
[1주차] 1. 운영체제 개요
- 강의를 소개하고 운영체제의 정의, 목적, 컴퓨터 시스템 내에서의 기능이 무엇인지 알아본다.
- 운영체제의 기능인 CPU 스케줄링, 메모리 관리, 디스크 스케줄링과 운영체제의 종류에 대해 알아본다.
강의 목표
운영체제는 컴퓨터 하드웨어 바로 위에 설치되는 소프트웨어 계층으로서 모든 컴퓨터 시스템의 필수적인 부분이다. 본 강좌에서는 이와 같은 운영체제의 개념과 역할, 운영체제를 구성하는 각 요소 및 그 알고리즘의 핵심적인 부분에 대해 기초부터 학습한다.
운영체제란?
운영체제가 없던 시절
운영체제가 없던 시절에는 프로그래머가 직접 기계어 프로그램을 천공 카드 등의 매체로 기록하여 컴퓨터를 구동했다. 현재 운영체제가 대신 해주는 컴파일러 탑재, 라이브러리 링크, 메모리 로드 등의 모든 작업을 다 처리해야 했다.
현대의 운영체제
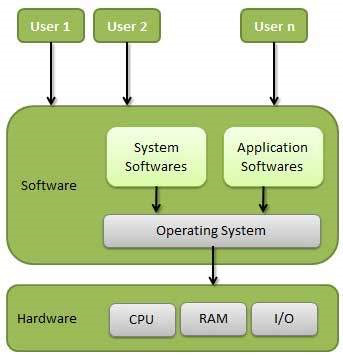
컴퓨터 하드웨어와 맞닿는 계층으로, 사용자 및 다른 소프트웨어와 하드웨어를 연결하는 소프트웨어(인터페이스) 계층이다.
즉, 소프트웨어 개발자와 일반 사용자는 하드웨어에 대해서 몰라도 되고, 직접 다룰 일이 거의 없어졌다.
운영체제의 목적
-
사용자나 소프트웨어가 편리하게 컴퓨터 시스템을 사용할 수 있도록 한다.
- 한 사용자가 여러 프로그램을 돌리더라도 동시에 실행되고 있는 듯한 환상을 제공한다.
- 여러 사용자가 한 컴퓨터로 동시에 작업을 하더라도 독자적 컴퓨터에서 수행되는 듯한 환상을 제공한다. (서버 환경)
-
컴퓨터 시스템의 자원을 효율적으로 관리해준다. (Scheduling)
- CPU, 메모리, I/O 장치 등의 한정되어 있는 자원을 각 사용자, 프로그램에 배분하는 역할을 한다.
- 어떻게 배분할거냐?
- 주어진 자원으로 최대한의 성능을 내도록 → 효율성
- 특정 사용자/프로그램의 지나친 불이익이 발생하지 않도록 → 형평성
컴퓨터 시스템의 구조
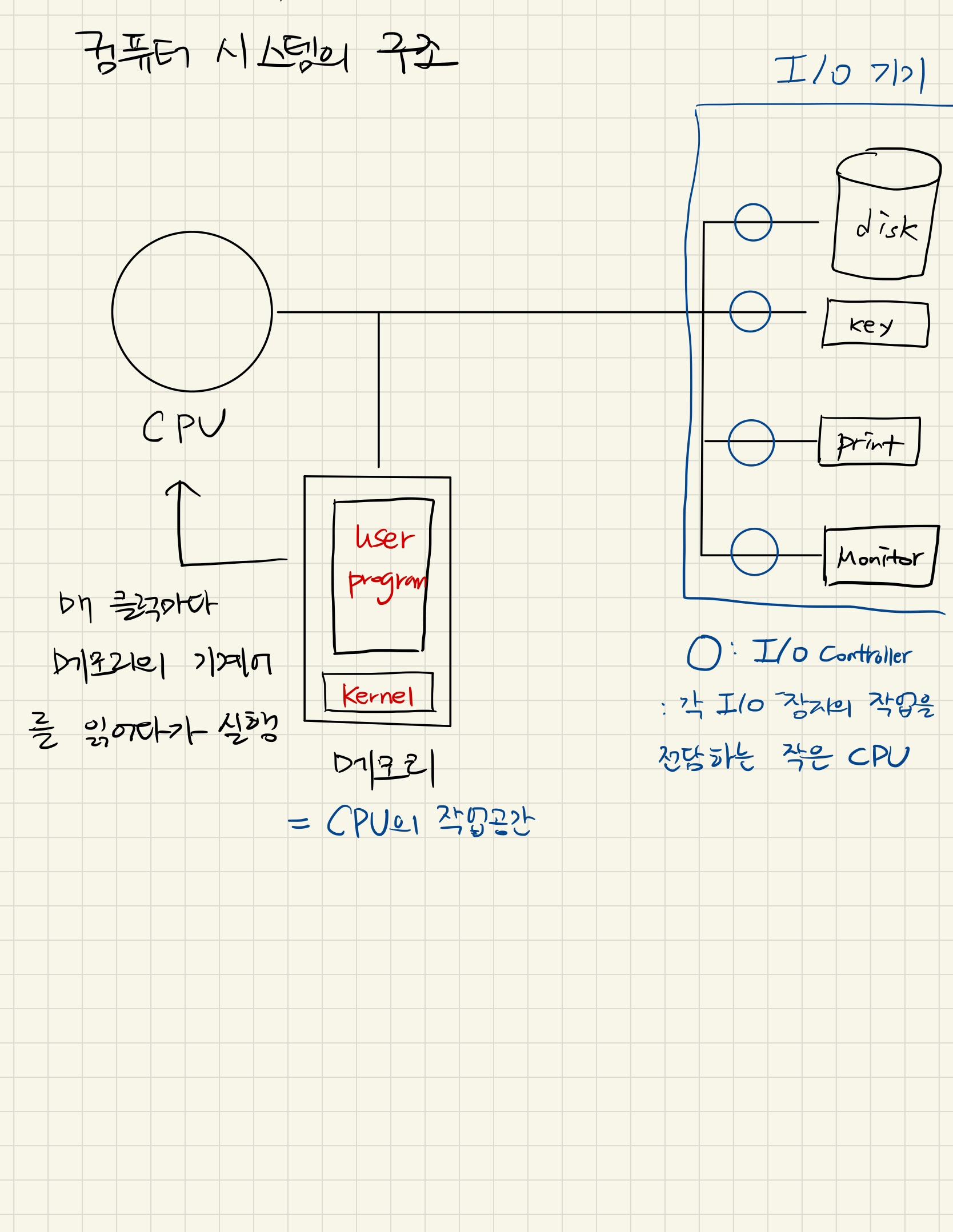
운영체제의 기능
CPU 스케줄링 : 어떤 프로그램에게 CPU 사용권을 줄 것인가
- CPU는 어떤 프로그램을 실행할 지 선택하지 않고 단지 가리키고 있는 메모리 주소에 있는 기계어를 실행할 뿐이다.
- 즉, 운영체제의 중요한 역할 중 하나는 CPU로 하여금 어느 프로그램의 기계어를 실행하도록 할 것인지 배정하는 일이다.
- 스케줄링할 때 중요한 것은 크게 어느 프로그램을 실행할 지, 얼마동안 사용권을 줄 것인지 두 가지이다.
- 이론적으로 운영체제 단독으로는 CPU 사용권을 얻어 실행중인 프로세스로부터 사용권을 뺏어올 수 없다. 이 과정에서는 하드웨어의 도움이 필요하다.
메모리 관리 : 한정된 메모리를 어떻게 쪼개쓸 것인가
- 컴퓨터 내에서 실행되고 있는 다양한 프로세스들에게 메모리를 어떻게 나누어줄 것인지도 운영체제가 수행한다.
디스크 스케줄링 : 디스크에 들어온 요청을 어떤 순서로 처리할까?
- 디스크는 CPU 대비 100만배정도 느리다. (메모리는 CPU 대비 100배 느리다.)
- 즉, 디스크 작업을 위해 CPU 사용을 낭비하는 것은 매우 효율을 떨어뜨리는 과정이다.
- 이러한 낭비를 줄이기 위해 디스크에 I/O 작업을 요청하는 동안 다른 프로세스에게 CPU 사용권이 넘어가게 되므로 동시에 많은 요청이 디스크에 들어올 수 있다.
- 이럴 때, 어느 요청부터 처리해야할 지에 대한 스케줄링도 운영체제의 역할이다.
- 디스크는 헤드가 직접 움직이면서 자료를 찾기 때문에 마치 엘리베이터 스케줄링과 유사한 방식으로 스케줄링을 한다.
인터럽트, 캐싱 : 빠른 CPU와 느린 I/O 장치간 속도차를 극복하자
- 캐싱(Caching) : 캐싱은 캐시(Cache)라고 하는 좀 더 빠른 메모리 영역으로 데이터를 가져와서 접근하는 방식을 말한다.
- 예를 들어, 디스크에 있는 데이터를 메모리에 가져오는 행위를 메모리에 캐싱한다라고 한다. 마찬가지로 메모리에 있는 데이터를 더 빠른 메모리인 CPU 메모리 캐시에 가져오는 것도 캐싱이라고 표현한다.
- 캐시는 데이터의 지역성(Locality)이라는 특성을 통해 성능을 개선한다. 한 번 접근된 데이터는 짧은 시간 내에 재접근될 확률이 높거나, 근처에 있는 데이터가 접근될 가능성이 높다는 특성이다. 즉, 반복 접근하는 데이터가 발생할 때 캐싱을 이용하면 상대적으로 느린 장치에 접근하는 시간을 줄일 수 있어 성능을 개선하는 것이다.
- 인터럽트(Interrupt) : 마이크로프로세서(CPU)가 프로그램을 실행하고 있을 때, 입출력 하드웨어 등의 장치에 예외상황이 발생하여 처리가 필요할 경우에 마이크로프로세서에게 알려 처리할 수 있도록 하는 것을 말한다
- CPU가 I/O 작업이 완료될 때까지 확인하고 있다면(마치 동기/블로킹되는 것이다) 100만배나 빠른 자원이기 때문에 큰 낭비가 발생한다.
- 그렇기 때문에, CPU는 I/O 작업이 진행되는 동안 당장 할 수 있는 일을 찾아서 실행하다가, I/O가 끝났음을 알리면(마치 비동기의 callback과 유사하다) 그 때 처리하는 방식으로 동작한다.
- 기계어를 실행할 때마다 CPU는 들어온 인터럽트가 있는지 인터럽트 라인을 확인한다.
- 인터럽트가 들어왔다면, 운영체제에게 CPU 제어권이 넘어가고 인터럽트의 이유에 해당하는 인터럽트 처리 루틴을 수행한다.
- 뭔가 직장생활과 비슷하다. 선배는 후배에게 일을 시키고 일을 잘 하나 보고 있는 것이 아니라 그 시간동안 자기 일을 하다가 다 됐다고 후배가 들고오면 그때 확인하는 식으로 일하는 느낌이다.
프로세스의 상태
- 프로세스 : 실행중인 프로그램(메모리에 올라간 상태)을 의미한다.
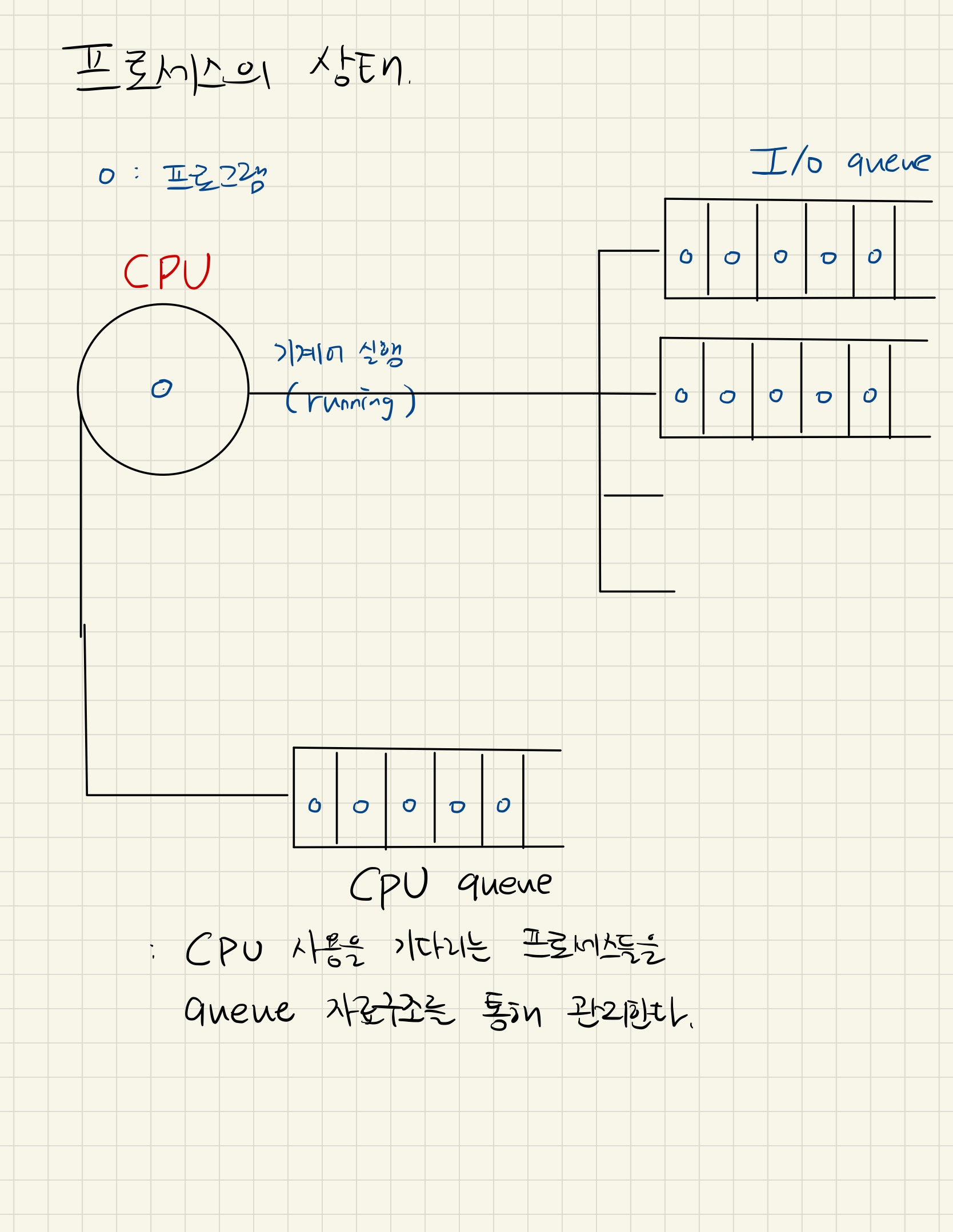
- 프로세스는 어느 자원을 많이 사용하냐에 따라 크게 두 종류로 나눌 수 있다.
- Inferactive Application : 사용자와 상호작용하기 때문에 I/O 작업이 빈번한 프로세스
- Scientific Application : 단순히 계산 작업이 많아 주로 CPU만 사용하는 프로세스
CPU 스케줄링
FCFS (First-Come First-Served)
- 프로세스들의 CPU burst time을 고려하지 않고, queue에 도착한 순서대로 CPU를 주는 알고리즘
- 도착한 순서에 따라서 성능의 변동이 심하다.
- CPU를 오래 사용할 프로세스부터 도착하는 경우에 평균 대기 시간이 길어진다.
SJF (Shortest-Job First)
- 프로세스들 중 이번 CPU burst time이 가장 짧은 프로세스부터 스케줄
- 이 스케줄링을 사용하면 minimum avg. waiting time을 보장한다.
- 그러나 Starvation (기아 현상) 이 발생할 가능성이 있다.
- 자신의 job보다 짧은 프로세스만 계속해서 도착하면 영원히 CPU를 얻을 수 없다.
RR (Round-Robin)
- 위의 스케줄링들은 CPU 사용권이 한번 넘어가면 뺏지 않는 비선점(non-preemption) 방식이다. 그렇기 때문에 형평성/효율성의 단점을 극복하기 힘든 점이 있다. 그래서 현대의 운영체제가 적용하는 해당 스케줄링은 선점형 스케줄링 방식을 이용한다.
- RR 방식에서는 각 프로세스에게 동일한 CPU 할당시간을 정해준다.
- 각 할당시간이 끝나면 인터럽트가 발생하여 프로세스는 CPU를 빼앗기고 다시 큐에 줄을 선다.
- n개의 프로세스가 있을 때에도 어떤 프로세스도 (n-1)*할당 시간 이상 기다리지 않는다. → 어느 정도 타협할만한 성능의 하한을 가진다.
- 대기시간이 프로세스의 CPU 사용시간에 비례한다.
- 짧게 쓰는 프로그램은 짧게 대기하고, 길게 쓰는 프로그램은 길게 대기한다는 뜻이므로 형평성을 가진다고 볼 수 있다.
메모리 관리
- 디스크에 있던 각 실행파일을 실행하면 프로그램이 메모리 상에 로드된다.
- 그런데 모든 프로그램을 다 메모리상에 올릴 수 없기 때문에 사이에 한 과정을 더 거친다.
- 디스크의 실행파일을 실행하면 가상 메모리 공간에 프로세스가 등록된다.
- 가상 메모리 공간에서 당장 필요한 부분만을 실제 메모리 상에 등록한다.
- 메모리에 공간이 부족하면, 사용하지 않는 메모리 공간을 다시 디스크 공간으로 쫓아낸다.
- 운영체제는 메모리 공간을 페이지라는 단위로 관리하는데, 어떤 페이지를 쫓아낼 것인지를 관리한다.
- CPU가 요청한 페이지 순서에 따라 LRU, LFU 등의 알고리즘을 활용하여 다음 쫓아낼 페이지를 정한다.
디스크 스케줄링
- 각 프로세스는 디스크에 I/O 요청을 한다.
- 프로세스가 요청한 디스크 상의 주소를 찾아서 전달해주어야 한다.
- 헤드가 회전하면서 최대한 효율적으로 정보를 찾으려면 어떤 식으로 스케줄링해야할 지를 운영체제가 정한다.
- 1 - 100 - 3 - 99 - 2 순으로 요청이 들어왔다면, 순서대로 처리할 경우 헤드의 동선 낭비가 커진다.
- 즉, CPU 스케줄링과 비슷한 방식의 스케줄링 방법들 중 최선의 방법을 택한다. (Scan 방식 : 엘리베이터의 스케줄링 방식)
저장장치 계층구조와 캐싱
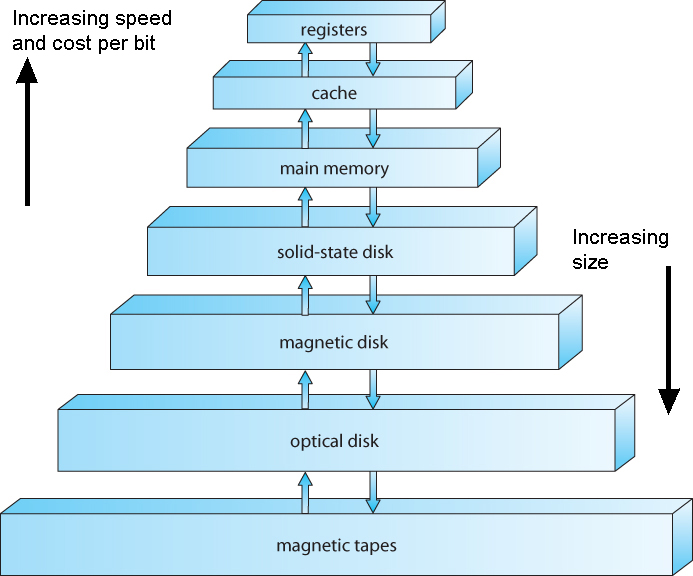
- 저장장치는 빠르지만 비싼 저장장치, 느리지만 저렴한 저장장치로 나눌 수 있다.
- 모든 저장장치를 빠른 저장장치로 구성하면 좋겠지만, 비용으로 인해 trade-off가 필요하다.
- 느린 저장장치와 빠른 저장장치의 완충을 위해 운영체제는 캐싱을 이용한다.
- 느린 저장장치에 있는 데이터를 빠른 저장장치에 백업해두고 필요할 때 사용하는 방법이다.
- 또, 저장장치는 휘발성/비휘발성으로 나눌 수 있다.
- main memory 위의 계층은 모두 휘발성 저장장치이다.
- SSD를 비롯한 하위 계층은 모두 전원이 꺼져도 저장이 가능한 비휘발성 저장장치이다.
- 저장장치를 Executable한지, 안한지로 나눌 수 있다.
- CPU가 직접 접근한 매체인지 아닌지를 나누는 것이다. Memory 이상의 계층에 있어야만 CPU가 접근해서 실행할 수 있다.
- 캐싱 또한 한정된 공간 상에서 이루어지기 때문에 스케줄링이 중요하다.
반효경 교수님의 운영체제 강의를 듣고 정리한 내용입니다.

천천히, 하지만 꾸준히 그리고 열심히