
반효경 교수님의 운영체제 강의와 Operating System Concepts 10th ed. 를 참고하였습니다.
CPU 스케줄링 마무리
Multiple-Processor Scheduling
- CPU가 여러 개인 경우 스케줄링은 더욱 복잡해짐
- Homogeneous processor인 경우
- Queue에 한줄로 세워서 각 프로세서가 알아서 꺼내가게 할 수 있다.
- 다만 어떤 프로세스가 반드시 특정 프로세서에서 실행되어야하는 경우에는 문제가 더 복잡해짐.
- Load sharing
- 일부 프로세서에 job이 몰리지 않도록 부하를 적절히 공유하는 메커니즘 필요
- 별개의 queue를 둘까? vs 공동 큐를 사용하는 방법
- Symmetric Multiprocessing(SMP)
- 각 프로세서가 각자 알아서 스케줄링 결정
- Asymmetric multiprocessing
- 하나의 프로세서가 시스템 데이터의 접근과 공유를 책임지고 나머지 프로세서는 거기에 따름
Real-Time CPU Scheduling
- 어떤 프로세스가 꼭 실행되어야 하는 deadline이 존재하는 경우의 스케줄링
- Hard real-time systems
- 정해진 시간 안에 꼭 끝내도록 설정되어야 함
- Soft real-time systems
- 보통 프로세스보다 높은 우선순위를 갖도록 함
- deadline을 잘 지키기 위해서는 응답속도(event latency)의 개선이 중요함
- 크게 interrupt latency와 dispatch latency로 나뉜다.
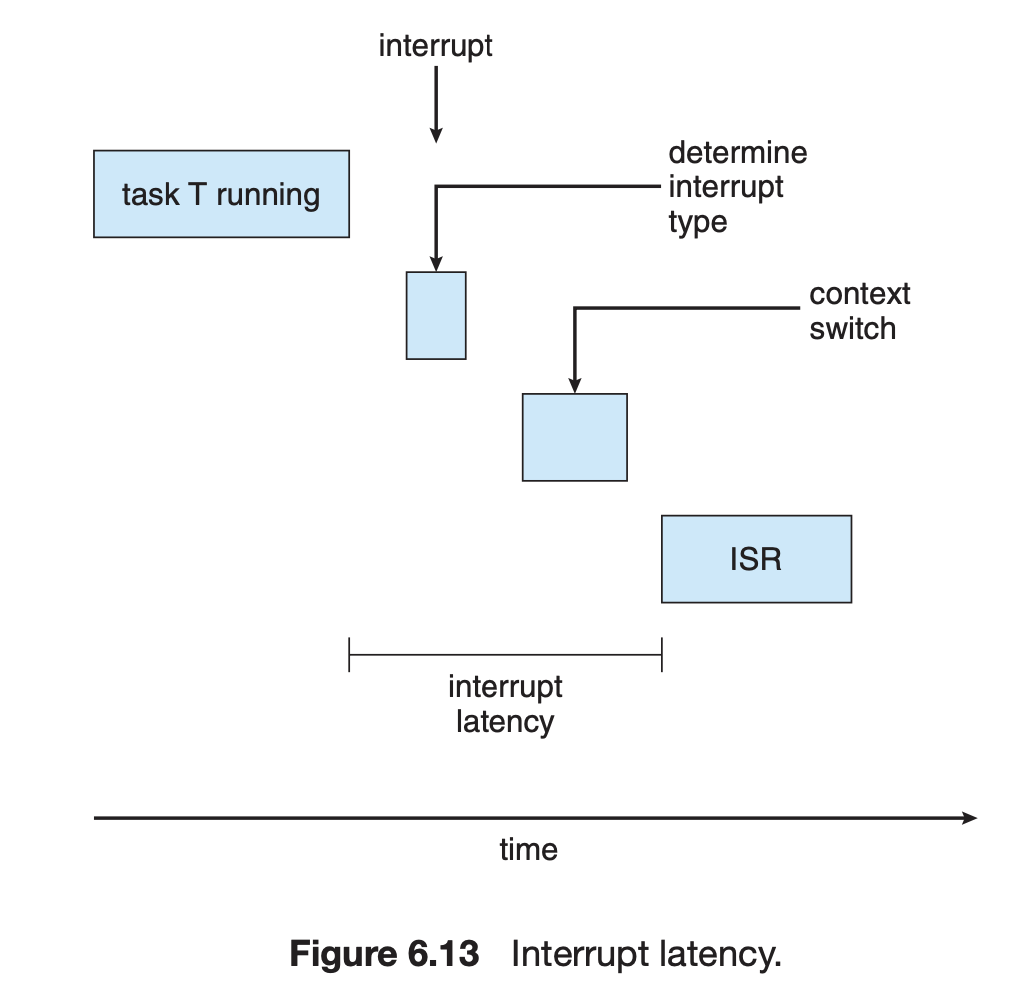
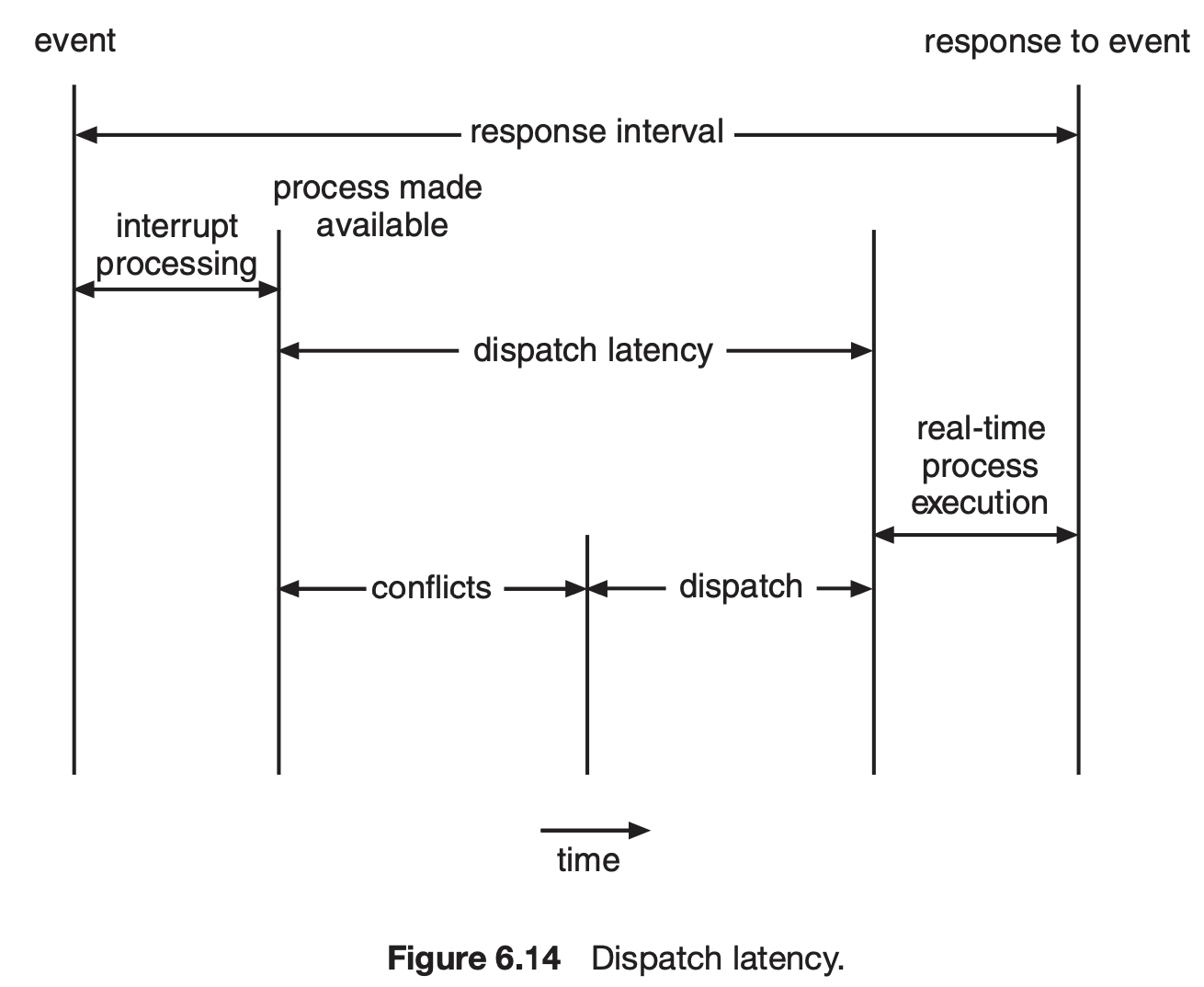
- 크게 interrupt latency와 dispatch latency로 나뉜다.
Thread Scheduling
- Local Scheduling
- 운영체제가 thread의 존재를 모르므로 어떤 thread를 스케줄링할 지 알 수 없음.
- user level thread의 경우 사용자 수준의 thread library에 의해 어떤 thread를 스케줄할지 결정
- Global Scheduling
- Kernel level thread의 경우 일반 프로세스와 마찬가지로 커널의 단기 스케줄러가 어떤 thread를 스케줄할지 결정
Algorithm Evaluation
- Queueing models
- 확률 분포로 주어지는 arrival rate와 service rate 등을 통해 각종 performance index 값을 계산
- Implementation & Measurement
- 실제 시스템에 알고리즘을 구현하여 실제 작업에 대해서 성능을 측정 비교
- 내가 만든 스케줄링을 CPU 스케줄링을 담은 리눅스에 담아서 설치한다음 비교해보는 방법
- 당연하게도 굉장히 매우 어렵다.
- Simulation
- 알고리즘을 모의 프로그램으로 작성 후 trace를 입력으로 하여 결과 비교
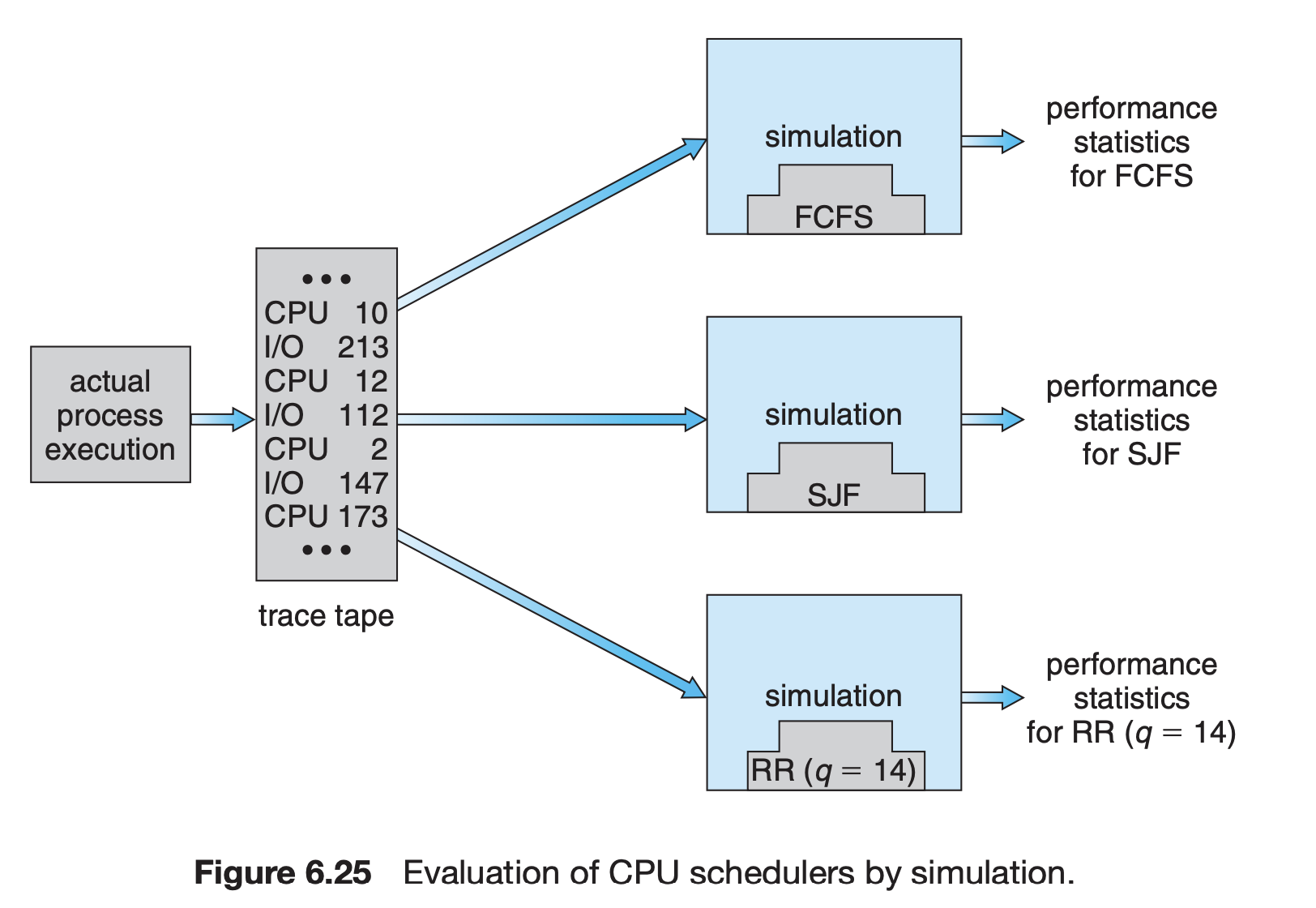
- 알고리즘을 모의 프로그램으로 작성 후 trace를 입력으로 하여 결과 비교
Process Synchronization
프로세스 동기화는 왜 필요할까?
만일 동시에 한 프로세스만 동작하고, 인터럽트도 존재하지 않아서 그 프로세스가 완료될 때까지 다른 프로세스가 CPU 제어권을 얻을 수 없었다면 동기화가 필요했을까? 아마도 아닐 것이다.
하지만 그동안 운영체제에 대해서 배우면서, 우리의 운영체제는 프로세스가 동시에 또는 병렬적으로 수행될 수 있다는 것을 배웠다. 마치 CPU가 동시에 작업을 처리하는 것처럼(concurrent)하게 실행되기 위해, CPU 스케줄러가 빠르게 switch하기 때문이다. 그 과정에서 어느 프로세스가 작업을 다 끝내기 전에 다른 프로세스가 스케줄링될 수도 있다는 뜻이다. 두 프로세스가 서로 독립적인 작업을 했다면 문제가 없겠지만, 서로 같은 부분에 접근하여 데이터를 바꿔놓는다면 두 작업 결과가 의도치않게 나올 가능성이 있다. 그렇기 때문에 운영체제는 동시에 접근이 가능한 자원에 대해서 동기화(Synchronization)을 제공하게 되었다.
Race Condition
A situation like this, where several processes access and manipulate the same data concurrently and the outcome of the execution depends on the particular order in which the access takes place, is called a race condition.
동시에 여러 프로세스가 한 데이터에 접근하여 값을 조작하고 그 연산 결과가 접근 순서에 따라서 달라지는 상황을 race condition이라고 부른다.
이런 상황은 멀티코어에서 실행되는 멀티스레딩 환경이나, 멀티 프로세서 환경, 또는 공유 메모리를 사용하는 프로세스들 간에 발생할 수 있다. 또는 커널 내부 데이터를 접근하는 루틴들 간에도 발생할 수 있다. 커널 모드에서 수행 중에 인터럽트로 커널 모드의 다른 루틴을 수행할 때에 발생할 수 있다.
다음은 OS에서 발생할 수 있는 race condition의 예이다.
(1) kernel 수행 중 인터럽트 발생 시
커널 모드에서 다른 작업을 수행하다가 인터럽트로 동일한 자원을 조작할 수 있다. 이런 경우에, 공유 자원에 접근할 때에는 interrupt를 disable하는 방식으로 방지할 수 있다. 공유 자원의 조작이 모두 끝난 후에야 인터럽트를 수행할 수 있다.
(2) 시스템콜을 하여 kernel mode로 수행 중인데 context switch가 발생하는 경우
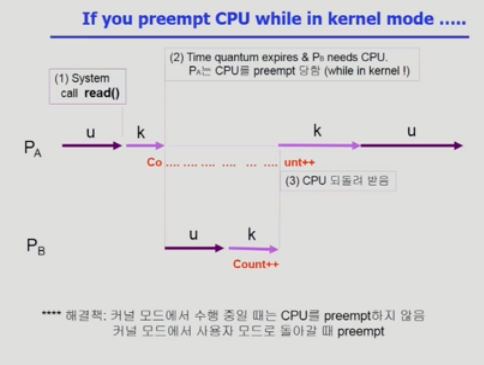
프로세스 A가 시스템 콜을 호출하여 count를 증가시키는 연산 도중에 timer interrupt가 발생하여 다른 프로세스 B가 역시 시스템 콜 상에서 count를 증가시키면, 2번 증가시켜야 하지만, A가 count를 증가시키던 문맥에서는 B의 결과가 반영되지 않았기 때문에(이미 register로 증가시키기 전의 값을 읽어갔다.) 한 번밖에 반영되지 않는다.
이 문제를 해결하려면 커널 모드에서 수행중일때는 CPU를 preempt하지 않는 것으로 방지할 수 있다.
(3) CPU가 여러 개인 경우
interrupt를 막는다고 해도 다른 CPU는 여전히 공유자원에 접근이 가능하기 때문에 방지할 수 없다.
방지하려면 한 번에 하나의 CPU만이 커널에 들어갈 수 있게 하는 방법이 있다. 직관적으로 해결할 수 있지만 굉장한 오버헤드가 수반된다.
또 다른 방법은 커널 전체가 아니라 커널 내부에 있는 각 공유 데이터에 접근할 때마다 그 데이터에 lock을 거는 방법이 있다.
The Critical-Section Problem

Each process has a segment of code, called a critical section, in which the process may be changing common variables, updating a table, writing a file, and so on.
각 프로세스는 공유 변수를 변경하거나, 테이블을 업데이트하거나 파일을 쓰는 등의 기능을 하는 코드 조각을 가지는 데 이를 critical section이라고 부른다. 그 결과 프로세스들은 일반적으로 위와 같은 구조를 가진다.
다음부터 이런 동기화 문제를 제어하기 위한 lock 알고리즘을 살펴본다.
Algorithm 1
int turn = 0; // 누군가의 차례를 나타내는 공유 변수
// process 0의 코드
do {
while (turn != 0) { } /* My turn? */
critical section
turn = 1; /* Now it's your turn */
remainder section
} while (1);이렇게 하면 process 0과 process 1이 critical section에 동시에 접근하는 일은 없다. 그러나 반드시 한번씩 교대로 들어가야 한다. 한번 p0가 critical section에 접근하면, p1이 접근할 때까지 들어갈 수가 없다. 극단적으로 한 프로세스는 자주 들락거리고, 한 프로세스는 딱 한번만 들어가는 프로세스라면 교착상태에 빠져버리게 된다. 그러므로 매우 비효율적인 구현 방식이다.
프로그램적 해결법의 충족 조건
- Mutual exclusion
If process Pi is executing in its critical section, then no other process can be executing in their critical sections.
어느 한 프로세스가 임계 영역에서 실행중이라면, 어떤 프로세스도 임계영역을 실행할 수 없다.
- Progress
If no process is executing in its critical section and some processes wish to enter their critical sections, then only those processes that are not executing in their remainder sections can participate in deciding which will enter its critical section next, and this selection cannot be postponed indefinitely.
현재 임계 영역을 실행하는 프로세스가 없고, 몇 개의 프로세스들이 임계영역을 실행하고자 하는 경우에 다음에 어떤 프로세스가 임계 영역에 진행할 지 결정하는 것은 remainder section을 실행하지 않고 있는 프로세스들간에 결정되어야 한다. (즉 임계영역을 실행하고 나면 다른 프로세스가 임계영역에 들어오는 것을 방해할 수 없다) 그리고 이 결정을 무기한으로 연기할 수 없다.
- Bound waiting
There exists a bound, or limit, on the number of times that other processes are allowed to enter their critical sections after a process has made a request to enter its critical section and before that request is granted.
임계영역을 들어가고자 하는 요청이 있은 뒤부터, 요청이 받아들여지기까지 다른 프로세스가 임계영역에 들어가는 횟수에 제한이 있어야 한다. 임계영역에 들어가기 위해 요청을 했는데 앞에 프로세스가 계속 임계영역에 들어가게 되면 starvation에 빠질 수 있기 때문입니다.
Algorithm 2
boolean[] flag = {false, false};
// Pi readt to enter its critical section if flag[i] == true
do {
flag[i] = true; /* Pretend I am in */
while (flag[j]) { } /* Is he also in? then wait */
critical section
flag[i] = flase; /* I am out now */
remainder section
} while (1);- 위 알고리즘은
mutual exclusion은 만족한다, 하지만progress는 만족하지 않는다. - 만약 flag만 들고 critical section에 실제로 들어가지 않더라도(CPU를 빼앗기거나 해서), 다른 프로세스는 critical section에 들어갈 수 없다. 실제로 critical section을 실행중인 프로세스가 없음에도 진행할 수 없기 때문에 progress를 만족하지 않는다.
Algorithm 3(Peterson's Algorithm)
do {
flag[i] = true; /* My intention is to enter */
turn = j; /* Set to hist turn */
while (flag[j] && turn ==j) { } /* wait only if */
critical section
flag[i] = false;
remainder section
} while (1);위 알고리즘은 1,2를 합친 알고리즘이다. 이 알고리즘은 경우의 수 중 단 한 경우에만 critical section에 진입하는 것을 대기한다.
이 알고리즘은 3가지의 충족조건을 다 만족하지만, busy-waiting(spin lock)이라는 비효율적 문제가 발생한다. 만약 임계영역에 진입할 조건이 만족하지 않으면, 다른 작업을 수행하지 못하고 while문을 돌면서 계속 대기해야하는 문제이다.
Hardware적 해결방법(Synchronization hardware)
동기화 문제를 해결하기 위해 위와 같이 복잡한 코드가 추가된다. 그럼 왜 이런 문제가 발생했을까? 데이터를 읽고 연산하고 저장하는 과정이 atomic(원자적)으로 실행되지 않아서 발생한 문제이다. 도중에 CPU를 빼앗겨 다른 프로세스가 데이터를 접근하는 일이 발생할 수 있기 때문이다. 그럼 일련의 과정을 원자적으로 관리한다면 공유자원을 별도로 관리하지 않아도 동기화를 잘 제어할 수 있다.
하드웨어적으로 특별한 instruction인 Test & Set를 지원하도록 하면 앞의 문제를 간단히 해결할 수 있다.
Synchronization variable: boolean lock = false;
Process Pi
do {
while (Test_and_Set(lock)) ;
critical section
lock = false;
remainder sectiontest_and_set은 아래와 같이 현재 lock의 값을 읽어오고, lock의 값을 1로 수정하는 동작을 원자적으로 수행한다. 도중에 CPU를 뺏기지 않기 때문에 lock 설정 사이에 빈틈이 생기지 않는다. 한번 lock을 획득한 process가 있다면 이후 인터럽트가 발생하더라도 다른 프로세스가 접근할 수 없다.

Semaphores
직접 코드로 구현했던 것들을 추상화된 기능으로 제공되는 소프트웨어 방법에 대해 소개한다. 대표적인 것이 세마포어와 모니터이다.
세마포어란 일종의 추상 자료형(ADT)이다. 구현 방식에 대해서는 논하지 않고, object와 operation만 정의해둔 것을 말한다. 우리가 integer에 변수를 대입하고, 연산하는 것도 추상 자료형의 일종이다. 우리가 사용할 수 있지만 내부적으로 어떻게 동작하는지는 잘 몰라도 되는 것처럼 말이다.
세마포어는 정수형 변수와 P(wait)연산과 V(signal)연산을 가진다. P연산은 자원을 획득하고 S를 decrement하는 원자적 연산, V연산은 자원을 반납하고 S를 increment하는 원자적 연산이다.
세마포어 변수 S가 0보다 크면 자원이 존재하는 상황이고, P연산을 하여 S가 0보다 작거나 같아지면 현재 사용할 수 있는 자원이 없다는 말이므로 대기에 빠진다. 자원을 모두 사용한 프로세스가 V연산을 통해 반납하면 S가 커진다. 특히, 자원이 하나뿐일 때는 S의 초기값을 1로 설정하면 된다. (mutex: mutual exclusion)
busy-wait 문제의 개선
뮤텍스와 세마포어 모두 P연산을 기다리는 동안 while문을 돌며 busy-wait에 빠진다. 이를 해결하려면 Block & Wakeup(sleep lock) 방식으로 구현할 수 있다.
누군가 이미 critical section에 접근하고 있어서 semaphore가 0 이하라면, 즉시 CPU를 내어놓고 blocked상태에 진입한다. 이 프로세스는 semaphore에 대한 wait queue에 들어간다. 그러다 누군가가 V연산을 하여 자원이 사용가능해지면 인터럽트를 통해 ready상태에 진입한다. (ready queue에 줄을 선다)
이 방식의 실제 구현 코드는 다음과 같다.

P(wait)연산을 수행하면 일단 자원을 1 빼보고, 자원이 0보다 작은 상태이면 프로세스를 queue에 집어넣고 blocking한다.

V(signal) 연산을 수행하면 일단 자원을 1 더하고, 자원이 0보다 같거나 작으면(=누군가가 semaphore를 기다리고 있다면) 큐에 있는 프로세스 하나를 wake-up 시킨다.
이 구현방식을 보면, busy-waiting 방식과는 달리 semaphore 값이 0보다 작아질 수 있다. 원문을 발췌하면 다음과 같다.
Note that in this implementation, semaphore values may be negative, whereas semaphore values are never negative under the classical definition of semaphores with busy waiting. If a semaphore value is negative, its magnitude is the number of processes waiting on that semaphore. This fact results from switching the order of the decrement and the test in the implementation of the wait() operation.
즉, 우선 S를 1 빼는 이유는 일단 사용가능한지 생각하지 않고, semaphore 쓰러왔습니다~하고 알리는 것이다. 빼봤더니 0보다 작으면 대기표를 뽑은 셈이고, 0보다 크면 쓰러 들어가서 점유한 셈인 것이다.
물론 이 방법에도 단점이 있다. 세마포어 대기가 길어지는 경우(프로세스 간 critical section의 경합이 치열한 경우)에는 이 방법이 효율적이지만, 금방 세마포어를 쓰고 나오는 경우(critical section이 한산한 경우)에는 오히려 blocked-wake up 과정에서의 context switch에 쓰이는 오버헤드가 더 커지게 된다.
Spinlocks do have an advantage, however, in that no context switch is required when a process must wait on a lock, and a context switch may take considerable time. Thus, when locks are expected to be held for short times, spinlocks are useful.
세마포어의 종류
- Counting semaphore
- 도메인이 0 이상인 임의의 정수값
- 주로 resource counting에 사용
- Binary semaphore (=mutex)
- 0 또는 1 값만 가질 수 있는 semaphore
- 주로 mutual exclusion(lock/unlock)에 사용
