메서드 이름으로 쿼리 생성
내가 원하는 조건으로 쿼리를 생성하고 싶다면, 어떻게 해야하지

이런식으로 엔티티 매니저가 들어있는 곳에 직접 쿼리를 작성하면 된다.
하지만, 일일이 다 만드는 것도 쉬운 작업이 아니다.
이를 위해 JpaRepository에서는 쿼리를 자동으로 만들어주는 기능이 있다.

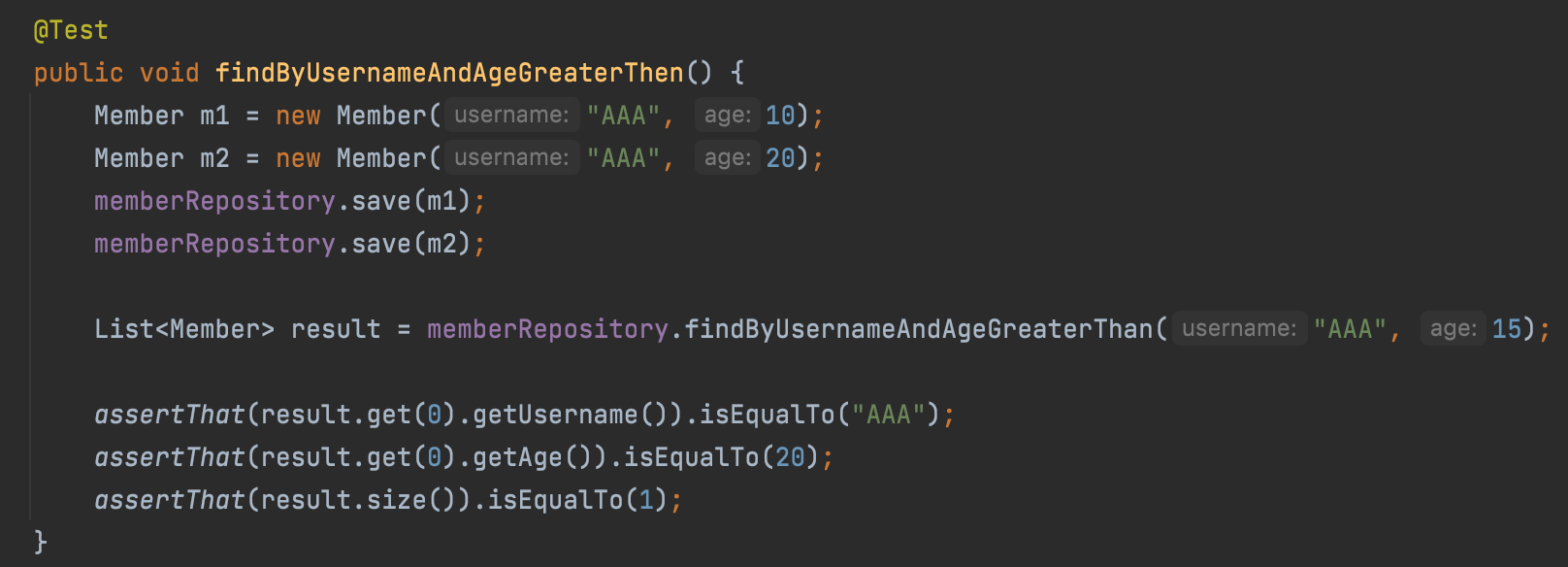
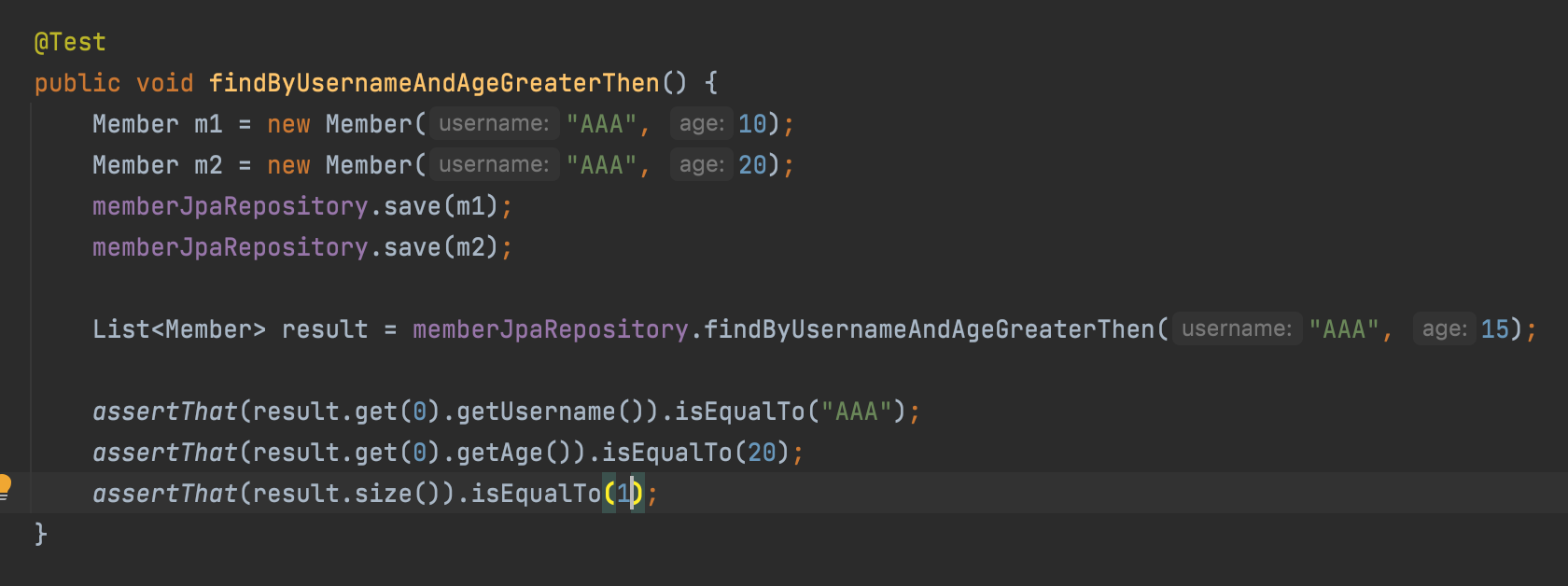
이게 스프링 JpaRepository에서 제공하는 강력한 기능중의 하나이다.
메서드 이름을 통해 쿼리를 만들어준다.
참고로 없는 객체이름을 넣으면 No property Xxx found for type 에러가 나온다.
기능들은 여기에
https://docs.spring.io/spring-data/jpa/docs/current/reference/html/#jpa.query-methods.query-creation
그런데 2개 보다 많은 조건을 넣기 시작하면 이름이 너무 길어지므로,
보통 조건이 2개까지만, 이 기능을 사용하고
그것보다 많은 조건은 또 다른 방법을 사용한다고 한다. 그건 뒤에서
조회: find...By, read...By, query...By, get...By
https://docs.spring.io/spring-data/jpa/docs/current/reference/html/#repositories.query-methods.query-creation
Count: count...By type: long
Exists: exists...By type: boolean
삭제: delete...By, remove...By type: long
Limit: findFirst3, findFirst, findTop, findTop3
https://docs.spring.io/spring-data/jpa/docs/current/reference/html/#repositories.limit-query-result
JPA NamedQuery
실무에서 쓸일은 없음.
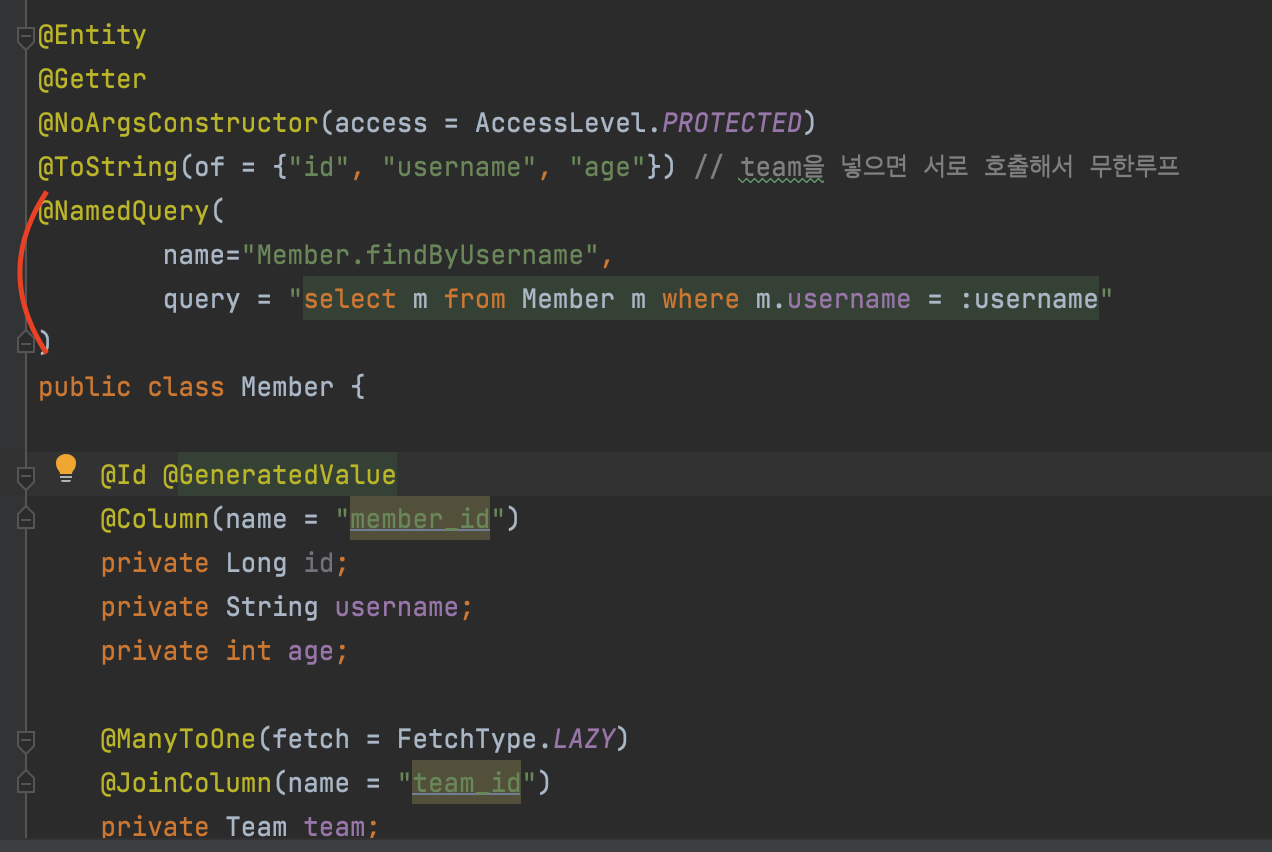
엔티티에서 이렇게 쿼리를 미리 만들어두고, 재활용하는 것이다.
이는 리포지토리와 JPA 리포지토리 둘다 사용하는 방법이 있다.
리포지토리
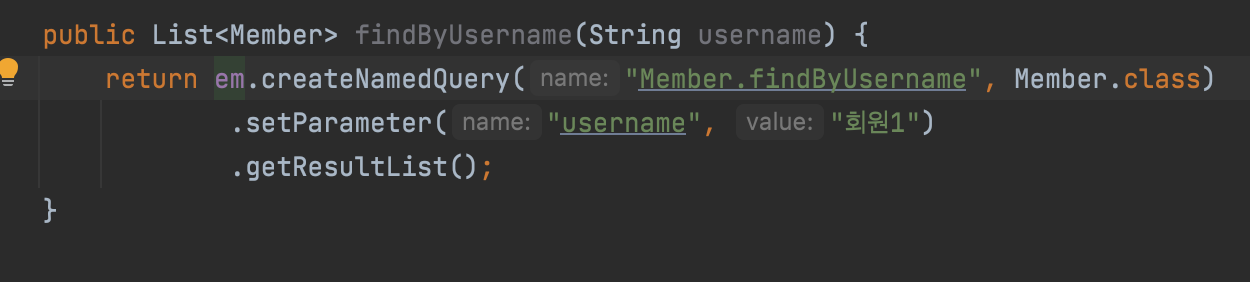
JpaRepository
테스트는 생략했다.
잘 안쓴다. 스프링 JpaRepository 더 막강한 기능을 갖고 있으므로, 잘 안쓴다.
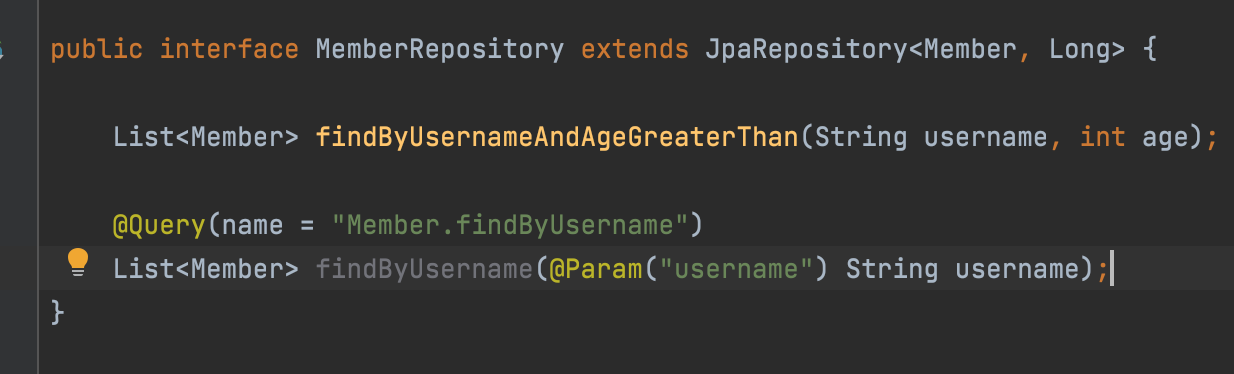
@Query, 리포지토리 메서드에 바로 쿼리를 지정하기
이게 그 막강하다는 기능
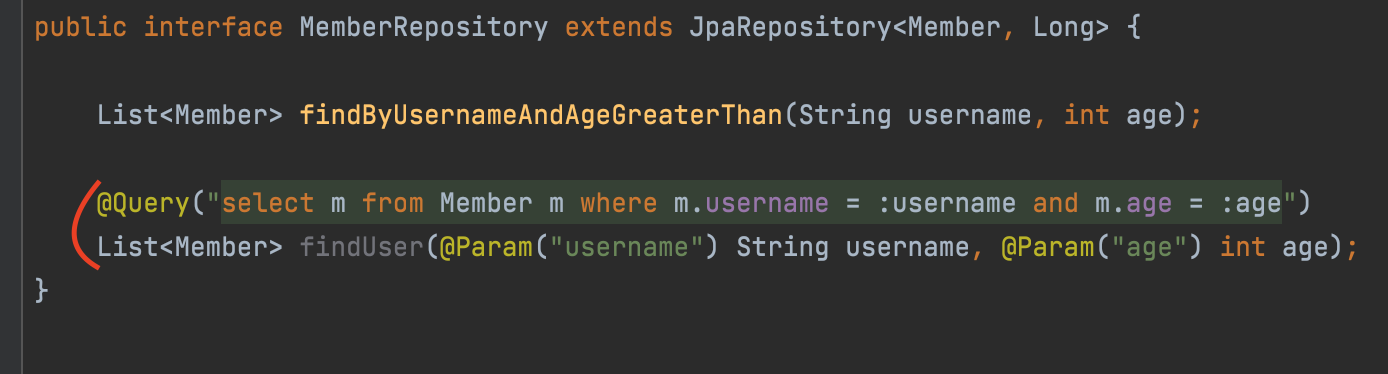
이전에 했던 내용을 이와 같이 한곳에서 전부 처리를 할 수 있다.
이렇게 사용하면 쿼리를 자동으로 생성하게 하기 위해 메서드 이름을 길게 쓸 필요도 없고, 직접 쿼리를 작성할 수 있다는 장점을 가지고 있다.
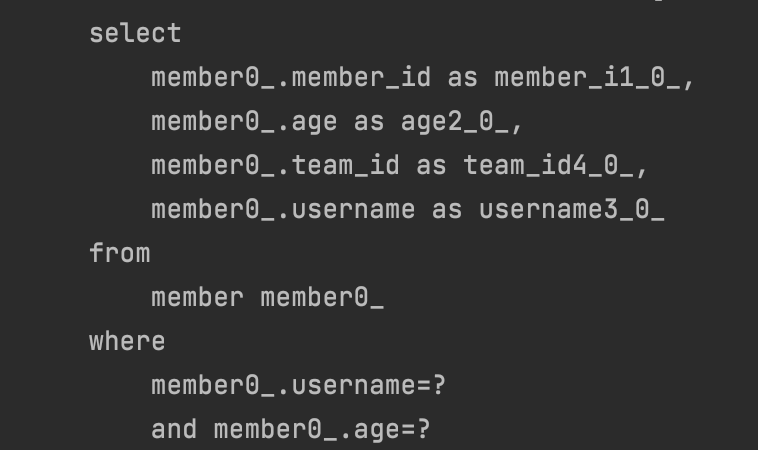
실무에서는
1. 조건이 2개 이하이다. -> 메서드이름을 이용한 자동생성
2. 2개 초과이다. -> @Query
@Query, 값, DTO 조회하기
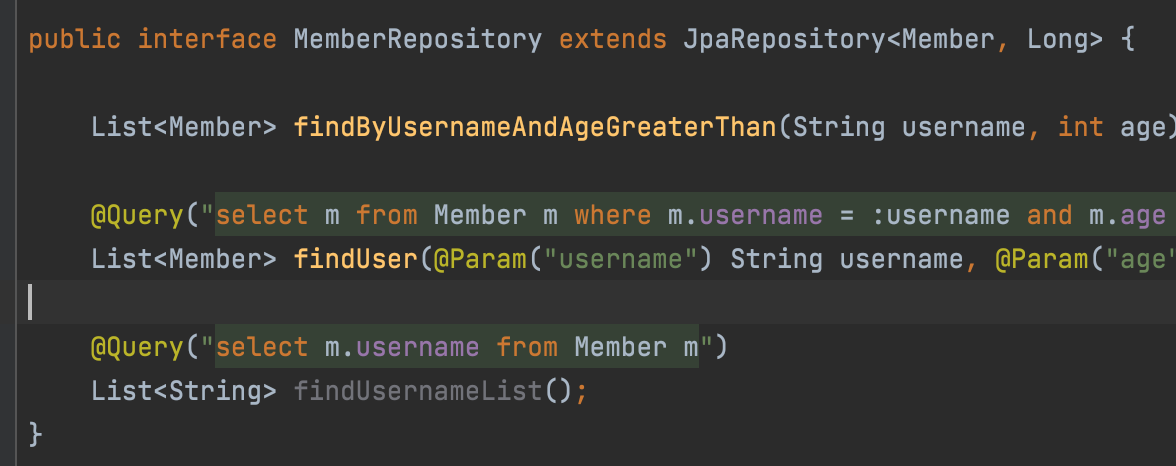

이렇게 전체 회원 이름만 가져오기도 가능
이제 DTO 조회를 해보자.
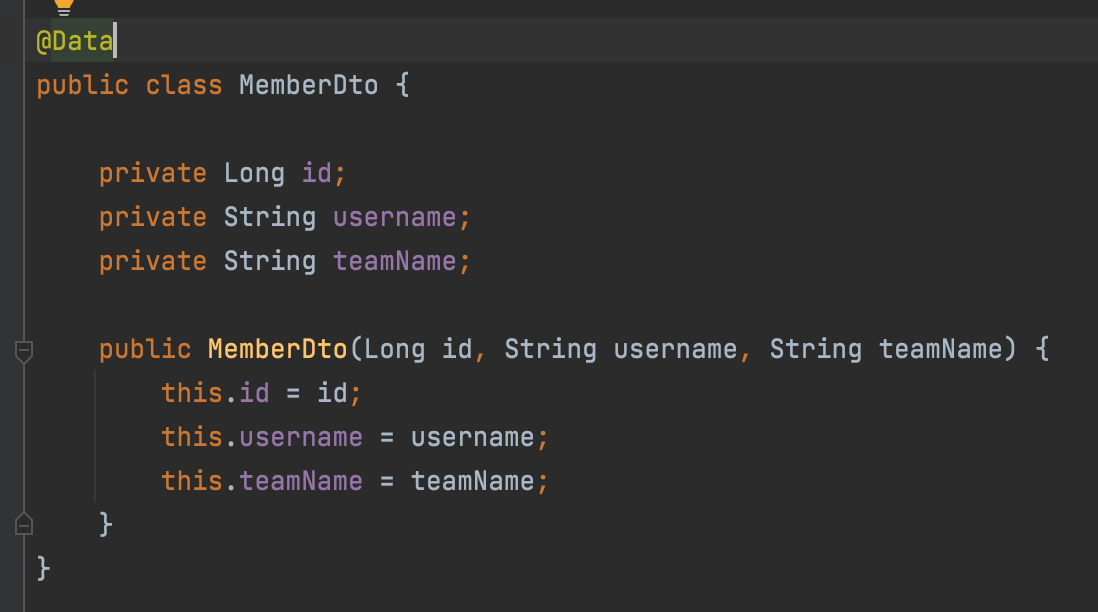
(원래는 DTO에 @Data 쓰면 안됨)

패키지를 직접 지정해주고, 생성자에 파라미터를 넣어줘야 한다.
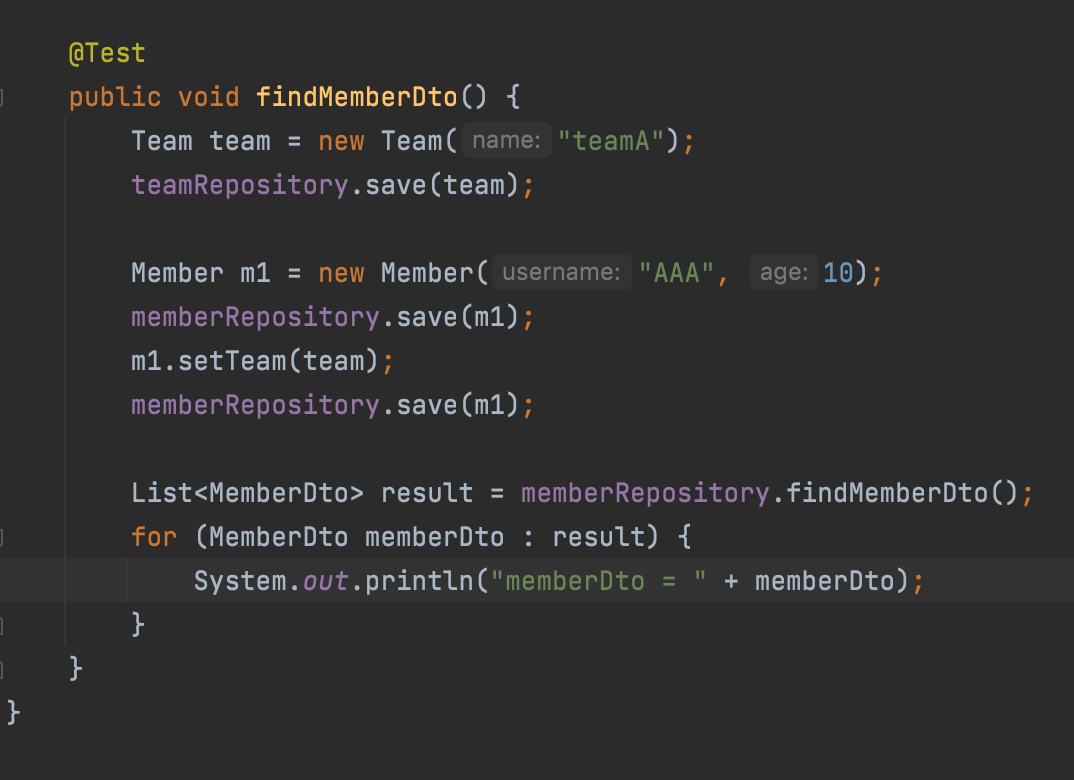

이 부분도 나중에 QueryDsl을 배우면 더 편하게 할 수 있다고 말씀하심.
파라미터 바인딩
- 위치 기반
- 이름 기반
select m from Member m where m.username = ?0 //위치 기반
select m from Member m where m.username = :name //이름 기반
실무에서는 이름 기반만 사용한다고 하심.
그리고 in절을 자동으로 이쁘게 만들어주는 기능도 잠깐 소개해주셨다.


반환 타입
스프링 데이터 JPA는 유연한 반환 타입 지원

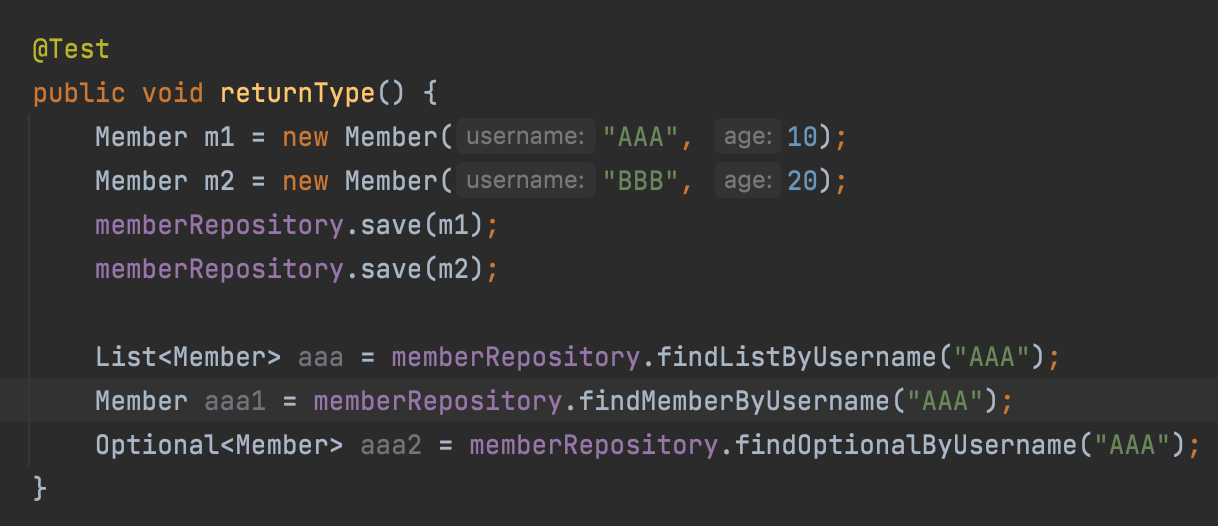
List의 경우 null이 들어가도 그냥 빈 컬렉션이 반환되기 때문에 따로 처리하지 않아도 된다.
그러나 Member 단건의 경우 없으면 null을 주기 때문에 반환을 하게 되면 문제가 발생할 수 있다.
그러므로 Optional 사용하자.
공식문서
https://docs.spring.io/spring-data/jpa/docs/current/reference/html/#repository-query-return-types
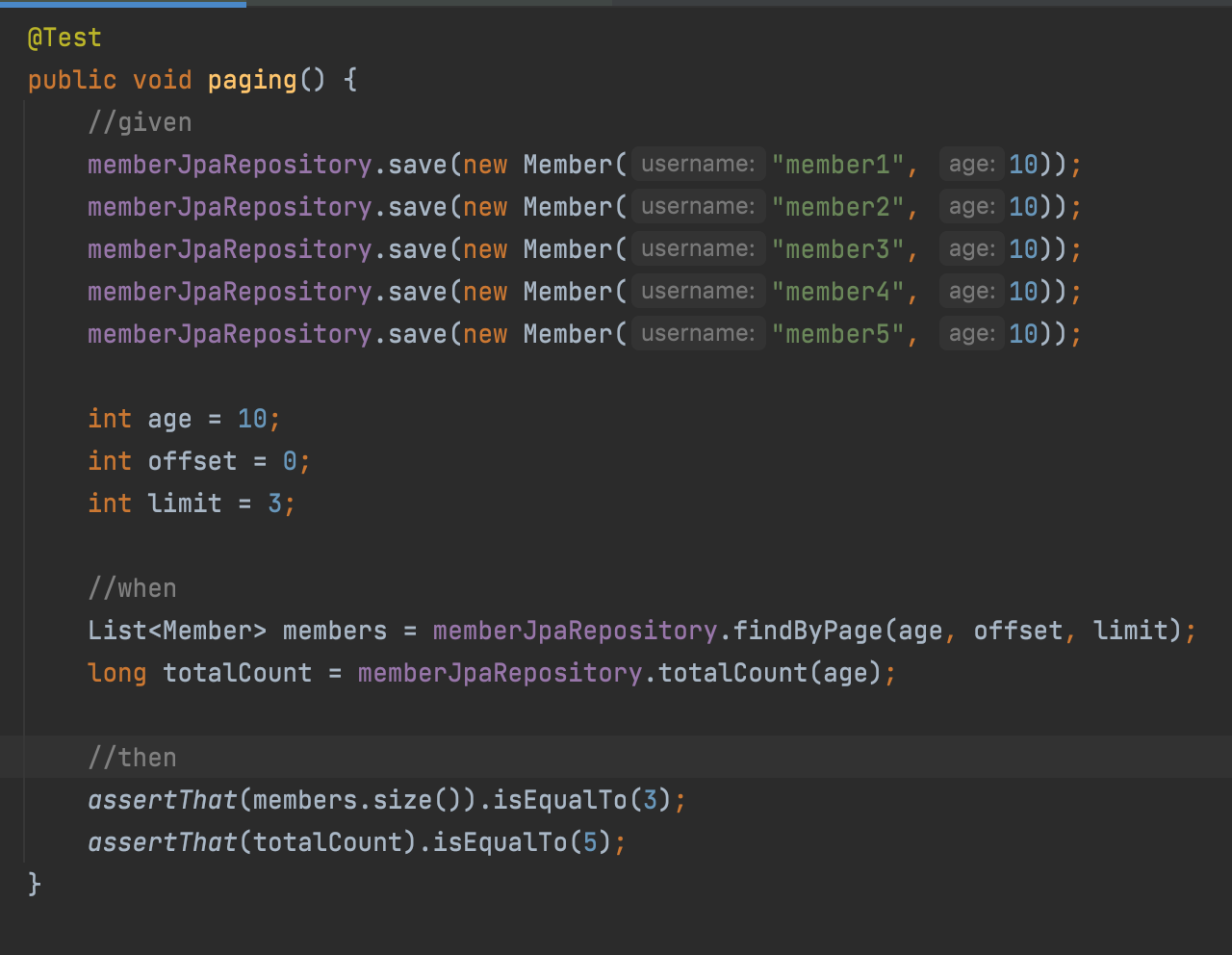
순수 JPA 페이징과 정렬
- 검색 조건: 나이가 10살
- 정렬 조건: 이름으로 내림차순
- 페이징 조건: 첫 번째 페이지, 페이지당 보여줄 데이터는 3건
Repository
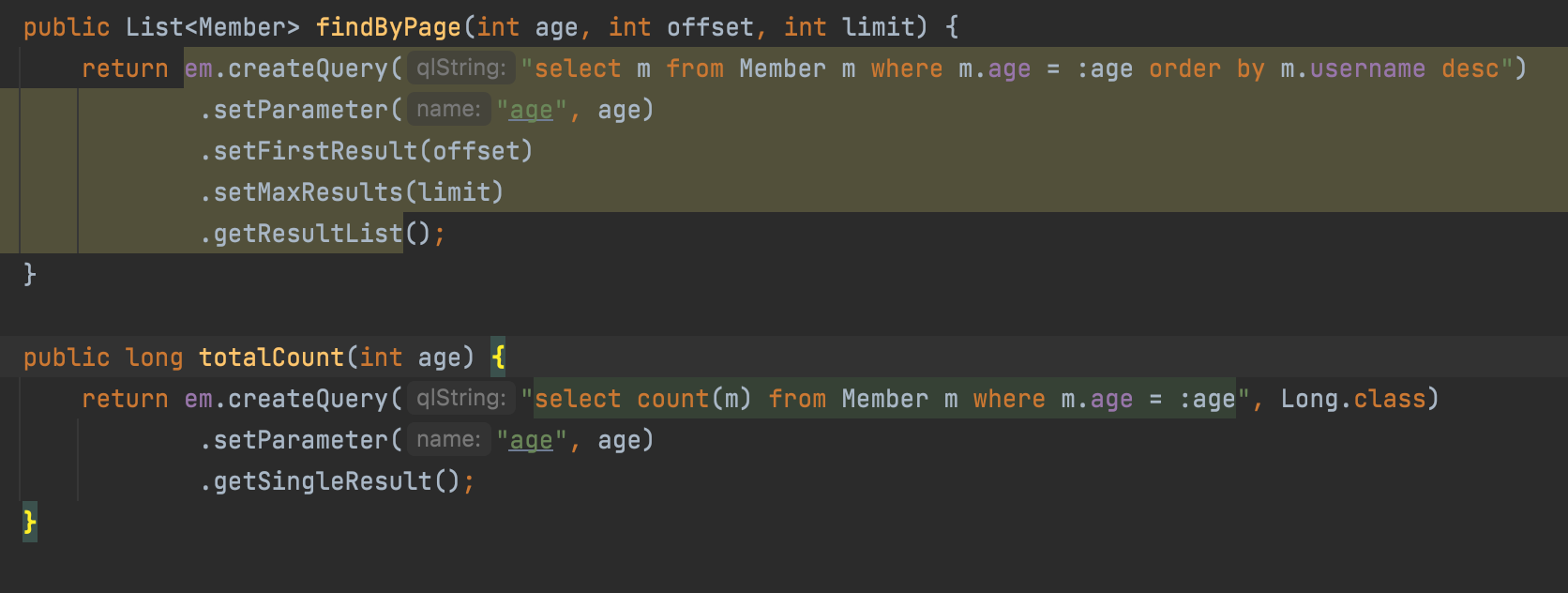
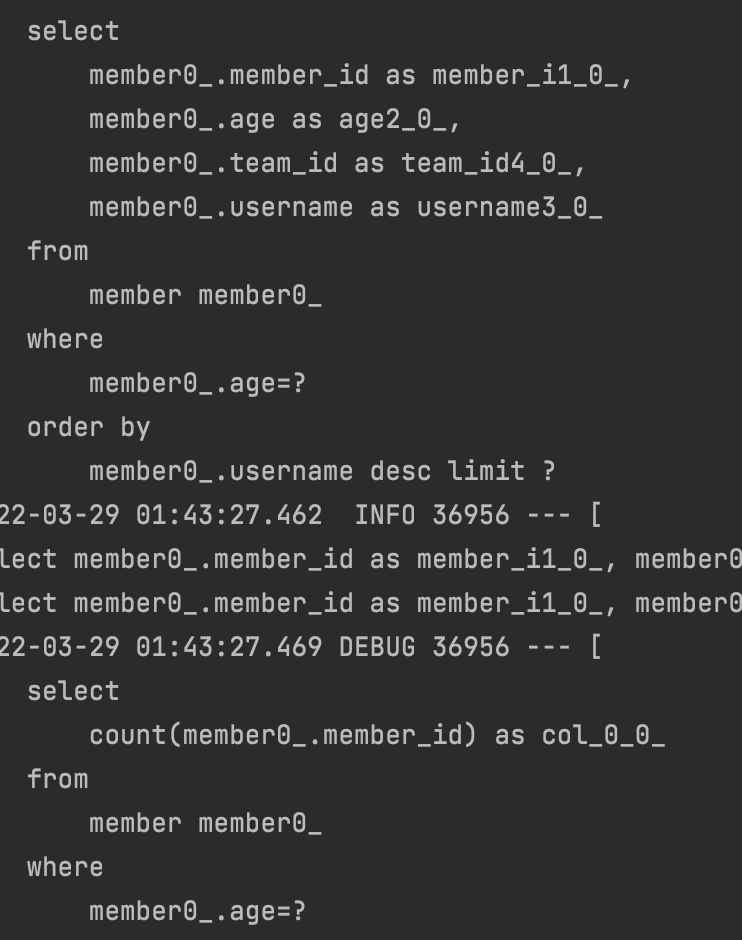
보통 실무에서는 전체 수와, 페이징 수 두 개를 만들고 사용한다고 한다.
스프링 데이터 JPA 페이징과 정렬
org.springframework.data.domain.Sort: 정렬 기능org.springframework.data.domain.Pageable: 페이징 기능(내부에Sort포함)
특별한 반환 타입
org.springframework.data.domain.Page: 추가count쿼리 결과를 포함하는 페이징org.springframework.data.domain.Slice: 추가count쿼리 없이 다음 페이지만 확인 가능(내부적으로 limit + 1 조회)List: 추가 count 쿼리 없이 결과만 반환
Page

끝
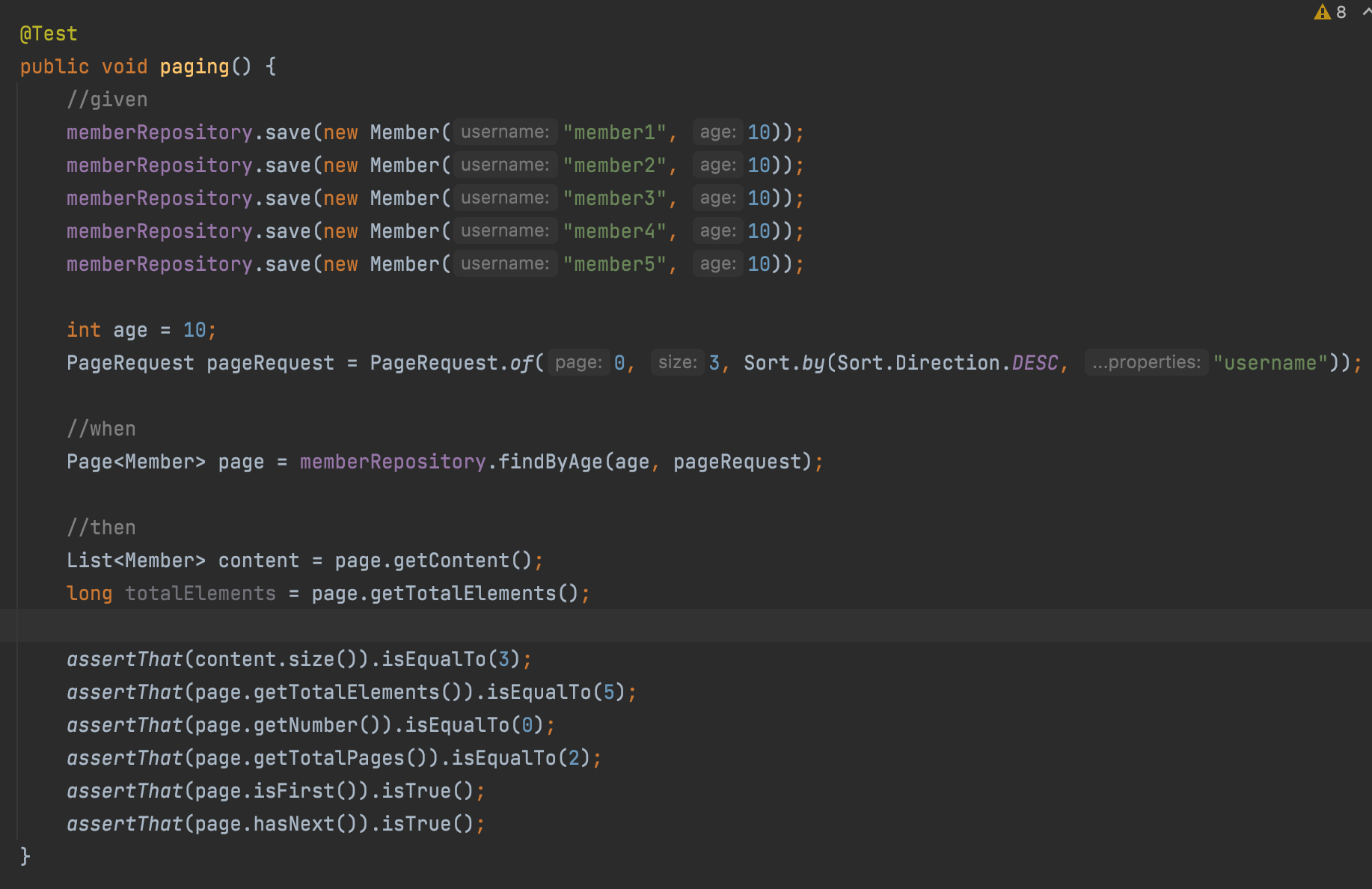
Pageable 인터페이스를 이용해서 그 구현체인 PageRequest를 넣어 페이징에 대한 많은 기능을 사용할 수 있다.
PageRequest.of(): 페이징 생성을 해주는 것이다. 0번부터 시작이고, 2번째 파라미터는 크기, 세번째부터는 조건인데 안써도 된다.
Slice

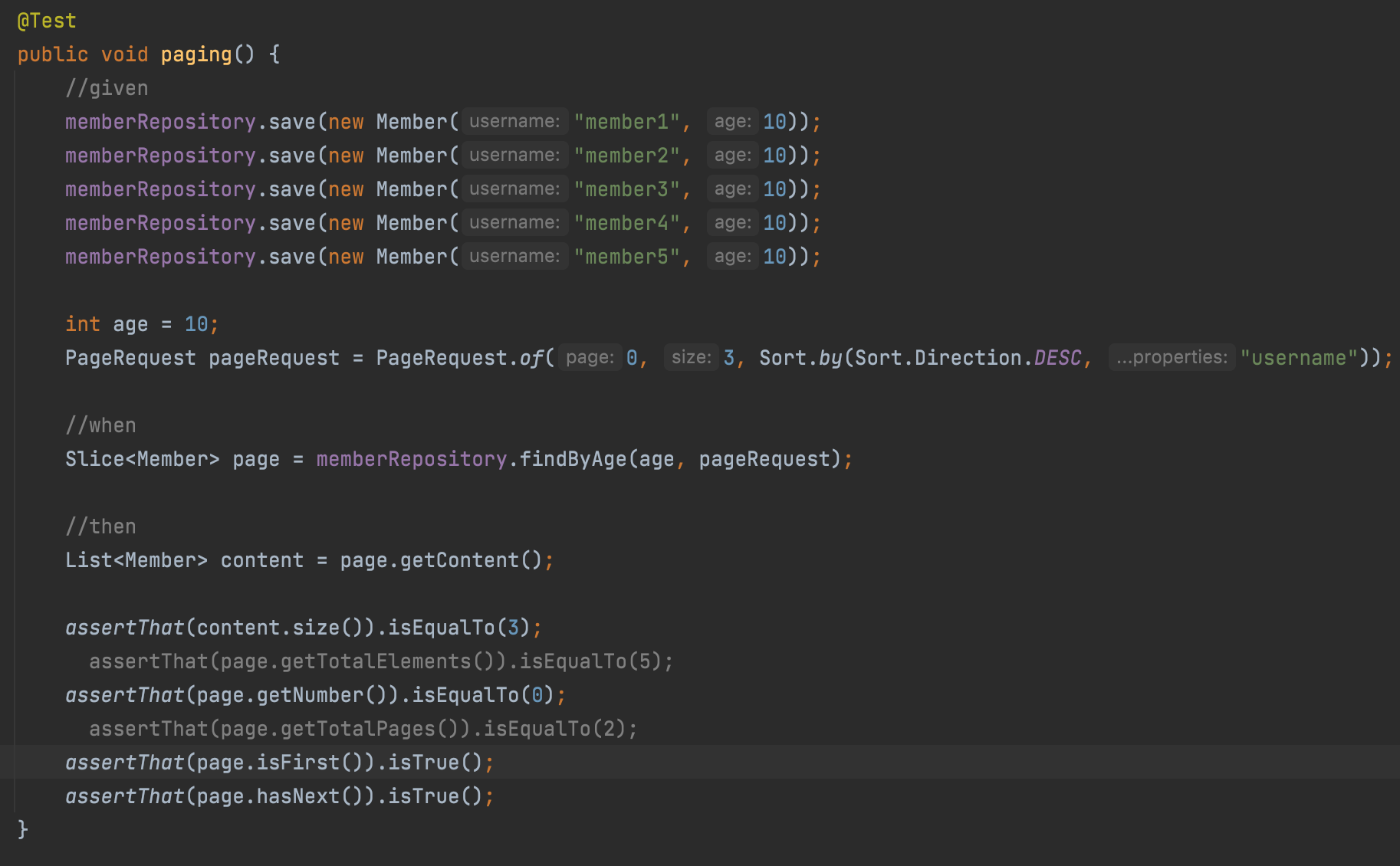
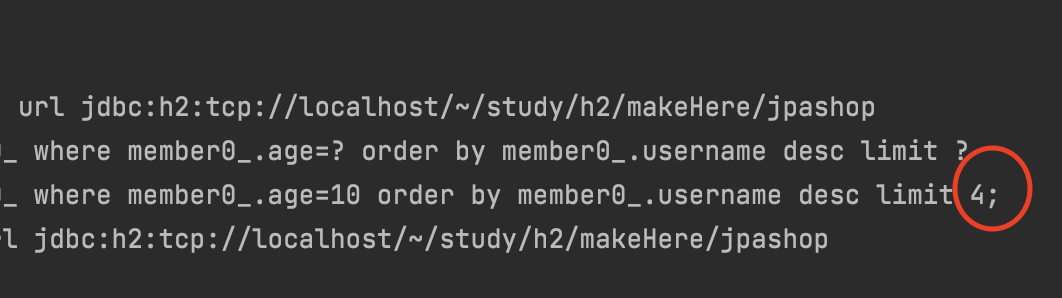
Slice의 경우에는 사이즈가 3일때 3 + 1 인 4개의 자료를 만든다.
흔히 사이트에서 더보기 버튼을 누를때 사용한다고 한다.
사용해보지 않아서 잘 모르겠다.
List

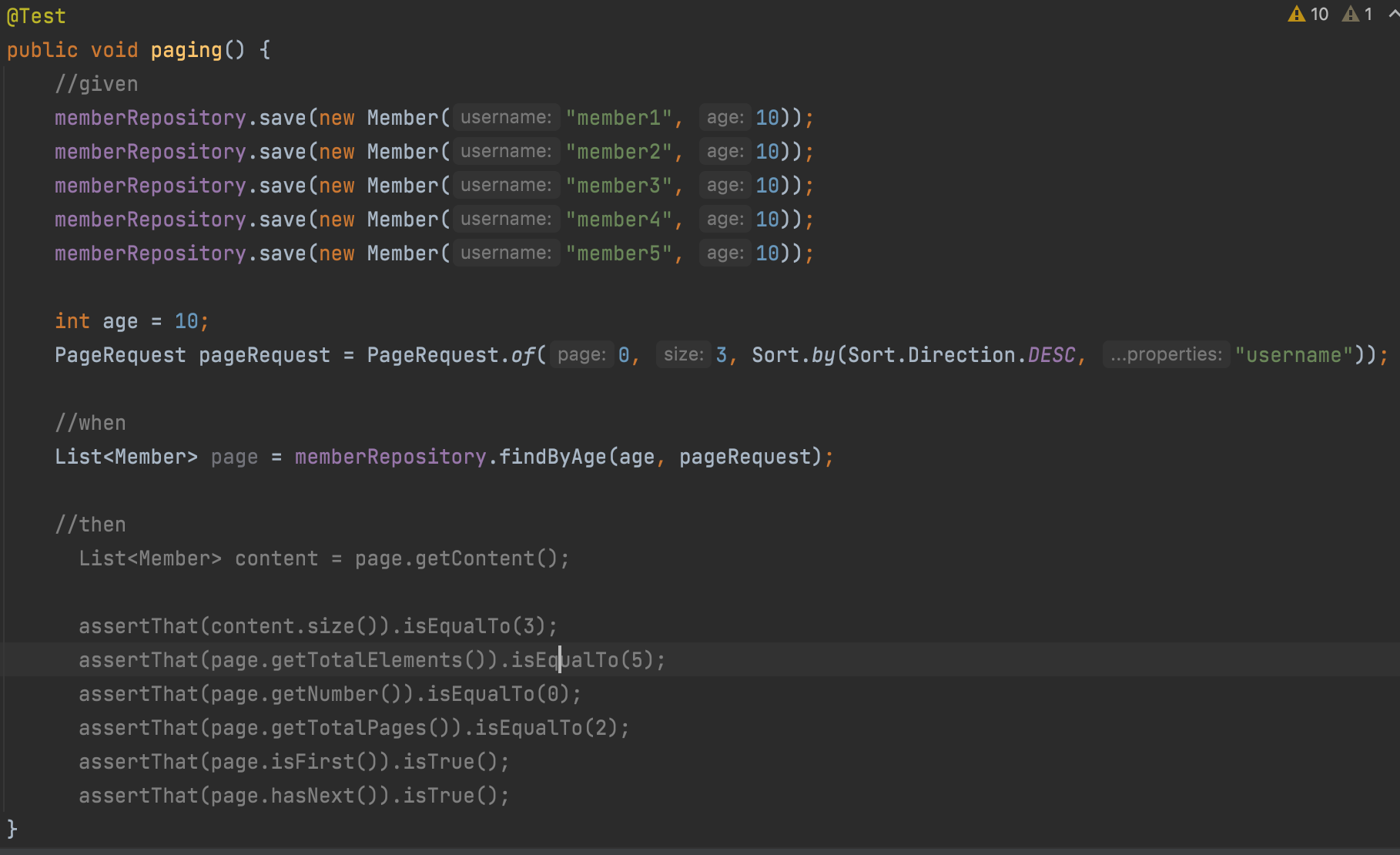
리스트는 뭐 리스트로 반환되니까 딱히 제공되는 기능이 없다.
실무에서 요즘에는 페이징을 잘 안쓴다고 한다.
totalCount를 할때 결국에는 모든 데이터를 조회해야 하기 때문.
이에 대한 해결책으로 totalCount 쿼리만 따로 빼서 사용할 수 있는 기능을 제공한다.
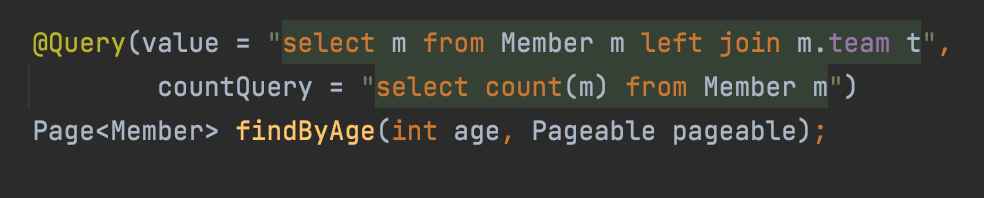
이렇게 countQuery를 분리할 수 있다.
실무에서는 참고로 이 페이징한 리스트들을 그대로 반환하면 절대 안된다.
DTO로 변환해서 넘길것.
이걸 쉽게 변환하는 방법도 있다.

꿀팁
벌크성 수정 쿼리
Repository

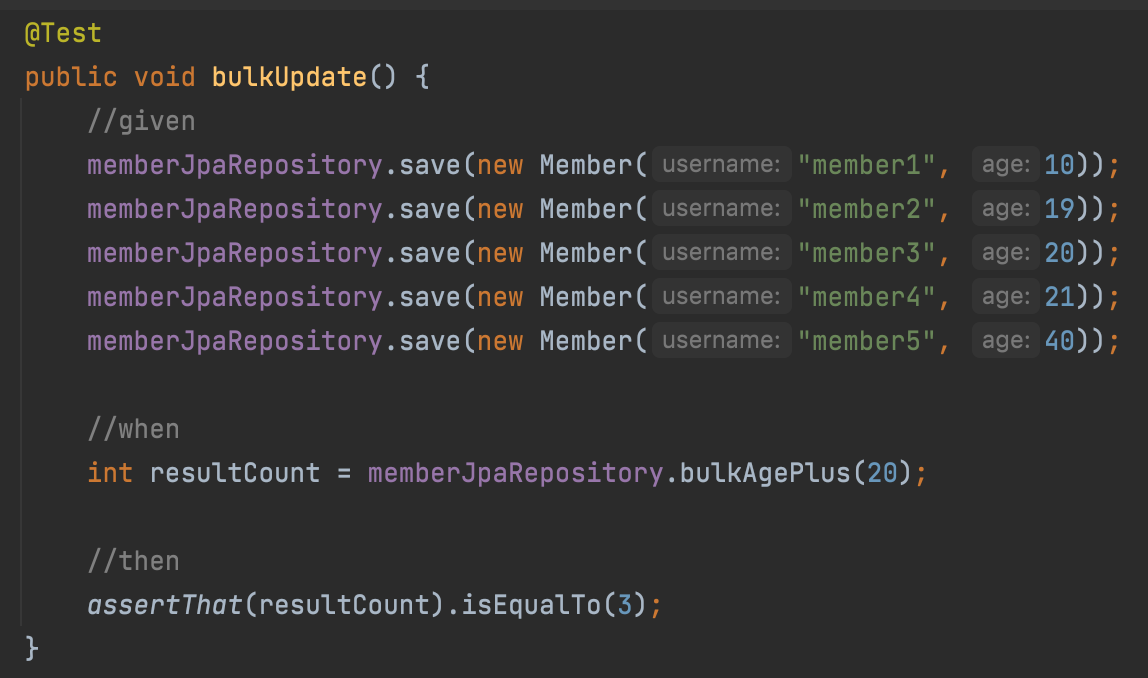
이렇게 하면, 20, 21, 40이 각각 1씩 올라가는 것을 확인할 수 있다.
JpaRepository

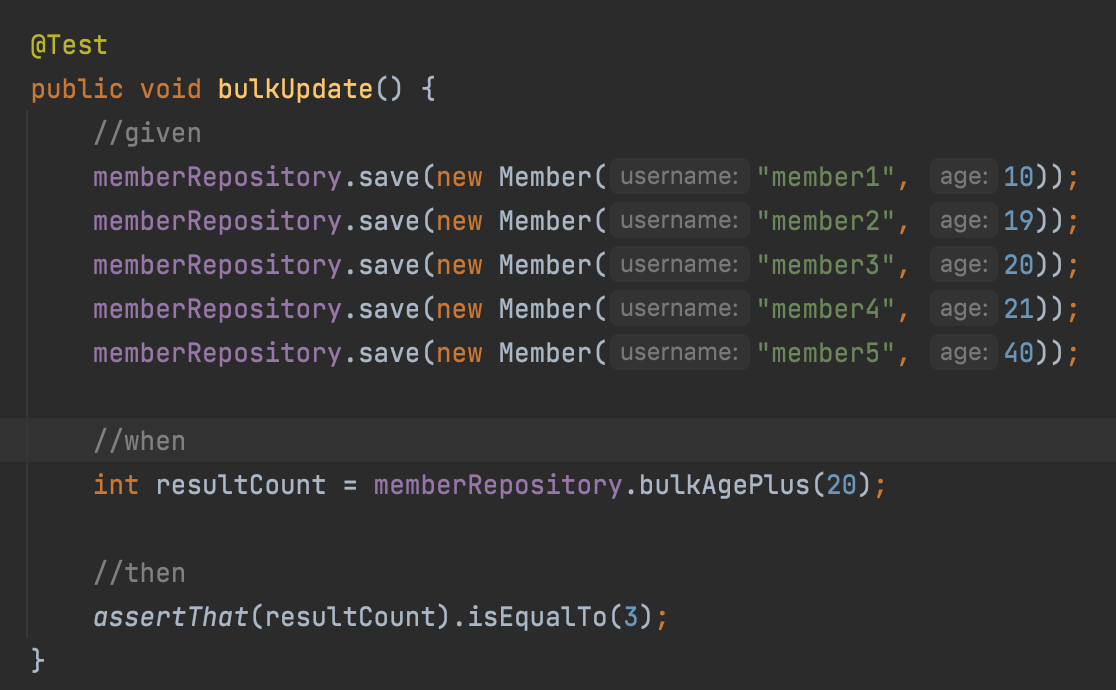
벌크 연산에서 조심해야할 점.
벌크 연산은 영속성 컨텍스트에는 이전값이 남아있기 때문에
벌크 연산 이후에는 데이터베이스에는 이후 값, 영속성 컨텍스트에는 이전 값이 있어 데이터를 가져오면 혼란이 발생한다.
그러므로 벌크 연산 이후에는 em.flush() -> em.clear()로 영속성 컨텍스트를 비워주는것이 좋다.
이 작업을 JpaRepository에서 처리할 수도 있다.

이 옵션을 설정하면 쿼리를 날리는 동시에 영속성 컨텍스트를 자동으로 비워준다.
@EntityGraph
fetch join에 대해 알고 있어야 한다.
이에 대해서는 생략하겠다.
아무튼 이 fetch, LAZY 를 편하게 사용할 수 있는게 @EntityGraph인 것 같다.
@EntityGraph는 fetch 조인을 해주는 어노테이션이다.
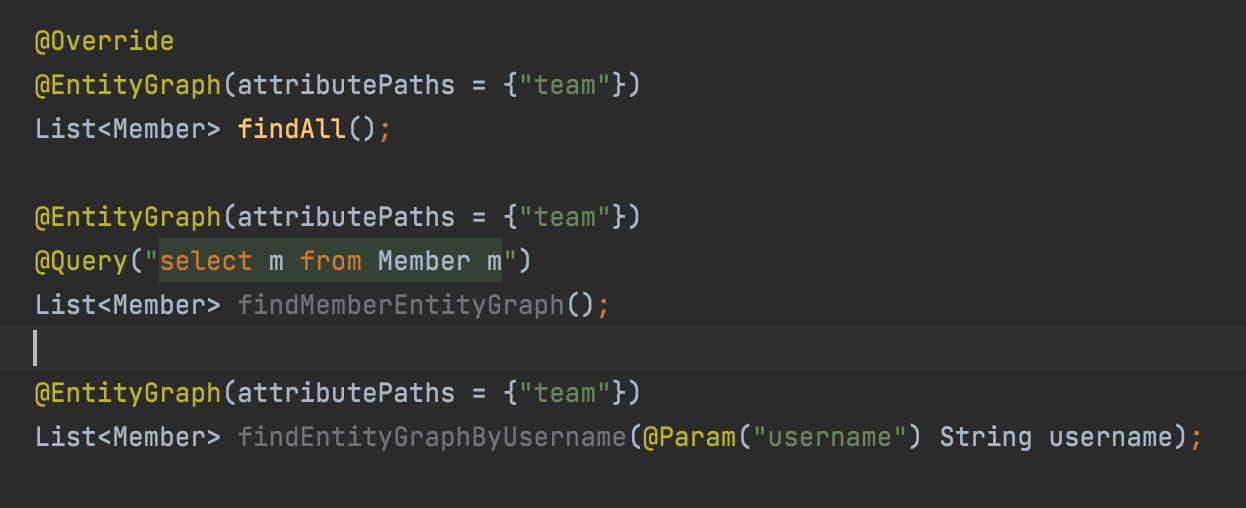
Member엔티티에서는 LAZY설정이 되어있다고 할때,
이렇게 이전에 있던 기능에서 fetch를 쓰고 싶을때,
쿼리를 만드는데 이 쿼리를 fetch를 쓰고 싶을때,
메서드 이름을 통해 자동생성을 하지만, fetch를 쓰고 싶을때,
@EntityGraph를 이용해 편하게 할 수 있다.
JPA Hint & Lock
Hint

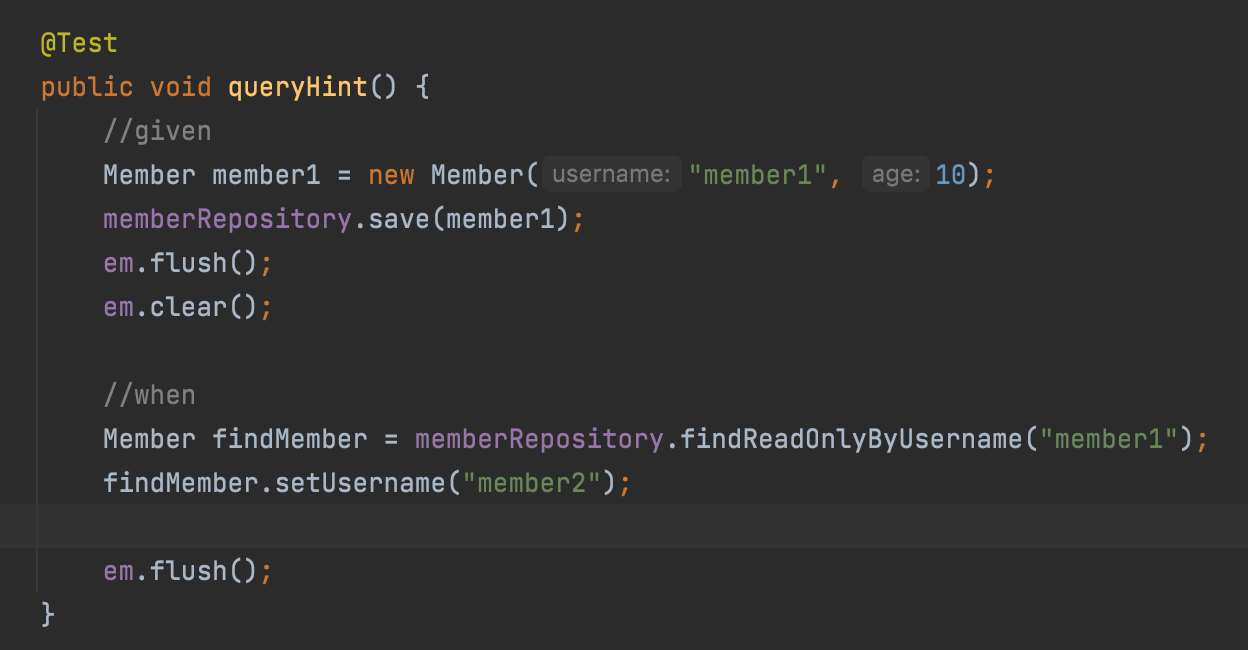
readOnly로 설정하면, set으로 설정해도 더티체킹이 되지 않고, 그냥 읽기 전용으로만 쓰인다.
많이 사용하지는 않음.
Lock

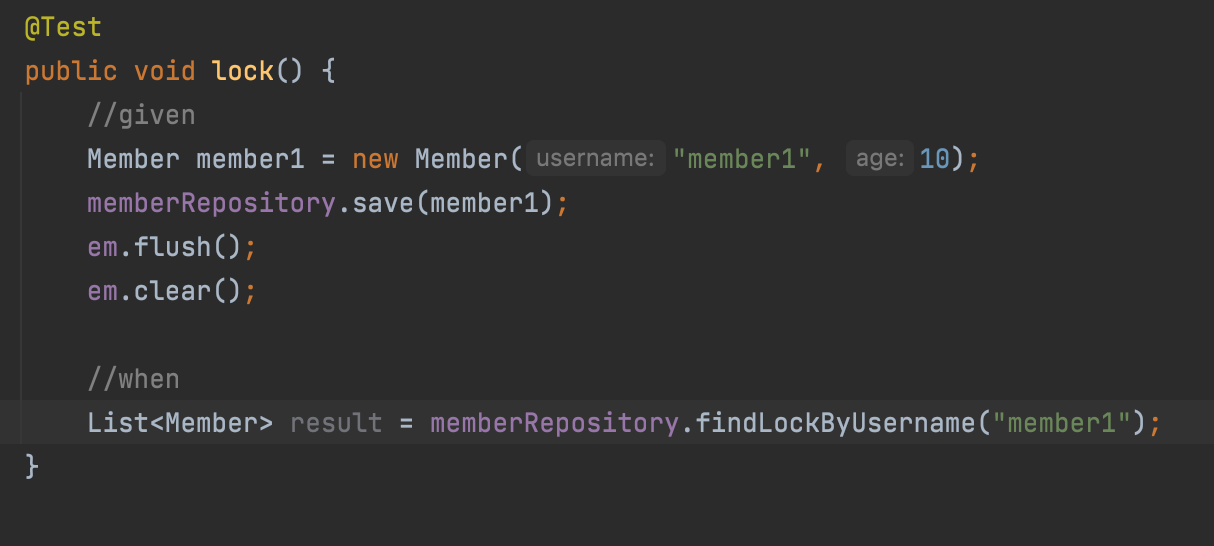
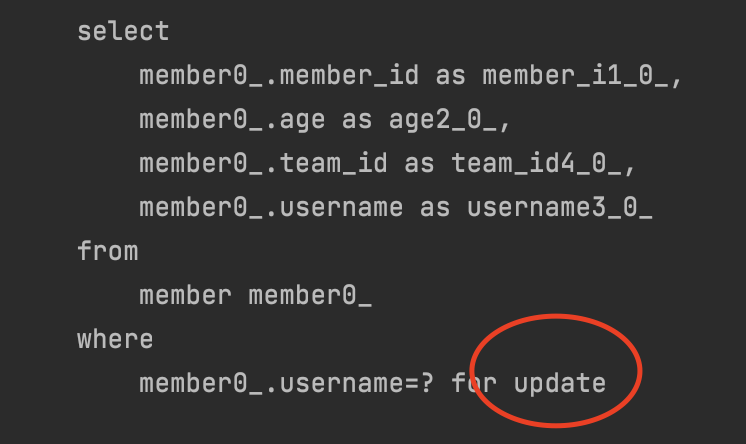
update가 자동으로 붙는다.
이건 데이터베이스에 따라 달라짐. DB마다 방언이 있기 때문에 더 깊은 내용으로 들어가야됨. 서비스에서는 가급적 Lock을 걸면 안됨.
