
SELECT
- 데이터를 조회하는 DML 명령어다.
SELECT 사용 방법
1. 특정 컬럼 조회
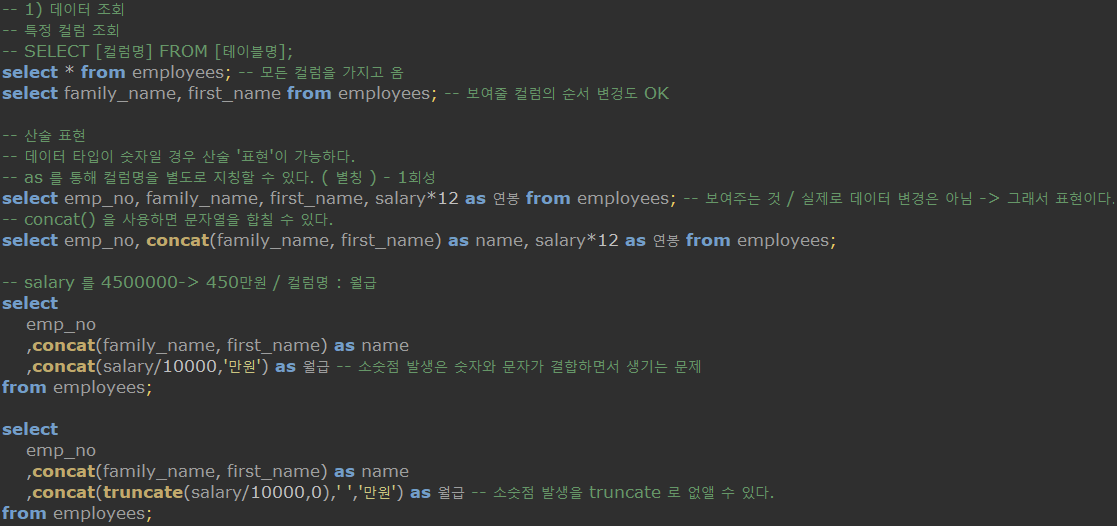
-
SELECT [컬럼명] FROM [테이블명]- 해당 테이블의 컬럼의 데이터를 가지고 온다. -
이때 컬럼명의 순서를 바꾸면 바꿔진 순서대로 나열해준다.
-
데이터 타입이 숫자일 경우
salary*12와 같이 산술 '표현'이 가능하다. -
이 때 곱해준 12가 실제 데이터가 변경되는 것은 아니다.
select를 통해 보여주는 것에 불과해 '표현'이라는 단어를 쓴 것이다. -
'as 연봉' 과 같이 컬럼에 별칭을 붙이는 것도 가능하다.
( 한글보다 영문으로 해주는 것이 좋다 ) -
concat(A,B)는 A와 B를 합쳐주는 함수이다.
( 여기서는 성과 이름을 붙였다. ) -
truncate(숫자, 버림할 소숫점자릿수) 는 소숫점 자릿수를 버릴 수 있는 함수이다.
2. 특정 조건의 데이터 조회
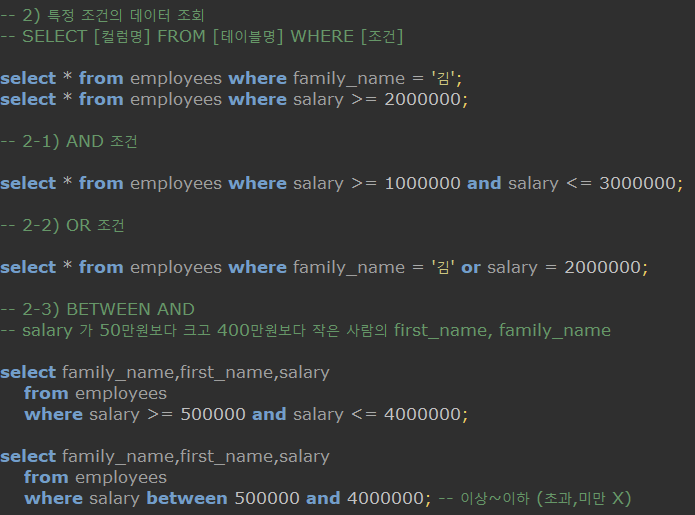
-
SELECT [컬럼명] FROM [테이블명] WHERE [조건]- 특정 조건의 데이터만 조회해준다. -
AND 조건 , OR 조건 , BETWEEN AND 조건이 있다.
-
비교하고자 하는 컬럼이 같으면
where salary between 50만이상 and 400만이하와 같이 between 을 이용하여 조건을 간소화 할 수 있다.
3. 중복제거

-
SELECT DISTINCT [컬럼명] FROM [테이블]- 해당 테이블의 컬럼의 데이터 중복을 제거해준다. -
선택한 컬럼이 한 개 이상 들어가면 중복 제거가 제대로 되지 않아 한 칼럼의 데이터 중복을 제거해줄 때만 사용한다.
( 여기서는 중복제거에도 불구하고 월급 200만원이 2번이나 나왔는데 한명은 성이 류씨고 다른 한명은 김씨였다. 이렇게 중복이 이상해진 이유는 family_name 의 중복을 제거하고 그 제거한 성씨들의 월급을 나타냈기 때문이다. 그래서 월급 중복 제거가 반영되지 않았다 ) -
GROUP BY도 그루핑을 하면서 중복을 제거하는데 DISTINCT 는 GROUP BY 와 달리 집계함수가 사용되지 않고, 정렬도 하지 않아 더 빠르다.
4. IN

-
select * from employees where family_name in('김','이','박')-
family_name이 '김' or '이' or '박' 인 경우만 가져오는 것과 같이 or 조건을 간소화한 명령어다. -
비교를 간소화 한 것이 between 이라면 in은 or 조건을 간소화한 것이다.
-
or 조건보다 속도가 빠른 장점이 있다.
-
다만 컬럼이 모두 공통되어야 in 사용이 가능하다.
-
NOT IN 의 경우 IN 안의 조건들을 제외한 조건절의 내용을 true 로 생각하여 보여준다.
5. IS NULL / IS NOT NULL

SELECT [컬럼명] FROM [테이블명] WHERE [조건에 쓸 컬럼] IS NULL/IS NOT NULL-
조건에 쓸 컬럼의 데이터에 null 이 존재하는지 여부를 판단하여 맞는 컬럼들의 데이터만 가지고 온다.
6. LIKE
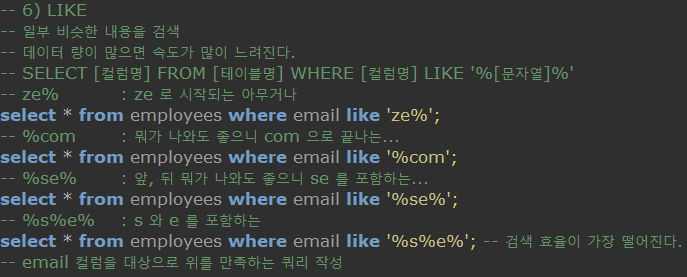
-
SELECT [컬럼명] FROM [테이블명] WHERE [조건 컬럼명] LIKE '%[문자열]%'-
일부 비슷한 내용을 검색하는데 사용한다. -
데이터양이 많으면 속도가 많이 느려진다.
-
조건의 컬럼 속 데이터에 '문자열' 의 단어가 들어가는 것이 있으면 해당 데이터의 제시된 컬럼들을 보여준다.
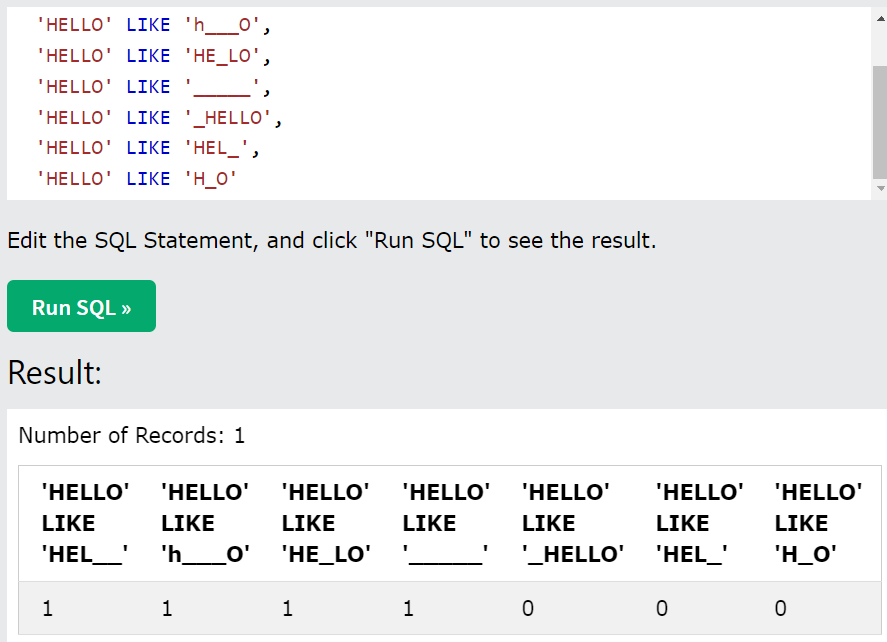
-
LIKE '_[문자열]_'-_를 사용하는 경우엔 언더바의 갯수까지 맞춰줘야 한다. -
가령 WHERE OrderID LIKE '1025_' 를 검색할 때 OrderID 에 102534 인 데이터가 있으면 그 데이터는 false 로 나타나지 않는다.
언더바의 갯수가 1개를 만족하는 데이터가 아니기 때문이다.
7. ORDER BY

-
SELECT [컬럼명] FROM [테이블명] ORDER BY [정렬할 컬럼] [ASC/DESC]-
오름차순(ASC), 내림차순(DESC)으로 해당 컬럼을 정렬해서 데이터를 보여준다. -
default 값은 오름차순(ASC) 이다.
-
정렬할 컬럼마다 각각 오름차순, 내림차순 키워드만 붙여주면 원하는 대로 정렬이 가능하다.
-
order by 는 where 조건 뒤에 붙는다.
-
데이터의 범위를 좁혀놓고 확보한 뒤 정렬을 하든 무언갈 하는 것이 훨씬 효율적이기 때문에 범위를 좁히는 where 이 앞으로 나오는 것이다.
효과적 : 리소스와 상관 없이 100% 확실한 방법 의미
효율적 : 적은 리소스를 투입하고 최대한의 방법을 뽑아낸 것 의미
8. GROUP BY
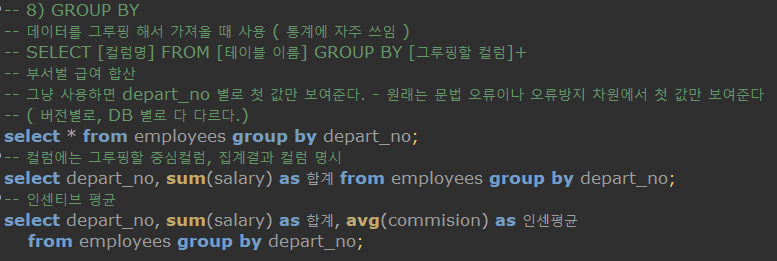
-
SELECT [컬럼명] FROM [테이블 이름] GROUP BY [그루핑할 컬럼]-
데이터를 그루핑해서 가져올 때 사용한다. -
여기서 그냥 depart_no(부서) 를 그루핑하여 모든 컬럼들을 보여달라고 하면 부서별 처음 등장하는 값만 보여준다.
( 원래는 문법 오류지만 mariaDB에선 오류방지 차원에서 첫 값만 보여준다 ) -
그루핑한 컬럼은 정렬되어서 나타난다.
- 선택한 컬럼에는 그루핑할 중심컬럼과 그 그루핑한 컬럼들끼리 집계 함수를 사용하여 낸 산술표현컬럼이 있어야 정상적으로 작동한다.
- 끝에 WITH ROLLUP 을 넣어주면 그루핑해 집계함수로 낸 숫자들의 총합을 맨 끝에 보여준다.
- 다만 ORDER BY 와는 함께 사용이 불가능하다.
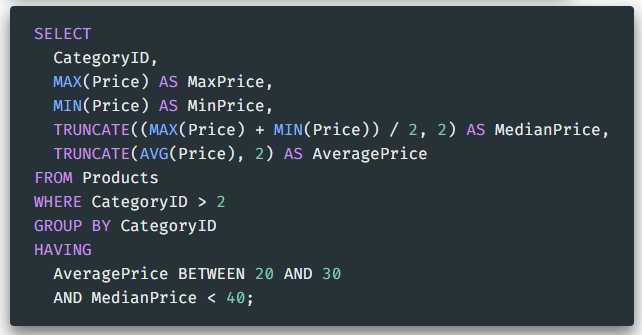
9. HAVING

SELECT [컬럼명] FROM [테이블명] GROUP BY [그루핑할 컬럼] HAVING [조건]-
group by의 결과로부터 특정 조건을 만족하는 값을 추출할 경우에 where 대신에 사용한다.
-
WHERE 은 그룹하기 전 데이터의 조건절이고
HAVING 은 그룹 후 집계함수로 결과를 내고 그 값들을 가지고 쓰는 조건절이다. -
그래서 WHERE 과 HAVING 은 역할이 달라 같이 사용이 가능하다.
-
having 에 컬럼의 명칭을 쓰면 오류가 난다. ( mariaDB 에서는 X )
10. LIMIT
-
SELECT [컬럼명] FROM [테이블명] LIMIT [건너뛸 개수], [가져올 개수];-
원하는 위치(건너 뛸 개수)에서 원하는 만큼(가져올 개수)만 데이터를 가져올 수 있다. 처음부터 가져오면 건너 뛸 개수가 0이라 생략이 가능하다.
예 ) LIMIT 30, 10 이면 31~40 까지 데이터를 가지고 온다. -
주로 검색 결과 페이지 나눌 때 쓰인다.
산술표현
-
데이터 타입이 숫자일 경우
salary*12와 같이 산술 '표현'이 가능하다. -
이 때 곱해준 12가 실제 데이터가 변경되는 것은 아니다.
select를 통해 보여주는 것에 불과해 '표현'이라는 단어를 쓴 것이다.
사칙연산
-
'문자열' 에 + 3 과 같은 연산시 '문자열' 을 0으로 인식하여 0+3 = 3 이 된다.
-
SELECT '1' + '002' * 3; 같은 숫자가 들어간 문자열은 숫자로 인식해줘서 1+2x3 = 7 이 된다.
-
SELECT [컬럼1] + [컬럼2] FROM [테이블]과 같이 숫자로 된 컬럼들끼리도 더하는게 가능하다.
boolean
-
TRUE 는 1 / FALSE 는 0 으로 나타난다.
-
!TRUE, NOT 1 : 0
!FALSE, NOT FALSE : 1 -
조건절 WHERE 에 0을 넣으면 false가 되어 값이 나타나지 않는다.
반대로 조건절 WHERE에 1을 넣으면 true가 되어 조건이 참인 값이 나온다.
IS / IS NOT
SELECT (TRUE IS FALSE) IS NOT TRUE;의 결과는 1(TRUE) 이다.
AND && / OR || / BETWEEN
-
SELECT 2 + 3 = 6 OR 2 * 3 = 6;의 결과는 1(TRUE) 이다. -
BETWEEN [작은수] AND [큰수]로 작은 수가 앞에 나와야 1(TRUE) 가 나온다. -
NOT BETWEEN [작은수] AND [큰수]는 작은수~큰수 사이가 아니면 1(TRUE) 가 나온다. -
주로 WHERE 조건절에 많이 쓰인다.
비교연산
-
!=, <> : 양쪽 값이 다름
-
SELECT 'A' = 'a';의 결과는 1(TRUE) 다. ( MySQL는 대소문자 구분 X )
