들어가기에 앞서... Index란?
인터넷이 없던 시절의 백과사전을 생각해보세요.
맨 뒷장에는 어김없이 ㄱㄴㄷ순의 단어들이 나열되어있는 '색인'이 있습니다.
ㄱㄴㄷ를 따라 쭉 내려가다 보면 원하는 단어와 함께 자세한 내용이 담긴 페이지를 찾게 됩니다.
수백장의 백과사전에서 원하는 정보를 찾아내는 것 치고는 꽤 빠른 검색 방법이었습니다.
MongoDB에서의 인덱스도 마찬가지 → 최적의 알고리즘을 이용해 검색 가능.
MongoDB Index 기본전략에 대하여
- Selectivity
영어 단어장을 만들고 있는데 영단어를 쉽게 검색하기 위해 색인을 만들었습니다.
고민끝에 '동사', '명사'로 구분지어 만들기로 했습니다. 총 1000자의 단어 중 동사가 300자, 명사가 700자였습니다. 'teacher'를 검색하기 위해 700자의 명사를 처음부터 하나씩 찾기 시작합니다.
→ 무엇이 문제일까? → 색인이 너무 큰 범위로 만들어짐. 즉, Selectivity가 떨어진다고 이야기함. → Slow query 발생
- 따라서 가급적 촘촘하게 인덱스를 작성해서 Selectivity를 높여야 할 필요성이 있음.
현재의 소셜 모니터링의 Slow Query
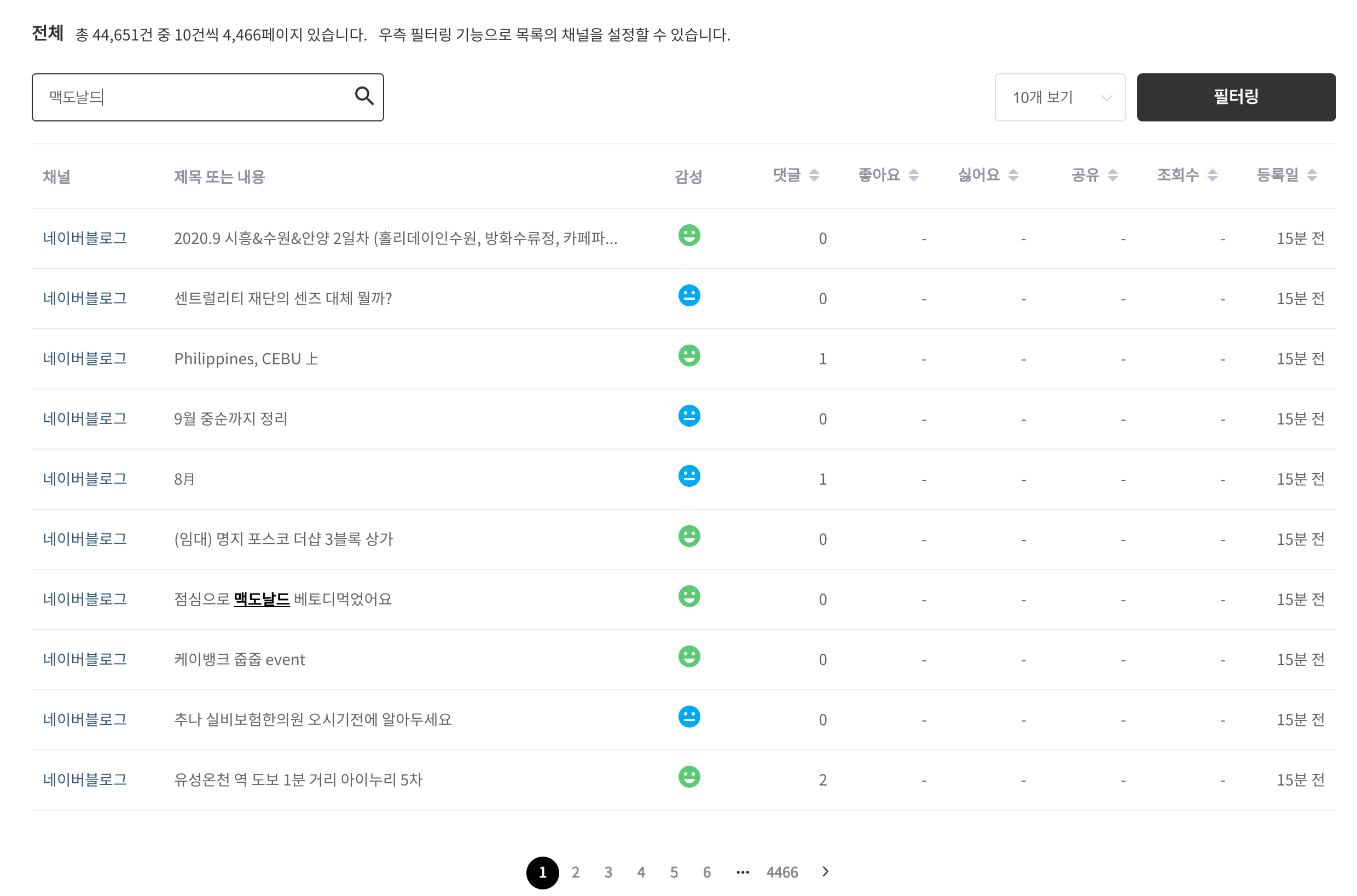
→ 수집 데이터 목록에서 사용자가 특정 단어를 검색하였을 때 너무 느린 것을 확인할 수 있습니다. (데이터가 많을 시)
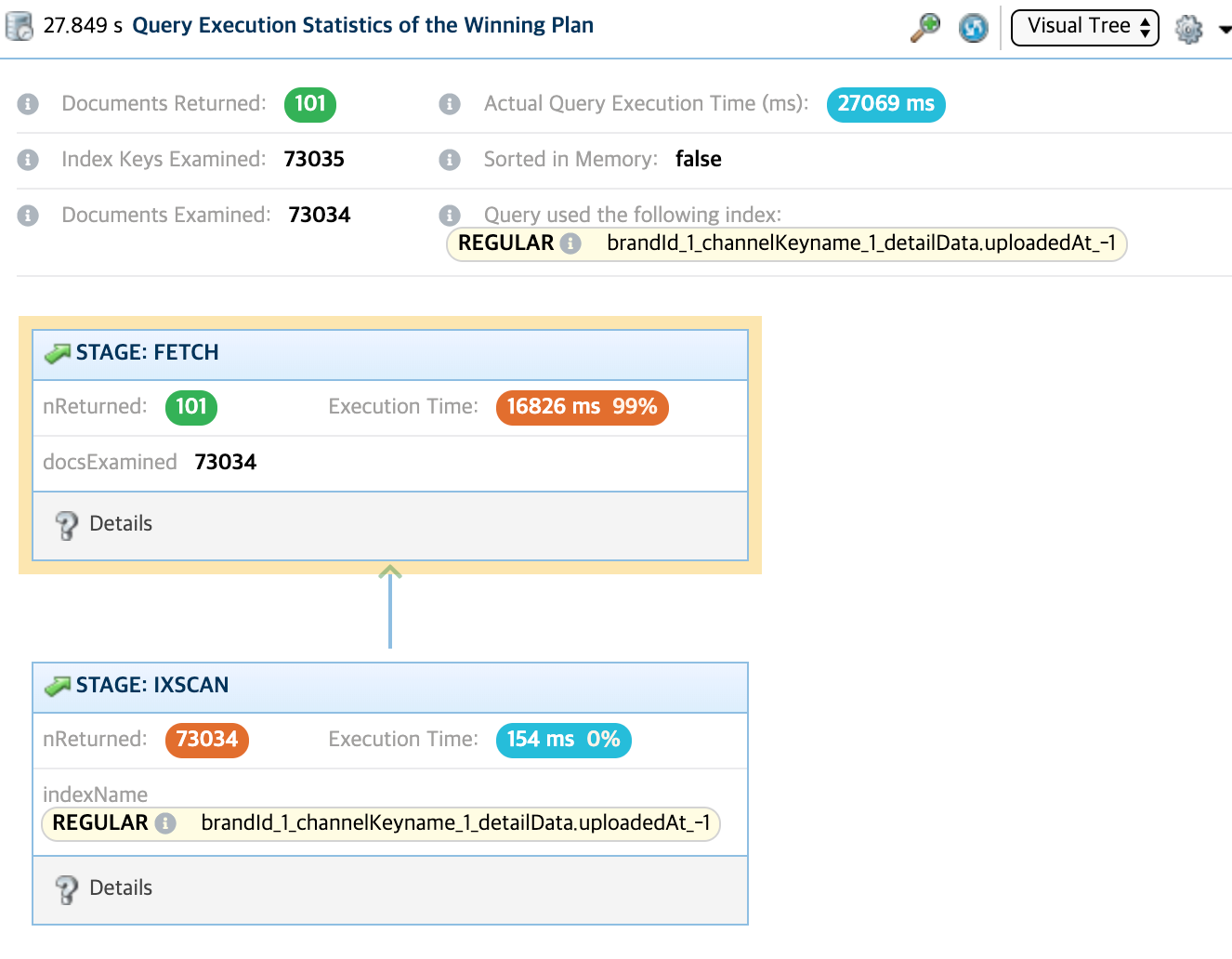
→ 위의 사진은 전체 데이터를 기준으로 데이터를 가져온다고 보았을 때 쿼리를 날린 상황입니다.
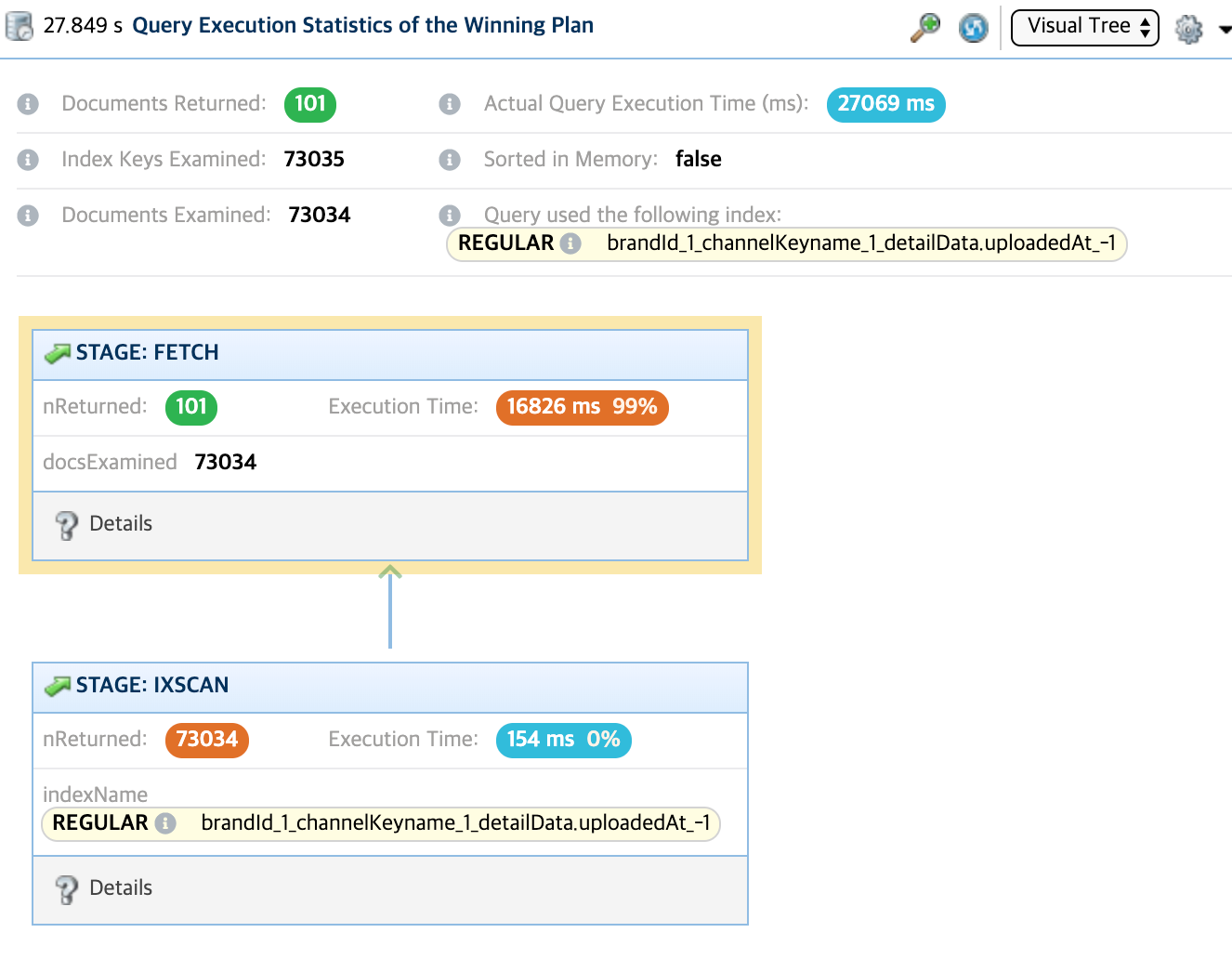
"밴쿠버" 라는 단어를 검색하였을 때, 검색되는 문서들은 총 101개라는 것을 확인할 수가 있습니다.
그러나 index를 사용하였는데도 불구하고 73034개의 문서들을 뒤져서 101개를 찾았다는 것을 확인할 수가 있습니다. 즉, Selectivity가 상당히 안좋은 상황이라고 볼 수 있습니다. 27초나 걸렸죠..
분명 index를 걸었는데?
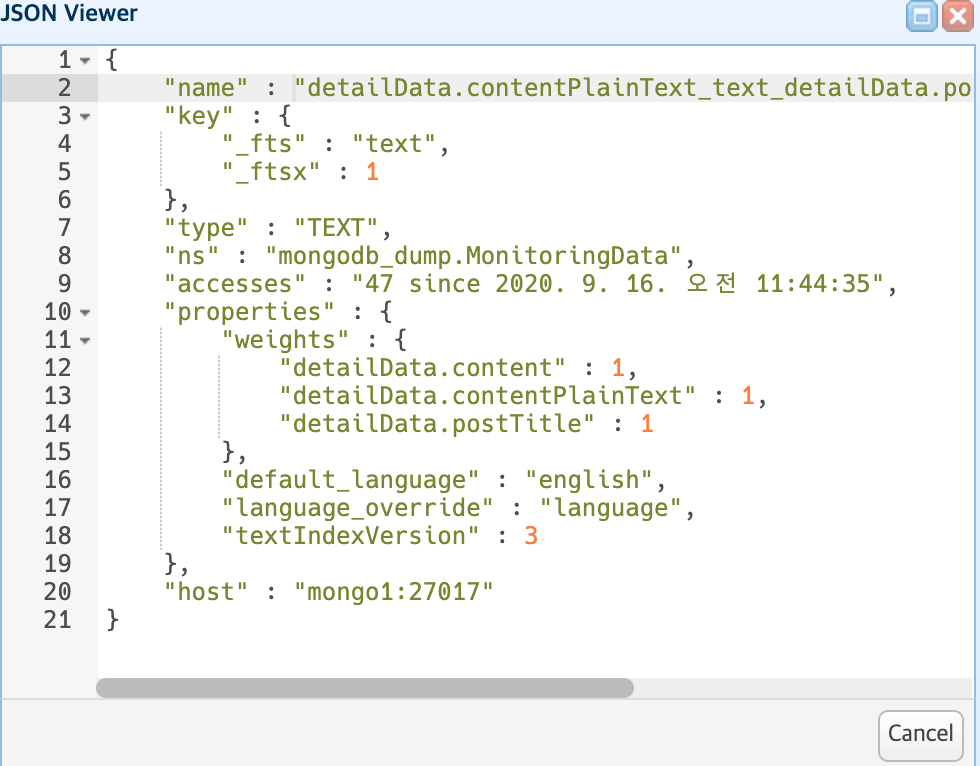
우선 위의 사진으로 내용과 제목에 text index를 걸어놓은 것을 확인할 수가 있습니다. 이렇게 되면 전체 문서가 아닌 "밴쿠버" 라는 단어가 들어간 문서만 찾게 되는 거죠.
근데 왜 아까 7만개의 문서나 뒤진걸까요?
해결 방안??
- Text Index를 걸리게 만들어야 합니다.

위에서 미리 지정해놓은 text index가 있기 때문에 regex대신에 위의 text쿼리를 사용하게 된다면
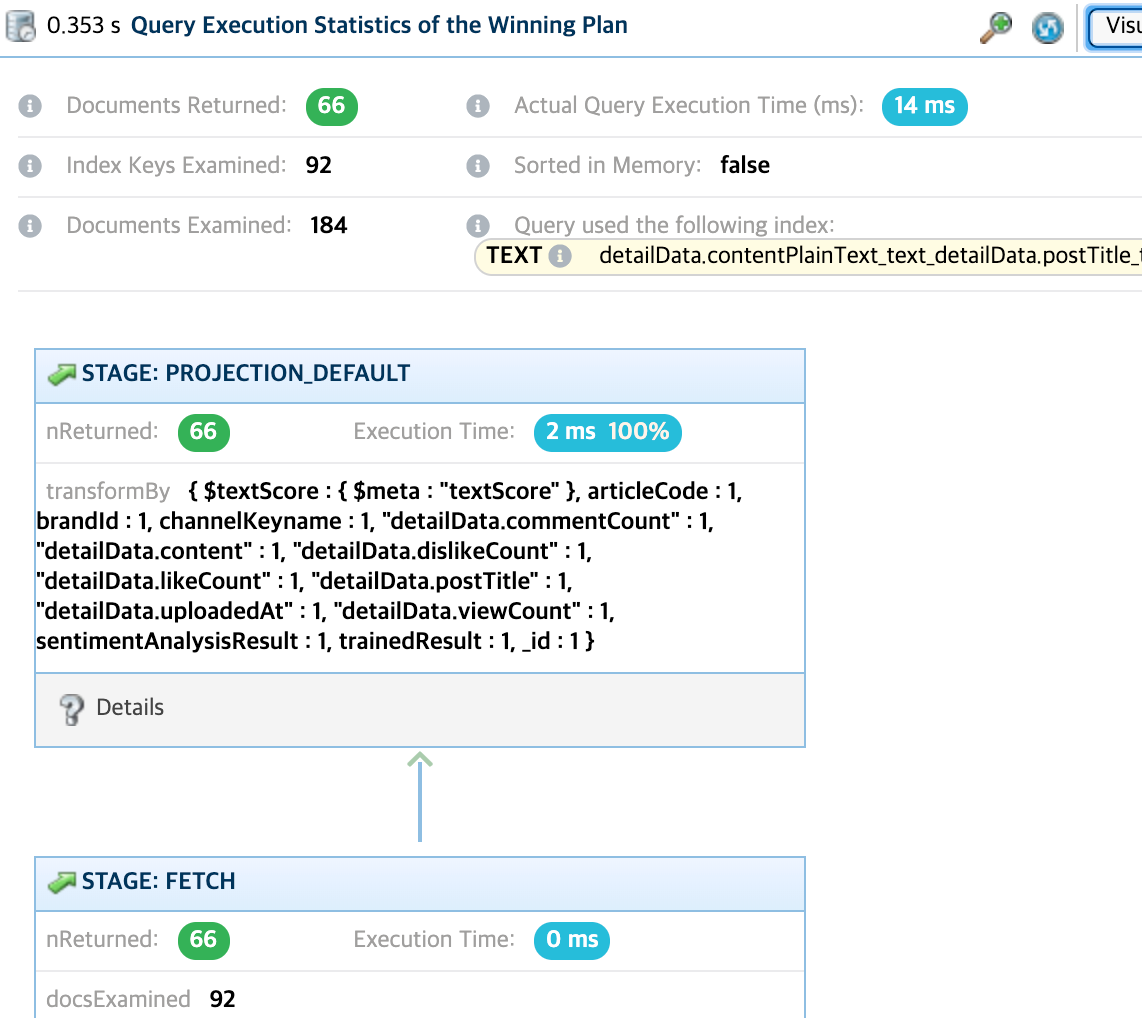
아래와 같은 결과가 나오게 됩니다.
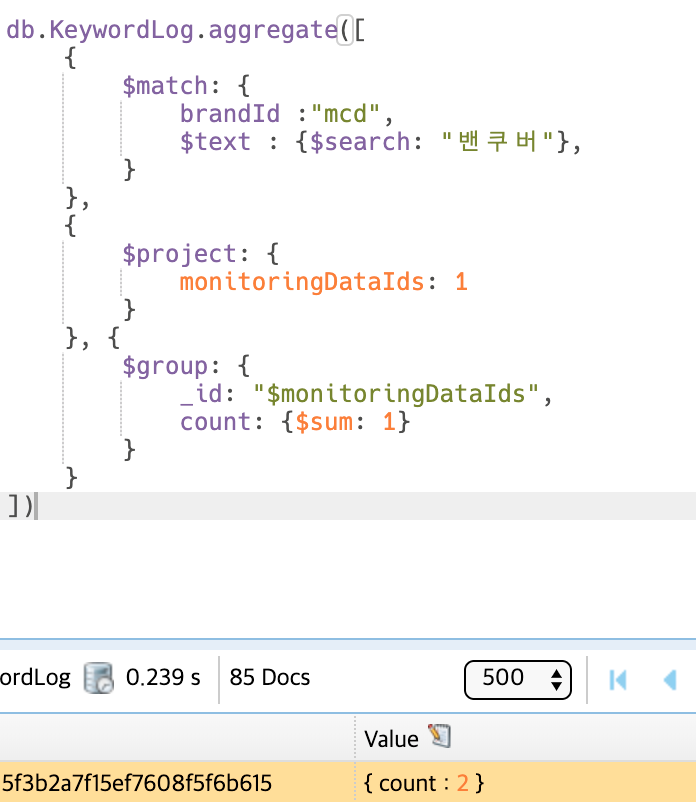
184개의 문서를 찾고 그 중 66개의 데이터를 찾아 냈습니다. 심지어 시간도 0.3초 밖에 걸리지 않았습니다.
검색 결과가 다르다? 문제점 발생
그런데 regex로 찾았을 때는 101개 였는데 왜 66개밖에 나오지 않았을까요?
regex로 찾게 되면 "밴쿠버" 가 "포함"된 모든 문서를 찾아내게 됩니다.
그러나 text index를 이용해 찾게 되면 "밴쿠버"라는 단어와 정확하게 일치하는 단어가 들어간 모든 문서를 찾게 됩니다.
예를 들어
- 밴쿠버에 갔다.
- 좋네밴쿠버
- 밴쿠버 좋네
라는 세가지 문장이 있다고 친다면,
regex는 세가지 문장을 다 찾아내어 문서 3개를 다 보여주지만,
text index로 찾게 되면 "밴쿠버 좋네"라는 문장 하나만 찾아서 보여줍니다.
두번째 해결방안? Keyword에서 찾아보는건..?
keyword는 다 명사 형태로 쪼개져 있기때문에 keyword에 text index를 등록하고 text쿼리를 사용하여 해당 문서를 찾게되면 잘 찾을 수 있을 것 같음.
test 결과가 아래의 사진.
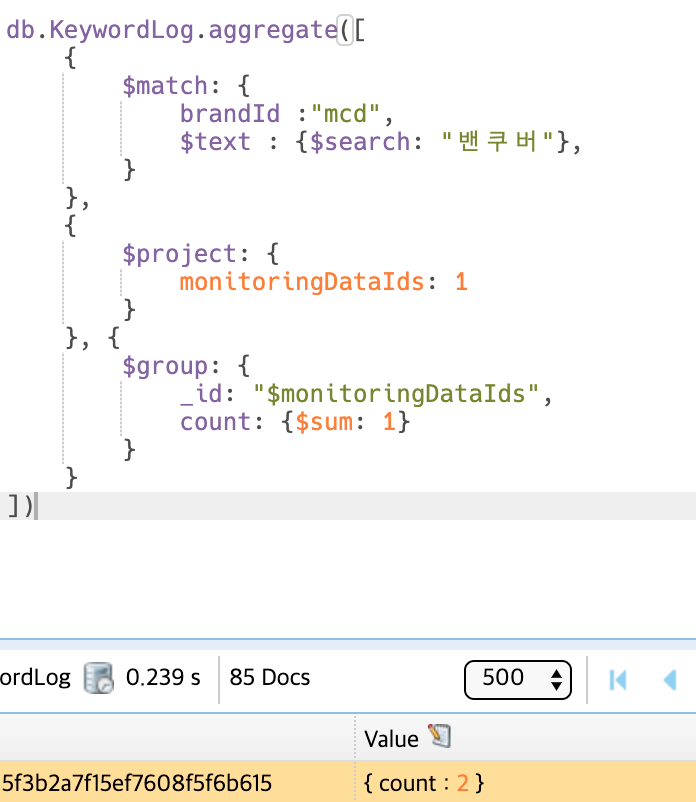
keyword에는 각각 monitoringDataId가 존재하는데 keyword들 중 그 id들이 같은 것끼리 묶으면 해당 키워드의 문서의 갯수가 나오게 됩니다.
이게 101개면 이걸로 해결할 수 있을 것임.
But 갯수가 또 맞지 않음. 85개가 나옴.
→ 키워드는 monitoringData에서 형태소 분석을 통해 추출되는데 형태소 분석에서 "밴쿠버"라는 단어를 인식하지 못하는 문서 경우가 16개 정도 있던 것 같음.

혹시 query plan 확인하신 툴이 뭔지 알수있을까요???