작은 단위로 여러개로 분할하여, 각각 처리한뒤 모으기 - 분산 프로그래밍
What?
Map Reduce는 여러 노드에 작업을 분배하는 방법으로, 각 노드에서 수행되는 데이터는 가능한 경우 해당 노드에 저장한다는 것이다.
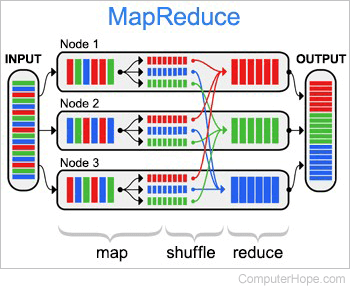
정렬된 데이터를 분산처리(map)하고 이를 다시 합치는(reduce) 과정을 수행한다.
Why?
Map Reduce는 Map Reduce 프로그래밍 모델을 구현하는 Apache Hadoop과 같은 빅 데이터 처리 프레임 워크에 널리 사용한다.
How?
Map Reduce를 사용하기 위해 일반적으로 다음과 같이 수행된다고 한다.
-
데이터 파티셔닝
대규모 데이터 세트를 종종 입력 분할 또는 청크라고 하는 더 작은 하위 집합으로 분할한다.
이러한 하위 집합은 맵 기능에 의해 독립적으로 처리된다. -
지도 기능 (Map)
입력 데이터 하위 집합을 가져와서 처리하여, 중간 key-value 쌍을 생성하는 Map기능을 정의한다. Map기능은 데이터 변환, 필터링 또는 데이터 처리 작업과 관련된 기타 로직을 수행해야 한다.
-
셔플 및 정렬
Map Reduce 프레임워크는 key를 기준으로 중간 key-value 상을 자동으로 섞고 정렬한다.
이 단계는 동일한 key를 가진 데이터가 함께 끝나고, 동일한 감속기에 의해 처리되도록 한다.
-
Reduce
동일한 key를 가진 key-value 쌍 그룹을 취하고 데이터를 집계, 요약 또는 결합하여 최종 출력을 생성하는 Reduce함수를 정의한다.
-
입력 및 출력
Map Reduce 작업의 입력 데이터 소스 및 출력 대상을 지정한다.
이는 HDFS와 같은 분산 파일 시스템일 수 있으며, 출력은 파일 또는 다른 스토리지 시스템에 기록될 수 있다.
-
실행 및 모니터링
실행을 위해 Map Reduce 작업을 클러스터에 제출한다. 프레임 워크는 작업을 노드에 배포하고 실행을 관리한다. 프레임 워크의 모니터링 도구를 통해 작업의 진행 상황과 상태를 모니터링 할 수 있다.
-
반복 프로세스(필요한 경우에만)
반복 알고리즘 또는 다단계 데이터 처리의 경우 한 작업의 출력을 다음 작업의 입력으로 사용하여 Map Reduce 작업을 순서대로 실행할 수 있다.

가치 있는 정보 공유해주셔서 감사합니다.