
사건의 발달.
seq2seq는 인코더의 마지막 hidden state만을 Decoder에 사용함.
즉, 마지막 히든 스테이트만을 사용하고, 나머지 히든 스테이트는 사용하지않는다.
그래서.
Attention은 바로 이 사용되지 않은 hidden state를 이용한 아이디어임.
어텐션의 기본 아이디어, decoder의 출력결과를 예측하는 매 시점마다
encoder의 hidden state를 다시한번 참고하고,
이 참고해야 하는 비율을 해당 시점에서 예측해야 하는 결과와 연관이 있는 부분을 판단하여 좀더 집중 (attention) 이라고 부름.
어텐션은 인코더의 hidden state를 다시한번 참고 한다고 함.
-
이때 어느 인코더의 hidden state를 얼마나 참고할지를 결정.
어텐션 스코어로 판단하여, 현재 예측에 필요한 점수
어텐션 스코어를 구하기 위해,
현 시점의 디코더의 hidden state 와 인코더의 모든 hidden state를
각각 내적을 수행함 → 백터 내적의 결과는 스칼라가 나옴.
이 스칼라값을 Soft max에 넣어 어텐션 분포를 구함.
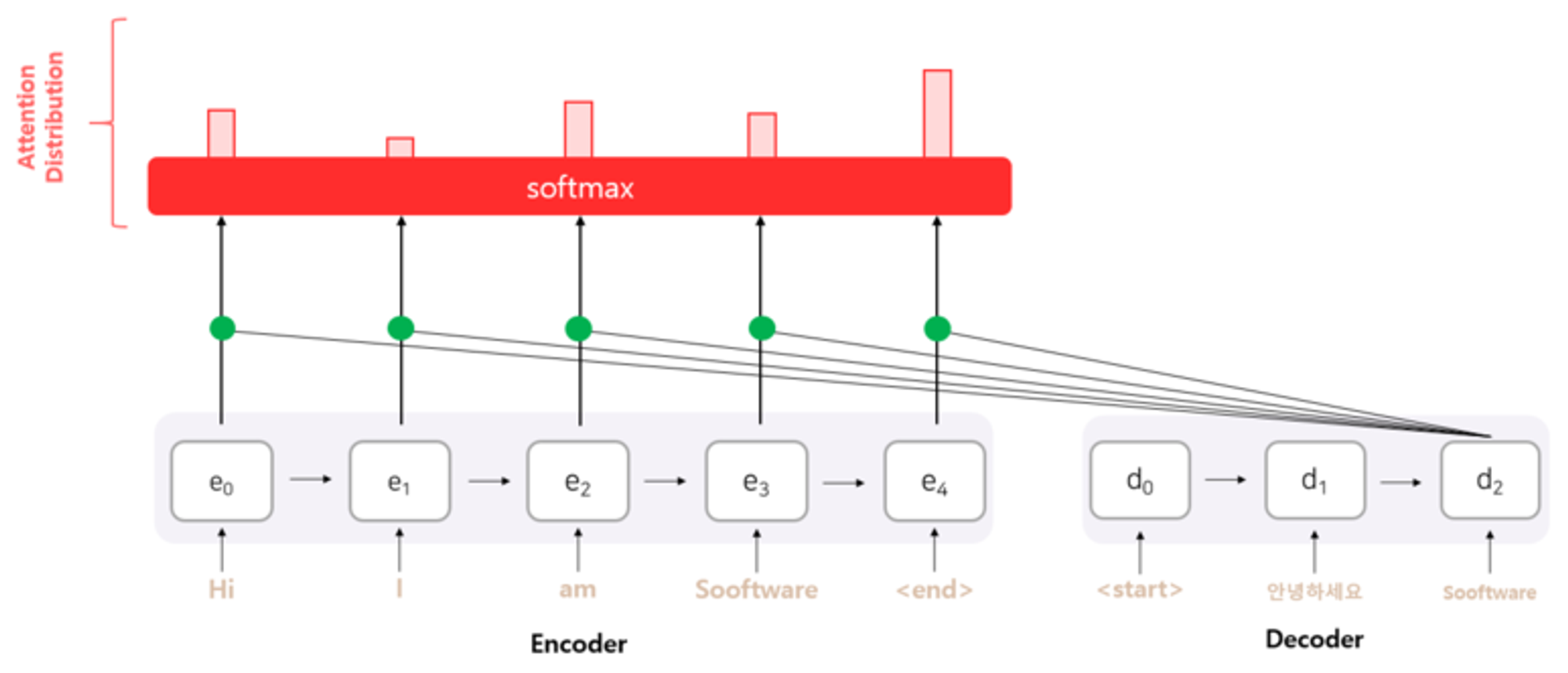
( Attention distribution )
이렇게 구한 어텐션 분포는 각 인코더 hidden state의 중요도라고 볼 수 있다.
EX) e0 : 10%, e1 : 15%, e2 : 20% …. ← soft max 에서 나온값
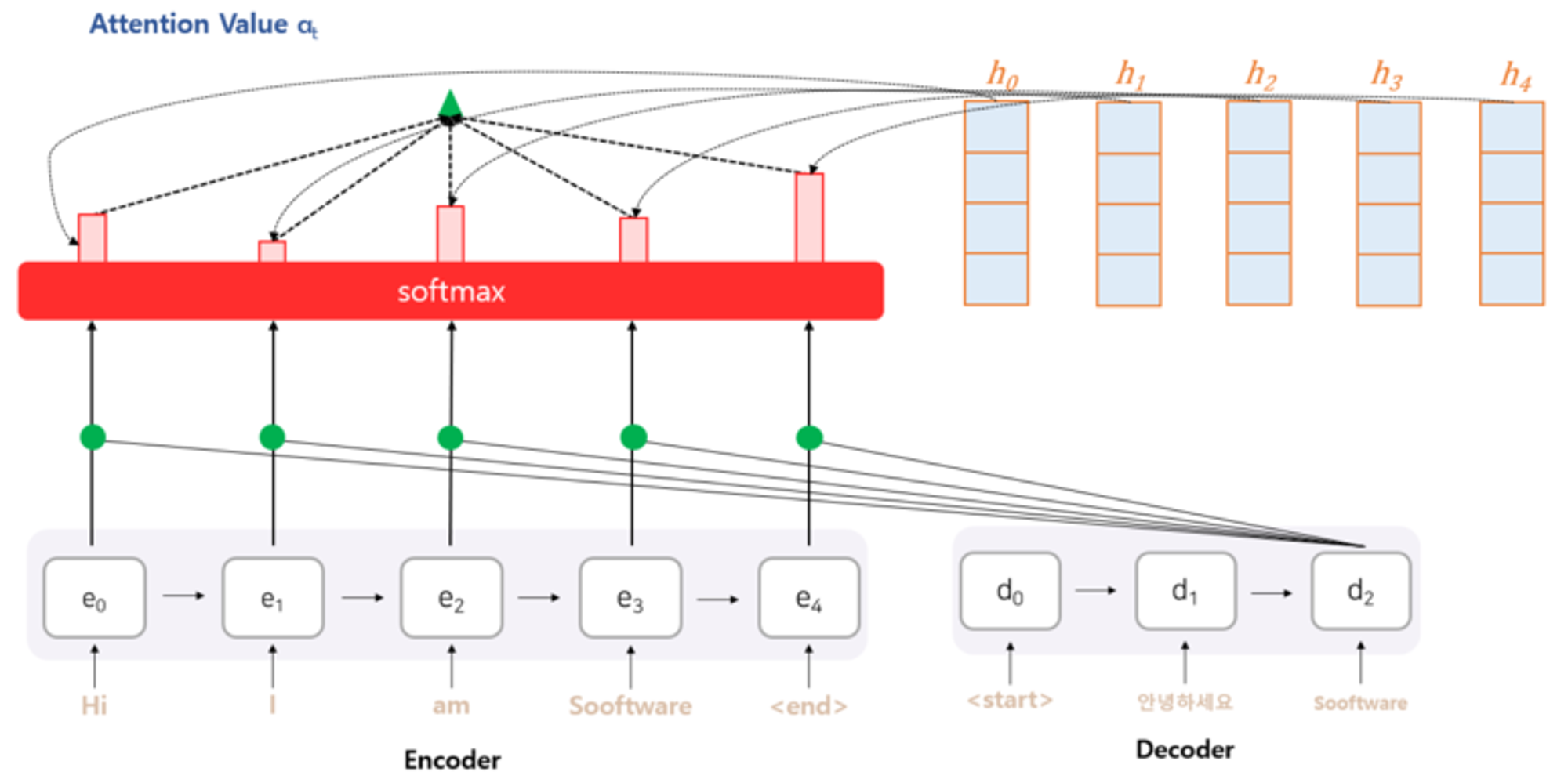
soft max를 통해 얻은 어텐션 분포를 각 인코더 hidden state 값에 곱해줌
Attention distribution X Encoder hidden state
( Brodcasting )
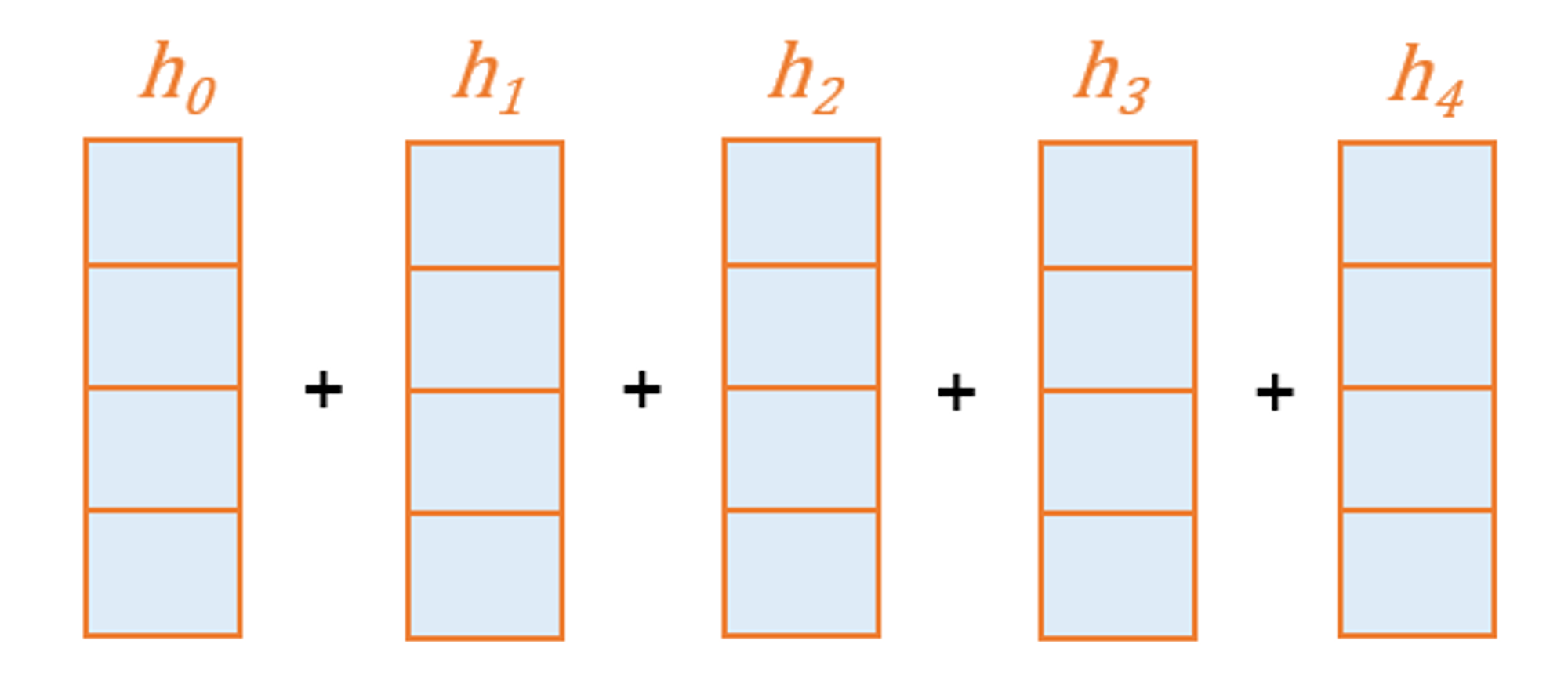
이후 각 어텐션 분포와의 곱을 통해 얻어진 hidden state들을 전부 더해줌
( element - wise )
이렇게 얻은 벡터를 인코더의 문맥을 포함하고 있다하여
컨텍스트 벡터라고 함. —> 기본적인 seq2seq 에서 인코더의 마지막 hidden state 를 부르는 것과 와는 대조가됨.
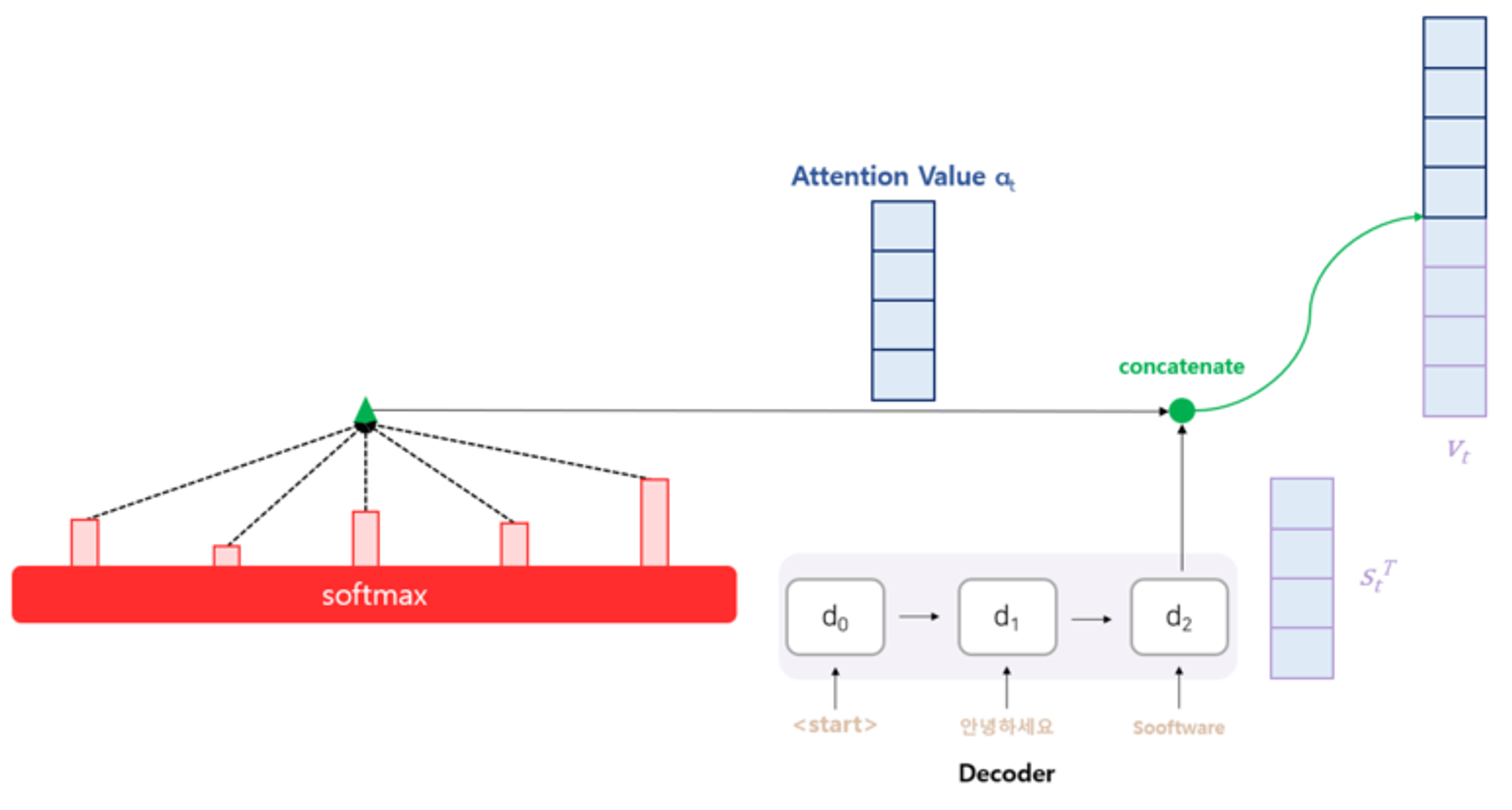
컨텍스트 벡터 와 현 시점의 디코더 셀의 hidden state와 연결
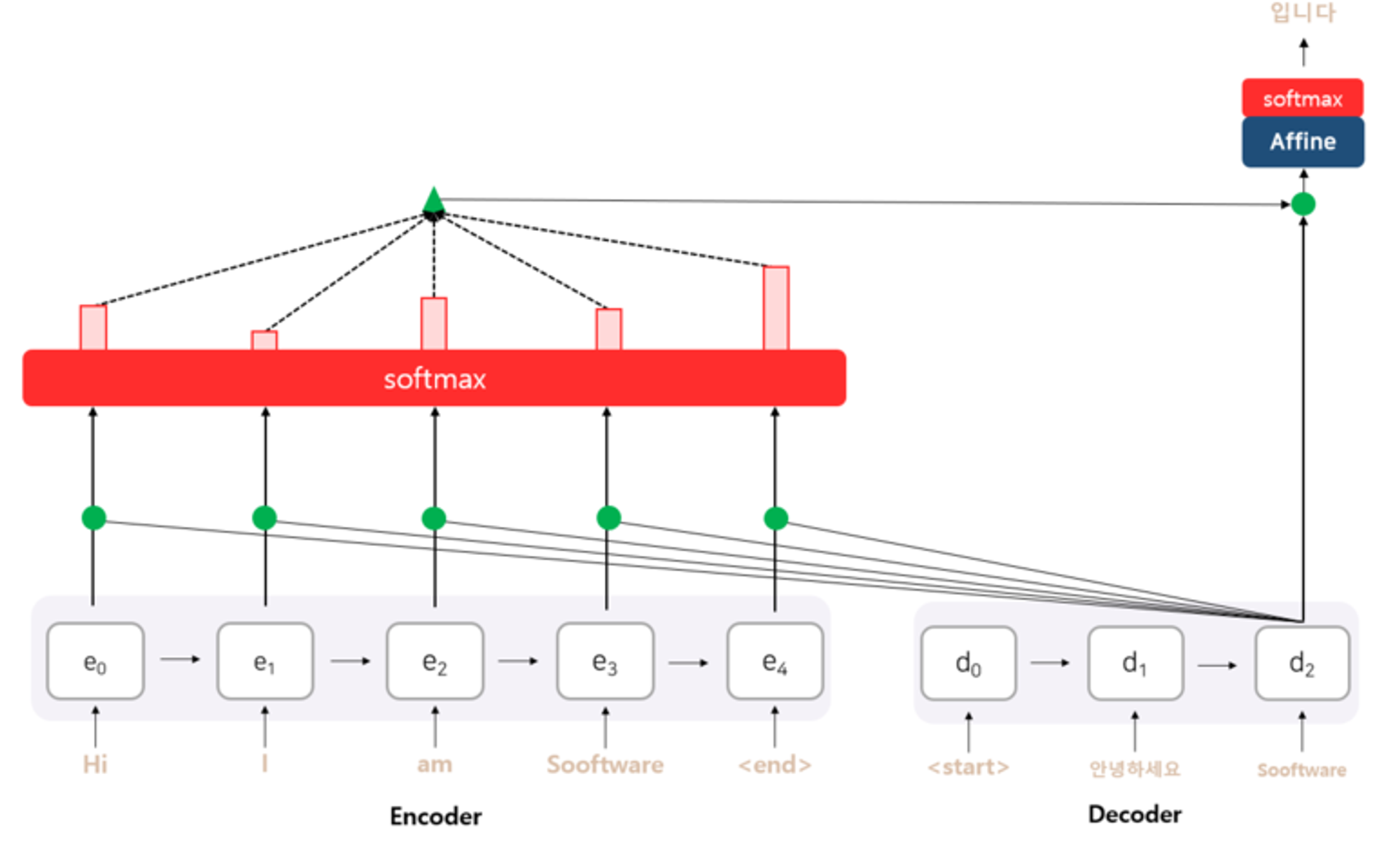
이렇게 구한 벡터를 이용해서 최종 예측값을 구함.
이것이 가장 간단한 Dot product Attention 의 설명임
