 할수록 매핑 작업만 늘어나게 되 객체를 자바 컬렉션에 저장 하듯이 DB에 저장할 수는 없을까? 라는 생각에서 나오게 된게 JPA(Java Persistence API)이다.
JPA?
-
Java Persistence API
-
자바 진영의 ORM 기술 표준
ORM?
- Object-relational mapping(객체 관계 매핑)
- 객체는 객체대로 설계
- 관계형 데이터베이스는 관계형 데이터베이스대로 설계
- ORM 프레임워크가 중간에서 매핑
- 대중적인 언어에는 대부분 ORM 기술이 존재 (ex: typescript, pythone등)
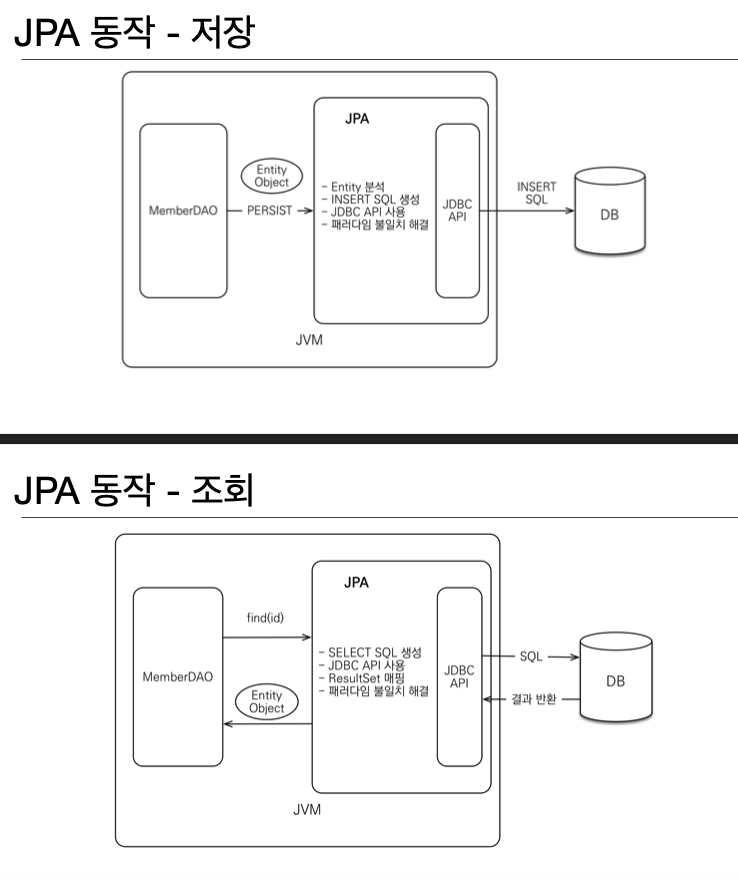
JPA 동작
JPA는 애플리케이션과 JDBC 사이에서 동작
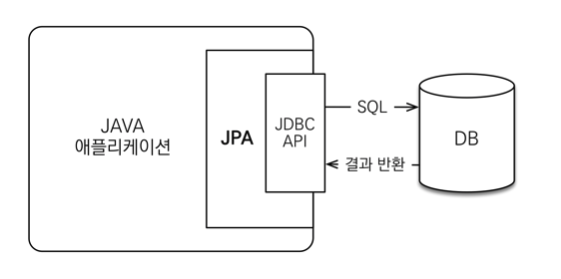
개발자가 직접 JDBC API를 쓰는게 아니라, JPA에게 명령을 하면 JPA가 JDBC API를 호출해 SQL를 생성하여 결과를 반환받는다.
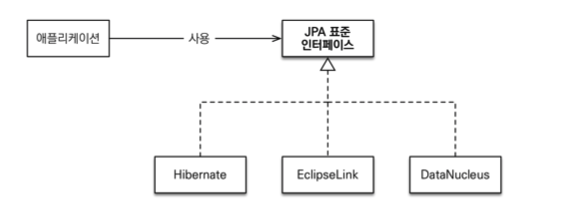
JPA는 표준 명세
- JPA는 인터페이스의 모음
- JPA2.1 표준 명세를 구현한 3가지 구현체.
- *하이버네이트, EclipseLink, DataNucelus
JPA를 왜 사용해야 하는가?
- SQL 중심적인 개발에서 객체 중심으로 개발
- 생산성
- 유지보수
- 패러다임의 불일치 해결
- 성능
- 데이터 접근 추상화와 벤더 독립성
- 표준
1. SQL 중심적인 개발에서 객체 중심으로 개발
2. 생산성
- 저장: jpa.persist(member)
- 조회: Member member = jpa.find(memberId)
- 수정: member.setName(“변경할 이름”)
- 삭제: jpa.remove(member)
자바 컬렉션에 데이터를 넣었다 뺐다하는 것처럼 사용할려는게 JPA
3. 유지보수
- 기존 : 필드 변경시 모든 SQL 수정
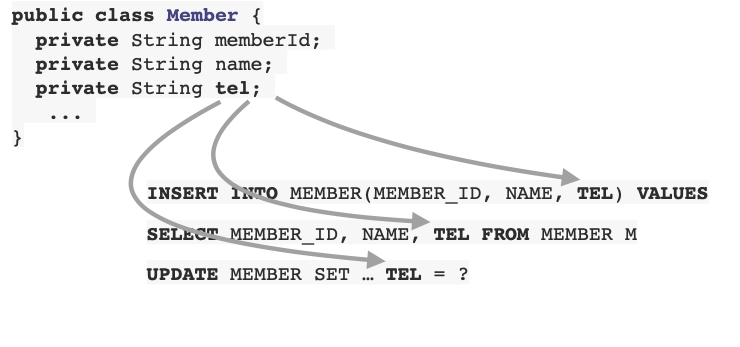
- JPA : 필드만 추가하면 됨, SQL은 JPA가 처리.
4. 패러다임의 불일치 해결
- JPA와 상속
객체지향 프로그래밍은 추상화, 캡슐화, 정보은닉, 상속, 다형성 등 시스템의 복잡성을 제어할 수 있는 다양한 장치들을 제공한다. 그래서 현대의 복잡한 어플리케이션을 객체지향 언어로 개발하고 있다.
비즈니스 요구사항을 정의한 도메인 모델도 객체로 모델링하면 객체지향 언어가 가진 장점들을 활용 할 수 있다. 문제는 이렇게 정의한 도메인 모델을 저장할 때 발생한다.
왜냐하면, 관계형 데이터베이스에 객체를 저장시 관계형 데이터베이스는 데이터 중심적으로 구조화 되어있고, 집합적인 사고를 요구하며 객체지향에서 이야기하는 추상화, 상속,다형성 같은 개념이 없다. 즉, 관계형 데이터 베이스와 객체지향 언어는 지향하는 목적이 서로 다르기 때문에 둘의 기능과 표현 방법이 다르고 이는 패러다임의 불일치 문제를 야기한다. 따라서 객체구조를 테이블 구조에 저장하는데 한계가 있고 이런 불일치 문제를 해결하는데 개발자가 중간에서 많은 시간과 코드를 소비한다.
아래에서 이로 인해 발생하는 문제를 구체적으로 설명하겠다.
- 상속
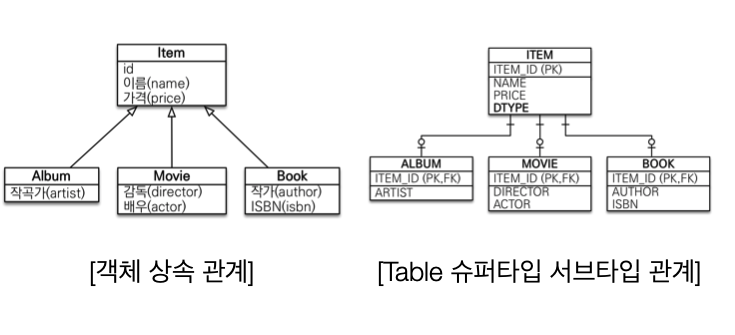
1) 자바컬렉션에 보관한다면?
abstract class Item{
Long id;
String name;
int price;
}
class Album extends Item{
String artist;
}
class Movie extends Item{
String director;
String actor;
}
class Book estends Item{
String author;
String actor;
}만약, 해당 객체들을 데이터베이스가 아닌 자바 컬렉션에 보관한다면 다음 같이 부모 자식이나 타입에 대한 고민 없이 해당 컬렉션을 아래와 같이 그냥 사용하면 된다.
list.add(album);
list.add(movie);
Album album = list.get(albumId);2) 데이터 베이스에 저장한다면?
객체는 상속이라는 기능을 가지고 있지만 테이블은 상속이라는 기능이 없다.
그나마 데이터 베이스 모델링에서 이야기하는 슈퍼타입 서브타입 관계를 사용하면 객체 상속과 가장 유사한 형태로 테이블을 설계할 수 있다.
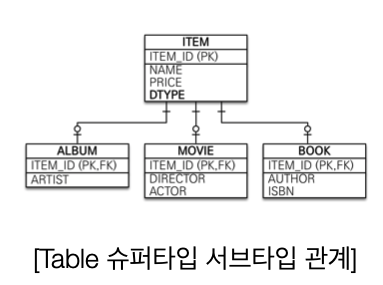
위의 그림과 같이 ITEM테이블의 DTYPE 컬럼을 사용해서 어떤 자식 테이블과 관계가 있는지 정의하고
자식테이블에 ITEM_ID칼럼을 통해 부모테이블과의 관계를 정의했다.
이때, Album객체를 저장할려면 다음 두 SQL을 만들어야 한다.
INSERT INTO ITEM ...
INSERT INTO ALBUM ... 이 때 JDBC API를 사용해서 이 코드를 완성하려면
1. 부모 객체(Item)에서 부모 데이터만 꺼내서 item용 insert sql을 작성
2. 자식객체에서 자식 데이터만 꺼내서 ALBUM 용 INSERT SQL을 작성해야한다.
3. 자식타입에 따라서 DTYPE도 저장해야 한다.
이렇게 작성해야할 코드량이 많만치 않다.
또한 조회할 때도 album을 조회한다면 item과 album테이블을 조인해서 조회한다음 그 결과로 album객체를 생성해야하는 등 조회하는 것도 쉬운 일이 아니다.
3) JPA와 상속
JPA는 상속과 관련되 패러다임의 불일치 문제를 개발자 대신 해결해준다.
개발자는 마치 자바컬렉션에 객체를 저장하듯이 JPA에게 객체를 저장하면 된다.
1. Item을 상속한 Album객체 저장
- 저장

개발자는 한줄의 코드만 날리면, 나머진 JPA가 처리해 알아서 2개의 insert query를 생성해 실행한다.
2. Album 객체를 조회.
- 조회

JPA는 ITEM과 ALBUM 두 테이블을 조인해서 필요한 데이터를 조회하고 그 결과를 반환한다.
5. 성능
-
1차 캐시와 동일성(identity) 보장.
1) 같은 트랜잭션 안에서는 같은 엔티티를 반환한다. - 약간의 조희 성능 향상String memberId = "100"; Member memeber1 = jpa.find(Member.classs, memberId); //SQL Member memeber2 = jpa.find(Member.classs, memberId); //캐쉬 member1 == member2 // true- 위 코드는 같은 트랜잭션 안에서 같은 회원을 두 번 조회하는 코드의 일부분.
- 위의 코드의 결과와 같이 JPA를 사용하면 회원을 조회하는 SELECT SQL을 한 번만 데이터베이스에 전달하고 두 번째는 조회한 회원 객체를 재사용
- [JDBC API와 비교]
JDBC API를 사용해서 해당코드를 직접 작성했다면 회원을 조회할 때마다 SELECT SQL을 사용해서 데이터베이스와 두 번 통신했을 것이다.
- [JDBC API와 비교]
2) DB Isolation Level이 Read Commit이어도 애플리케이션에서 Repeatable Read보장.
-
트랜잭션을 지원하는 쓰기 지연(transactional wirtie-behind)
1) 트랜잭션을 커밋할 때까지 INSERT SQL을 모음.
2) JDBC BATCH SQL 기능을 사용해서 한번에 SQL 전송transaction.begin(); // [트랜잭션] 시작 em.persist(member A); em.persist(member B); em.persist(member C); //여기까지 INSERT SQL을 데이터베이스에 보내지 않는다. transaction.commiit()// [트랜잭션] 커밋 //커밋하는 순간 데이터베이스에 INSET SQL을 모아서 보낸다. -
간단한 설정을 통해 실제 사용하는 시점에 지연 로딩(Lazy Loading)과 즉시로딩 인지를 정의할 수 있다.
- 지연 로딩: 객체가 실제 사용될 때 로딩
- 즉시 로딩: JOIN SQL을 한번에 연관된 객체까지 미리조회
