HashTable
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable {
public synchronized V get(Object key) {
//...
}
public synchronized V put(K key, V value) {
//...
}
} HashTable은 값을 읽고 쓸 때 모두 synchronized 메서드를 사용하여 멀티 쓰레드 환경에서 Thread-safe를 보장한다는 특징이 있습니다. 그러나 해당 객체의 lock을 가지고 있는 쓰레드만 임계 영역의 코드를 수행할 수 있어 다른 쓰레드들은 lock을 얻을 때까지 기다려야 하기 때문에 성능이 떨어집니다.
HashMap
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable {
public V get(Object key) {
//...
}
public V put(K key, V value) {
//...
}
} HashTable과는 달리, get, put 메서드에 모두 synchronized 키워드가 존재하지 않습니다. 성능은 hashtable보다는 뛰어나지만, 멀티 쓰레드 환경에서 Thread-safe하지 않습니다.
ConcurrentHashMap
public class ConcurrentHashMap<K,V> extends AbstractMap<K,V>
implements ConcurrentMap<K,V>, Serializable {
public V get(Object key) {
//...
}
public V put(K key, V value) {
return putVal(key, value, false);
}
} ConcurrentHashMap은 HashTable보다 성능이 뛰어나며 동시에 Thread-safe한 자료구조입니다. JDK 1.5 업데이트에서 등장하였습니다. 메서드를 살펴보면 get과 put메서드에서 synchronized 키워드를 확인할 수 없습니다. putVal 메서드를 자세히 보겠습니다.
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else if (onlyIfAbsent // check first node without acquiring lock
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}메서드 중간에 synchronized라는 키워드를 볼 수 있네요. ConcurrentHashMap은 읽기 작업에는 여러 쓰레드가 동시에 읽을 수 있지만, 쓰기 작업에서는 Lock을 사용한다는 것을 알 수 있습니다. 동기화 방식을 좀 더 자세히 파헤쳐 보겠습니다.
//1. 조건절이 없음, 무한루프
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//2. tabAt 메서드를 통해 해당 버킷이 비어있는지(null) 확인
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//3. 다시 Node 와 기대값(null) 을 비교하여(casTabAt 함수) 같으면 새로운 Node를 생성해 넣는다.
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
//...
}무한루프를 돌면서 버킷이 비어있다면, casTabAt 메서드를 통해 데이터를 add하는 것을 확인할 수 있습니다. casTabAt 메서드를 보겠습니다.
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSetObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
/**
* Atomically updates Java variable to x if it is currently
* holding expected.
*
* This operation has memory semantics of a volatile read
* and write. Corresponds to C11 atomic_compare_exchange_strong.
*
* returns : true if successful
*/
@HotSpotIntrinsicCandidate
public final native boolean compareAndSetObject(Object o, long offset,
Object expected,
Object x);주석을 해석하면, compareAndSetObject 메서드는 현재 값이 expected와 같을 경우 x로 업데이트하고 true를 반환하는 메서드임을 알 수 있습니다. Compare and Swap(CAS) 알고리즘을 간단히 설명하자면 다음과 같습니다.
Compare and Swap(CAS)
CAS 알고리즘이란 현재 쓰레드가 존재하는 CPU 의 CacheMemory 와 MainMemory 에 저장된 값을 비교하여, 일치하는 경우 새로운 값으로 교체하고, 일치하지 않을 경우 기존 교체가 실패되고, 이에 대해 계속 재시도를 하는 방식입니다.
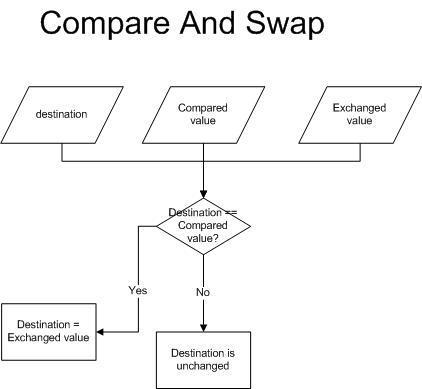
1) CPU가 MainMemory 의 자원을 CPU Cache Memory 로 가져와 연산을 수행하는 동안
2) 다른 쓰레드에서 연산이 수행되어 MainMemory 의 자원이 바뀌었을 경우,
3) 기존 연산을 실패처리하고, 새로 바뀐 MainMemory 값으로 재수행합니다.
원래 volatile 의 경우, synchronized 키워드와는 달리 동시 접근 문제를 해결하지 못합니다. 즉, 가시성은 보장하나 원자성은 보장하지 못합니다. CAS 알고리즘을 통해 원자성을 보장하도록 만든 비동기 방식이 Atomic변수이고, synchronized 키워드처럼 동시접근 문제와 가시성 문제 모두 해결할 수 있는 방법입니다.
다시 돌아와서 정리하면, ConcurrentHashMap에서 버킷이 비었다면 lock-free한 CAS 방법으로 값을 추가해주고 있다는 것을 확인할 수 있었습니다. 비어있는 버킷에 추가할 때에는 lock을 사용하지 않고 서로 다른 스레드가 같은 해시 버킷에 접근할 때만 해당 블록이 잠기게 되기 때문에 성능상에 이점이 있는 것이죠!
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 1. 동일한 Key이면 Node를 새로운 Node로 교체
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
//2. Seperate Chaining에 추가
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
//3. Tree에 추가
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}비어있지 않은 해시 버킷에 접근할 때 synchronized 키워드를 사용하고 있습니다. 동일한 Key 이면 Node 를 새로운 노드로 바꾸고, 해시 충돌(hash collision) 인 경우에는 Separate Chaining 에 추가 하거나 TreeNode 에 추가하는 것을 알 수 있었습니다.
정리하자면 다음과 같습니다.
HashTable은Synchronized키워드를 통해 동시성을 보장하지만, 값을 읽고 쓸 때 모두synchronized키워드를 사용하므로 여러 쓰레드가 접근할 때 병목 현상이 발생하는 등의 성능 이슈가 있을 수 있습니다.HashMap은synchronized키워드를 사용하지 않아 값을 읽고 쓸 때 매우 좋은 성능을 가지지만, 동시성을 보장하지 않아 멀티 쓰레드 환경에서 사용하기 어렵습니다.ConcurrentHashmap은 동시성을 보장하면서HashTable의 성능을 보완한 자료구조입니다. 값을 읽을 때에는 여러 쓰레드의 접근을 허용하기 때문에 성능이 좋고, 값을 쓸 때에만 CAS 알고리즘과synchronized키워드를 사용합니다. 특히 비어있는 해시 버킷에 접근할 때에는 CAS 알고리즘을 통해 lock-free 한 방법으로 동시성을 보장하고 있습니다. 비어있지 않은 해시 버킷에 접근할 때에는synchronized키워드를 사용하여 lock을 걸고 있습니다.
ConcurrentHashmap과 같이 동시성을 보장하는 자료구조들은 java.util.concurrent패키지에 존재합니다. CopyOnWriteArrayList와 BlockingQueue 등 여러 자료구조가 존재하며 각각에 대해서는 더 공부가 필요할 것 같습니다. 궁금하신 분들은 java.util.concurrent 패키지를 열어보시는 것을 추천드립니다!
