0x01 관계형 데이터 모델
- 데이터베이스를 관계(relation) + 무결성 제약(integrity constraint)으로 묶음(collection)
- 관계간에 순서가 없고, 관계 내의 튜플도 순서가 없다.
- 1970년 E.F.Codd에 의해 제안
- 수학적 이론사용 (집합이론, 일차수학논리)
- 매우 많이 사용됨
1.1 Relation 예제
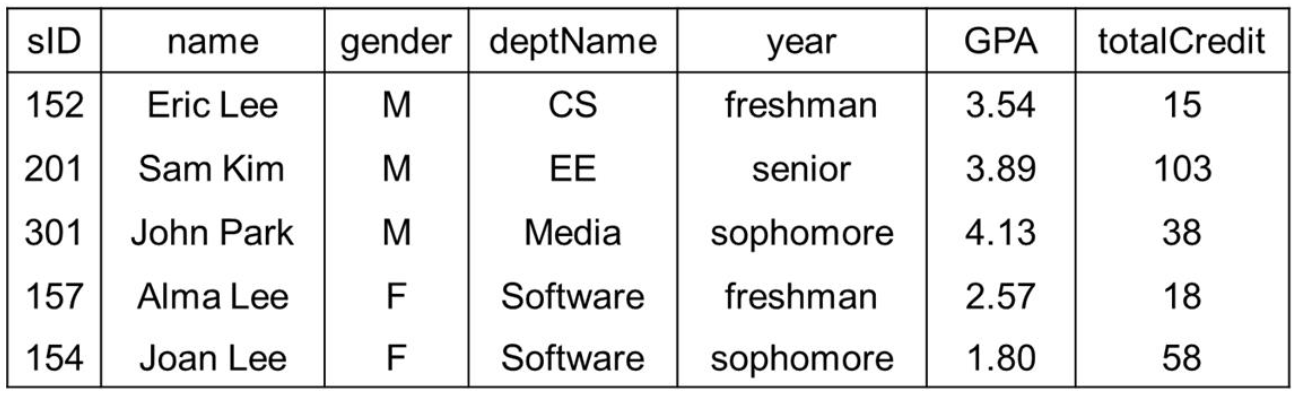
- 위는 Student 관계의 예제이다. 관계는 테이블 형식으로 표현한다.
- 위는 7개의 속성과 5개의 튜플을 가지고 있다.
1.2 똑같은 용어들
| Relational data model | (옜날방식)Network data model/Hierarchical data model |
|---|---|
| relation | table |
| tuple | record, row |
| attribute | column |
(1) 속성(attribute)
- attribute value로 가질 수 있는 값의 집합을 domain이라고 한다.
- 각 속성값은 해당 도메인의 원소(element)이다.
- 속성 값은 더이상 쪼갤 수 없는 값(atomic)이여야 한다. (관계형 모델의 중요한 성질)
- 정수, 실수, 문자, 문자열, 시간, 날짜, timestamp 등
- 더이상 쪼갤 수 없는 값이 아닌(non-atomic) 예제 : 집합(ex.전화번호:폰을 여러개가질 수 있으므로), 리스트, 복합값(ex.주소: 주소는 숫자, 문자,기호등으로 이루어진 복합값) 등
- 확장된 관계형 데이터모델은 non-atomic한 값들도 지원하나, 일반적인 데이터모델은 지원하지 않는다.
- 정수, 실수, 문자, 문자열, 시간, 날짜, timestamp 등
- 각 도메인은 NULL을 default로 가진다.
- NULL값 : 값이 입력되지 않은 것
1.3 관계 Schema와 Instance, 관계 Database
1.1의 예제에서 관계이름(Student)과 속성명(sID, name, gender, deptName, year, GPA, totalCredit)이 관계 스키마 // 5개의 튜플이 관계 인스턴스
📝관계스키마
- 관계 이름과 속성명을 나열한 것
- 통상 관계 스키마는 관계 이름과 속성명 외에도 각 속성의 자료형, 관계에 관련되는 무결성제약도 함께 표현한다.
📝관계인스턴스
-
각 속성 도메인 값의 모든 조합 (쉽게 말해 특정 시점에 테이블의 상태)
-
즉, 도메인의 Cartesian product의 부분 집합(아래에 설명)
-
을 attributes라고 하면 이 관계스키마
-
을 에 대한 Domain이라고 하면 관계인스턴스는 의 부분집합이다.
-
또는 n-tuples의 집합이다.()
📝 관계데이터베이스
- Relational DB = set of relations + set of integrity constraints
- 학생, 교수, 강의 같은 테이블 여러개 + 제약조건 여러개
Integrity constraints : 키 제약(Key constraint : primary key는 중복된 값을 가지지 못하는 제약), 엔티티 제약(Entity constraint : primary key는 NULL값을 가지지 못하는 제약), 참조 무결성 제약(Referential integrity constraint : foreign key는 NULL이거나 참조 릴레이션의 primary key 값과 동일해야 하는 제약) 등
1.4 대학 데이터베이스 예제
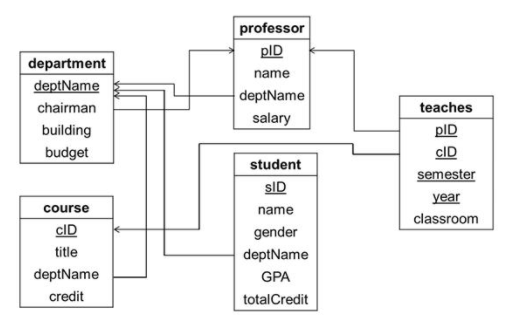
- 위 그림은 관계형 데이터베이스의 예제이다.
- 위 데이터베이스는 총 5개의 관계(table)로 구성된다.
- 각 relation에서 밑줄친 속성은 primary key이다.
- teaches relation의 primary key는 pID, cID, semester, year의 연결(codncatenation)이며 pID같은 속성 하나하나는 primary key가 아니다.
- 각 화살표는 참조 무결성 제약을 나타낸다.
- 예를 들어 teaches 관계의 cID 속성은 course 관계의 primary key 속성인 cID 속성을 참조하는 foreign key(외래 키)이다.
1.5 key
(1) Key의 종류
📝 Key : 어떤 속성의 집합 (Key⊆Relation)
-
key는 3가지 종류가 있다 :
-
Super Key(수퍼키)
-
릴레이션에서 튜플을 유일하게 식별할 수 있는 속성의 집합
-
e.g., 이름은 수퍼키 될 수 ❌, 학번은 수퍼키 될 수 ⭕,
이름+학번도 수퍼키될 수 ⭕
-
가장 큰 수퍼키는 Relation
-
-
-
Candidate Key(후보키)
- 유일성을 유지하면서 가장 적은(minimal) 수의 속성으로 구성된 키
- 수퍼키중에서 쓸모없는거 없애고 최소한의 수 가지고 식별할 수 있는 알맹이 키
-
Primary Key(기본키)
- 릴레이션에 1개이상의 후보키가 존재하면 그 중 하나를 기본키로 지정
-
기본키 ⊂ 후보키 ⊂ 수퍼키
(2) Key 예제
My student라는 relation이 student-id, name, national-id, address, phone이라는 attribute를 갖고있다고 가정하자.
여기서 하나도 겹치지 않는 유일한 속성은 student-id, national-id(신분증)이다.

1.6 참조 무결성 제약(외래키)
foreign key는 다른 테이블의 특정 row를 식별할 수 있게 해주는 컬럼 이지만, 외래키의 정의를 직접적으로 설명하는 것 보단 아래와 같이 상황에 따라 자연스럽게 녹아드는 개념이 더 잘 와닿으므로, 이 같은 방식으로 서술한다.
(1) 개념
참조 무결성 제약은 특정 속성에 나타나는 모든 "값"은 반드시 다른 속성에도 나타나야 한다는 것이다.
즉, 특성 속성에 나오는 모든 값은 ⊂ 다른 속성 값의 일부분 이어야 한다. 그리고, 참조 받는 속성은 반드시 그 테이블의 기본키이어야한다.
한 테이블의 참조하는 속성을 foreign key라 하고, 다른 테이블의 참조받는 속성은 Primary key이어야 한다.
- 참조 무결성 제약은 두 테이블에 존재하는 조건 혹은 관계를 “값”으로 표현하기 위해서 만들어 졌다.
- 참고로, 기존 계층/네트워크 데이터 모델에서는 데이터 간의 관계를 포인터로 표현하였다.
- 참조 무결성 제약(referential integrity constraint, 또는 referential constraint)는 관계형 데이터 모델에만 존재하는 제약이다.
- 관계형 데이터 모델을 기반으로 하는 객체-관계형 데이터 모델에서도 참조 무결성 제약은 존재한다.
(2) 예제
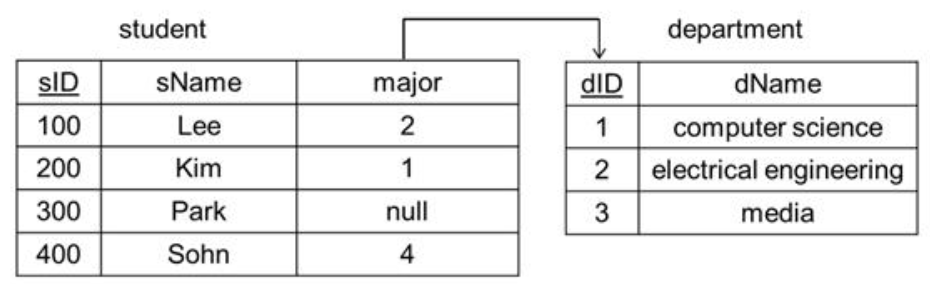
상기와같이 2개의 테이블이 있고, student의 major컬럼은 department의 dID를 참조하고 있는 외래키이다. 살펴보면, student 테이블에서 Lee 학생의 major속성 값은 2이며, 이는 department 테이블을 보면 electrical engineering을 전공하고 있음을 알 수 있다.
그러나 Sohn 학생은 major 속성 값 4에 대응이 되는 학과가 없어 문제가 있다. Park 학생은 major 값이 없는 null 값인데, 아직 학과가 결정되지 않았거나 또는 데이터가 존재하지 않거나 등으로 해석할 수 있어, 문제가 있는 것은 아니다.
즉, major속성 값은 아무런 제약 없이 임의의 값을 가질 수 없고, department의 dID 속성 값 중에서 나와야 의미가 있다. 이 경우, major 속성을 department(dID) 참조하는 외래 키(foreign key)라고 하며,student 테이블을 참조하는 테이블, department 테이블을 참조 받는 테이블이라고 한다.
참조 받는 속성은 반드시 그 테이블의 기본키이어야하며, 본 예제서도 dID가 department 테이블의 기본키임을 알 수 있다. 이는 student 관계의 특정 튜플과 department 관계의 특정 튜플이 관련이 있을 때(상기에서는 학생과 학과 간의 ‘전공’ 관계), department 관계의 primary key를 참조하여야 하기 때문이다. department 의 primary key를 참조하여야만, 반드시 department 관계의 하나 튜플이 특정된다.
또한 department 테이블의 <3,media> 튜플을 참조하는 튜플이 student 테이블에 없으며, 이는 참조 무결성 제약과 관련 없이 허용되는 현상이다.
1.7 데이터 사전(=system catalog)
(1) 개념
데이터 사전은 데이터베이스 시스템이 내부적으로 관리하는 데이터 장소이며, 데이터에 대한 데이터 즉 메타데이터를 관리한다.
데이터 사전이 저장 및 관리되는 데이터 상세는 다음과 같다 :
- name of tables : 테이블 명
- names, types, lengths of attributes of each relation : 각 테이블 속성의 이름,타입,길이
- names and definitions of views : 뷰의 이름과 정의
- integrity constraints : 무결성 제약조건
- User and accounting information, including passwords : 사용자에 대한 정보
- Statistical and descriptive data : 통계적 데이터
- 각 relation에서 tuple들의 갯수
- Physical file organization information
- 어떻게 테이블이 저장되어 있는지에 대한 정보(sequential/hash/⋯)
- 테이블의 물리적인 위치
- indices(index)에 대한 information : 검색을 효율적으로 하기위한 인덱스에 대한 정보
상용 데이터베이스 시스템은 사용자에게 투명하게 데이터 사전 접근을 허용하며, 사용자는 SQL 언어를 활용하여 데이터 사전에 속하는 데이터를 접근할 수 있다.
(2) 예제
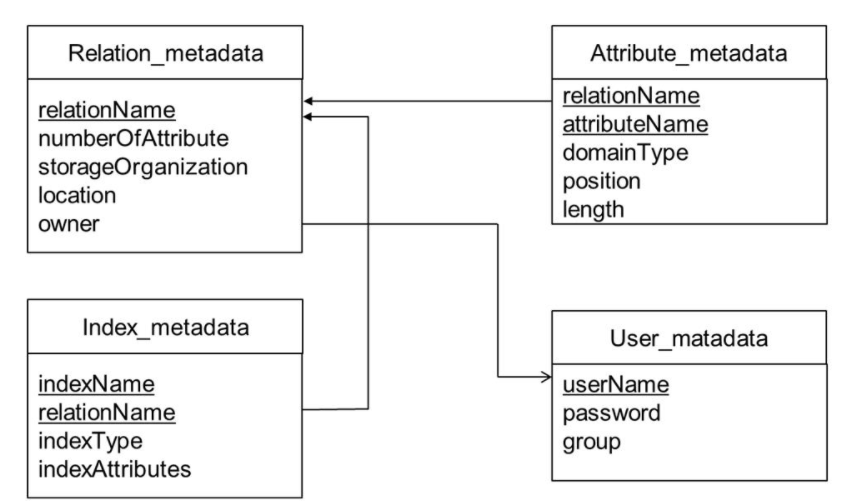
- 상기 그림은 메타데이터 정보를 일반적인 테이블 형식으로 저장/관리되고 있는 모습이다.
0x02 샘플 대학교 데이터베이스
(1) 7개의 table

본 책에서는 대학교 데이터베이스를 예제 데이터베이스로 사용한다. 총 7개의 테이블로 구성되어 있으며, 밑줄이 있는 속성 집합은 해당 테이블의 주 키를 표시한다. 또한 다수의 참조 무결성 제약이 존재한다.
(2) Schema Diagram
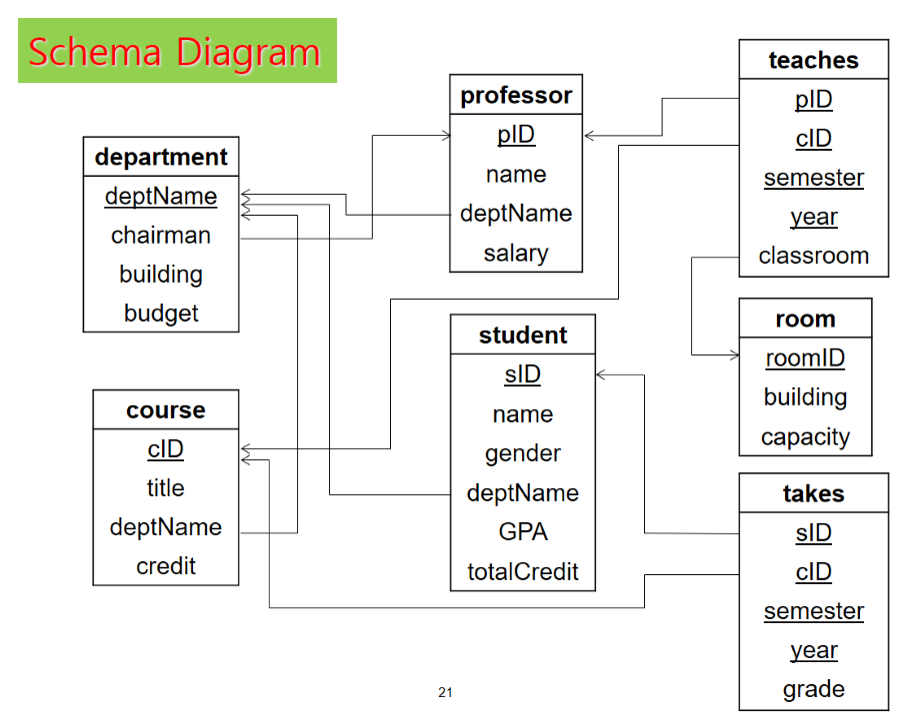
상기 그림은 대학교 데이터베이스를 스키마 다이어그램으로 표시한 것이다. 앞으로 본 책에서 언급되는 대부분 예제는 위의 대학교 데이터베이스 스키마를 사용하므로, 학생들은 이 다이어그램을 숙지하길 바란다.
각 테이블에 대한 예제 인스턴스는 다음과 같다. 예제 인스턴스는 테이블에 대한 이해 향상에 도움을 주려고 하는 것이며, 향후에 나오는 예제들이 예제 인스턴스를 가정하고 설명하지는 않는다.
(3) 각각의 table들 구성
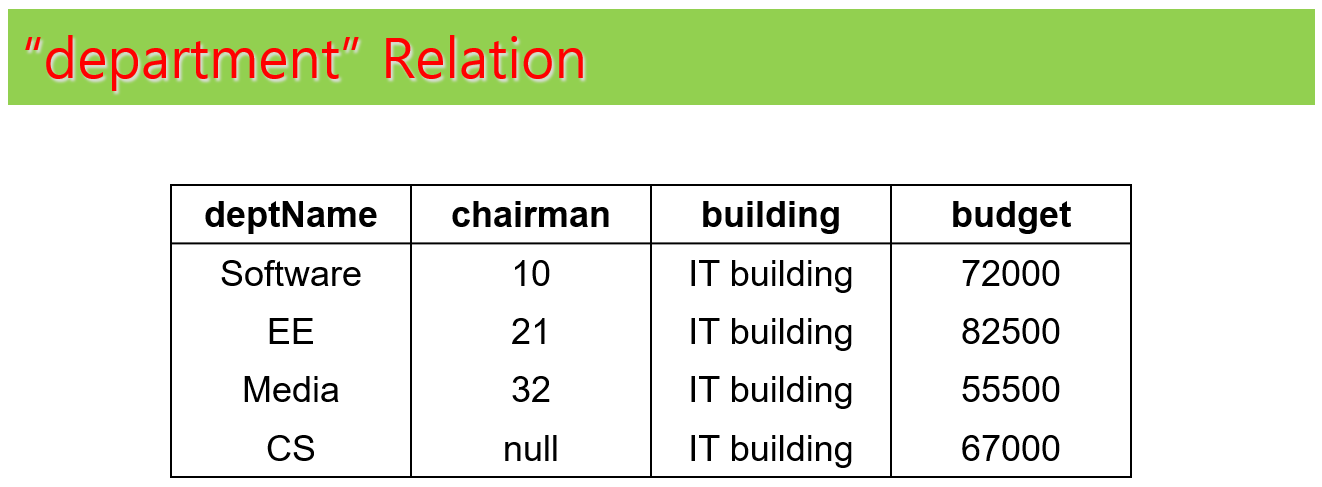
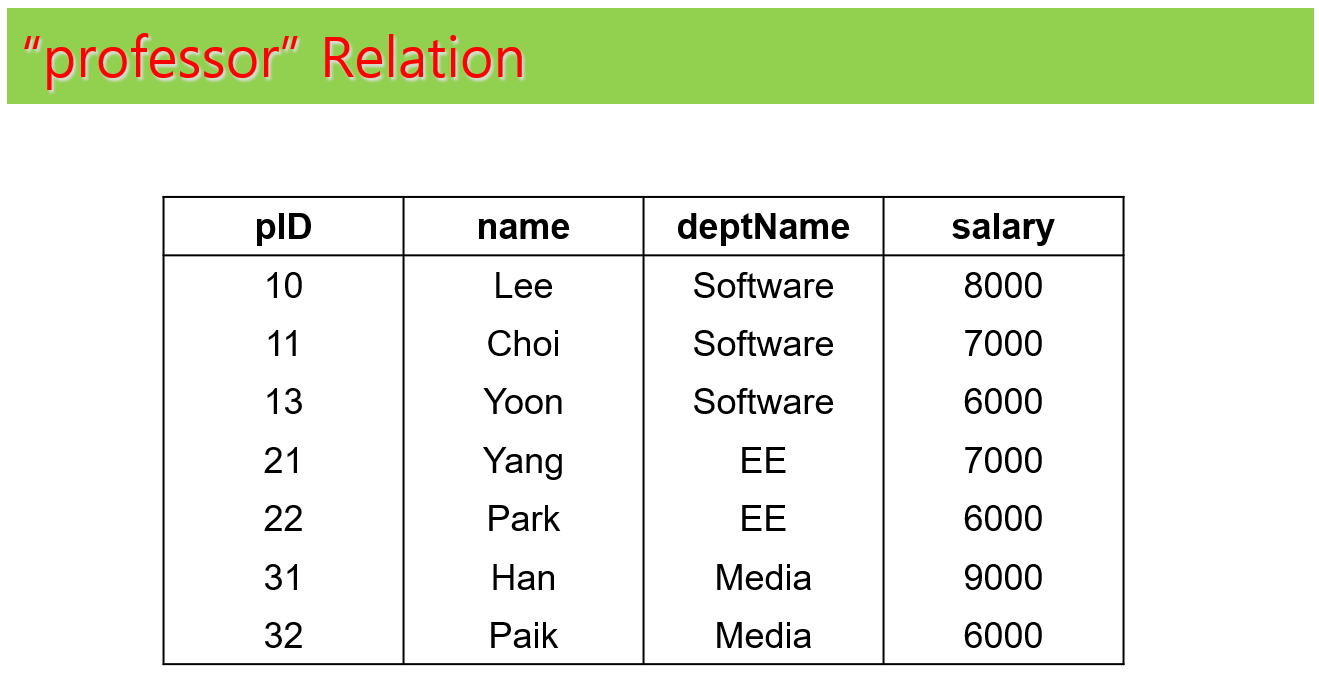
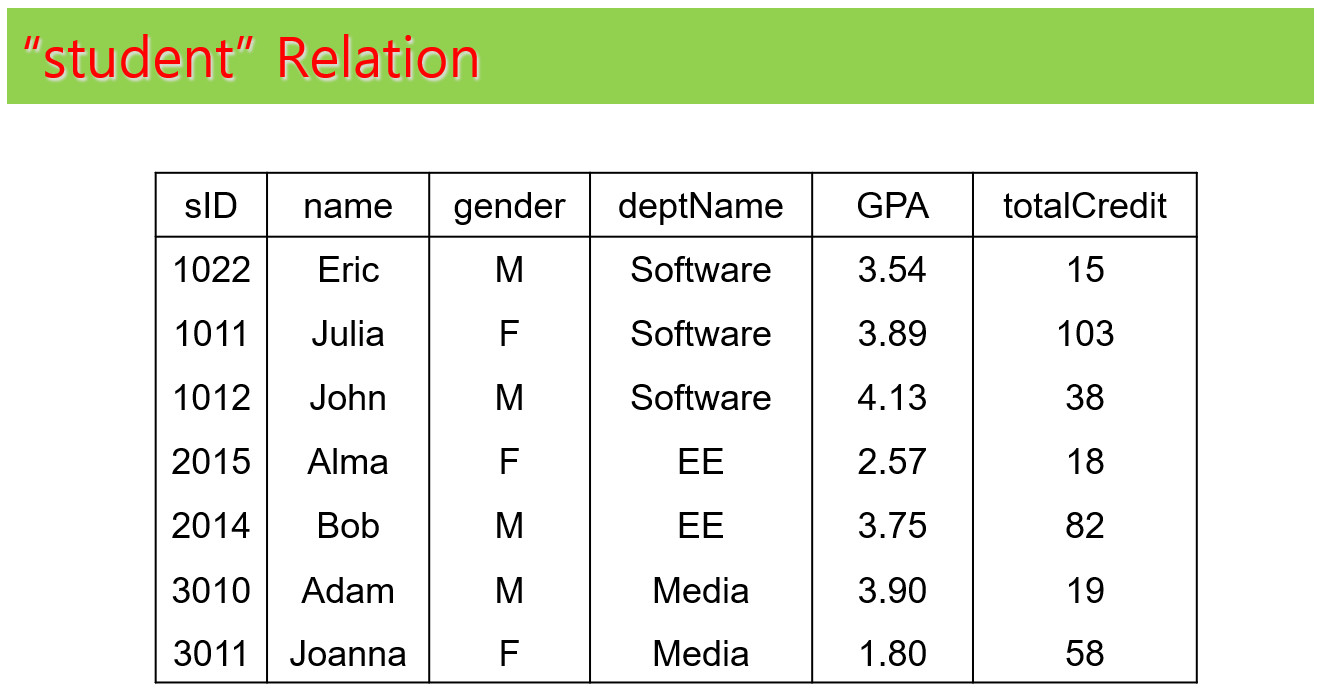
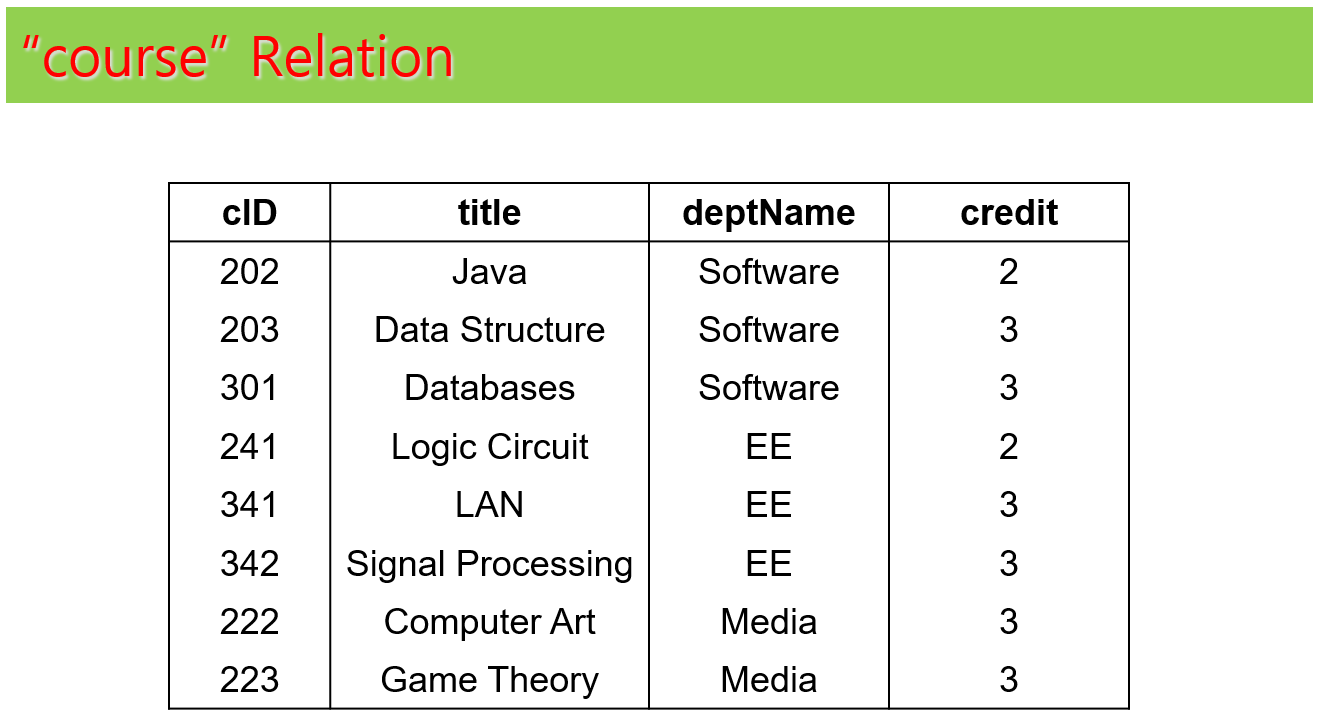
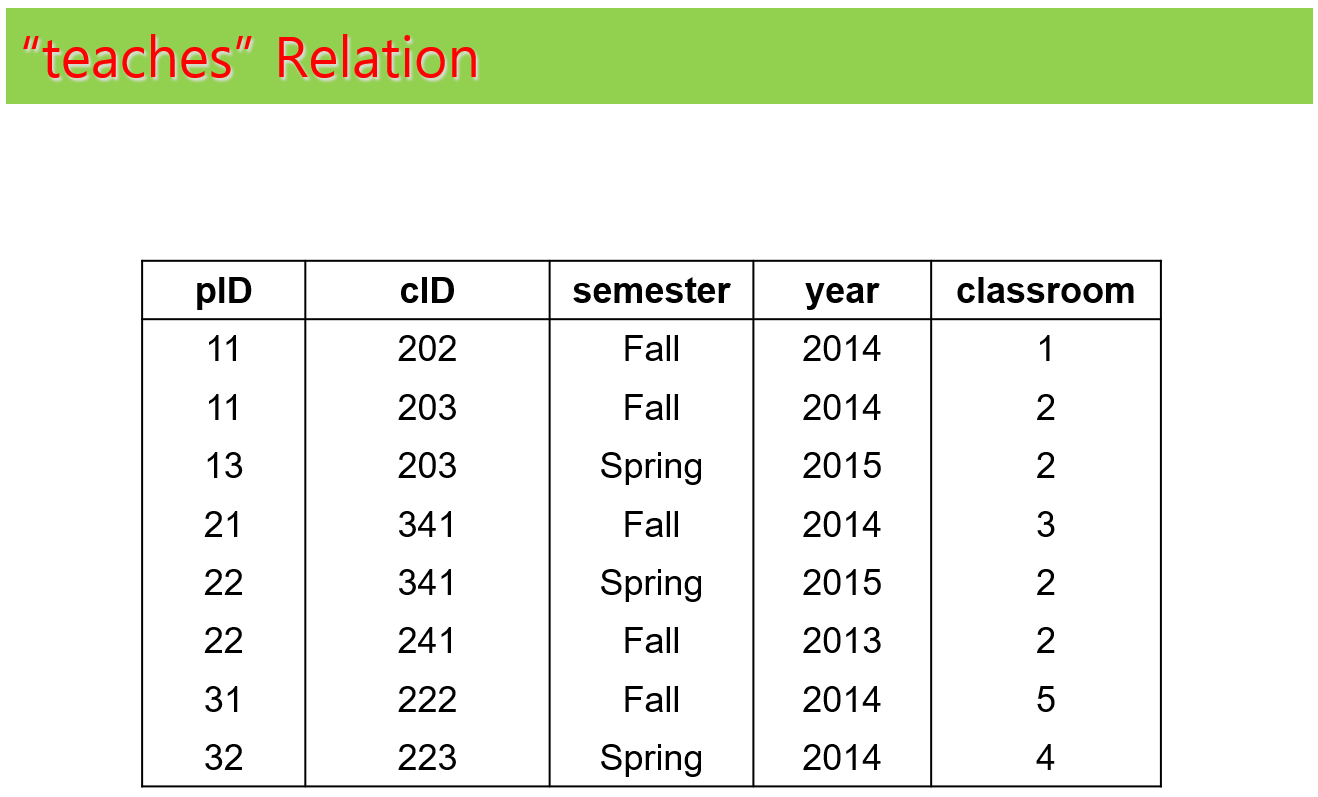
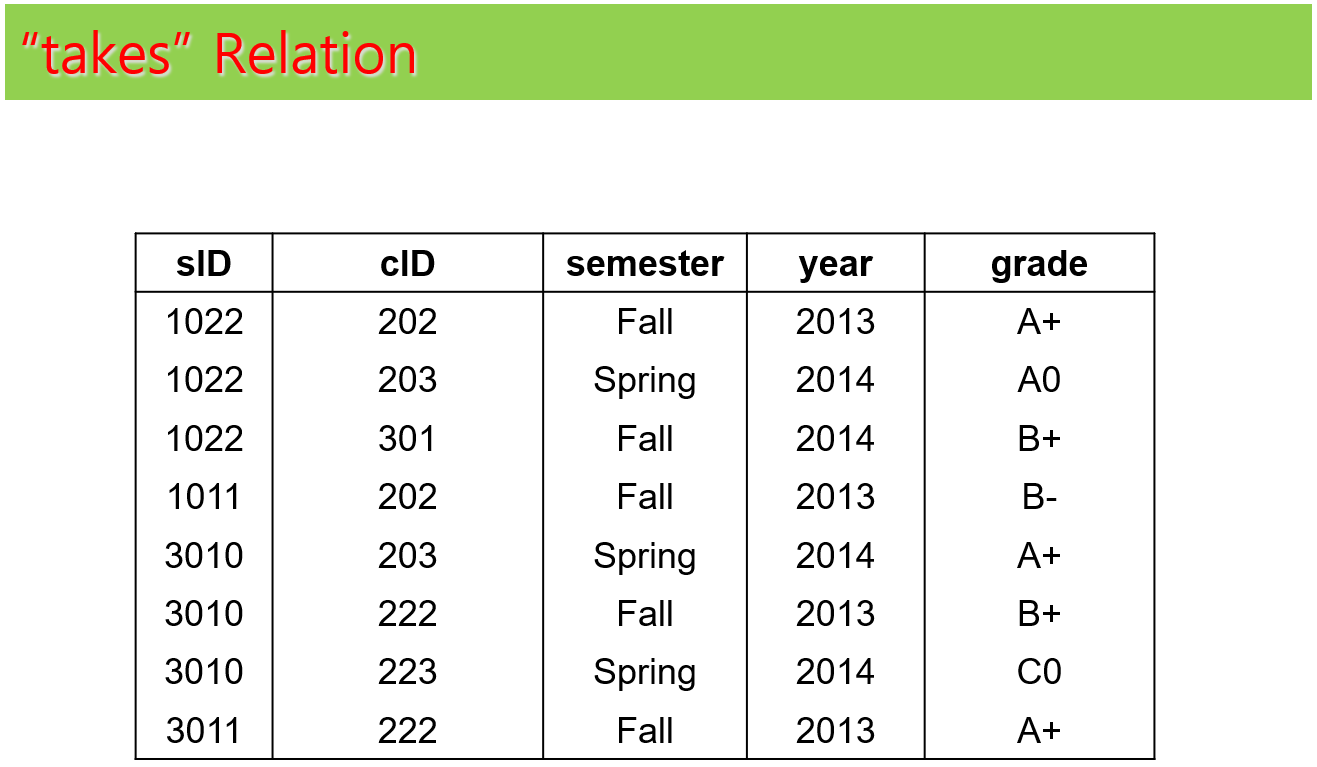
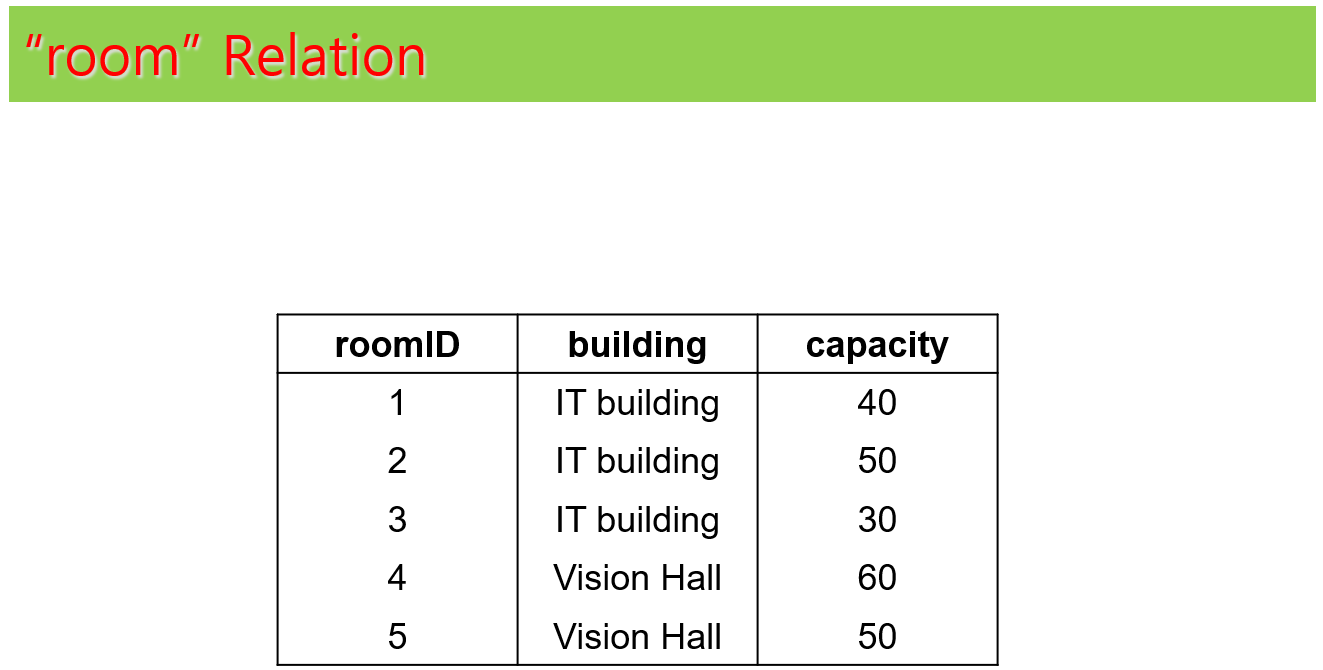
과제 테이블 구성
CREATE TABLE `Customer` (
`customer_id` varchar(10),
`customer_name` varchar(10),
`customer_street` varchar(50),
`customer_city` varchar(10),
PRIMARY KEY (`customer_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_general_ci;CREATE TABLE `Loan` (
`loan_number` varchar(10),
`amount` int,
PRIMARY KEY (`loan_number`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_general_ci;CREATE TABLE `Account` (
`account_number` varchar(10),
`balance` int ,
PRIMARY KEY (`account_number`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_general_ci;CREATE TABLE `Branch` (
`branch_name` varchar(10) ,
`branch_city` varchar(10) ,
`assets` int ,
PRIMARY KEY (`branch_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_general_ci;CREATE TABLE `Payment` (
`loan_number` varchar(10) ,
`payment_number` varchar(10) ,
`payment_amount` int ,
`payment_date` date ,
PRIMARY KEY (`loan_number`, `payment_number`),
FOREIGN KEY (`loan_number`) REFERENCES Loan (`loan_number`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_general_ci;CREATE TABLE `Borrower` (
`customer_id` varchar(10) ,
`loan_number` varchar(10) ,
FOREIGN KEY (`customer_id`) REFERENCES Customer (`customer_id`),
FOREIGN KEY (`loan_number`) REFERENCES Loan (`loan_number`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_general_ci;CREATE TABLE `Depositor` (
`customer_id` varchar(10) ,
`account_number` varchar(10) ,
`access_date` date ,
FOREIGN KEY (`customer_id`) REFERENCES Customer (`customer_id`),
FOREIGN KEY (`account_number`) REFERENCES Account (`account_number`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_general_ci;CREATE TABLE `Loan_Branch` (
`loan_number` varchar(10) ,
`branch_name` varchar(10) ,
FOREIGN KEY (`loan_number`) REFERENCES Loan (`loan_number`),
FOREIGN KEY (`branch_name`) REFERENCES Branch (`branch_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_general_ci;