
반효경 교수님의 운영체제 강의와 Operating System Concepts 10th ed. 를 참고하였습니다.
프로그램의 실행 과정
-
파일 시스템의 실행 파일을 실행하면, 메모리에 올라가서 프로세스가 된다.
- 메인 메모리 상에는 커널이 상주하고 있고, 남은 공간에 사용자 프로그램이 실행된다.
-
사실은 이 사이에 한 과정을 더 거친다.
- 각 프로그램은 0번부터 시작하는 자신만의 가상 메모리를 가진다.
- 가상 메모리 중에서 실제 메모리 상에 등록돼있는 부분을 제외하고는 Swap area에 있게 된다.
-
논리 주소(가상 메모리)와 물리 주소는 다른 주소이기 때문에 주소 변환이 필요하다.
가상 메모리는 code, data, heap, stack 영역이 존재한다.
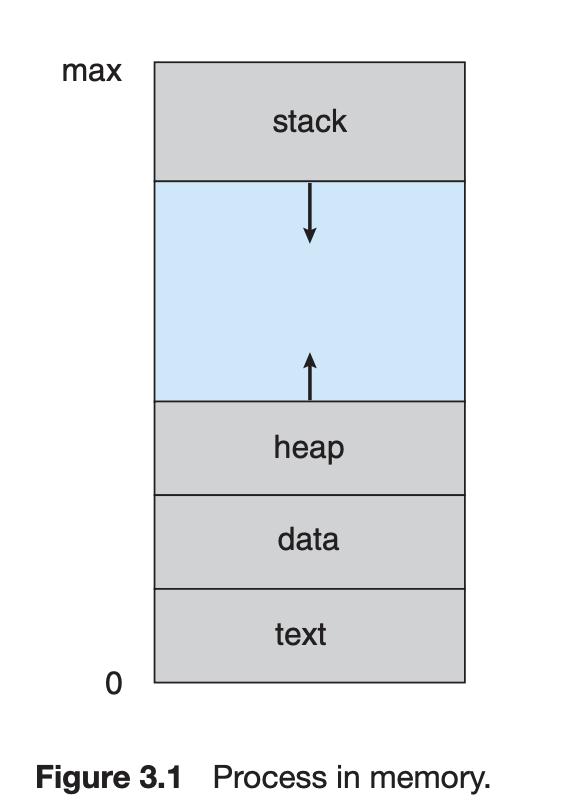
code(text)영역에는 우리가 작성한 코드가 컴파일을 거쳐 기계어 형태로 존재하고 있다.
data영역에는 전역변수나 프로그램이 시작해서 종료할 때까지 남아있는 데이터가 저장된다.
heap영역에는 런타임 동안 동적으로 할당되는 공간이다. (new로 생성한 객체 등)
stack영역에는 함수 호출과 리턴에 관련한 정보, 지역변수 등을 저장한다.
커널 주소 공간의 내용
code영역- 시스템 콜, 인터럽트 처리 코드
- 자원 관리를 위한 코드
- 편리한 서비스 제공을 위한(I/O 작업 등) 코드
data영역- 모든 하드웨어들을 관리하기 위한 자료구조
- 모든 프로세스들을 관리하기 위한 자료구조
stack영역- 커널을 사용하는 사용자 프로그램의 관리를 위해 존재한다.
- 어떤 프로세스가 시스템 콜을 실행했느냐에 따라 스택을 배정한다.
사용자 프로그램이 사용하는 함수
- 사용자 정의 함수
- 자신의 프로그램에서 정의한 함수
- 라이브러리 함수
- 자신의 프로그램에서 정의하지 않고 갖다 쓴 함수
- 자신이 작성하진 않았지만 자신의 프로그램 실행 파일에 포함되어 있다.
- 즉, 자신의 주소공간에 있는 명령어를 실행하는 것이다.
- 커널 함수
- 시스템 콜을 통해서 운영체제의 함수를 실행하는 것
프로세스의 개념
-
실행중인 프로그램을 말한다.
-
프로세스의 문맥(CPU 사용량, 메모리 사용량, 파일을 얼마나 열고 있는가 등)
-
CPU 수행 상태를 나타내는 하드웨어 문맥
- register(Program Counter): CPU에서 어디를 실행하는가, register에는 어떤 값을 넣고 있었나
-
프로세스의 주소 공간
-
프로세스 관련 커널 자료 구조
- PCB, Kernel stack
-
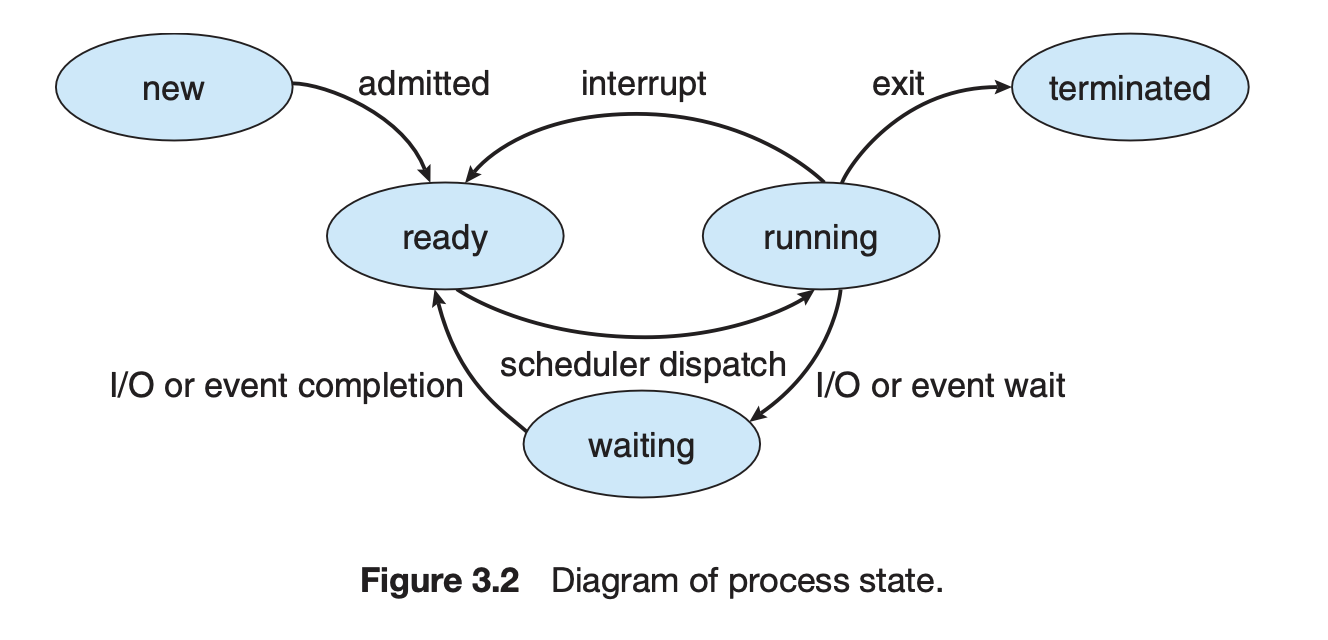
프로세스의 상태
-
프로세스가 생성중일 때,
new상태라고 부른다. -
프로세서가 하나이기 때문에, 매 순간 기계어를 실행하는 하나의 프로세스를
running상태에 있다고 부른다. -
CPU 사용을 위해 기다리고 있는 프로세스들을
ready상태에 있다고 부른다. -
현재 CPU를 넘겨받아도 당장 실행할 수 없는 프로세스들(I/O 작업 대기)을
blocked(wait, sleep)상태에 있다고 부른다.- 기다리던 작업이 끝나면 인터럽트를 발생시켜 운영체제가 확인한 다음 프로세스의 상태를
ready로 바꾼다.
- 기다리던 작업이 끝나면 인터럽트를 발생시켜 운영체제가 확인한 다음 프로세스의 상태를
-
프로세스의 작업이 완료되면
terminated상태가 된다. -
운영체제는 자신의 data영역에 queue를 만들어 프로세스들을 관리한다.
프로세스가 자신의 CPU 제어권을 내놓는 경우
- (Timer) Interrupt에 의해 더 사용하고 싶은데 내어놓는 경우
- 자신의 일을 모두 마쳤을 때
- I/O 작업을 대기하는 경우
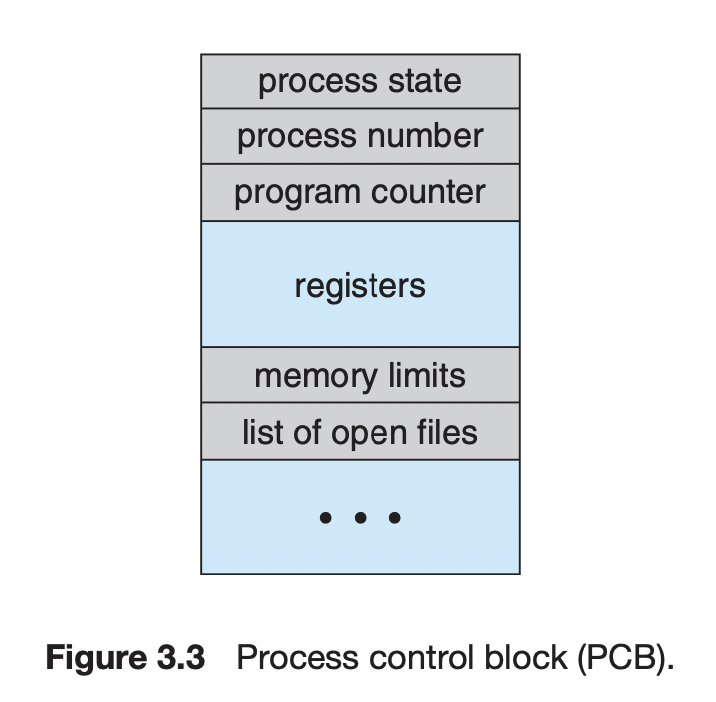
PCB
-
PCB에는 Linked list 형태의 자료구조인 queue로 프로세스를 관리하기 위해
pointer변수를 가지고 있다. -
그 외에 프로세스의 우선순위, Process ID, 스케줄링 정보 등을 가지고 있다.
PCB에는 program counter와 register는 왜 있을까?
실제로 Program counter와 register는 CPU가 이미 가지고 있는 값이다. 그런데 PCB는 왜 프로세스마다 이런 정보를 가지고 있을까?
우리가 사용하는 OS는 시분할 시스템이기 때문에, CPU 사용권을 프로세스마다 일정 시간 간격마다 나누어 사용하게 된다. 만일, 프로세스가 실행 중에 다른 프로세스에게 넘어가면 현재 Program counter, register값은 새 프로세스에 의해 대체될 것이다. 그렇기 때문에 다른 프로세스에게 CPU를 넘겨줬다가 다시 프로세스를 이어서 실행하려면 그 프로세스가 실행중이던 문맥(context)이 필요하다. 그 중에서, 현재 레지스터에 담고 있던 값, 실행하던 메모리 주소는 필수적일 것이다. 그렇기 때문에 운영체제가 프로세스 별로 해당 정보를 백업해두고 관리하는 것이다.
문맥 교환(Context Switch)
- 새 프로세스의 상태를 PCB에서 읽어옴
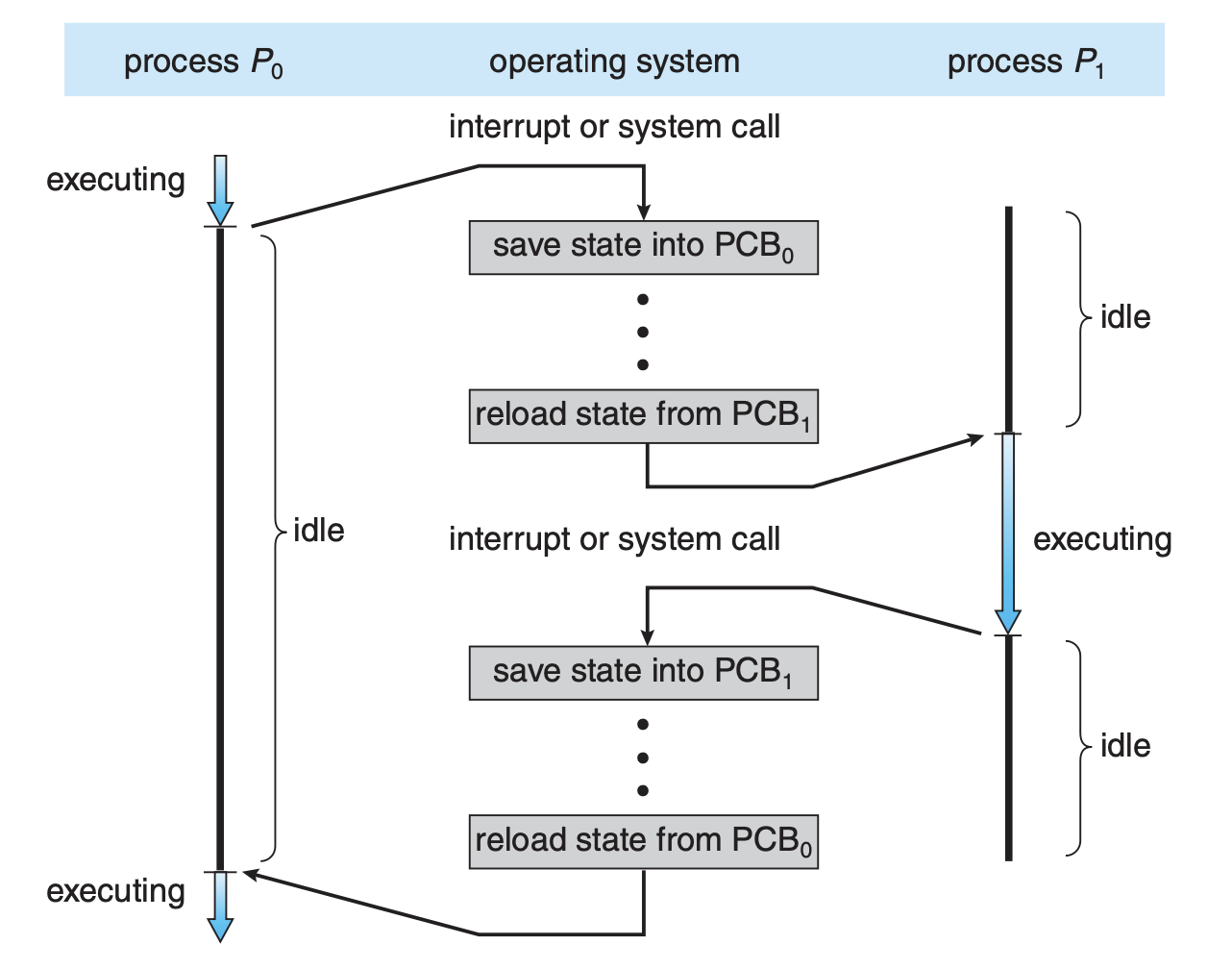
- CPU를 한 프로세스에서 다른 프로세스로 넘겨주는 과정
- CPU가 다른 프로세스에게 넘어갈 때 운영체제는 다음을 수행
- 기존 프로세스의 상태를 PCB에 저장
- 단, 사용자 프로세스에서 운영체제로 CPU가 넘어가는 것을 문맥 교환이라고 하지는 않는다.
- 이 때에도 일부 context를 저장하긴 하지만, cache memory flush와 같은 큰 overhead가 발생하지 않는다.
프로세스를 스케줄링하기 위한 Queue
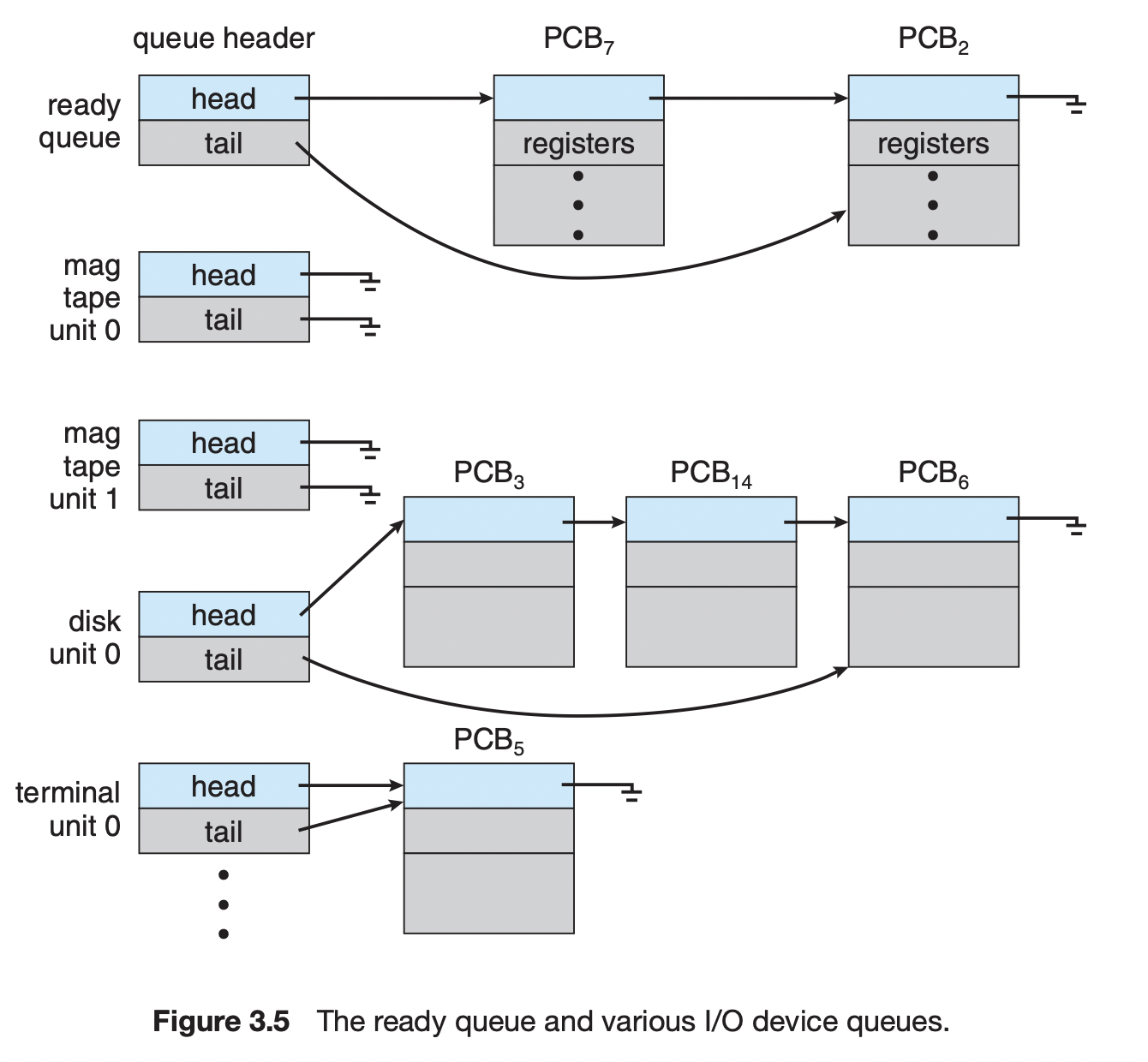
Job queue: 현재 시스템 내에 있는 모든 프로세스의 집합
-
Ready queue: 현재 메모리 내에 있으면서 CPU를 받으면 즉시 실행 가능한 프로세스의 집합 -
Device queues: I/O device의 처리를 기다리는 프로세스의 집합
프로세스 스케줄링 큐의 모습
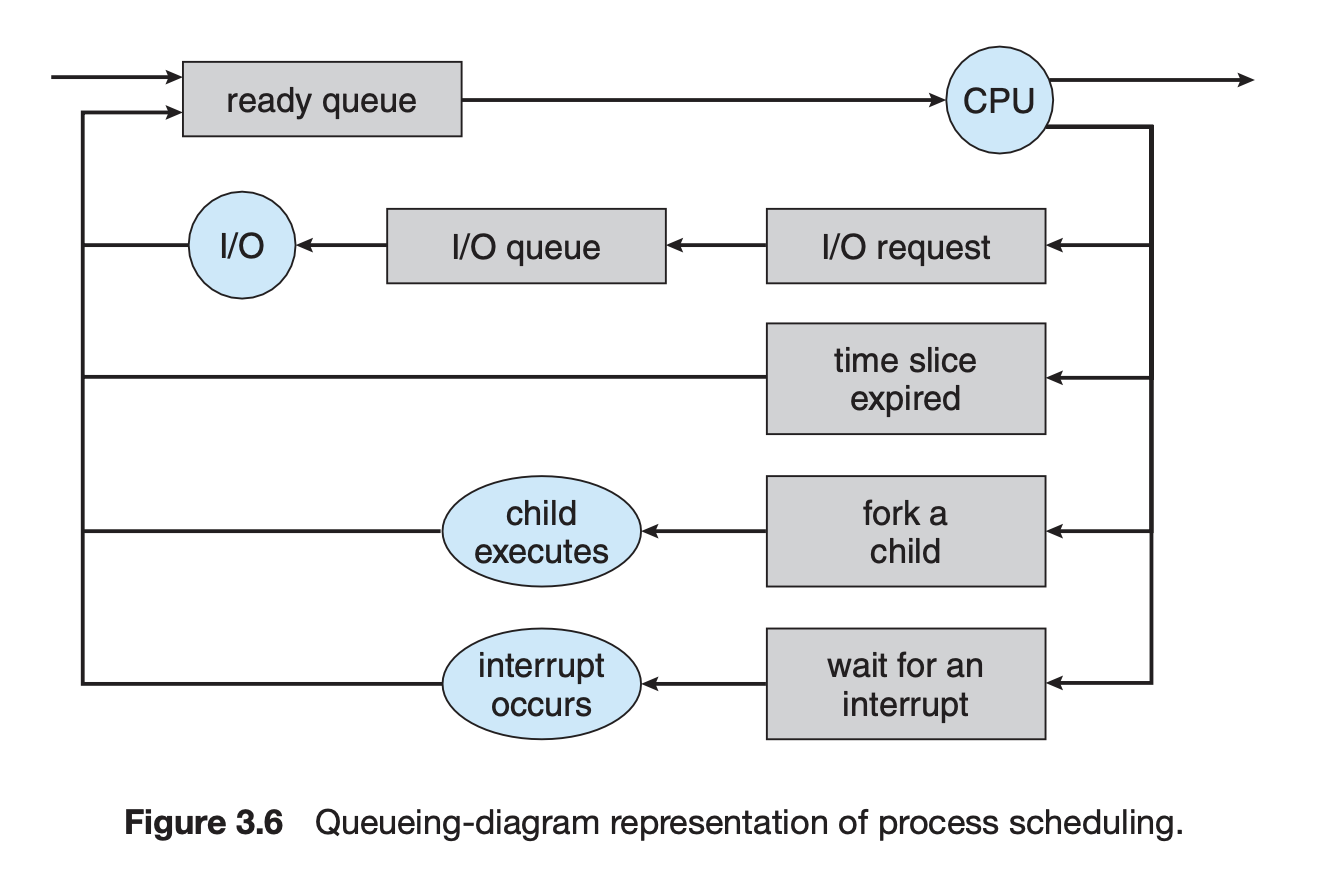
스케줄러 (Scheduler)
Long-term scheduler(job scheduler)
- 시작 프로세스 중 어떤 것들을 reday queue로 보낼지 결정하는 스케줄링을 담당한다.
- 즉, 프로세스를 메모리에 올리는 역할을 관장하므로
degree of Multiprogramming을 제어한다. - 현대의 시분할 운영체제에는 대부분 없다. (일단 생성되면 무조건 ready queue로 옮긴다.)
time-sharing systems such as UNIX and Microsoft Windows systems often have no long-term scheduler but simply put every new process in memory for the short-term scheduler.
Short-term scheduler(CPU scheduler)
- ready queue의 프로세스 중 어떤 프로세스를 다음 번에 running 시킬지 결정한다.
- 프로세스가 CPU를 사용하는 시간은 매우 짧기 때문에, 스케줄링 속도가 매우 빨라야 한다.
Because of the short time between executions, the short-term scheduler must be fast. If it takes 10 milliseconds to decide to execute a process for 100 milliseconds, then 10/(100+10) = 9 percent of the CPU is being wasted simply for scheduling the work.
- 100ms 단위로 실행되는 시분할 환경에서 스케줄링에 10ms만 쓰여도 CPU 성능의 9%는 낭비되고 있는 셈이다.
Medium-term scheduler(Swapper)
- 현대 운영체제에서는 장기 스케줄러를 두지 않고 있다.
- 그럼 동시에 무수한 프로그램을 실행시켜서 메모리에 올리면 프로세스 간 메모리 경합이 일어나 문제가 발생한다. 그럴 땐 어떡해야 할까?
- 그래서 현대 운영체제는 중기 스케줄러를 채택하였다.
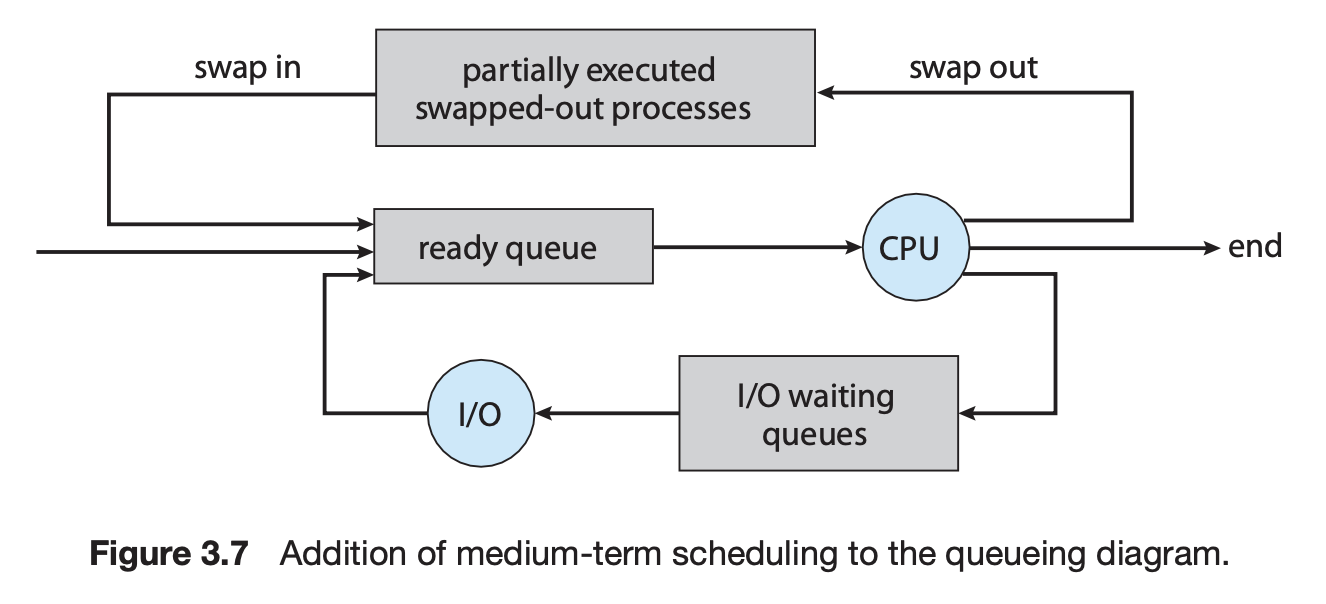
- 너무 많은 메모리가 사용되고 있으면 적절히 프로세스를 메모리에서 쫓아내는 역할을 한다.
- swap out한 경우 더 이상 실행하지 못하는 프로세스는
Suspended상태가 된다. - 외부에서 resume해야만 다시 Active 상태가 된다.
- swap out한 경우 더 이상 실행하지 못하는 프로세스는
프로그램의 실행
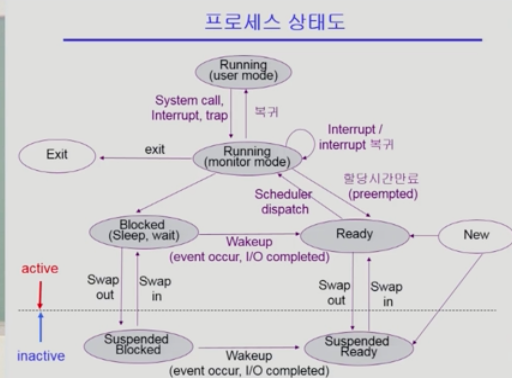
Running상태에는 두 가지 모드가 있다.- 커널 모드에서 실행되는 경우, 사용자 모드에서 실행되는 경우이다.
- 커널 모드에서 실행되더라도, 직전까지 실행되던 프로세스가 running 한다고 말한다.
- 일반적으로 운영체제가 running중이다라고는 말하지 않기 때문이다.
- 심지어, 다른 프로세스에 의한 인터럽트로 운영체제에게 CPU를 뺏겨도 마찬가지이다.
Suspended에도 두 가지 종류가 있다.Blocked상태에서 swap되는 경우Ready상태에서 swap되는 경우Suspended상태에서는 메모리를 빼앗기지만, I/O 작업의 완료 등은 처리할 수 있다.- Suspended Blocked에서 Suspended Ready로는 변경될 수 있다.
Thread
A thread is basic unit of CPU utilization
스레드는 프로그램의 실행 단위이다. 각 스레드는 독자적인 ID, program counter, register set, stack을 가진다. 우리가 배운 프로세스들은 스레드가 하나인 프로세스라고 볼 수 있다. (traditional/heavyweight process)
Multi-Thread
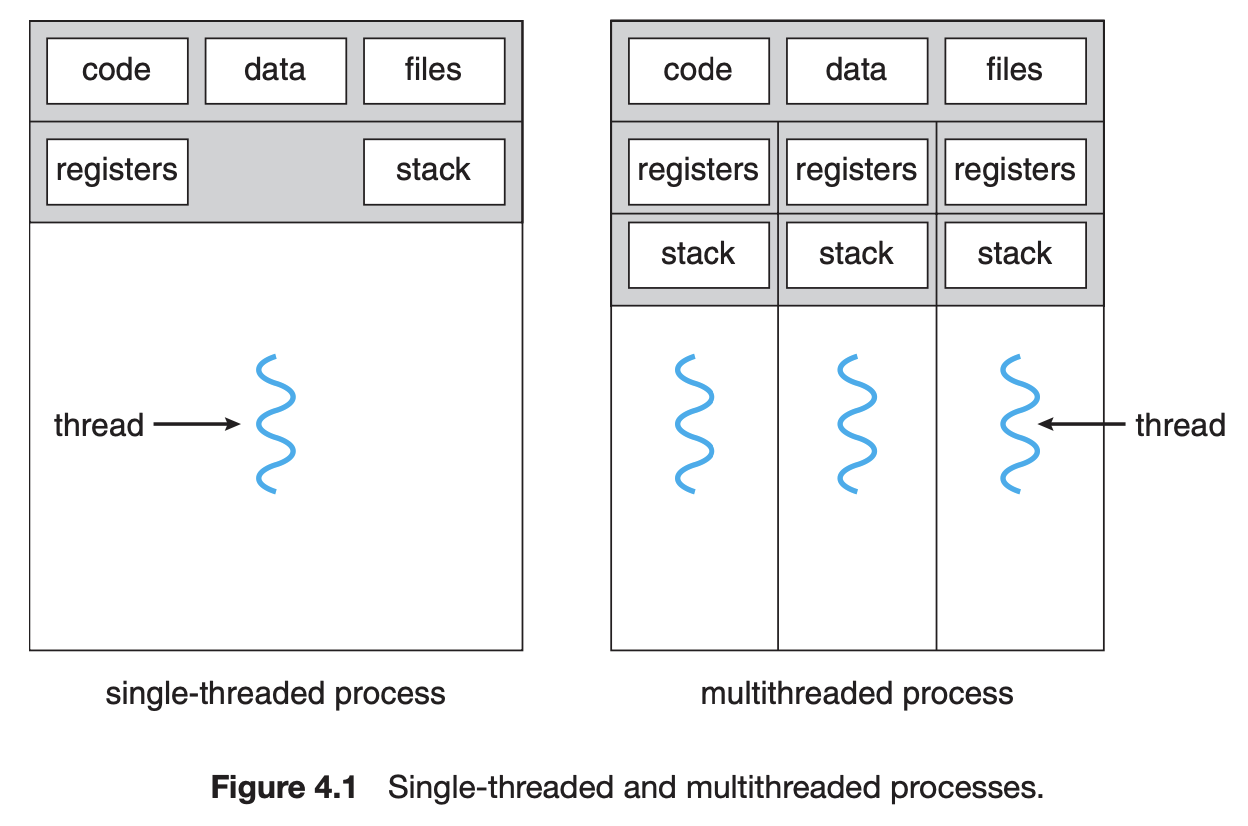
동일한 코드를 수행하는 프로그램에서 동시에 다른 작업을 할 때, 프로세스로 작업을 관리한다면 Code, data 등의 중복된 내용의 메모리 영역이 낭비된다. 그런 경우 스레드를 여러 개 만드는 것이 효과적일 수 있다. 단일 프로세스의 주소공간 내에서 code와 data, heap 영역을 공유하며 실행될 수 있기 때문이다.
Multi-Thread의 장점
Responsiveness: 다중 스레드로 구성된 태스크 구조에서는 하나의 서버 스레드가 blocked (waiting) 상태인 동안에도 동일한 태스크 내의 다른 스레드가 실행되어 빠른 처리를 할 수 있다.
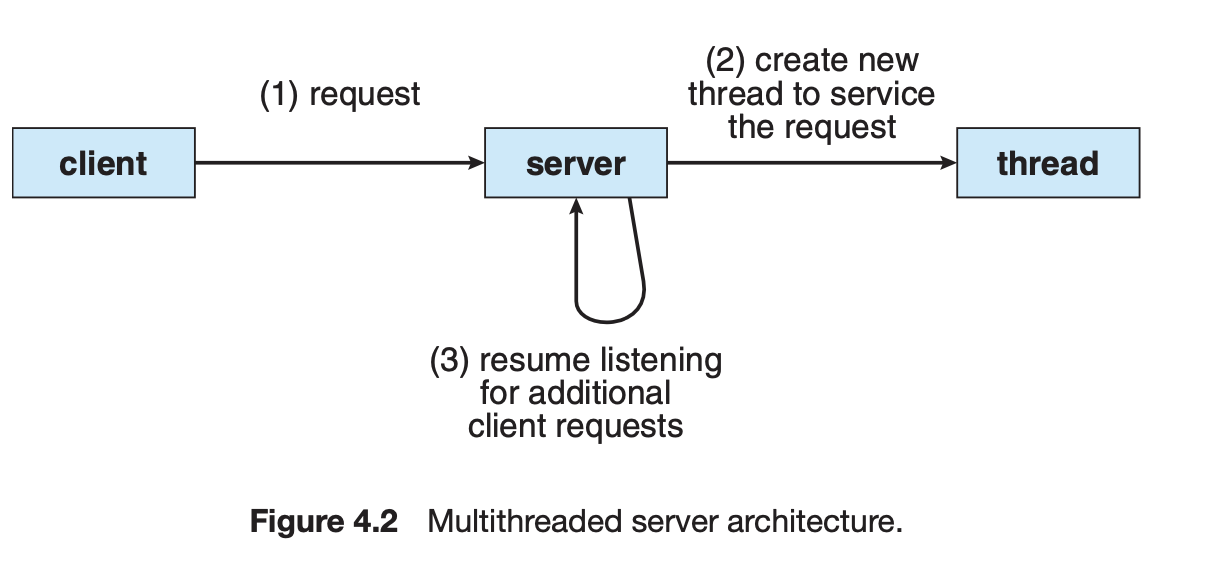
A web browser might have one thread display images or text while another thread retrieves data from the network, for example.
-
Resource Sharing: 프로세스 간에 자원을 공유하려면, sheard memory나 message passing과 같은 처리를 개발자가 해주어야 한다. 하지만, 스레드는 기본적으로 code와 data 영역을 공유한다. -
Economy: 프로세스를 만들고 context switch하는 것보다 스레드를 만드는 것이 훨씬 cost가 적다. -
Scalability: MultiProcessor 환경에서 스레드가 병렬적으로 처리될 수 있다. 멀티코어를 잘 활용할 수 있다. -
Concurrency vs Parallelism
Concurrency(동시성)
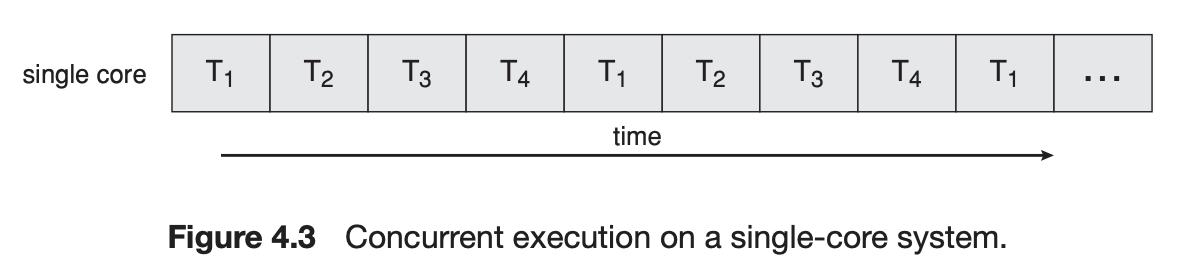
Parallelism(병렬성)
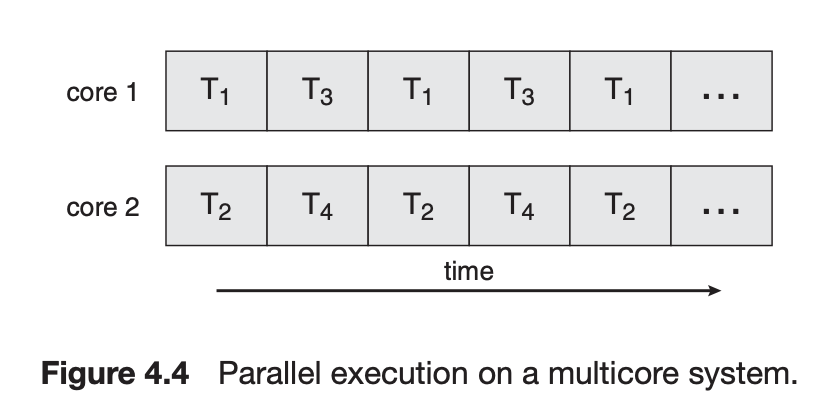
Implementation of Threads
- 커널에 의해 지원되는
Kernel Threads- 커널이 스레드의 존재를 알기 때문에 CPU 스케줄링을 스레드 단위로 해준다.
- 유저가 라이브러리를 통해 만드는
User Threads- 커널이 보기에는 평범한 프로그램처럼 보인다.
- 비동기식 입출력 등의 방법으로 바로 CPU 제어권을 받아 다른 스레드에게 넘기면서 멀티 스레드로 동작한다.
MultiThreading Models
Many-to-One Model
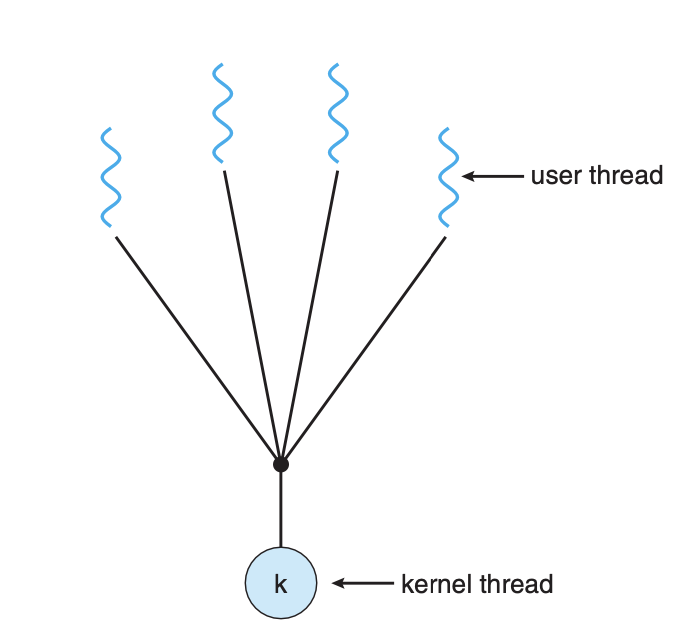
커널 스레드는 하나이고, 유저가 내부적으로 스레드를 만들어 멀티 스레드로 동작하게 만든 경우
- 커널 스레드가 한 개이기 때문에 한 스레드만 시스템 콜을 발생시켜도 전체 프로세스가 blocked된다.
- 시스템 콜 발생 시 멀티코어 시스템에서도 다른 스레드를 동작할 수 없다.
One-to-One Model
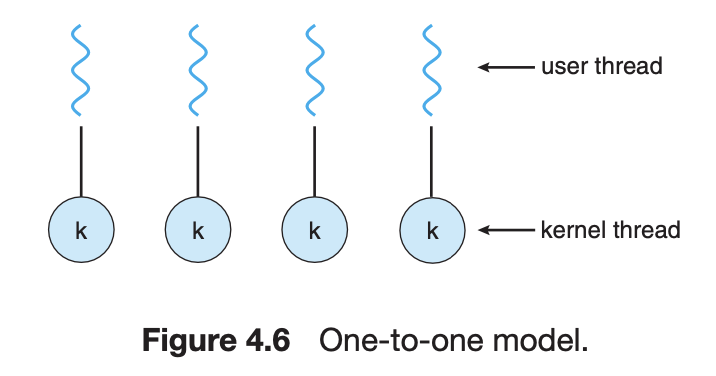
유저 스레드 하나 당 커널 스레드를 배치하는 방법
- 커널 스레드가 여러 개이기때문에 한 스레드가 시스템 콜을 발생시켜도 다른 스레드가 동작할 수 있다.
- 단, 스레드를 만들 때 커널 스레드를 만들어야 하는 비용이 발생하기 때문에 시스템에서 스레드 개수를 제한한다.
- 리눅스나 윈도우의 스레드 모델이다.
Many-to-Many Model
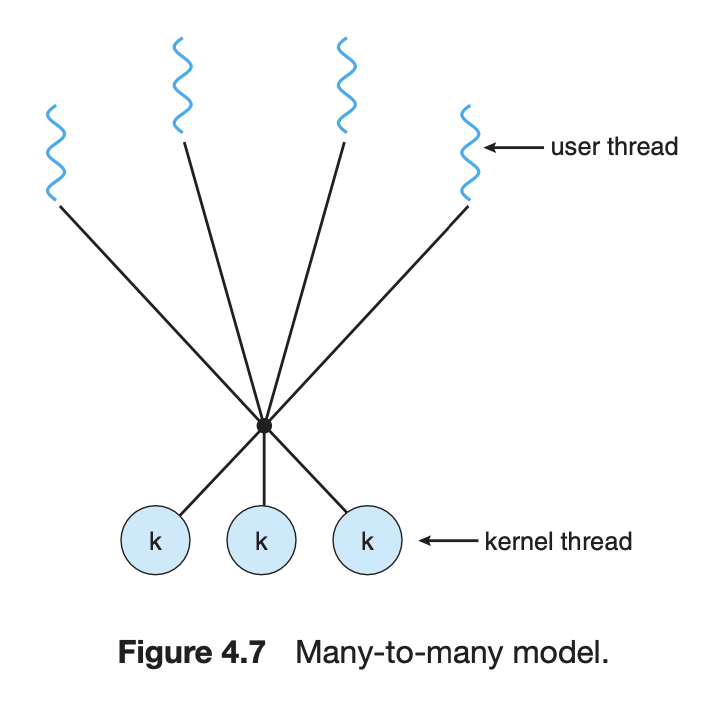
유저 스레드보다 같거나 적은 커널 스레드를 가지는 모델이다. 위 두 모델의 단점을 극복한 모델이라고 볼 수 있다. Many-to-One의 단점인 멀티코어에서의 동시성 문제와, One-to-One의 단점인 커널 스레드 생성 비용을 절충한다.
유저 스레드는 마음껏 만들고, 멀티코어에서 병렬적으로 동작 가능한 수준으로 커널 스레드를 만들어준다.
Process Creation
- 부모 프로세스가 자식 프로세스를 생성한다.
- 자식 프로세스는 누가 만들까?
- 운영체제가 만들어야 한다. 즉, 시스템 콜(fork)을 통해서 만들어달라고 요청한다.
- 자식 프로세스는 누가 만들까?
- 프로세스의 트리 구조 형성
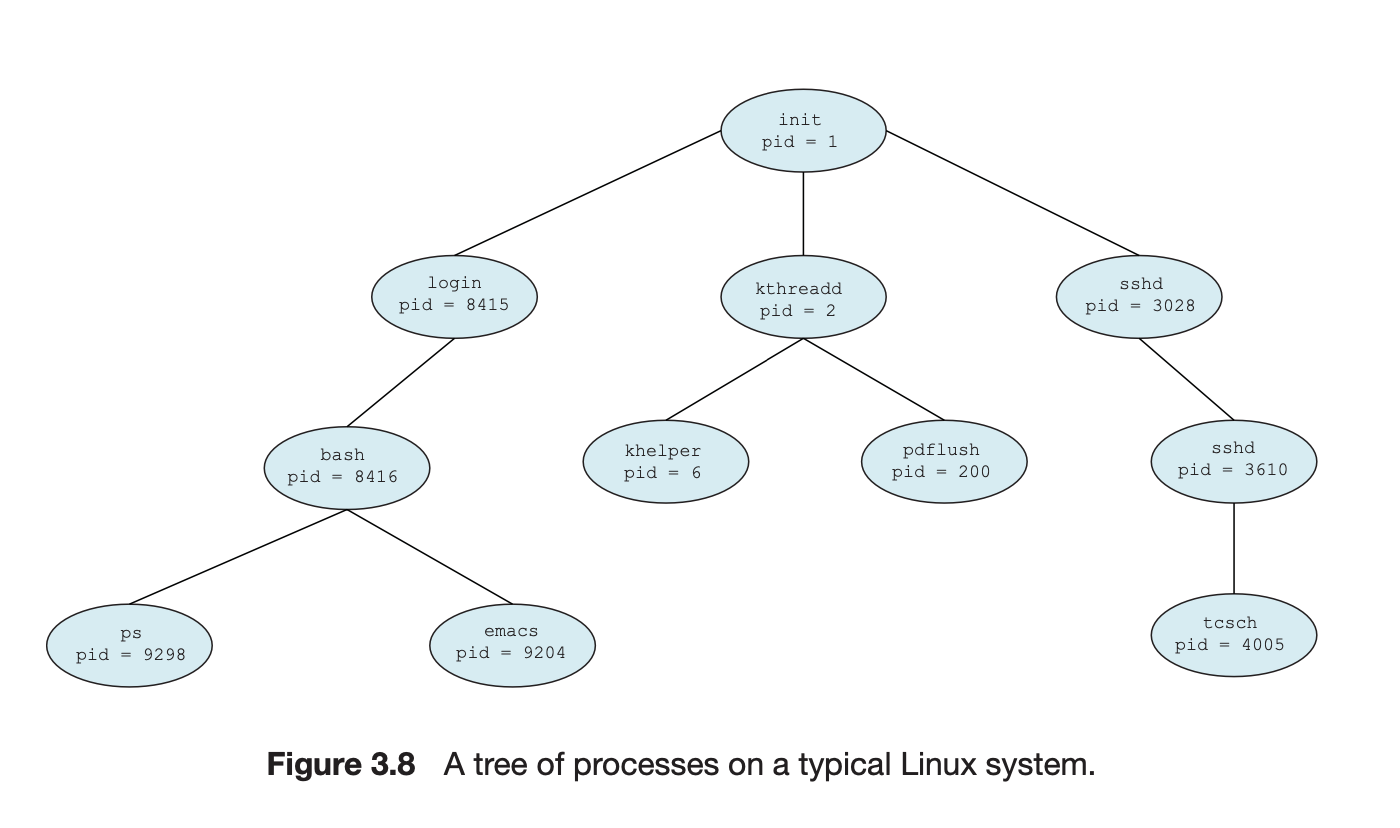
- 모든 프로세스의 조상은 부팅 시 켜지는 최초의 프로세스가 된다. (리눅스에서는 pid = 1인 init)
- 자식과 부모 프로세스 간에 자원의 공유 여부에 따른 모델들이 존재한다.
- 수행될 때
- 부모와 자식은 공존하며 수행되거나
- 자식이 종료될 때까지 부모가 기다리는 모델이 있다.
- 주소 공간
- 자식은 부모의 공간을 복사함 (code, data, stack 모두)
- 자식은 그 공간에 새로운 프로그램을 올림
Process Termination
exit()시스템 콜을 통해 종료한다는 사실을 운영체제에게 알린다.- 부모 프로세스가 자식의 수행을 종료시킴
- 자식이 할당 자원의 한계치를 넘어섬
- 자식에게 할당된 태스크가 더 이상 필요하지 않음
- 부모가 종료하는 경우
- 부모 프로세스가 종료하면 자식 프로세스부터 단계적으로 종료시킨다.
