DFS와 BFS?
그래프 또는 트리를 탐색하기 위해
DFS(Depth-First Search, 깊이 우선 탐색),
BFS(Breadth-First Search, 너비 우선 탐색) 두 가지 기법이 쓰인다.
아래와 같은 트리에서 1부터 시작하여 모든 노드를 탐색하려 할 때,
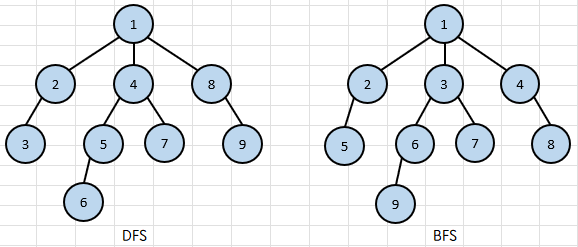
DFS, 깊이 우선 탐색은 인접한 노드중 하나를 방문해 그 정점에 인접한 노드들을 쭉 방문하고,
BFS, 너비 우선 탐색은 인접한 노드들을 우선적으로 모두 방문하는 것에 차이가 있다.
그렇다면 그래프에서의 탐색은 어떤 방식으로 이뤄지는 지 알아보자!
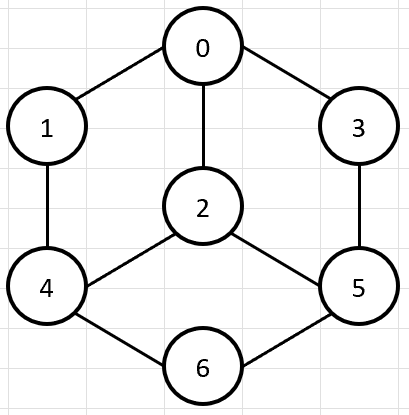
그래프란 어떠한 현상이나 사물을 아래 그림처럼 정점(vertex)과 간선(edge)로 표현한 것으로, 두 정점이 간선으로 연결되어 있을 때 인접하다고 한다.
위 그래프에서의 DFS, BFS는 다음과 같이 진행된다.
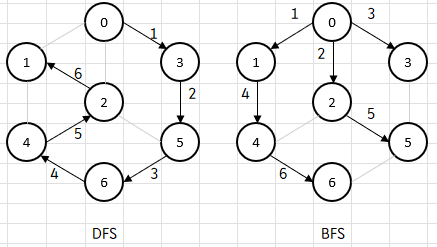
앞서 언급하였듯 DFS는 인접한 정점 하나에서 꾸준히 길을 찾아가고,
BFS는 인접한 정점들을 우선 모두 탐색한 뒤에야 그 다음 깊이를 탐색한다.
DFS는 스택 혹은 재귀, BFS는 큐를 이용하여 구현되며,
DFS와 BFS가 진행되는 원리는 필자가 벨로그로 이사오기 전에 작성했던 이 글에 자세히 설명되어 있으니 참고해주세용!
어떻게 쓰일까?
백준 1260번은 DFS, BFS로 그래프 탐색을 하는 가장 기초적인 문제이다.
우선 정점의 갯수 N과 간선의 갯수 M, 탐색을 시작할 정점 V를 입력받는다.
그리고 정점이 어떻게 연결되어 있는지에 대한 정보를 입력받으면, 이를 바탕으로 그래프를 생성하고 해당 그래프를 DFS, BFS로 탐색한 순서를 출력하는 문제이다.
단, 인접한 정점은 숫자가 작은 순서부터 방문한다는 점이 위의 참조 링크에서 설명된 DFS, BFS의 진행 원리와 이 문제의 차별점이다.
4 5 1
1 2
1 3
1 4
2 4
3 4
위와 같은 입력이 주어질 때, 그래프는 아래처럼 그릴 수 있다.
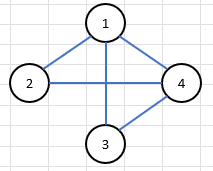
그렇다면 이 그래프를 DFS, BFS로 탐색한다면?
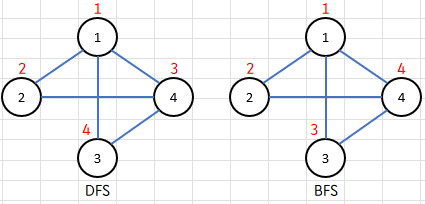
1 2 4 3
1 2 3 4
위와 같은 출력을 얻을 수 있다.
그래프 생성
그래프 생성은 main 함수에서 작성하였다.
#include <iostream>
#include <vector>
#include <queue>
#include <stack>
#include <algorithm>
using namespace std;
int N, M, V; // DFS, BFS에서 함께 쓰니까
vector<vector<int>> graph; // 전역변수로 선언
void DFS();
void BFS();
int main() {
cin >> N >> M >> V;
graph.resize(N + 1);
for (int i = 0; i < M; i++)
{
int u, v;
cin >> u >> v;
graph[u].push_back(v);
graph[v].push_back(u); // 양방향 그래프일때만 push
}
DFS(); // DFS로 탐색 시 탐색순서 출력
cout << endl;
BFS(); // BFS로 탐색 시 탐색순서 출력
return 0;
}그래프의 정점 번호가 1부터 N 까지 이므로,
전역으로 선언한 2차원 벡터 graph의 크기를 N+1로 설정했다.
이는 0번을 버리고 1~N번 까지의 인덱스를 쓰기 위해서이다.
이후 for 문을 돌며 정점 u와 v가 서로 연결돼있다는 정보를 받는데,
이 때 graph[u]에 v를 push 해 줌으로써 u와 v가 연결되어 있음을 저장한다.
문제에서의 그래프는 양방향 그래프이므로, graph[v]에도 u를 push 해 준다.
여기까지의 과정이 바로 이 그림까지 그려진 것이다.
DFS 탐색 과정
void DFS() {
vector<bool> visited; // 방문여부 저장 벡터
visited.resize(N + 1, false); // 아직 모든 정점을 방문 안했어요
stack<int> s;
s.push(V); // 시작정점을 스택에 push
while (!s.empty()) { // 스택이 빌 때까지..
int curr = s.top(); // 지금 스택의 top 원소를 curr에 저장
s.pop(); // 그걸 스택에서 삭제!
if (visited[curr] == false) { // 방문 안한 정점이면?
visited[curr] = true; // 방문했다고 표시하고
cout << curr << " "; // 출력
sort(graph[curr].begin(), graph[curr].end());
// 인접 정점을 오름차순 정렬
for (int i = graph[curr].size() - 1; i >= 0 ; i--)
// for문을 거꾸로 돌면서!
{
int k = graph[curr][i];
if (visited[k] == false) { // 방문 안한 정점을
s.push(k); // 스택에 push
}
}
}
}
}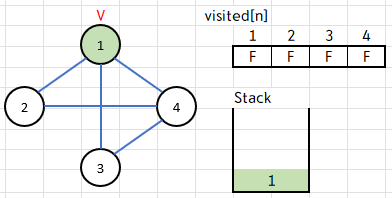
우선 시작 정점 V를 스택에 push!
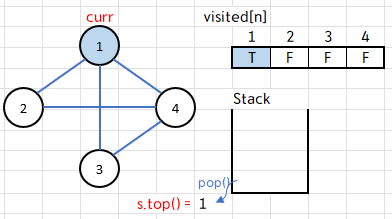
스택의 top 원소가 1이니 이 값을 curr에 저장하고, 스택에서 pop 해준다.
이후 visited[1]==false 이므로 if 조건문을 실행!
visited[1]=true 로 1번 정점을 방문했다고 표시하고, 1을 출력한다.
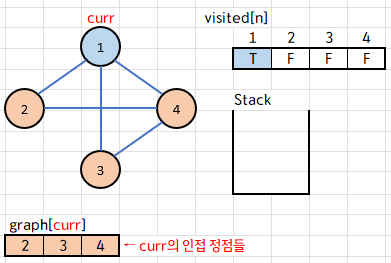
1에 인접한 정점 정보는 모두 아까 만든 2차원 벡터 graph[1] 에 저장되어 있다.
graph[1] 에는 {2, 3, 4}가 들어있는데, 이를 오름차순 정렬해 주고,
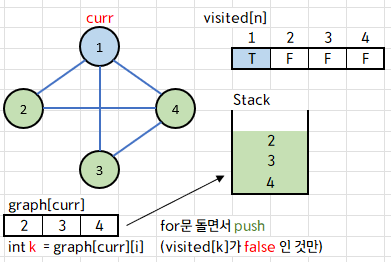
for 문을 거꾸로 돌면서 스택에 push 해준다.
거꾸로 넣어주는 이유는 높은 정점부터 스택에 push해야 제일 낮은 정점이 먼저 pop 될 수 있기 때문!
이 문제는 인접한 정점이 여러 개라면 낮은 숫자의 정점을 먼저 방문한다는 것을 잊지 말자.
물론 정렬할 때 내림차순으로 정렬하고 for문을 그냥 돌아도 될 듯..
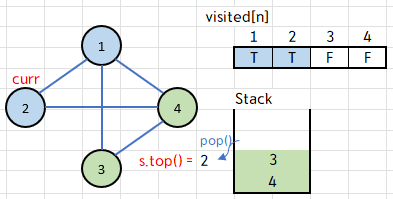
while 문의 새 루프를 돌 차례이다.
요번에는 스택의 top이 2 였으니, curr=2를 저장하고 스택에서 2를 pop 한다.
또한 visited[2]==false 였으므로 if 조건문을 실행하여 visited[2]=true로 바꿔주고 2를 출력!
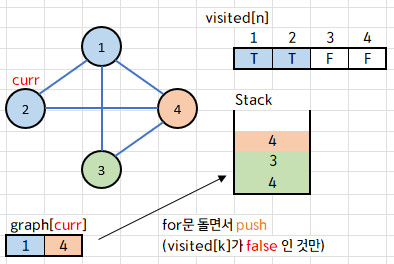
마찬가지로 2에 인접한 정점인 graph[2]={1, 4} 에서,
1번은 이미 방문했으므로 visited[4]==false인 4번 정점만 스택에 push 한다.
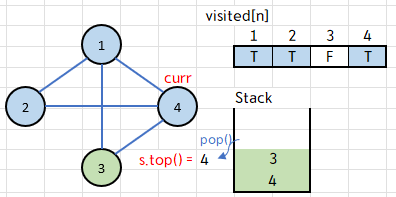
그 다음 while 루프에서도 스택의 top인 4를 curr에 저장, pop 해주고
visited[4]==false 이므로 if 조건문을 실행하여 true로 바꿔주고 4를 출력한다.
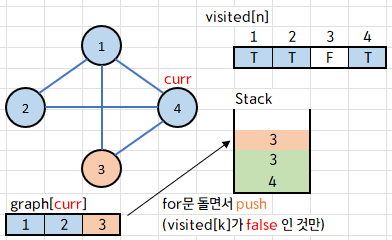
4에 인접한 정점 {1, 2, 3} 에서, 아직 방문하지 않은 3번 정점만 스택에 push해 준다.
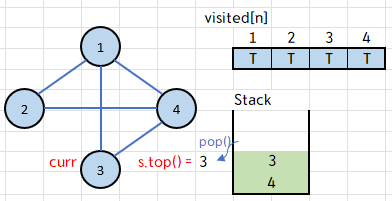
새 while 루프로 돌아와, 스택의 top인 3을 curr에 저장하고 pop,
visited[3]==false 이므로 if 조건문을 실행하여 true로 바꿔주고 3을 출력!
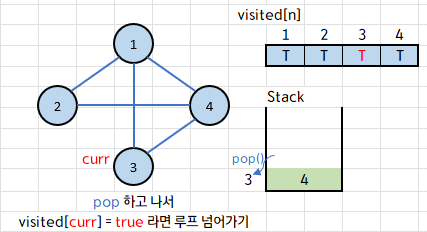
또 다음 루프에서도 스택의 top이 3이니 이 값을 curr에 저장하고 스택에서 pop 해준다.
이 때, visited[3]==true 이므로 if 조건문을 실행하지 않고 다음 루프로 넘어간다.
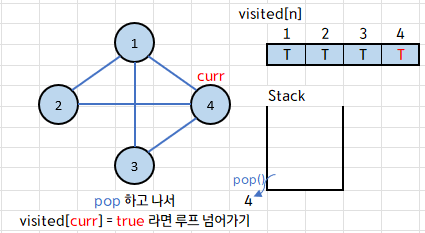
스택에 남은 4 또한 마찬가지로 pop만 해 주고 조건문을 실행하지 않는다.
이렇게 스택이 비게 되면 while(!s.empty) 조건에 의하여 반복문을 종료, DFS() 함수가 끝나게 된다.
이 과정에서 우리는 1, 2, 4, 3 순서로 탐색하였고, 출력까지 완료하였다.
BFS 탐색 과정
void BFS() {
vector<bool> visited;
visited.resize(N + 1, false);
queue<int> q;
q.push(V);
while (!q.empty()) {
int curr = q.front();
q.pop();
if (visited[curr] == false) {
visited[curr] = true;
cout << curr << " ";
sort(graph[curr].begin(), graph[curr].end());
for (int i = 0; i < graph[curr].size(); i++)
{
int k = graph[curr][i];
if (visited[k] == false) {
q.push(k);
}
}
}
}
}BFS도 DFS와 비슷한 구조이나, 이번엔 큐를 사용한다.
스택에서는 제일 마지막에 쌓은 원소가 top에 위치하게 되는데, 큐는 스택과 달리 선입선출 구조이기 때문에 제일 먼저 들어온 원소가 front에 위치하므로 무조건 먼저 나갈 수 있게 된다.
