1 데이터 처리, 저장 및 구성
데이터 처리에 대한 두 가지 접근 방식인 OLTP와 OLAP에 대해 알아보기
1. OPTP vs OLAP
OLTP
- 온라인 트랜잭션처리 (트랜잭션이 중심) ,
- 무수히 많이 발생되는 각각의 작업요청을 오류없이 처리하고, 그 결과값을 실시간으로 확인시켜줘야 함을 의미합니다.
OLAP
- 온라인 분석 처리 (분석이 중심)
- 기존에 저장되어 있는 데이터를 사용자의 요구와 목적에 맞게 분석하여 정보를 제공하는 개념
OLTP 데이터베이스는 직원이 근무한 시간을 추적하는 데 사용되며, 이 달의 직원이 누구인지에 대한 분석을 실행하려면 OLAP으로 전환해야 합니다.
OLTP는 일상적인 운영을 지원하는 데 중점을 두는 반면, OLAP 작업은 더 모호하고 비즈니스 의사 결정에 중점을 둡니다.
| 구분 | OLTP | OLAP |
|---|---|---|
| 목적 | 비지니스 활동 지원 | 비즈니스 활동에 대한 평가,분석 |
| 주 트랜잭션형태 | SELECT, INSERT, UPDATE, DELETE | SELECT |
| 속도 | 수초 이내 | 수초 이상 수분 이내 |
| 데이터표현시간 | 실시간 | 과거 |
| 관리단위 | 테이블 | 분석된 정보 |
| 최적화 방법 | 트랜잭션 효율화, 무결성의 극대화 | 조회 속도, 정보의 가치, 편의성 |
| 데이터의 특성 | 트랜잭션 중심 | 정보 중심 |
| 예시 | 회원정보 수정,상품주문,댓글 남기기&수정 | 1년간의 주요 인기 트랜드, 한달간의 항목별 수입지출 |
2. 데이터의 종류
- structed data(정형 데이터)
- 스키마로 정의되는 구조화된 데이터
- 데이터 유형, 외래키과 같은 개념을 사용하여 테이블간의 관계도 정의
- 일괄적인 주고 때문에 새 구조로의 진화가 어려움
ex ) 스프레드 시트 , csv
- unstructed data(비정형 데이터)
- 스키마가 없고 가장 원시적인 테이터 (소셜데이터의 텍스트, 이미지, 영상 워드등)
- 예시) photo, mp3
- semi structed data(반정형 데이터)
- 구조에 따라 저장된 데이터지만 데이터 형식과 구조가 변경도리 수 있음
- 정형데이터에 비해 확장이 유연하고 간단
- 예시) NoSQL, XML, JSON 이 포함
3. ETL vs ELT
-
ETL (Extract Transform, Load)
Extract : 소스 data로부터 추출
Transform : DeNomalize 등의 추출된 데이터 변형
Load : DW(DataWarehouse)로의 데이터 적재 -
ELT
Extract : 소스 data로부터 추출
Load : DW(DataWarehouse)로의 데이터 적재
Transform :적제된 데이터 변형
2 데이터베이스 스키마 및 정규화
1. 스키마
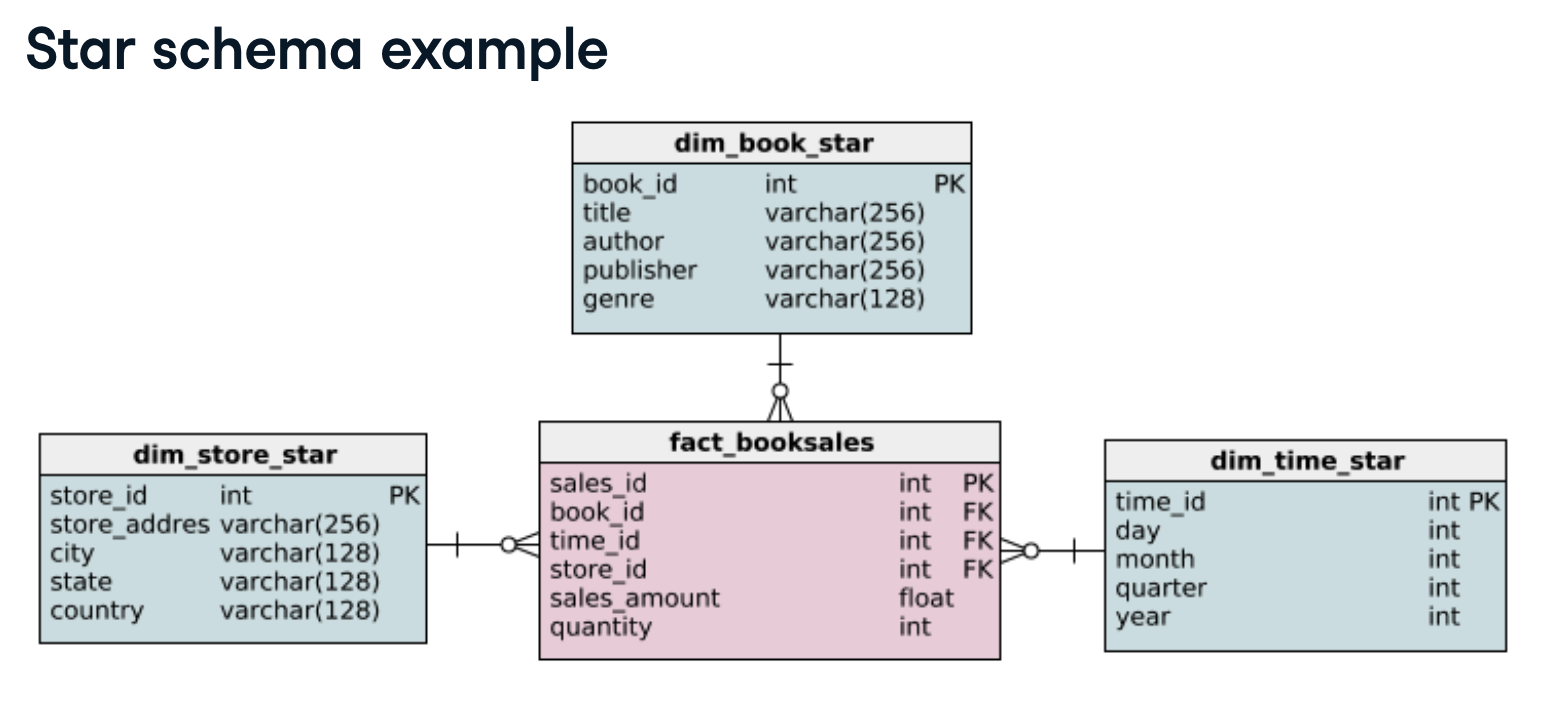
- star schema
- 정규화를 사용하지않음
- 각 차원에 대해 단일 테이블과 함께 팩트 테이블로 구성되는 단순하고 일반적인 모델링이다.
- 스키마는 중심인 팩트 테이블을 둘러싸고 확장되는 패턴으로 표시된 차원 테이블을 사용하여 별 모양처럼 보인다.
팩트 테이블의 dimension은 기본 키와 외래 키를 통해 차원 테이블에 연결된다.
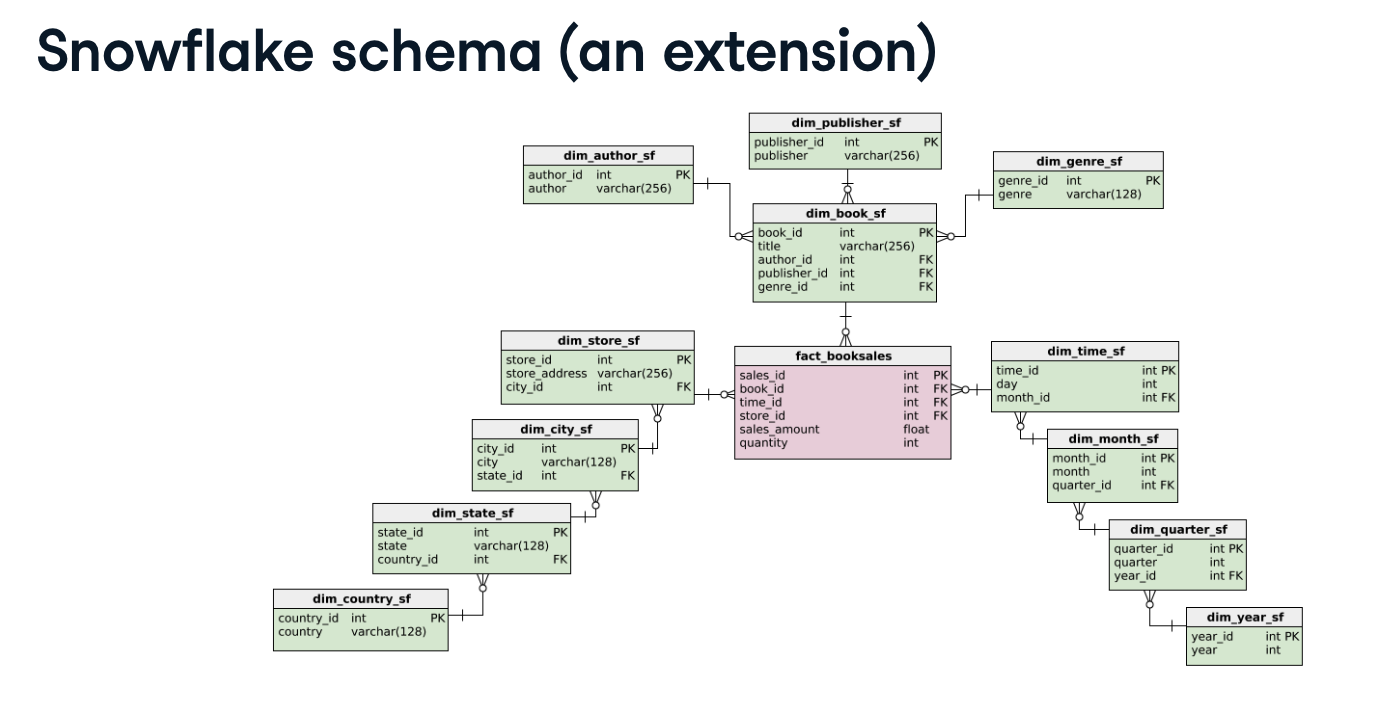
- snowflake schema
- 데이터의 중복을 제거하기위해 정규화를 사용
- 차원 테이블의 계층적 형태를 포함하는 일종의 스타 스키마
이 스키마에는 기본 및 외래키를 통해 팩트 테이블에 연결된 다양한 차원 및 하위 차원 테이블로 구성된 팩트 테이블이 있다.
구조는 눈송이와 유사하게 생겼다.
- 테이블을 추가 테이블로 분할하는 정규화를 사용한다.
테이블을 분할함으로써 중복성을 줄이고 메모리 낭비를 방지할 수 있다. - 스노우플레이크 스키마는 관리하기는 더 쉽지만 설계와 이해가 복잡하다. 또한 쿼리를 실행하는 데 더 많은 조인이 필요하므로 검색 효율이 떨어질 수 있다.
2. 정규화
- 관계형 데이터베이스의 설계에서 중복을 최소화하게 데이터를 구조화하는 프로세스를 정규화라고 한다.
- 정규화를하게 되면 공간이 절약

3 데이터베이스 보기
1. view vs Materialized view
1) view
- 실체가 존재하지 않는 다는 의미로 가상 테이블이라고도 불린다.
- 반복적인 조회를 단순하게 만들어 줄 수 있다.
- ex) 특정 테이블의 특정 컬럼들만 자주 불러와서 사용하는 경우.
- ex) 특정 테이블들을 UNION하여 가져 올 경우.
- ex) 특정 DB LINK를 반복적으로 사용할 경우. 등 등
- SELECT만 가능하고 UPDATE, DELETE, INSERT는 불가능하다.
-- 컬럼명을 변경없이 상용할 경우
CREATE VIEW ${viewName} AS ${SELECT구문}
-- 컬럼명을 변경하여 사용할 경우
CREATE VIEW ${viewName}(${colName1}, ${colName2}, ...) AS ${SELECT구문}2) Materialized view
- 구체화 뷰(MView) 라고 불린다.
- 기존 View와 비슷하게 동작하지만 실제데이터를 가지고 있다는 차이가 있다.
- 원본테이블에 INSERT,UPDATE, DELETE가 발생하면 MView에도 반영이 된다.
- Index를 생성하여 조회 성능을 향상 시킬 수 있다.
CREATE MATERIALIZED VIEW view_name
BUILD [IMMEDIATE | DEFERRED]
REFRESH [ FAST | COMPLETE | FORCE | NEVER ]
ON [COMMMT | DEMAND]
[[ENABLE | DISABLE] QUERY REWRITE [ON PREBUILT TABLE]]
[[ENABLE | DISABLE] ON QUERY COMPUTATION
AS
SELECT 문장;Normalization
- 테이블 내 중복성 감소
- 논리 데이터 모델 변경
- 데이터베이스 내의 테이블을 조정하여 중복된 데이터를 줄이고,
데이터를 더 효율적으로 관리할 수 있게 하는 과정
Vertical Partitioning
- 열(컬럼)을 기준으로 데이터를 분리하는 방법입니다.
-> 이는 특정 데이터를 자주 사용하지 않거나, 접근 속도가 다른 저장 매체로 이동시키고자 할 때 사용합니다.
Horizontal Partitioning
- 행(로우)을 기준으로 데이터를 나누는 것을 말합니다.
이 방법은 특히 데이터베이스가 매우 크거나 사용자 요구가 많을 때 유용합니다.
->예를 들어, 특정 기간(예: 4분기)의 데이터만 별도의 테이블로 옮기면, 해당 기간의 데이터에 빠르게 접근할 수 있습니다.
4 데이터베이스 관리
데이터 통합시 염두에 두어야 할 사항
1. Data integration do's and dont's
Dont's
- 자동화된 테스팅과 능동적인 알람이 필요하지 않다
- 지금 당장 필요한 작업에 적합한 솔루션을 선택해야 한다
- 최종 보기에서 모든 데이터는 실시간으로 업데이트되어야 한다
- 데이터 통합 솔루션, 수동 코딩이든 ETL 도구든, 한 번 작동하면 결과적인 뷰를 - 영원히 쿼리 실행에 사용할 수 있다
- 모든 사람이 최종 보기에서 민감한 데이터에 접근할 수 있어야 한다
- 데이터 통합 후 모든 데이터는 단일 테이블에 있어야 한다
DO
- 원하는 데이터에 단일 뷰를 통해 접근할 수 있다는 것은 모든 데이터가 함께 저장된다는 의미가 아니다
- 나의 원본 데이터는 다른 형식과 데이터베이스 관리 시스템에 있을 수 있다
- 나의 원본 데이터는 다른 물리적 위치에 저장될 수 있다
- 데이터 통합은 비즈니스 주도적이어야 한다.

안녕하세요. DBA 망고언니입니다.