
해당 글은 naver boostcourse
'모두를 위한 컴퓨터 과학(CS50)' 강의 정리 글입니다.
앞선 WEEK 1,2,3은 기초 문법이기 때문에
WEEK4 부터 정리하고자 합니다.
0. 들어가기 앞서
알고리즘이란 무엇일까?
바로 input을 집어넣어 output을 끄집어내는 방법이다.
(전자공학과에선 아마 시스템이라고 불렀던것 같다)
알고리즘
어떠한 문제를 해결하기 위해 정해진 일련의 절차나 방법을 공식화한 형태로 표현한 것
좋은 알고리즘을 만들고자 한다면
우리가 고려해야할 추가적인 것이 있는데
바로 '효율성'이다.
효율성은 두가지의 기준으로 나타낼 수 있다.
1. 공간복잡도(space complexity)
2. 시간복잡도(time complexity)
이번 강의에서는 알고리즘이 문제를 해결하기 위해
걸리는 시간을 기준으로 '시간복잡도'에 대해 설명한다.
1. 검색 알고리즘

위와 같은 lockers에 1,2,3,4,5,6,7,50 이 랜덤으로
들어있다고 생각해보자, 그리고 50을 찾고싶다.
- 앞부터 순서대로 찾는다. (선형검색,linear search)
- 중앙부터 찾은 뒤 50보다 작으면 왼쪽 50보다 크면 오른쪽으로 간다. (이진검색, binary search)
위의 두 가지 방법이 있을 것이다.
좀 더 나아가서 의사코드로 작성해보자
- 선형검색(linear search)
For i from 0 to n-1 // 처음 locker에서부터 끝까지 반복한다.
if i'th element is 50 //만약 50을 찾았다면
return true //true
return false //못찾았다면 false
- 이진검색(binary search)
if no items // 어디에도 50이 없다면 false
return false
if middle item is 50 // 중간을 찾았는데 50이 나왔다면?
return true //true
else if 50 < middle item //중간을 찾았는데 50보다 크다면
search left half // 왼쪽으로간다.
else if 50 > middle item // 중간을 찾았는데 50보다 작다면?
search right half // 오른쪽으로 간다.당연히 이진검색을 사용하려면 정렬된 배열이 있어야 할 것이다 (아니면 비효율적이니까)
2. 알고리즘 표기법
좋은 알고리즘이란 효율적이어야 한다.
알고리즘이 얼마나 잘 설계되었는지
시간복잡도(time complexity)로 그 기준을 정의한다.
시간복잡도는 다시 세가지로 나뉜다.
- 빅오 표기법 (Big-O)
-> 여기서 O는 "on the order of"의 약자로 "~만큼의 정도로 커지는" 이라는 뜻이다. (실행 시간의 상한) - 빅오메가 표기법 (Big-Omega)
-> 실행시간의 하한이다. - 빅세타 표기법 (Big-theta)
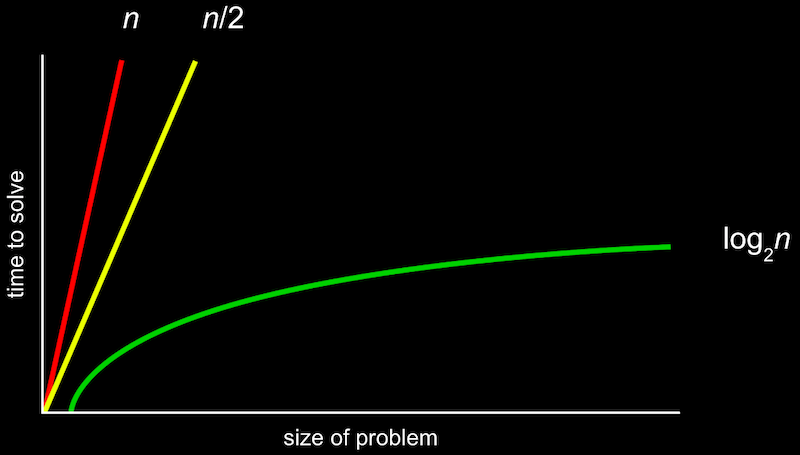
위의 locker에서 50을 찾는과정을 linear search로 생각해보자.
0번째 (우리는 컴퓨터 공학자니까) locker부터 n-1번째 locker까지
최악의 경우 총 n번 확인해야한다. (50이 가장 마지막에 있을 수 있으니까)
위의 빨간색 그래프가 그려진다.
그럼 binary search의 경우는 어떨까? 이다.
탐색하고자 하는 크기를 라고 생각했을 때 과정을 생각해보자.
- 가장 가운데를 탐색한다.
- 크기를 판별한다. (조건문)
- 방향을 정했다면 나머지 절반은 버린다 ()
- 시행을 반복하면 절반씩 버려진다. ( x ...)
k번 반복시,
(만약 반드시 경우가 존재한다면, 아니면 false return)
양변을 넘겨서 계산해주면
위의 그림에서 초록색 그래프가 그려진다.
위의 두 경우는 최악의 경우를 가정한다.
정말 재수가 없어서 찾고 찾고 찾았는데 가장 마지막에
존재하는 case 이다.
이런 경우 시간복잡도 중 빅오 표기법으로 표기한다.
시간복잡도는 정확하게 딱 수치화해서 얼마가 걸린다 라는 표현이 아니다.
마치 우리가 일상에서 "그거 아마 이만큼 클껄?" 라고 말하는 것처럼
대략적인 시간소요를 표기하는 방법이다.
너무나 큰 경우를 가정하기 때문에
, , .. 는 전부 이다.
도 마찬가지다. 으로 표기한다.
반대로, 시간의 하한인 빅 오메가(Big-Omega)를 생각해보면
linear search는 한번에 찾을 수 있을 것이다.
운이 너무좋아서 locker를 열었는데 50이 있는 것이다.
binary search도 마찬가지로 한번에 찾을 수 있다.
생각해보면 그럼 빅 오메가가 1이 아닌경우가 있을 수 있는가?
있다. 알고리즘이 locker의 수를 세야한다면 아무리 좋아도 n개를 세어야 한다.
Big-O와 Big-Omega 중 Big-O가 더 중요하다.
이유는 정렬되어진 값을 다시 빠르게 정렬한다고 좋은 알고리즘인지
파악하기 어렵기 때문이다.
