
✍️로드밸런싱이란?
Load(서버가 받는 요청, 부하) + Balancing(분산)
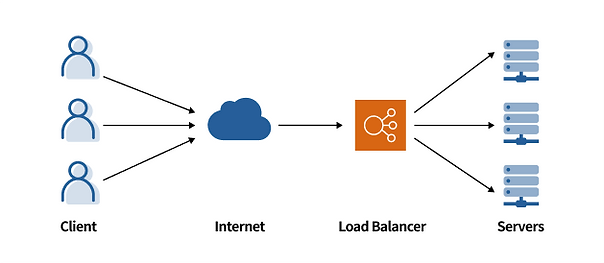
즉 로드밸런싱이란, '부하분산'으로 다수의 서버에 네트워크 트래픽을 균등하게 분배하여 시스템의 안정성과 가용성을 높이는 기술
💡로드밸런싱 알고리즘
- 라운드로빈 (Round Robin)
- 서버에 들어온 요청 순서대로 서버에 분배 (A,B,C 서버에 들어온 순서대로 하나씩 할당)
- 로드밸런싱 대상 서버의 스펙이 동일하고, 서버와의 연결이 오래 지속되지 않는 경우에 활용하기 적합한 방식
- 가중 라운드로빈 (Weighted Round Robin)
- 각 서버마다 가중치를 설정해두고 해당 가중치만큼 세션을 할당해주는 방식
- 성능이 좋은 서버에는 가중치를 더 두어서 세션을 더 많이 할당
- IP 해시 (IP Hash)
- 특정 사용자는 특정 서버로만 할당시키는 방식
- 특정 IP주소나 포트에서 접속량이 특히 많을 때 관리가 편한 방식
- 최소 연결 (Least Connection)
- 가장 적게 연결되어 여유가 있는 서버에 세션을 할당해주는 방식
- 서버의 연결이 자주 길어지거나, 각 서버에 분배된 트래픽들이 일정하지 않은 경우에 적합
- 최소 응답 (Least Response Time)
- 현재 연결 상태와 응답시간을 모두 고려하여, 가장 응답시간이 짧은 서버로 트래픽을 우선적으로 할당하는 방식
💡로드밸런싱 구현방법
| L4 로드밸런서 | L7 로드밸런서 | |
|---|---|---|
| 네트워크 계층 | Layer 4 전송계층(Transport layer) | Layer 7 응용계층(Application layer) |
| 특징 | IP주소, 포트(Port) 정보를 바탕으로 함 단순한 포워딩 | TCP/UDP 정보는 물론 HTTP의 URI, FTP의 파일명, 쿠키 정보 등을 바탕으로 함 |
| 장점 | - 데이터 안을 들여다보지 않고 패킷 레벨에서만 로드를 분산하기 때문에 속도가 빠르고 응답이 빠름 - 데이터의 내용을 복호화할 필요가 없기에 안전함 - L7 로드밸런서보다 가격이 저렴함 | - 상위 계층에서 로드를 분산하기 때문에 콘텐츠 기반 라우팅이 가능함 - 캐싱 기능을 제공함 - 비정상적인 트래픽을 사전에 필터링할 수 있어 서비스 안정성이 높음 |
| 단점 | - 패킷의 내용을 살펴볼 수 없기 때문에 섬세한 라우팅이 불가능함 - 사용자의 IP가 수시로 바뀌는 경우라면 연속적인 서비스를 제공하기 어려움 | - 패킷의 내용을 복호화해야 하기에 더 높은 비용을 지불해야 함 - 클라이언트가 로드밸런서와 인증서를 공유해야하기 때문에 공격자가 로드밸런서를 통해서 클라이언트에 데이터에 접근할 보안 상의 위험성이 존재함 |
✍️ 로드밸런서(Load Balancer)
로드 밸런싱을 수행하는 '실제 장비' 또는 '소프트웨어'
💡로드밸런서의 기본 기능
- 상태 확인 (Health Check)
- 서버들의 상태를 주기적으로 확인
- 응답시간, CPU 사용률 등 모니터링
- 비정상 서버 감지 및 트래픽 차단
- 장애 서버 복구 시 자동 감지
- NAT (Network Address Translation)
- 사설 IP를 공인 IP로 변환하는 기능
- 내부 네트워크와 외부 네트워크 간의 통신을 가능하게 함
| 방식 | 흐름 | 설명 |
|---|---|---|
| SNAT (Source NAT) | 내부 → 외부 | 내부 사설 IP 주소를 외부의 공인 IP 주소로 변환하는 방식 |
| DNAT (Destination NAT) | 외부 → 내부 | 외부 공인 IP 주소를 내부의 사설 IP로 주소로 변환하는 방식 |
- DSR (Direct Server Return)
- 서버가 클라이언트에게 직접 응답을 전송하는 방식
요청: [클라이언트] → [로드밸런서] → [서버]
응답: [클라이언트] ← [서버] (직접 응답)
- 서버가 클라이언트에게 직접 응답을 전송하는 방식
- 터널링 (Tunneling)
- 두 네트워크 사이에 가상 경로를 만드는 기능
- 캡슐화를 통한 통신 구현
✍️서버 확장 방식

-
Scale-up (스케일 업)
- 기존 서버의 하드웨어 성능을 향상시키는 방식
- 장점
- 관리가 단순
- 소프트웨어 수정이 거의 불필요
- 데이터 정합성 유지 용이
- 단점
- 하드웨어적 한계가 존재
- 장애 발생시 시스템 전체에 영향
-
Scale-out (스케일 아웃)
-
서버를 여러 대 추가하여 분산처리 하는 방식
-
장점
- 무제한 확장이 가능
- 일부 장애 시 전체 서비스에 영향 최소화
-
단점
- 데이터정합성 유지가 어려움
- 로드밸런싱이 필요🤔데이터 정합성
여러 시스템이나 데이터베이스에 저장된 데이터가 서로 모순없이 일치하는 상태
정합성 레벨
정합성 레벨 특징 장점 단점 사용 사례 강한 정합성
(Strong Consistency)- 데이터 쓰기 후 즉시 모든 읽기에 반영
- 모든 노드가 같은 값을 반환- 데이터 신뢰도 높음
- 트랜잭션 처리 용이
- 일관된 사용자 경험- 높은 지연시간
- 성능 저하
- 가용성 감소- 은행 거래
- 결제 시스템
- 예약 시스템약한 정합성
(Weak Consistency)- 데이터 쓰기 후 일정 시간 동안 이전 값 반환 가능
- 동기화 시점 보장 없음- 빠른 응답 시간
- 높은 처리량
- 시스템 부하 감소- 일시적 데이터 불일치
- 복잡한 에러 처리
- 사용자 혼란 가능성- SNS 좋아요
- 조회수
- 실시간 채팅최종 정합성
(Eventual Consistency)- 일정 시간 후 모든 복제본 동기화
- 최종적으로 일관된 상태 보장- 고가용성
- 낮은 지연시간
- 확장성 우수- 일시적 불일치
- 충돌 해결 필요
- 복잡한 설계 필요- DNS
- 이메일
- 분산 캐시데이터 정합성 유지 방법
1. 트랜잭션 관리
2. 동기화 메커니즘 사용
3. 복제(Replication) 전략 수립
-
Reference

게시글 업로드중..⌛