
📌문제
[프로그래머스] Lv.1 성격 유형 검사하기 (Python)
📌나의 풀이
- personality라는 dictionary에 R, T, C, F, J, M, A, N을 key로 두고 value를 0으로 초기화 한다.
- 아래의 선택지와 성격 유형 점수를 보면 choices에서 4점을 빼면 점수가 나온다는 것을 알 수 있다. (만약 choices가 5라면 5-4는 1이니까 어피치형 1점이 된다.)
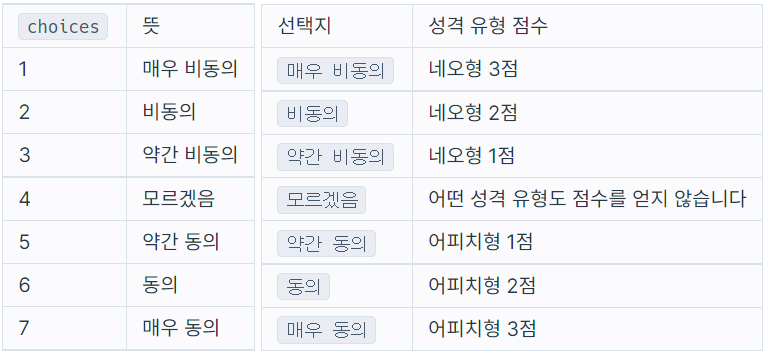
- 만약 choices - 4가 음수라면 비동의쪽 점수니까 네오형 1점이 되는 것!
- 따라서 survey가 입력됐을 때 choices - 4가 양수라면 오른쪽 부분 알파벳을 가져오고 점수를 저장한다.("RN"일 경우 N을 가져오며 choice - 4점을 저장함)
- 마찬가지로 음수가 나오면 왼쪽 부분 알파벳을 가져오고 점수를 저장한다.
💻코드
def solution(survey, choices):
answer = ''
personality = {
'R' : 0,
'T' : 0,
'C' : 0,
'F' : 0,
'J' : 0,
'M' : 0,
'A' : 0,
'N' : 0
}
for sur, choice in zip(survey, choices):
if choice - 4 > 0:
# 오른쪽 부분 알파벳
# personality[sur[1]] = personality[sur[1]] + choice-4
personality[sur[1]] += (choice - 4)
elif choice - 4 < 0:
# 왼족 부분 알파벳
personality[sur[0]] += (4 - choice)
new_personal = list(personality.items())
# 점수가 저장된 리스트를 순회하면서 점수가 높은 알파벳을 출력하면 됨
# RT/CF/JM/AN 이렇게 두쌍씩 봐야하니까 2씩 증가하면서 for문
# 앞에가 알파벳(0번째 인덱스), 1번째 인덱스가 점수임
# new_personal의 길이만큼 2씩 증가하면서 for문
for i in range(0, len(new_personal), 2):
# 점수가 높은 쪽 알파벳을 answer에 더해준다
if new_personal[i+1][1] > new_personal[i][1]:
answer += new_personal[i+1][0]
else: # 앞의 알파벳의 점수가 더 높거나 둘의 점수가 같다면
answer += new_personal[i][0] # 앞의 알파벳 출력, 사전순으로 빠른거
return answer사실 이 전에 좀 시행착오가 많았는데 따로 기록을 안해두고 프로그래머스 자체에서 바로 수정 때려서 제출해버려서.. 기억이 잘 안남..😂
코드에 대한 자세한 설명은 주석에 적혀있으니 생략.
📌다른사람 풀이
첫번째 다른 풀이
def solution(설문_조사_배열, 선택지_배열):
지표 = {}
지표['RT'] = 지표['TR'] = {'R': 0, 'T': 0,}
지표['FC'] = 지표['CF'] = {'C': 0, 'F': 0,}
지표['MJ'] = 지표['JM'] = {'J': 0, 'M': 0,}
지표['AN'] = 지표['NA'] = {'A': 0, 'N': 0,}
점수 = {
'매우 비동의': 3,
'비동의': 2,
'약간 비동의': 1,
'모르겠음': 0,
'약간 동의': 1,
'동의': 2,
'매우 동의': 3,
}
비동의 = [1, 2, 3]
동의 = [5, 6, 7]
선택지 = {
1: '매우 비동의',
2: '비동의',
3: '약간 비동의',
4: '모르겠음',
5: '약간 동의',
6: '동의',
7: '매우 동의',
}
answer = ''
for 인덱스 in range(len(설문_조사_배열)):
비동의_캐릭터, 동의_캐릭터 = 설문_조사_배열[인덱스]
if 선택지_배열[인덱스] in 비동의:
지표[설문_조사_배열[인덱스]][비동의_캐릭터] += 점수[선택지[선택지_배열[인덱스]]]
continue
if 선택지_배열[인덱스] in 동의:
지표[설문_조사_배열[인덱스]][동의_캐릭터] += 점수[선택지[선택지_배열[인덱스]]]
결과_배열 = [지표['RT'].items(), 지표['FC'].items(), 지표['MJ'].items(), 지표['AN'].items()]
정렬된_배열 = []
for 결과 in 결과_배열:
정렬된_배열.append(sorted(결과, key=lambda x: -x[1]))
return ''.join([캐릭터_점수_튜플[0] for [캐릭터_점수_튜플, _] in 정렬된_배열])매우 신선한 접근.. 한글로 돼있어서 더 직관적임
두번째 다른 풀이
def solution(survey, choices):
answer = ''
'RT'
'CF'
'JM'
'AN'
MBTI_dict = {
'RT': 0,
'CF': 0,
'JM': 0,
'AN': 0
}
# 반복문
for i in range(len(survey)):
mbti = survey[i]
if mbti in MBTI_dict:
# 양수일 경우, 앞에 나오는 유형이 +
# 음수일 경우, 뒤에 나오는 유형이 +
score = 4 - choices[i]
# 계산된 점수를 데이터에 최신화
MBTI_dict[mbti] += score
# 반대의 경우,
elif mbti[::-1] in MBTI_dict:
score = choices[i] - 4
MBTI_dict[mbti[::-1]] += score
# 계산된 결과를 가지고,
for key in MBTI_dict:
# 0보다 크거나 같으면, 앞을 선택
if MBTI_dict[key] >= 0:
answer+=key[0]
# 아닐 경우, 뒤를 선택
else:
answer+=key[1]
return answer이거는 수업시간에 강사님이 풀어주신 방법
나처럼 모든 알파벳에 점수를 저장한 것이 아니라 입력되는 값 두쌍을 가지고 dictionary에 저장해서 풀이 한 방법

중요한 것은 꺾이지 않는 마음