
반효경 교수님의 운영체제 강의와 Operating System Concepts 10th ed. 를 참고하였습니다.
Deadlock Avoidance
- 2가지 경우에 따른 avoidance 알고리즘
- Single instance per resource type: 자원 할당 그래프 알고리즘 사용
- Multiple instance per resource type: Banker's Algorithm 사용
Resource Allocation Graph algorithm
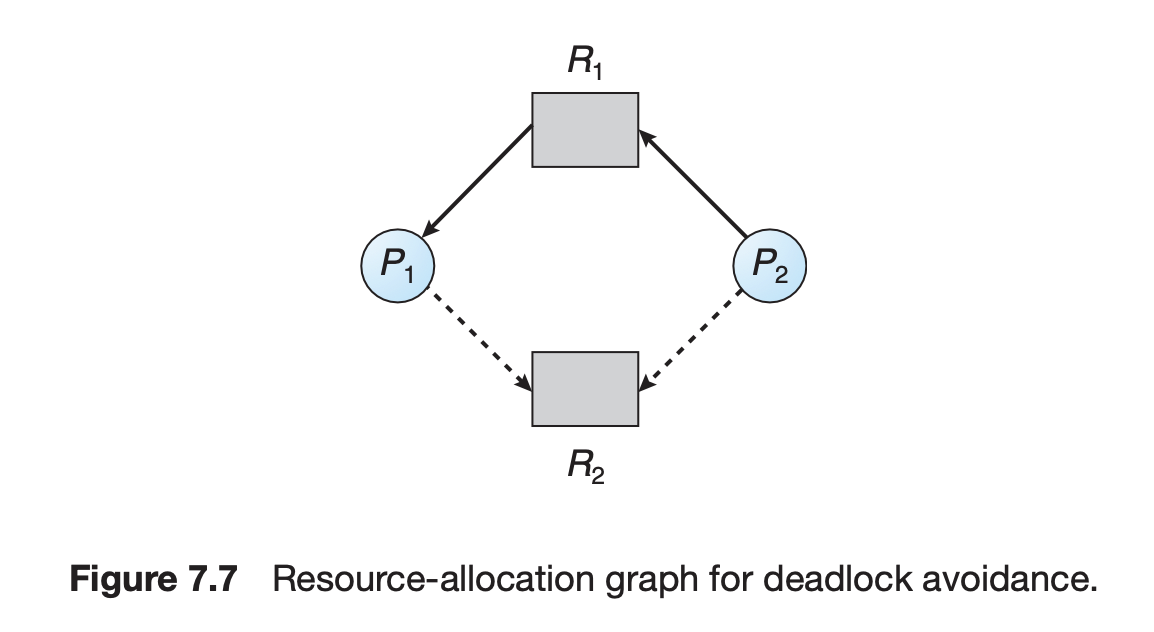
자원 할당 그래프 상에서 실선은 실제로 요청한 자원, 점선은 살면서 요청할 수 있는 자원을 나타낸다.
이 알고리즘에서는 점선 또한 사이클 형성 여부를 고려할 때 같이 고려한다. 현재는 사이클이 생기지 않더라도, 점선에 해당하는 요청이 실제로 발생하면 사이클이 발생할 수 있다면 데드락 위험이 있기 때문이다.
Banker's Algorithm
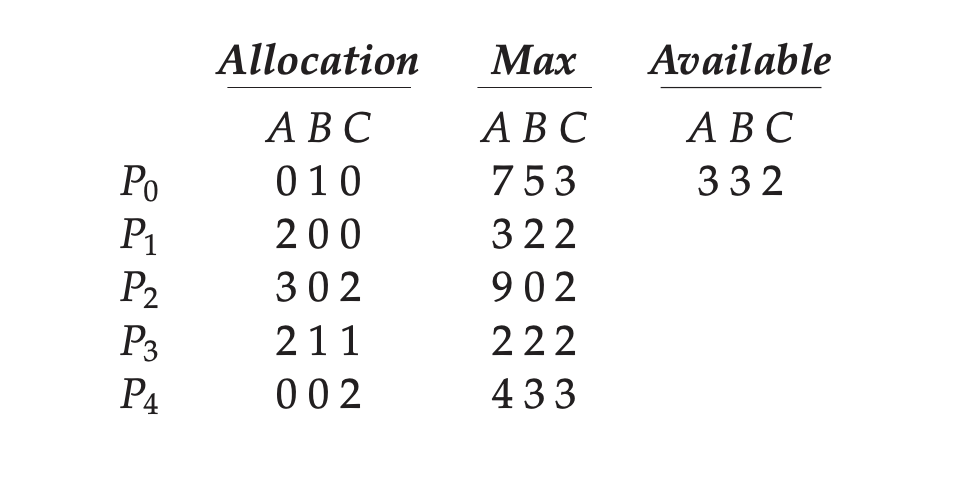
Banker's algorithm에서는 프로세스가 최대로 요청할 자원의 개수를 알고 있다고 가정한다. 그럼 현재 할당된 자원 대비 더 요청가능한 자원의 수를 파악할 수 있다.

그럼 추가로 요청할 Need에 해당하는 자원을 현재 보유한 자원을 통해 모두 할당해줄 수 있는 경우에만 프로세스에게 자원을 준다. 왜냐하면 모든 자원을 주면 추가 자원을 요청하지 않기 때문에 절대 데드락이 발생할 일이 없기 때문이다.
즉, 위 그림에서는 P1, P3의 요청만 현재 받아들일 수 있다.
그리고 현재 P1, P3, P4, P2, P0의 순으로 자원을 할당하면 모두 프로세스를 데드락 없이 종료시킬 수 있는 경우가 존재하므로 이 프로그램은 safe하다고 말할 수 있다.
추가로 이름의 유래는 아마 대출을 해줄 때 은행원이 고객이 대출을 상환할 수 있는지 판단하는 느낌에서 짓지 않았을까 하는 생각이 든다.
Deadlock Avoidance의 단점
너무 앞서나가 걱정한다
이 방식의 단점을 한마디로 나타낸 말이 아닐까 싶다. 실제로 데드락이 발생하지 않을 수 있는데 가능성을 조사하며(심지어 가능성을 조사하는 데도 오버헤드가 든다) 가용 상태의 자원을 낭비하는 결과를 초래한다.
Deadlock Detection and Recovery
Deadlock Detection
Deadlock detection 역시 자원 당 한 개의 인스턴스만 갖는 경우와 여러 인스턴스를 갖는 경우에 각각 Deadlock avoidance와 유사한 알고리즘으로 진행된다.
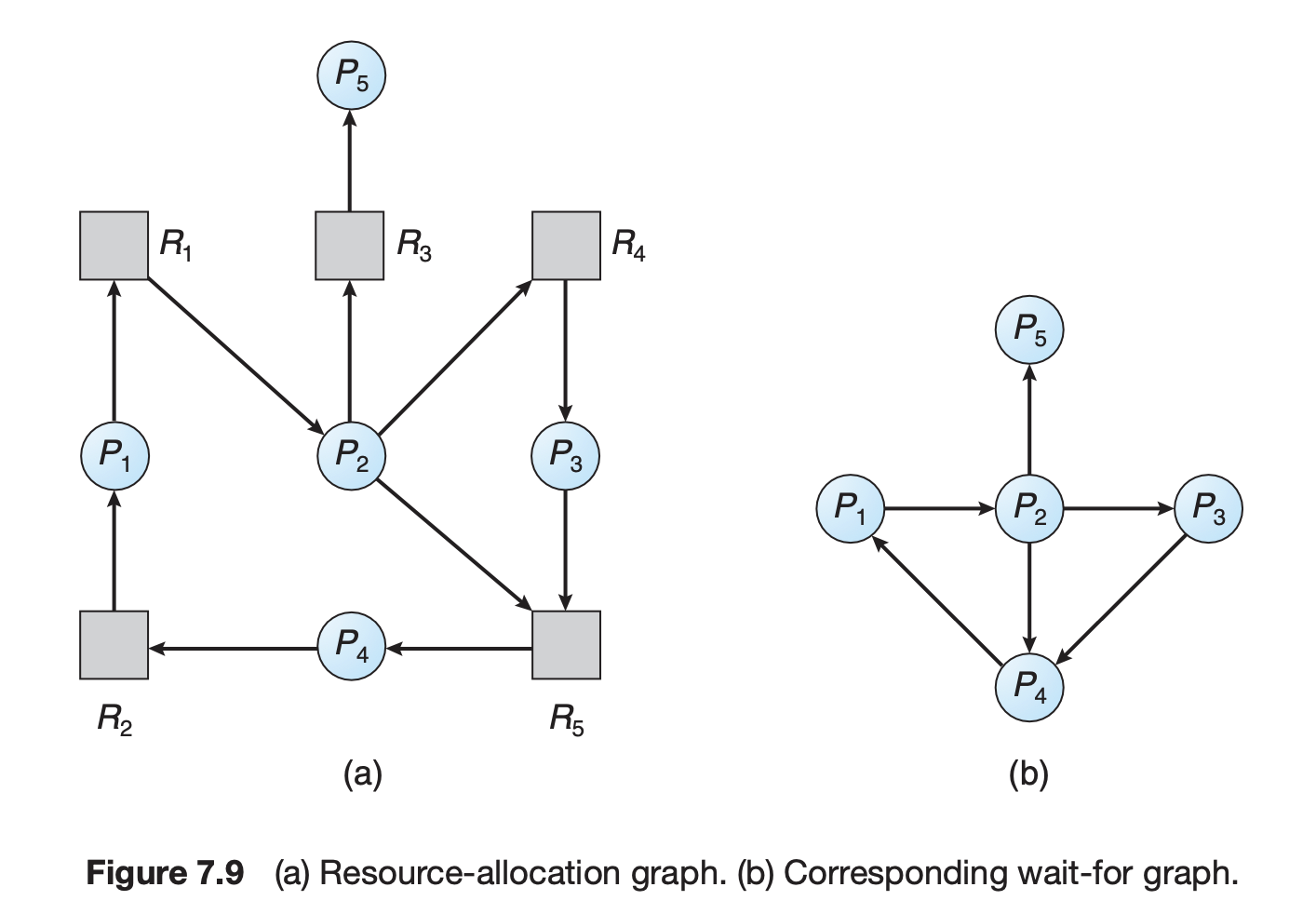
인스턴스가 하나인 경우, 현재 자원 할당 그래프를 그려 데드락인지를 판단한다. 현재 위 그래프에서는 프로세스 간에 자원 요청 사이클이 발생하여 데드락이 발생했다.
데드락 판단을 더 쉽게 하기 위해 프로세스 간의 wait 관계를 그린 wait-for graph를 그리기도 한다.
인스턴스가 여러개인 경우에는 Banker's algorithm과 달리 미래에 요청할 자원을 고려하지 않고 무조건 자원을 할당해준다. 그리고 추가 요청이 없는 프로세스들이 자원을 내어놓을 것으로 고려하고 가용 자원을 계산한다. 그리고 현재 요청한 프로세스들의 요청을 처리할 수 있는지 판단하여 데드락 여부를 판단한다.
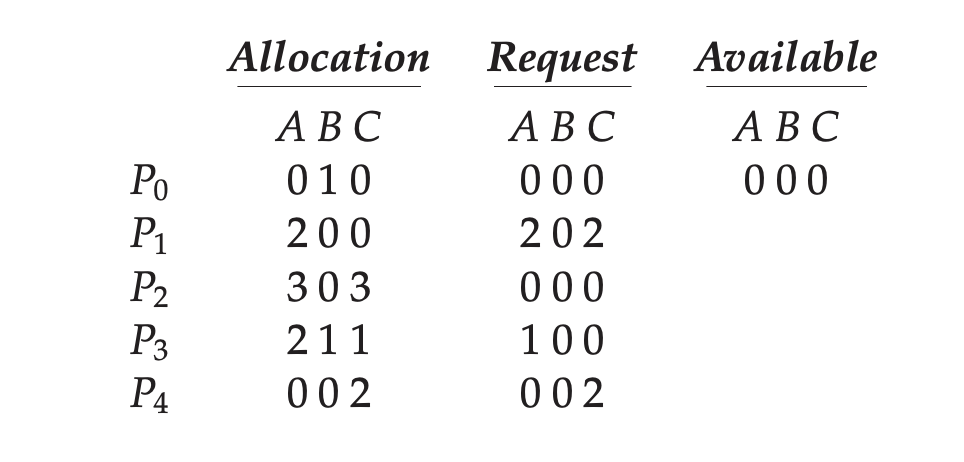
위 그림에서 현재 추가 요청이 없는 P0, P2가 자원을 내어놓을 것이라 생각하고 A 3, B 1, C 3이 가용자원이 된다. 그 상황에서 P1, P3, P4의 요청을 모두 처리할 수 있기 때문에 데드락이 없다고 판단한다.
Deadlock recovery
Process termination- 데드락에 연루된 모든 프로세스를 죽이는 방법
- 데드락에 연루된 프로세스를 하나씩 죽여서 사라질 때까지 반복하는 방법
Resource Preemption- cost를 최소화하는 victim을 선정한다.
- victim으로부터 resource를 빼앗았으면 safe state가 되도록 roll-back한다.
- Starvation 문제가 발생할 수 있다
- 반복적으로 한 프로세스가 victim으로 선정되는 경우- rollback 횟수도 고려하여 cost를 고려한다.
Deadlock Ignorance
데드락은 매우 드물게 발생하는 일 중 하나이므로 운영체제가 이를 막거나, 찾거나, 복구하기 위해 뭔가를 하는 것 자체가 운영체제의 비효율성을 증가시킨다. 즉, 현대의 운영체제는 대부분 데드락을 방치하는 방법을 선택했다. 데드락이 발생한 경우에는 사람이 프로세스를 종료하거나 하는 등의 조치를 취하도록 맡긴다.
그럼 데드락을 왜 배울까?
실제로 시분할 OS에서 공유자원을 사용할 때 발생할 수 있는 현상 중 하나이므로 발생하는 조건이나 이유 등에대해 배우는 것이 의미가 있기 때문이다.
메모리의 주소
메모리는 기본적으로 주소로 접근하는 저장 장치이다. 그럼 메모리의 주소는 어떻게 매겨질까?
Logical vs. Physical Address
-
Logical address- 프로세스마다 독립적으로 가지는 주소 공간
- 각 프로세스는 0번지부터 시작
- CPU가 보는 주소에 해당함
-
Physical address- 메모리에 실제 올라가는 위치
-
주소 바인딩: 논리 주소를 실제 주소로 바꾸는 과정
Symbolic address -> logical address -> physical address
주소 바인딩
우리가 코드를 작성하게 되면 직접 메모리 주소를 적는 것이 아니라 프로그래밍 언어로 이뤄진 Symbolic address를 통해 프로그램을 작성한다.
이 프로그램이 컴파일되면 실행파일 속의 주소는 Logical address로 변환이 된다.
그럼 이 논리적인 주소가 실제 주소로 바뀌는 타이밍은 크게 세 가지가 있을 것이다.
-
Compile time binding: 컴파일 되는 타이밍에 주소가 정해지는 방식, 물리 주소를 변경하려면 재 컴파일해야 한다.
-
Load time binding: 논리적인 주소가 바뀌는 시점이 메모리에 로딩되는 시점에 해당한다.
Loader의 책임 하에 물리적 메모리 주소를 부여하고 컴파일러가 재배치 가능 코드를 생성한 경우에 가능하다. -
Run time binding: 수행이 시작된 이후에도 프로세스의 메모리 상 위치를 옮길 수 있음
CPU가 주소를 참조할 때마다 address mapping table을 통해 binding을 점검하게 된다.
하드웨어적인 지원이 필요
CPU는 기계어에 들어있는 논리적인 주소를 읽기 때문에 실제 메모리 주소를 알려면 주소 변환이 필요하다.
MMU (Memory-Management Unit)
local address를 physical address로 매핑해주는 Hardware device
Dynamic Relocation
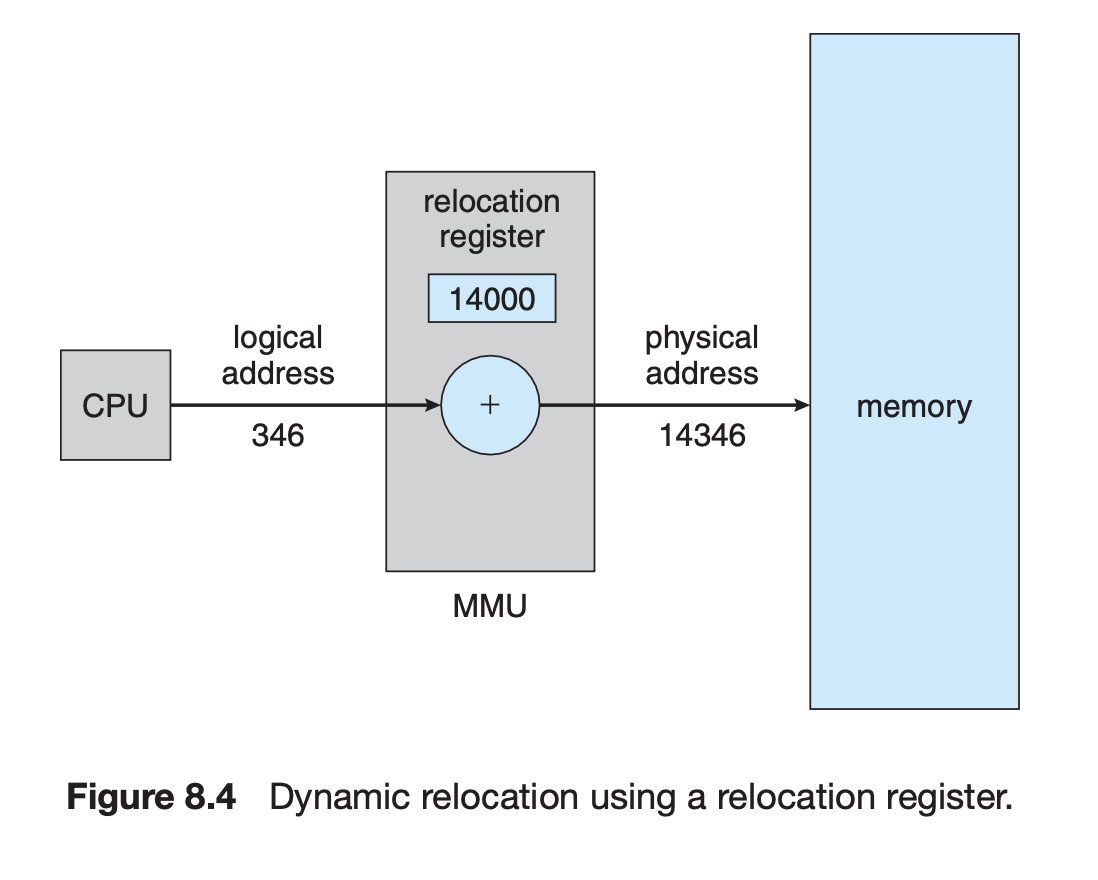
MMU는 두 개의 레지스터를 통해 CPU가 보는 논리 주소를 실제 주소로 매핑해준다. base register는 어떤 프로세스의 시작점의 주소를, limit register는 그 프로세스의 크기를 정해준다. 그래서 해당 프로세스 크기를 넘어가는 명령이 주어지는 경우를 막을 수 있다.
Dynamic Loading
- 어떤 프로세스 전체가 메모리에 올라가는 것이 아니라 루틴이 불려질 때 메모리에 로딩을 하는 것
- memory-space utilization의 향상
- 모든 루틴은 디스크 상에 relocatable load format으로 저장되어 있음
- 필요할 때 언제든지 재할당하여 로딩할 수 있다
- dynamic loading은 운영체제 도움 없이 사용자 프로그램 상에서 라이브러리를 통해 구현이 가능하다.
Overlays
- 작은 공간의 메모리를 사용하던 초창기 시스템에서 수작업으로 구현하던 방식
- 프로세스의 크기가 메모리보다 클 때 유용
Dynamic Linking(shared library)
- Static linking(static library)은 라이브러리가 실행 코드 내에 이미 포함돼있어서 프로그램이 메모리에 올라갈 때 같이 올라간다.
- 반면에 Dynamic linking은 라이브러리가 별도의 파일로 존재하다가 라이브러리 함수를 호출하는 시점에 메모리에 올리는 방법이다.
- 라이브러리 호출 부분에 위치를 찾기 위한 stub이라는 작은 코드를 둔다.
- 라이브러리가 이미 메모리에 있으면, 루틴의 주소로 가고 없으면 디스크에서 읽어와야 한다.
- 이 과정에서 운영체제의 도움이 필요하다. 필요한 루틴이 다른 프로세스의 주소 공간에 있는지 체크해줄 수 있는 유일한 주체가 운영체제이기 때문이다.
Swapping
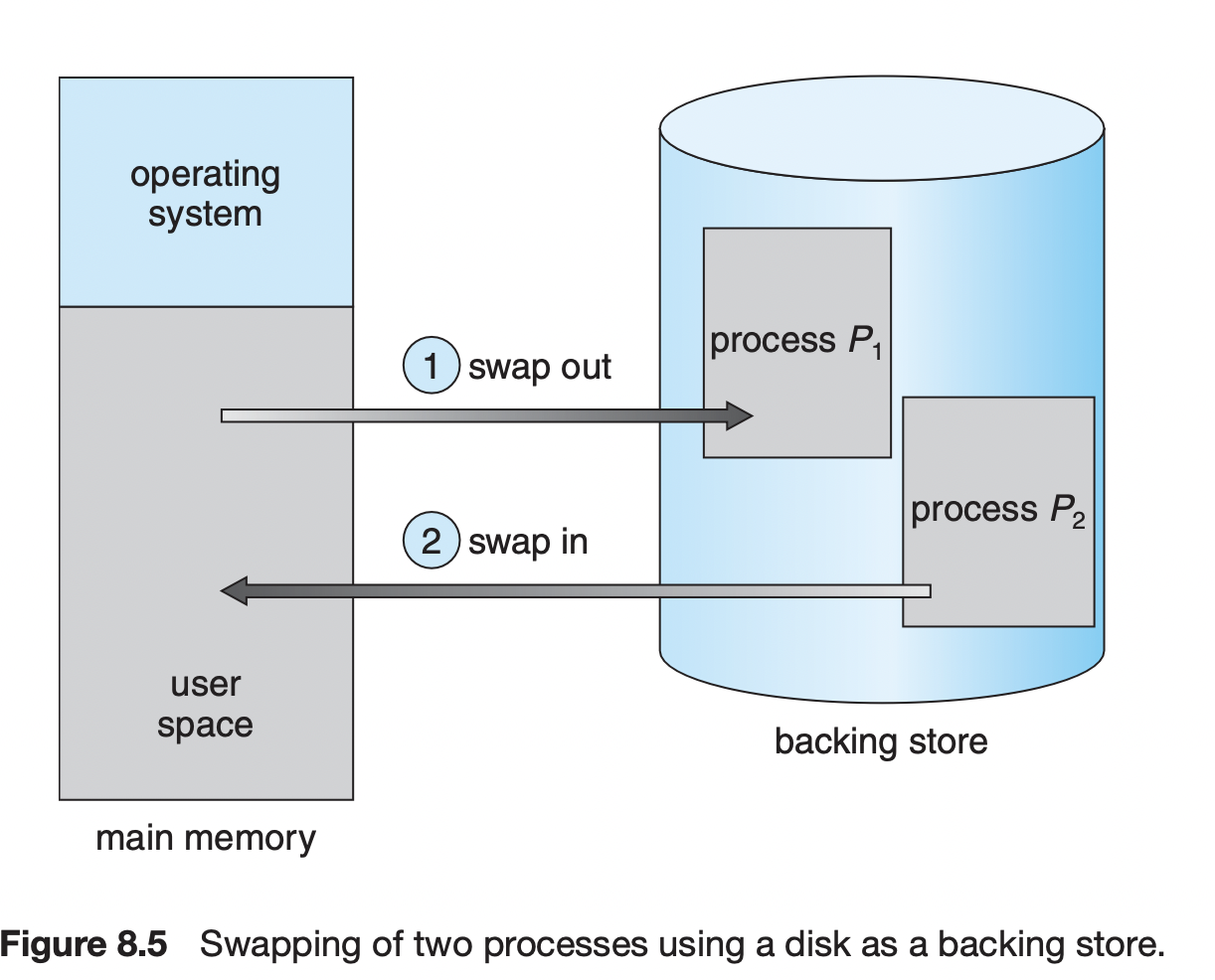
-
multiprogramming을 위해서는 메모리 상의 프로세스를 메모리에서 쫓아내는 것도 중요하다. 그래서 현대 운영체제는 중기 스케줄러를 통해 프로세스를 backing store로 일시적으로 swapping한다.
-
Swap in / Swap out
- 일반적으로 중기스케줄러가 프로세스를 선정한다.
- 우선순위에 따라서 swap될 프로세스를 선정한다.
- Compile time binding이나 load time binding 하에서는 원래 메모리 위치로 swap in 해야 한다.
- Runtime binding은 빈 메모리 영역 아무 곳에서 올려놓을 수 있다.
- swap time은 대부분 backing store에서 불러오는 시간이다.
Standard swapping에는 여러가지 문제점이 있다. 우선 swap out할 프로세스를 선정할 때, 그 프로세스가 완벽히 idle 상태인 지 판단해야 한다. 그런데, 여기서 I/O를 기다리고 있는 프로세스가 있다면 어떨까?
I/O를 기다리는 시간 동안 메모리를 차지하는 것은 낭비라고 생각하여 swap out하고 싶다는 생각이 든다.
하지만 이 프로세스가 I/O를 비동기적으로 처리하면서 I/O 버퍼로서 메모리에 접근하고 있었다면 어떨까?
이 경우에는 이 프로세스를 swap해서는 안된다. 만약 I/O device가 바쁜 상황이라 I/O 작업이 대기중인 상황에서 I/O를 요청한 p1을 p2로 swap하는 순간 I/O operation의 결과가 P2가 쓰고 있는 메모리 영역에 영향을 끼칠 수도 있기 때문이다.
이런 문제를 해결하는 방법에는 두 가지 방법이 있다고 한다. 첫번째는 I/O를 대기중에는 절대 swap하지 않는 방법이고, 두번째는 I/O operation을 O/S buffer에서만 동작하도록 만드는 방법이다. 전자는 다소 메모리가 비효율적으로 사용될 가능성이 높다. 후자의 방법은 double buffering이라고 부르는 방법인데, 시스템의 오버헤드가 커져 크게 권장되지 않는다. 그렇기 때문에 현대 운영체제에서는 전통적인 swapping을 사용하지 않는다. 프로세스 전체를 swap in/out하는 것은 transfer time도 많이 들고 프로세스 단위가 크기 때문에 메모리가 작다면 각 프로세스에게 주어지는 실행시간도 너무 짧아진다.
그래서 현대 운영체제에서는 free memory 크기에 따라서 swapping을 disable/enable하는 방법을 사용하기도 한다. 또는 전체 프로세스가 아닌 프로세스의 일정 부분을 swap in/out 하는 방법을 사용하기도 한다. 이것이 바로 페이징 기법이나 세그멘테이션 방법이다.
Allocation of Physical Memory
- 메모리는 일반적으로 OS 영역, 사용자 프로세스 영역으로 나눠져 있다.
- 사용자 프로세스를 메모리 상에 어떻게 할당할 것이냐도 중요한 문제이다.
- 메모리 할당 방법
Contiguous allocation
- 프로세스가 메모리 상에 연속적으로 할당되도록 하는 방법- 메모리를 고정 크기로 분할하는 방법 vs 가변 크기로 할당하는 방법
Non-contiguous allocation- 프로세스의 주소 공간이 연속적이지 않고 산발적으로 메모리에 올라갈 수 있는 할당방법
Contiguous allocation
-
고정 분할 방식
- 물리적인 메모리를 고정된 크기의 여러개의 파티션으로 미리 나눈다.
- 프로그램 크기가 들어갈 수 있는 크기에 프로그램을 할당한다.
- 이 때, 각 파티션에 들어가고 남은 조각을
내부 조각이라고 한다. - 그리고 사용되고 있지 않지만 크기가 작아 사용되지 못하는 공간을
외부 조각이라고 한다.
-
가변 분할 방식
- 물리적인 메모리를 미리 나눠놓지 않는다.
- 내부 조각은 발생하지 않지만, 연속할당 방식이기 때문에 중간중간 비는 공간을 사용할 수 없어
외부 조각이 발생한다.
-
Hole
- 가용 메모리 공간이지만 사용되지 않고 있는 부분
- 운영체제는 할당 공간과 가용 공간(hole)의 정보를 알고 있어야 한다.
- 운영체제는 빈 hole 중 어디에 프로세스를 올려야할 지에 대한 문제도 생긴다.
Dynamic Storage-Allocation Problem
-
First-fit- Size가 n 이상인 것 중 최초로 찾아지는 hole에 할당 -> 시간 복잡도에 유리하다.
-
Best-fit- Size가 n 이상인 것 중 가장 작은 hole을 찾아서 할당한다.
- hole이 정렬되지 않은 경우 O(n)이 소요된다.
- 외부 조각이 생겨 아주 작은 hole이 많이 생성된다.
-
Worst-fit- 제일 큰 hole에 할당하는 방법
- 역시 탐색도 진행해야 하므로 O(n)이 소요된다.
- 아주 큰 hole이 생긴다.
Compaction
외부 조각을 없애기 위해 모든 hole을 한 곳으로 몰아넣는 방법
- 매우 비용이 많이 드는 방법이기 때문에 최소한의 메모리 이동으로 compaction하는 방법이 있다.
- 그 방법을 찾는 것이 매우 복잡하다.
- compaction은 runtime binding에서만 사용이 가능하다.
