
Django 데이터 조회(Read)
전 part에서 데이터 추가(Create)하는 방법을 알아보았다. 그러면서 데이터 조회하는 방법도 약간 알아보았는데, 이제 좀 더 세부적으로 알아보도록 하겠다.
- 이전 Part Review
{model}.objects.all(): 모든 데이터 조회{model}.objects.all().values(): 세부 데이터까지 조회
0x01. 조회하고 싶은 필드를 조회
{model}.objects.all().values('필드명')
values()는 컬럼으로 조회할 때 사용한다. SQL의
SELECT 컬럼명 FROM 테이블명; 과 동일
0x02. 정렬하여 조회
{model}.objects.order_by('필드명')- SQL과 마찬가지로 어떤 필드기준으로 정렬할 것인지를 인수로 넣어주어야 한다.

대시(-) 가 붙으면 내림차순 정렬을 한다.
0x03. 특정조건을 만족하는 데이터 조회


- 아래는 여러데이터를 조회하기 위해
filter를 사용하였고,name 필드에서코가 포함된 데이터를 조회한다.- 특정문자열 포함한 데이터 조회 :
{model}.objects.filter({필드명}__contains="{문자열}") 
- 특정문자열 포함한 데이터 조회 :
- 마찬가지로 여러데이터를 조회하기 위해
filter를 사용하였고,price 필드에서(2000,10000)범위 내에 있는 데이터를 조회한다.- 특정범위의 데이터 조회 :
{model}.objects.filter({필드명}__range=(시작, 끝)) 
- 특정범위의 데이터 조회 :
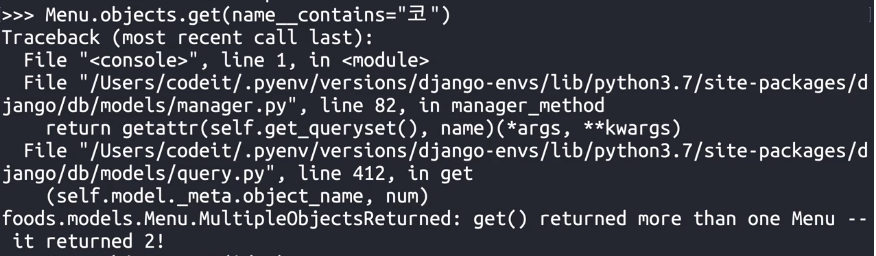
- get은
id필드처럼 겹치는 데이터가 없는 경우 사용한다. 만약 조건에 부합하는 여러 데이터를 조회할 경우 에러를 출력한다. 따라서 아래그림처럼 unique한 데이터에 get을 사용해야한다.

0x04. 정리하기

👀 좀 더 알아보기
0x01. 데이터 갯수 세기
- 데이터 갯수를 셀 땐 count를 사용한다.
rows = {model}.objects.count()
0x02. 특정 조건을 제외한 데이터 조회하기
- 특정 조건을 제외한 데이터를 조회하고 싶을 때 exclude를 사용한다.
data = {model}.objects.exclude(field=value)- 특정 field가 value인 데이터를 제외한 모든 데이터를 조회
0x03. 체인으로 연결해서 조회하기
- 여러가지 데이터 조회를 체인처럼 연결해서 사용할 수 있다.
data = {model}.objects.filter(price=10000).order_by('name')
가격(price)이 10,000원인 데이터를 이름(name)으로 정렬해서 조회한다.data = {model}.objects.filter(price=10000)
data = data.order_by('name')
이렇게 적어도 위와 똑같은 명령을 수행한다.
ORM을 통해서 데이터 조회를 복잡한 쿼리로 작성하다보면 체인으로 연결해서 한줄에 작성하는 경우가 많은데 이렇게 복잡한 조회 과정을 하나의 체인으로 묶는것을 지양해야한다. 그 이유는 첫째로, 체인으로 한 번에 묶는다고 더 빠른 속도로 동작하지 않기 때문이고 두번째로 코드의 가독성이 매우 떨어지기 때문이다.
📌 조건 키워드
- 모든 데이터 조회는 조건 키워드를 함께 사용하여 조회할 수 있으며,
{field_name}__{keyword}={condition}형태로 사용한다.
아래는 몇가지 조건 키워드의 예시이다.
1. __exact, __iexact
__exact는 대소문자를 구분해서 조건과 정확히 일치 하는지를 체크하며,
__iexact는 대소문자를 구분 하지 않고 일치하는 지를 체크한다.
data = {model}.objects.filter(name__iexact='chicken')
# 음식의 이름(name)이 'chicken'인 데이터를 모두 조회한다.
# 단, 대소문자를 구분하지 않는다.2. __contains, __icontains (이미 했던 것)
__contains는 지정한 문자열을 포함 하는지를 체크한다.
마찬가지로__icontains는 대소문자를 구분하지 않고 체크한다.
data = {model}.objects.filter(name__contains='chicken')
# 음식의 이름(name)에 'chicken'이 포함된 모든 데이터를 조회한다.
# 단, 대소문자를 구분한다. (__contains)3. __range (이미 했던 것)
- 지정한 범위 내에 포함 되는지 체크한다.
- 날짜, 숫자 문자 등 모든 데이터의 범위를 사용할 수 있으며 파이썬의 range와 비슷하다.
data = {model}.objects.filter(price__range=(1000,5000))
# 가격(price)이 1000원~5000원인 모든 데이터를 조회한다.import datetime
start_date = datetime.date(2020,8,12)
end_date = datetime.date(2020,9,12)
data = {model}.objects.filter(pub_date__range=(start_date,end_date))
# 생성일(pub_date)이 2020-08-12~2020-09-12인 모든 데이터를 조회한다.
# 이밖에도 많은 조건 키워드가 있다.4. __lt , __gt, __lte, __gte
__lt: 미만 (less-than),__gt: 초과 (greater-than)
__lte: 이하 (less-than-or-equal),__gte: 이상(greater-than-or-equal)
인 데이터를 조회한다.
data = {model}.objects.filter(age__gt=25)5. __in
- 주어진 리스트 안에 존재하는 자료를 조회한다.
data = {model}.objects.filter(age__in=[21,25,27])
hello world :)