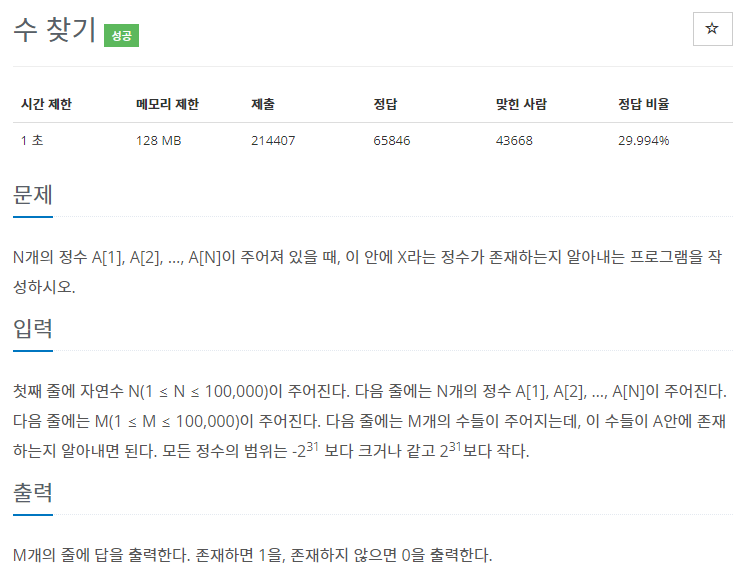
문제 해석
N개의 정수가 담긴 배열 A를 입력받고, M개의 정수를 입력하였을 때,
해당 정수가 A 안에 존재하면 1, 존재하지 않으면 0을 출력하는 문제이다.
입력이 아래와 같은 케이스를 살펴보면,
5
4 1 5 2 3
5
1 3 7 9 5
N=5, A=[4, 1, 5, 2, 3], M=5
그리고 M만큼의 정수 [1, 3, 7, 9, 5] 를 입력하였다.
1, 3, 5는 A 안에 존재하므로 1을 출력하고, 나머지는 존재하지 않아 0을 출력하기에 출력은 다음과 같다.
1
1
0
0
1
시행착오
처음에는 이분탐색으로 풀지 않고 정말 간단하게 벡터의 멤버 함수인 find를 사용하였다.
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int checkout(int s, vector<int> A) {
if (find(A.begin(), A.end(), s) == A.end())
return 0;
else return 1;
}
int main() {
int N, M;
cin >> N;
vector<int> A(N);
for (int i = 0; i < N; i++)
{
cin >> A[i];
}
cin >> M;
int s;
for (int i = 0; i < M; i++)
{
cin >> s;
cout << checkout(s, A) << endl;
}
return 0;
}벡터 A의 값을 입력받고, 값을 확인하려는 M개의 정수 s를 입력받아
checkout 함수에서 find를 사용하여 값이 있다면 1, 없다면 0을 출력하도록 하였다.
그러나 시간초과가 발생하였고, 그제서야 아래 문제 분류에서 이분 탐색이 써져있는 것을 보았다 🤯
참고로 vector의 멤버 함수 find는 다음과 같이 사용할 수 있다.
find(A.begin(), A.end(), s);
// find(찾으려는 범위의 시작 iterator, 끝 iterator, 찾으려는 값);
// A.end()를 반환한다면 해당 범위에서 s를 찾지 못한 것!
find 함수는 <vector> 라이브러리에서 사용 가능하며, BOJ에 코드를 제출하기 위해서는 <algorithm> 라이브러리까지 추가해야 한다.
시행착오 2트
어쨌거나 그 다음으로는 재귀를 활용하여 이분탐색으로 코드를 구현해 보았다.
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int binarySearch(vector<int>& A, int key) {
int N = A.size();
int pivot = N / 2;
if (N == 0) return 0;
if (A[pivot] == key) {
return 1;
}
else if (A[pivot] > key) {
vector<int> slice(A.begin(), A.begin() + pivot);
return binarySearch(slice, key);
}
else if (A[pivot] < key) {
vector<int> slice(A.begin() + pivot + 1, A.end());
return binarySearch(slice, key);
}
}
int main() {
ios_base::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
int N, M;
cin >> N;
vector<int> A(N);
for (int i = 0; i < N; i++)
{
cin >> A[i];
}
sort(A.begin(), A.end());
cin >> M;
int key;
for (int i = 0; i < M; i++)
{
cin >> key;
cout << binarySearch(A, key) << endl;
}
return 0;
}우선 A 벡터를 오름차순으로 정렬하기 위해 sort 함수를 사용하였다.
sort 함수는 C++ STL에서 지원하는 함수로, 퀵 정렬을 기반으로 O(nlogn)의 시간 복잡도를 보장해주는 아주 좋은 정렬 함수이며 <algorithm> 라이브러리를 include 하여 사용할 수 있다.
binarySearch 함수는 오름차순으로 정렬된 벡터 A의 중간 인덱스를 pivot으로 설정하여, 확인하려는 정수인 key가 A[pivot]과 동일하면 1을 리턴하고, A[pivot]보다 작으면(크면) 그보다 큰(작은) 값을 제외하고 새로 만든 벡터인 slice를 생성하여 재귀호출한다.
그런데 이러한 재귀 방식 역시, 재귀를 할 때마다 새로운 벡터 slice를 만드므로 기존의 A 벡터의 길이가 굉장히 길다면 많은 메모리를 차지하게 된다. 사실 시간복잡도로는 아래의 반복문 이분탐색과 비슷하지만, 백준에 해당 코드를 제출하니 시간 초과를 겪게 되었다.
그래서 어떻게 했는데
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
vector<int> A;
int binarySearch(int key) {
int end = A.size() - 1;
int begin = 0;
while (begin <= end) {
int pivot = begin + (end - begin) / 2;
if (A[pivot] == key) return 1;
else if (A[pivot] < key) {
begin = pivot + 1;
}
else if (A[pivot] > key) {
end = pivot - 1;
}
}
return 0;
}
int main() {
ios_base::sync_with_stdio(false);
cin.tie(NULL);
cout.tie(NULL);
int N, M;
cin >> N;
A.resize(N);
for (int i = 0; i < N; i++)
{
cin >> A[i];
}
sort(A.begin(), A.end());
cin >> M;
int key;
for (int i = 0; i < M; i++)
{
cin >> key;
cout << binarySearch(key) << '\n';
}
return 0;
}따라서 binarySearch 함수의 재귀 부분을 반복문으로 대체하였다.
시작 인덱스 begin을 0, 끝 인덱스 end를 A.size()-1, pivot 인덱스를 그 중간값으로 설정한 뒤,
위와 같이 A[pivot]이 key값과 동일하면 1을 리턴하고, A[pivot]이 key보다 작으면(크면) begin을 pivot의 다음(이전) 인덱스로 설정하여 다시 반복문을 돌린다.
또한 조금이라도 시간을 단축하기 위해 벡터 A를 전역변수로 설정하고, 출력문의 endl을 '\n'으로 바꾸어 줄바꿈에 걸리는 시간을 줄여주었다.
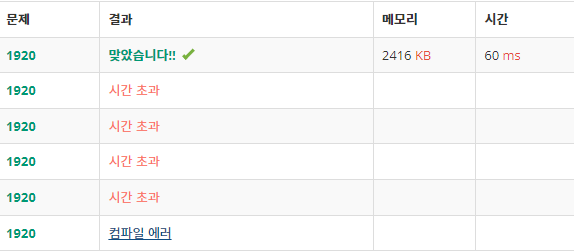
뭐 결국 그래서 어떻게 풀기는 했다!
