
📍CSV 파일 읽고 쓰기
CSV(Comma-Seperated Values)로 콤마로 분류되어 있는 데이터들을 말한다.with객체를 사용하여 파일을 열고 읽고, 쓸 수 있다. (w,r,a,r+모드가 있음)file.write(): 파일 쓰기file.read(): 파일 읽기file.readlines(): csv파일 모두 읽기file.readline(): csv파일 한줄만 읽기(최상단)
📍실습 2
- CSV로 작성된 연도, 월별 판매데이터를 취합해 한 개의 CSV 파일에 연도, 월, 매출로 구성된 파일을 생성해주세요. 각 연도, 월별 판매 데이터에는 수강생명, 수강금액, 상담날짜, 강좌명으로 구성된 CSV 파일입니다.
[['수강생명', '수강금액', '상담날짜', '강좌명'],
['배찬우', '900000', '2017.10.10', '파이썬 자동화 강의'],
['조윤장', '820000', '2017.10.11', '파이썬 자동화 강의'],
['김민우', '740000', '2017.10.02', '파이썬 자동화 강의'],
['이은철', '900000', '2017.10.12', '파이썬 자동화 강의'],
['정용운', '900000', '2017.10.09', '파이썬 자동화 강의'],
['윤순규', '720000', '2017.10.06', '파이썬 자동화 강의'],
['이창희', '880000', '2017.10.08', '파이썬 자동화 강의'],
['정택호', '720000', '2017.10.17', '파이썬 자동화 강의'],
['양영주', '820000', '2017.10.02', '파이썬 자동화 강의'],
['권민재', '640000', '2017.10.29', '파이썬 자동화 강의']]csv파일 인코딩이 깨져서 출력물을 가져왔다. 대충 이렇게 구성된 csv파일들이 2017년 1월부터 12월까지 각각 존재한다.
💻나의 코드
import os
file_list = os.listdir('실습2/csv_files')
for file in file_list:
with open('실습2/csv_files/' + file, 'r') as f:
header = f.readline() # 헤더 빼기
data = [l.rstrip().split(',') for l in f.readlines()]
sum = 0
for i in range(len(data)):
sum += int(data[i][1])
with open('실습2/csv_files/orders.csv', 'w', encoding='utf-8') as f:
# f.write('연도, 월, 매출\n')
f.write('%s, %s, %d\n'%(file[:4], file[5:7], sum))이렇게 하면
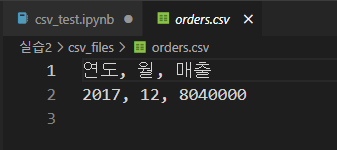
이렇게.. 맨 마지막 12월의 매출 합 밖에 나오지 않는다. 강사님 풀이랑 별 반 다를게 없길래 도대체 어디서 실수했나 했더니
with open('실습2/csv_files/orders.csv', 'w', encoding='utf-8') as f:
# f.write('연도, 월, 매출\n')
f.write('%s, %s, %d\n'%(file[:4], file[5:7], sum))이 부분에서 mode를 'a'로 해줘야 함.. 왜냐면 반복문 안에서 계속 파일을 이어서 써줘야 하기 때문에. 'w'를 쓰면 그 위에 계속 덮어쓰기밖에 안되던 것..!!
그리고 f.write('연도, 월, 매출\n') 이부분을 넣어주면
연도, 월, 매출
2017, 12, 123123
연도, 월, 매출
2017, 11, 123123
...이런식으로 출력됨.. 당연함.. 계속 이어서 써주는 거임.. 그래서 빼줌.

처음에 List Comprehenshion을 사용해서.. 혹시 그 List가 계속해서 초기화돼서 그런가? 했는데 이마저도 틀린생각 ㅋㅋㅋㅋㅋㅋㅋㅋ 아직 갈 길이 멀다.
💻모범 답안
import os
CSV_DIR = './실습2/csv_files/'
csv_list = os.listdir(CSV_DIR)
for csv in csv_list:
csv_dir = CSV_DIR + csv
with open(csv_dir, 'r') as f:
datas = f.readlines()
orders = []
for data in datas:
temp = data.rstrip().split(',')
orders.append(temp)
# 수강 금액 부분만 int형으로 바꾸고, 다 더해주면 됨
total_sale = 0
for order in orders[1:]:
total_sale += int(order[1])
with open(CSV_DIR + 'orders_answer.csv', 'a', encoding='utf-8') as f:
year, month, ext = csv.split('.')
# ['2017', '1', 'csv']
f.write('%s, %s, %s\n'%(year, month, total_sale))내 코드랑 거의 비슷함.
근데 CSV_DIR을 준 것 처럼 경로를 constant variable로 주면 훨씬 더 보기 깔끔한 것 같다. 상대경로라 그렇게 길진 않지만.. 저렇게 두는 걸 습관들여야 코드가 보기 편해질듯.
📍Excel 자동화
-
openpyxl: 엑셀 파일도 다룰 수 있는 패키지.pip install openpyxl로 설치! -
엑셀 생성, 불러오기
new_excel = openpyxl.Workbook(): 엑셀 생성read_excel = openpyxl.load_workbook(file_path, read_only=True): 읽기 모드
-
sheet 관리
new_excel.create_sheet('study_sheet'): 시트 생성
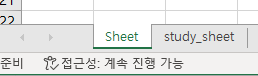
이렇게 생성된다.
-
활성화된 sheet 가져오기
target_sheet = read_excel.activestudy_sheet = new_excel['study_sheet']: 키값으로 지정해서 시트 불러오기
-
특정 셀 불러오기
a1_cell = study_sheet['A1']
A 칼럼의 1행을 불러오는 것이다. 컴활 배울때랑 비슷한듯 ㅎㅎ
-
셀 값 지정해주기
a1_cell.value = '테스트입니다'
print(a1_cell.value)테스트입니다가 출력된다. .value를 이용해서 셀 값을 지정해줄 수 있다. (당연히 row나 column에 사용하면 적용 안된다.)
- 엑셀의 슬라이싱은 끝 값을 포함해준다.
rows_12 = study_sheet['1:2']: 2행까지 확인 가능
- 셀값에 접근하려면 이중
for문을 사용하는 것이 일반적.
ab_columns = study_sheet['A:B']
for column in ab_columns:
for cell in column:
print(cell.value)new_excel.append([value1, value2, value3, ...]): 새 데이터 넣어주기
(하지만 잘 사용하진 않는다고 한다.)new_excel.save(‘target_path’): 지정된 경로에 엑셀파일 저장하기
📍실습 3
2017.12.1.xlsx~2017.12.9.xlsx엑셀 파일의 내용을 하나의 엑셀 파일에 취합해주세요.
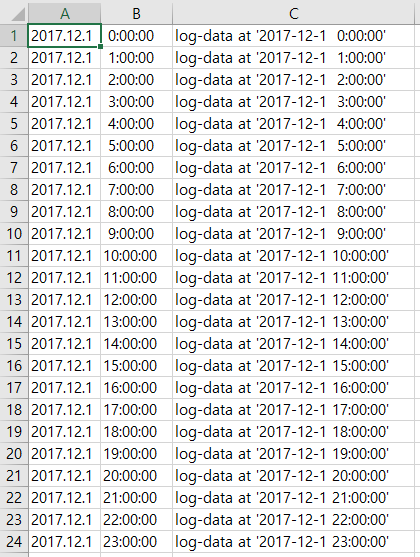
엑셀 파일들은 이렇게 구성돼있음.
💻나의 코드
import os
import openpyxl
xlsx_list = os.listdir('./실습3/')
result_excel = openpyxl.Workbook() # 워크북 클래스에 인스턴스를 만들어준다. 결과를 담을 result_excel 생성
result_sheet = result_excel.active
for xlsx in xlsx_list:
read_excel = openpyxl.load_workbook('./실습3/' + xlsx, read_only = True) # 각각의 파일을 불러온다
# 활성화된 시트 가져오기
Sheet = read_excel.active
# 각각의 row별로 데이터 저장
for row in Sheet.iter_rows():
row_data = []
for cell in row:
row_data.append(cell.value)
# 최종 결과 sheet에 데이터 append
result_sheet.append(row_data)
result_excel.save('./실습3/example3.xlsx')일단 os로 파일 제목들 불러오고, for문 안에서 openpyxl.load_workbook()으로 각각의 파일들을 불러온다.
처음엔 Sheet = read_excel['Sheet']로 sheet를 불러왔는데 활성화된 시트가 하나밖에 없으니 그냥 .active를 사용하면 되더라..
해당시트의 모든 row들을 .iter_rows()로 가져오고, row_data에 각각의 셀들을 append해준다. 각 sheet를 돌면서 행값을 저장해야하므로 row_data는 for문 안에서 계속 초기화를 시켜줘야 한다. 그렇게 row_data가 마지막 엑셀 sheet의 데이터까지 취합되면 result_sheet에 append해주면 끝~
결과를 담을 엑셀을 저장해주면 된다.
💻모범 답안
import os
import openpyxl
EXCEL_DIR = './실습3/'
excel_list = os.listdir(EXCEL_DIR)
new_excel = openpyxl.Workbook()
new_sheet = new_excel.active
for excel in excel_list:
workbook = openpyxl.load_workbook(EXCEL_DIR + excel, read_only = True)
data_sheet = workbook.active
for row in data_sheet.iter_rows():
temp = [row[0].value, row[1].value, row[2].value]
new_sheet.append(temp)
new_excel.save('./result.xlsx')나는 코드를 짜다보니 for문이 3중이 되었는데.. 저렇게 하면 이중for문으로 끝낼 수 있다.
훨씬 직관적이기도 한 듯.. 나는 생각을 너무 어렵게 하는거가탸,,,띠발
경로역시 EXCEL_DIR로 주는거 또 까먹었당 ㅎㅎ 데헷
csv파일은 학부생시절 인공지능 수업 들을 때 몇번 다뤄봐서 어렵진 않았는데, excel은 처음 다뤄봤다. 뭐 그렇게 어려운건 아니고 메서드들이 좀 외우기 힘들다..정도? 컴활 배웠을 때도 (자격증은 못땀 ㅎㅎ;) coulmn, row따지면서 뭐 그.. 암튼 이것저것 했었던 기억이🤔
