What is Self-Supervised Learning(자기지도학습)?
Self-Supervised Learning (SSL) is a special type of representation learning that enables learning good data representation from unlabelled dataset.
출처 - https://neurips.cc/media/neurips-2021/Slides/21895.pdf
라벨이 없는 데이터 셋을 이용해 좋은 representataion을 배울 수 있게하는 representation 학습유형. 여기서 representation는 자기 자신의 특성이라고 이해하면 될 것 같다.
기존의 음성인식 모델들은 라벨링이 된 데이터를 활용해 훈련하는 과정을 거치는데, 이 때문에 많은 양의 데이터가 부족한 분야에서는 성능이 떨어지는 한계가 있다.
이와 달리, SSL은 라벨링이 되지 않은 데이터로 representation training 을 한 후 (pre-trained 모델) 라벨링된 데이터로 fine tuning 과정을 거쳐 성능을 향상 시킨다.
SSL은 input내에서 스스로 과제를 정해서 (pretext tasks = 핑계로 과제를 만들어내는) supervision 방식으로 모델을 학습한다.
Methods
학습방식으로는 크게 self-prediction 과 constrative learning으로 나뉜다.
Self-Prediction
각각의 데이터 샘플내에서 한 부분을 기반으로 다른 한 부분을 예측하는 과제를 말한다.
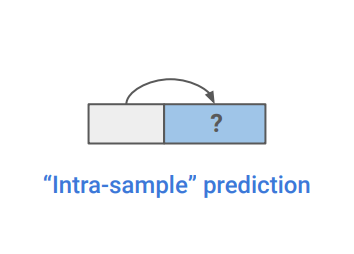
Self-prediction은 4가지 방식으로 나눠볼 수 있다.
-
Autoregressive generation
과거로 부터 미래를 예측하는 방식으로 연속적인 순서가 있는 데이터는 regression으로 모델링 될 수
있다. -
Masked generation
정보의 일부를 연속성에 상관없이 가리고, 가려지지 않은 부분을 통해 가려진 부분을 예측하는 방식이다. random masking으로 그 범위가 계속 변화하기 때문에 다양한 scale 혹은 size에 대한 학습이 가능하다. -
Innate relationship prediction
하나의 샘플 데이터에 변형(transformation)이 가해지더라도 원본 정보를 유지하거나, 요구되는 본질적 로직을 따른다는 믿음에서 그 관계를 예측하는 방식이다. -
Hybrid self-prediction
여러가지 prediction방식들을 혼합하는 방식.
Constrative learning
여러 데이터 샘플 간의 관계를 예측하는 과제를 말한다.
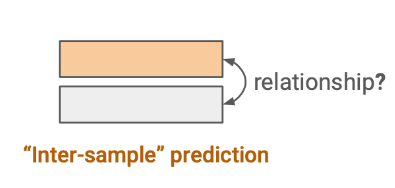
embedding space에서 유사한 샘플과 유사하지 않은 샘플들을 나누는 법을 훈련하는 것을 목적으로 한다.
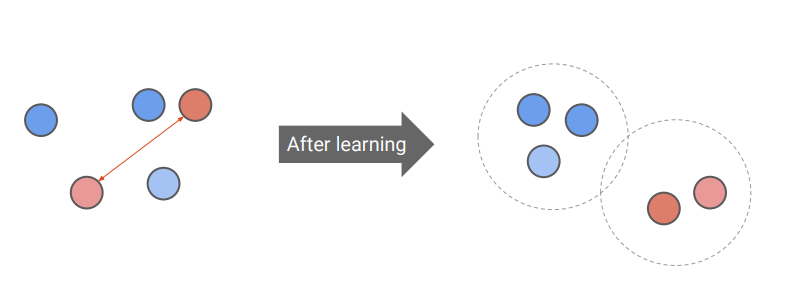
Constrative learning은 3가지로 나눌 수 있다.
-
Inter-sample classification
유사한 후보(positive) 와 유사하지 않은 후보(negative)들을 주고 어떤 것이 기준이되는 (anchor
data point)에 더 유사한지를 가려내는 것을 classification task이라한다. -
Feature clustering
클러스터링 알고리즘을 사용하여 샘플에 가짜 라벨을 붙이고 inter-sample classification을 진행하는
방식 -
Multiview coding
입력된 데이터의 두개 이상의 다른 view에 InfoNCE objective를 적용시키는 방식
*InfoNCE: categorical cross entropy loss를 사용해 노이스 샘플 세트에서 유사샘플을 가려낸다.
Masked Prediction vs Constrative Learning
Self-prediction 중 하나의 방식인 masked prediction이 fine tuning 성능이 constrative learning 보다 더 높다는 결과가 많아지고 있어 각광받고 있지만 실제로는 task마다, 데이터세트 의 사이즈마다 성능의 우위가 다르다.
Constrative learning이 샘플 전체에 대한 view간의 agreement를 학습함으로써 object에 대한 글로벌 패턴과 shape를 파악할 수 있고, masked prediction은 로컬 부분에 초점을 두고 쿼리 토큰에 대한 관계를 파악하여 로컬 패턴을 파악한다.
[reference]
https://neurips.cc/media/neurips-2021/Slides/21895.pdf
https://sanghyu.tistory.com/184
https://openreview.net/pdf?id=azCKuYyS74
