
반효경 교수님의 운영체제 강의와 Operating System Concepts 10th ed. 를 참고하였습니다.
가상 메모리
Demand Paging
- 운영체제의 도움을 받아 실제로 필요할 때 Page를 메모리에 올리는 것
- I/O 양의 감소
- Memory 사용량 감소
- 빠른 응답 시간
- 더 많은 사용자 수용
- Valid / Invalid bit의 사용
- Invalid의 의미
- 사용되지 않는 주소 영역
- 현재 물리 메모리에 없는 영역
- 처음에는 모든 page entry가 invalid로 초기화
- 주소 변환시에 모든 invalid bit이 set되어 있으면 ->
page fault
- Invalid의 의미
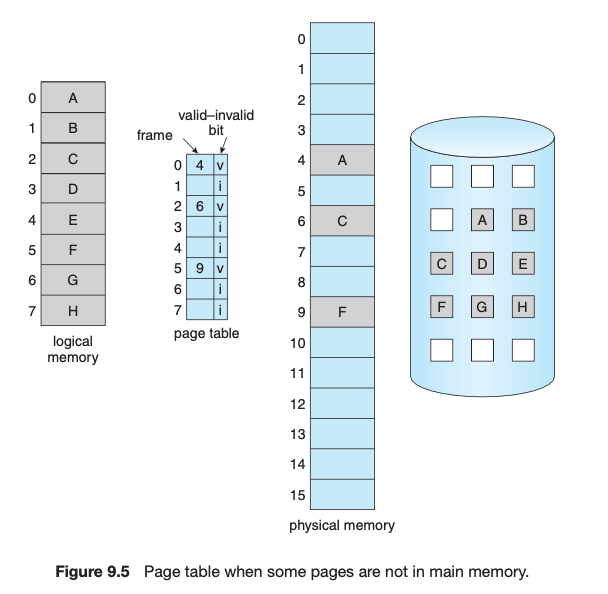
만약 CPU가 주소 변환을 위해 페이지 테이블에 접근하였는데 invalid라면 page fault가 발생한다. 이 때는 backing store(disk)에서 해당 페이지를 읽어와야 하고, 트랩을 통해 CPU 제어권이 운영체제에게 넘어간다. 운영체제는 해당 페이지를 메모리에 올려놓는 I/O 작업을 수행한다.
Page fault
- invalid page를 접근하면 MMU가 trap을 발생시킴
- Kernel mode로 들어가서 page fault handler가 호출됨
- page fault 처리 과정
- 정상적인 요청인가?
- 비어있는 페이지 프레임을 가져오거나 뺏어온다.
- 해당 페이지를 disk에서 memory로 읽어온다
- I/O 가 진행되는 동안 CPU를 빼앗기고, 다 읽으면 page table의 entry를 기록하고 valid bit를 업데이트한 다음, ready queue에 프로세스를 올림.
- 다시 프로세스가 CPU를 잡고 실행됨

대부분의 경우에는 page fault가 나지 않고, 대부분의 경우에 메모리 접근이 가능하다. 만약 page fault가 발생한다면 매우 오래 걸리는 작업이 수행된다.
Effective Access Time = (1 - p) x memory access + p (OS & HW page fault overhead + [swap page out if needed ] + swap page in + OS & HW restart overhead
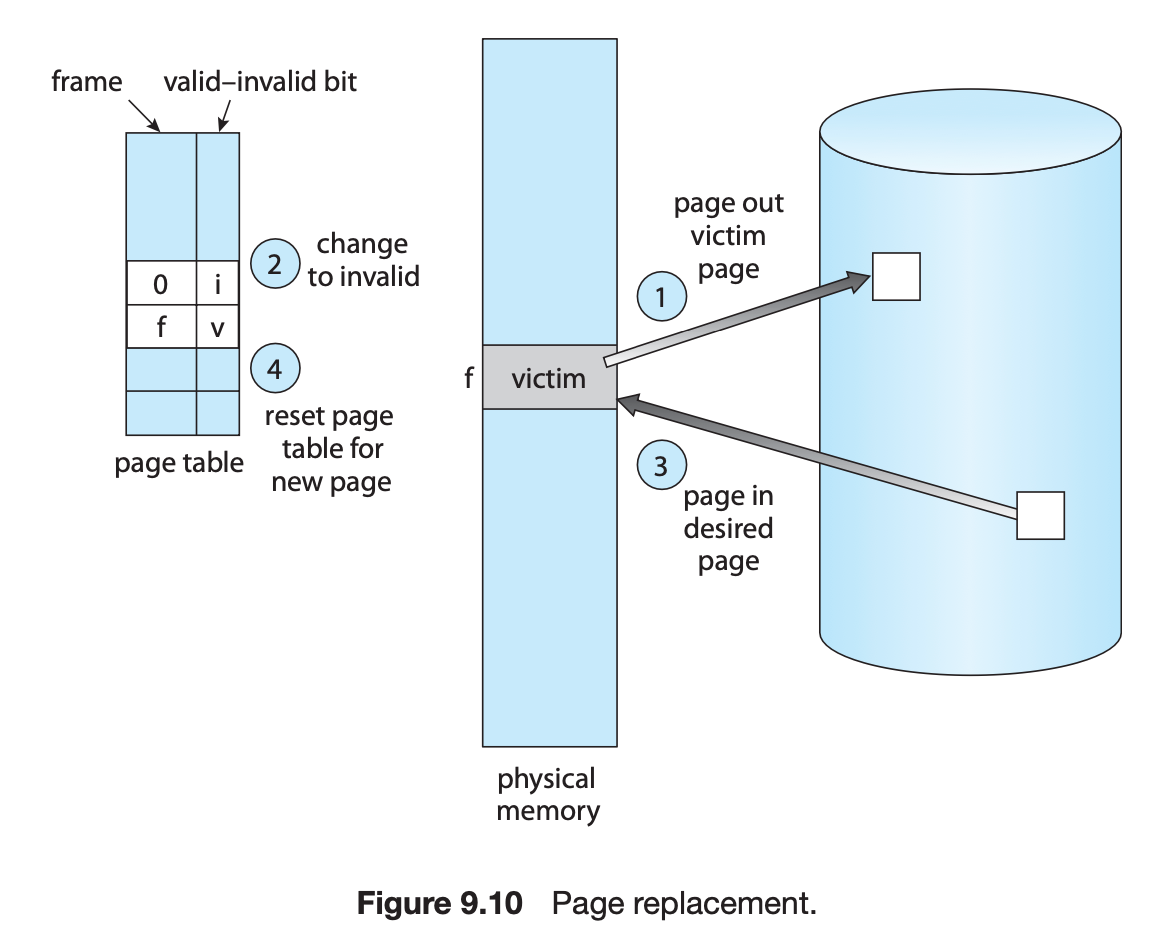
Free frame이 없는 경우
-
Page replacement
- 어떤 frame을 빼앗아올지 결정하는 문제
- 곧바로 사용되지 않을 page를 빼앗는 것이 좋음
-
Replacement Algorithm
- page-fault rate를 최소화하는 것이 목표
- 주어진 page reference string에 대해 page fault를 얼마나 내는지로 평가
Optimal Algorithm
- 미래의 참조정보를 알 수 있다고 할 때, 가장 먼 미래에 참조되는 page를 replace한다.
- 미래의 참조를 어떻게 알 수 있을까?
- Offline algorithm
- 다른 알고리즘의 성능에 대한 upper bound 제공
FIFO (First In First Out) Algorithm
- 먼저 들어온 페이지부터 먼저 내쫓음
- FIFO Anomaly (Belady's Anomaly)
- frame이 많아짐에도 불구하고 page fault가 늘어나는 현상
- FIFO 순서에 따라서 묘하게 순서가 꼬이는 경우에 발생할 수 있다
LRU (Least Recently Used) Algorithm
- 미래를 보고 판단할 수 없기 때문에 과거를 보고 판단하는 알고리즘
- 가장 오래 전에 참조된 것을 지움
LFU (Least Frequently Used) Algorithm
- 참조 횟수가 가장 적은 페이지를 지운다.
- 최저 참조 횟수가 여럿 있는 경우?
- 임의로 선정하는 것이 전통적인 방식이지만, 성능을 위해 참조 시기를 우선 순위로 하여 구현할 수도 있다.
LRU와 LFU 알고리즘의 구현
-
LRU
- 참조 시점을 기준으로 연결리스트를 만든다.
- 참조된 경우에는 가장 최신 노드 뒤에 연결하고, page fault인 경우에는 마지막에 있는 node를 빼주면 된다. 이러면 O(1)에 구현이 가능하다.
-
LFU
- 연결리스트로 구현하면 참조된 페이지를 어디로 옮겨야할 지 결정하기 힘들다.
- 제일 밑으로 내릴 수 없기 때문에 직접 비교를 해야 하므로 시간 복잡도가 높다.
- 이를 보완하기 위해 heap으로 구현한다.
- 참조 횟수에 따라 최소 힙으로 구현하여 참조될 때마다 힙 정렬이 일어나고, page fault가 발생할 때마다 root node를 빼준다.
다양한 캐슁 환경
- Caching
- 한정된 빠른 공간(캐시)에 요청된 자료를 보관하였다가 후속 요청시 캐시로부터 직접 서비스하는 방식
- paging 외에도 cache memory, buffer caching, Web caching 등 다양한 분야에서 사용
- 캐시 운영의 시간 제약
- 교체 알고리즘에서 삭제할 항목을 결정하는 일에 지나치게 긴 시간을 소비할 수 없다.
- 버퍼 캐싱이나 웹 캐싱에서는 O(1)에서 O(logn)까지만 허용한다.
- 페이징 시스템에서는 page fault인 경우에만 OS가 관여한다.
- 페이지가 이미 메모리에 존재하는 경우, 참조시각의 정보를 OS가 알 수 없다.
Clock Algorithm
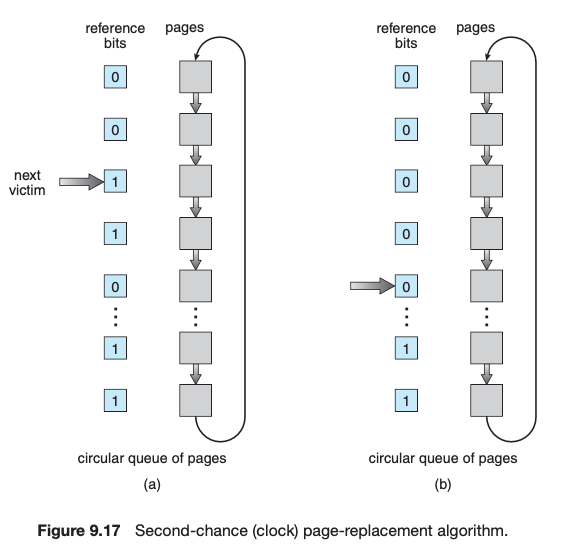
근본적으로 운영체제가 페이지의 참조 과정을 알 수 없기 때문에 하드웨어의 도움을 받아 페이지가 참조될 때마다 reference bit를 통한 clock algorithm을 사용한다.
만약 page fault가 발생하여 페이지 교체가 필요하다면 현재 next victim을 가리키고 있는 pointer가 돌기 시작한다. reference bit이 1인 페이지가 있다면 이 페이지는 최근에 참조되었던 것이므로 0으로 바꾸고 다음 페이지로 넘어간다. 1인 페이지를 만나면 0으로 바꾸는 것을 반복하다가 reference bit이 0인 페이지를 만나면 그 페이지를 쫓아낸다.
이런식으로 가장 참조되지 않았던 페이지를 찾는 과정에 근사한 알고리즘을 구현한다.
- Second chance algorithm
- Reference bit을 사용해서 교체 대상 페이지 선정
- dirty bit을 동반 사용하여 최근에 참조 여부/최근에 변경 여부를 동시에 체크할 수 있다. 만약 최근에 변경되었던 페이지가 쫓겨나는 경우 수정사항을 디스크에 반영하기 위한 용도로 쓰인다.
Page Frame의 Allocation
-
Allocation problem: 각 프로세스에 얼마만큼의 page frame을 할당할 것인가?
-
Allocation의 필요성
- 메모리 참조 명령어 수행 시 명령어, 데이터 등 여러 페이지를 동시에 참조한다.
- 명령어 수행을 위해 최소한 할당되어야 하는 frame의 수가 있다.
-
Loop를 구성하는 page들은 한꺼번에 allocate 되는 것이 유리함
- 최소한의 allocation이 없으면 매 loop마다 page fault가 발생한다.
-
Allocation Scheme
- Equal allocation: 모든 프로세스에 평등하게
- Proportional allocation: 프로세스 크기에 비례하여
- Priority allocation: 프로세스 우선순위에 비례하여
Global vs Local Replacement
-
Global replacement
- 다른 프로세스의 프레임도 교체 알고리즘 하에 자유롭게 경쟁하는 환경
- 프로세스 별 할당량을 조절하는 또 다른 방법
- Working set, PFF 알고리즘 사용
-
Local replacement
- 프로세스별로 프레임을 할당한다.
- 페이지 교체가 필요하면 자신에게 할당된 페이지 중에 하나를 교체함
Thrashing
메모리 상에 올라가는 프로세스가 많아지다보면, 어느 순간 CPU 이용률이 급격하게 낮아진다. 이는 잦은 page fault로 인해 어느 프로세스도 제대로 실행되지 못하는 순간인 것이다. 이 현상을 thrashing이라고 한다.
thrashing이 발생하면 CPU 이용률이 낮아지므로 운영체제는 CPU 이용률을 높이기 위해 더 많은 프로세스를 올린다. 이를 방지하려면 프로세스가 점유해야 할 최소한의 메모리를 설정해주어야 한다.
Working-set Model
-
Locality of reference
- 프로세스는 특정 시간동안 일정 장소만을 집중적으로 참조하는 경향이 있다.
- 이를 locality set이라고 부른다.
-
Working-set Model
- Locality에 기반하여 프로세스가 일정 시간 동안 원활하게 수행되기 위해 한꺼번에 메모리에 올라와 있어야 하는 page들의 집합을 Working Set이라 정의함
- Working set 모델에서는 process의 working set 전체가 메모리에 올라와있어야 수행되고 그렇지 않을 경우 모든 frame을 반납한 후 swap out
- Thrashing 방지, Degree of Multiprogramming을 결정
-
Working set의 결정
- Working set window를 통해 알아냄
- window size 시간 간격동안 참조된 서로 다른 페이지들의 집합이 working set이다
- 참조된 후 일정 시간동안 페이지를 메모리에 유지한 후 버린다.
PFF (Page-Fault Frequency) Scheme

- Page-fault rate에 따라서 할당하는 frame을 조절한다.
- 상한값을 넘으면 frame을 더 할당한다
- 하한값 이하이면 할당 frame 수를 줄인다.
- 빈 프레임이 없는 경우에 일부 프로세스를 swap out시킨다.
페이지 크기
- 페이지 크기를 늘리면?
- 필요한 페이지가 일부인데도 불구하고 전체 페이지를 다 불러오기 때문에 그만큼 메모리에서 손해를 본다.
- 페이지 크기가 작으면?
- 내부 단편화는 감소한다.
- 페이지 테이블의 엔트리가 늘어난다.
- 인접한 위치가 사용될 확률이 높은데 한 작업이 수행될 때 여러 페이지가 필요해진다.
- Disk transfer의 효율성이 감소한다.
