
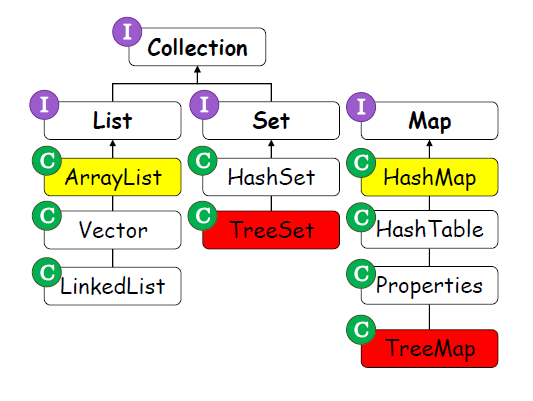
Collection Framework
-
Collection interface 를 최상위로 하는 자료구조 인터페이스 이다.
-
List / Set / Map 인터페이스를 구현하여 각 collection 으로 사용한다.
-
초기 선언 시 크기를 지정하지 않는다. ( 크기가 거의 무한하다 )
-
최상위 collection 인터페이스와 List / set / Map 인터페이스를 구현하기 때문에 Colletion Framework 의 데이터 추가,삭제, 검색 방법은 거의 비슷하다.
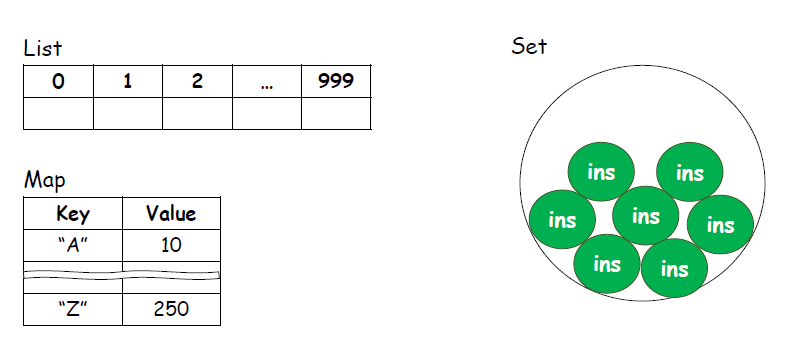
Collection Framework 는 다양한 자료구조를 가지고 있다.
-
List : 순서 O / 중복 O
-
Map : Key-Value 구조 ( key 는 순서 X 중복 X )
-
Set : 순서 X / 중복 X ( (ex) 로또 기계 )
List 는 JS의 배열처럼 늘어나고 메서드를 넣을 수 있단 점이 동일하고,
Map 은 JS의 오브젝트의 key,value 사용하는 것이 비슷하다.
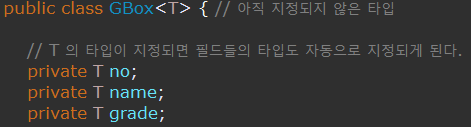
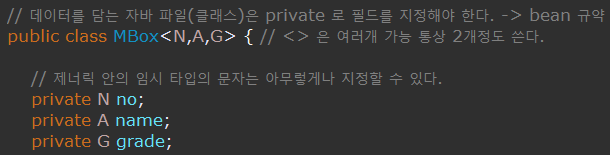
Generic
-
<> 안에 들어갈 수 있는 타입을 명시해준다.
-
클래스에 사용이 가능하며, 데이터타입은 무조건 클래스타입으로 들어가야 한다.
(ex)<int>(X) /<integer>(O) -
클래스를 객체화 할 때 마다 유연하게 클래스 내 데이터 타입을 지정할 수 있는 장점이 있다.
jdk 1.7 부터 new 객체 생성하는 부분은 제네릭 타입을 생략할 수 있다.
HashMap<String,String> map = new HashMap<>();가능
List
ArrayList
-
index 로 객체를 관리한다는 점에서는 Array 와 유사하다.
-
배열과 달리 인덱스의 길이가 유연하다.
-
객체의 추가, 삭제 시 인덱스가 1씩 당겨지거나 미뤄지게 된다.
-
때문에 빈번한 객체의 추가, 삭제가 일어나는 경우 무리가 생긴다.

Vector
-
ArrayList 는 특정 Thread 가 접근 시 다른 Thread 가 접근이 가능하다.
-
Vector 은 특정 Thread 가 접근 시 다른 Thread 가 접근할 수 없다.
-
즉, 누군가 사용하고 있다면 다른 사람이 기다리는게 Vector 이다.
LinkedList
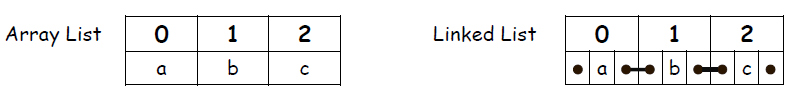
-
ArrayList와 달리 LinkedList 는 좌우 데이터의 주소를 기억하는 구조를 갖는다.
-
그래서 중간에 데이터가 추가/삭제 될때 높은 효율을 보인다.
단순히 뒤에서부터 쌓고 빠지는 것은 ArrayList 가 빠르다.
LinkedList 는 좌우 데이터 주소를 기억하고 있어야 하기 때문이다.
Set
-
로또 기계 속 공과 같이 중복이 허용되지 않으며 순서가 없다.
-
Set 은 Map 과 달리 중복을 덮어쓰지 않고 데이터 오염을 막기 위해 아예 받지 않는다.
HashSet
-
Set collection 은 순서 X / 중복 X 이다.
-
검색 기능이 없는 대신 하나씩 꺼낼 수 있는 Iterator 을 제공한다.
-
Set 안에 동일한 클래스의 객체 데이터를 생성하여 넣으면 일련번호가 달라 각각 다르다고 판단한다. ( 중복 발생 X )
Iterator
-
Set 은 순서가 없는 특성때문에 get(index) 를 사용할 수 없다.
-
그래서 Iterator을 통해 데이터를 쪼개서 next()로 하나씩 꺼내어 사용한다.
-
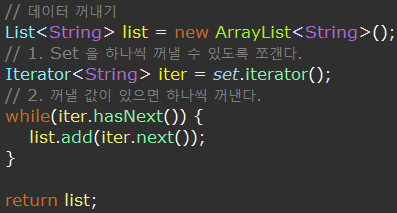
여기서는 set.iterator() 로 쪼개어
Iterator<string>타입의 iter 변수 안에 넣고 iter.hasNext() 를 통해 꺼낼 값이 있는지 확인 후 반복문을 통해 iter.next() 로 하나씩 꺼내어 ArrayList 객체인 list 안에 넣어 반환한다. -
이때 set 은 순서가 없고 중복이 허용되지 않기 때문에 매번 결과물이 다르게 뜬다.
Map
- 검색 시 key 값을 찾기만 하면 되서 ArrayList 처럼 하나씩 찾아보는 것에 비해 더 유리하다.
HashMap
-
Key-value 구조이다
-
Key 는 순서 X / 중복 X 이다.
-
List / Set 과는 달리 collection 인터페이스를 구현하지 않기 때문에 기존과 조금 다른 메서드를 사용한다.
-
Set 과는 달리 Key의 중복은 덮어쓰는 개념이다.
HashTable
- List 의 Vector 처럼 특정 Thread 가 접근 시 다른 Thread 가 접근할 수 없는 것이 HashMap 과의 차이점이다.
etc
동기방식(synchronous)
- 클라이언트가 요청을 보내고, 응답이 올 때까지 기다려야 하는 방법
형변환 예외
- Interger.parseInt() 와 같은 형변환 메서드는 NumberFormatException 을 발생할 수 있다. 그래서 try-catch 로 예외 처리해야 한다.
