연결지향형 트랜스포트 : TCP
TCP 연결
- 연결지향형 : 데이터를 통신하는 두 프로세스가 서로 핸드셰이크를 먼저 해야함
- Point-to-point : 단일 송신자와 단일 수신자 사이의 점대점 연결
- full-duplex : 전이중 서비스 제공 - A에서 B로 데이터가 흐르면 B에서 A로도 데이터가 흐를 수 있음
- 3-way handshake : 세 방향 핸드셰이크 - 클라이언트가 요청을 보내고 서버가 응답을 한 후 클라이언트가 세번째 특별한 세그먼트로 응답함 처음 두 세그먼트에는 페이로드 즉 데이터가 없으며 세번째 세그먼트에는 페이로드(어플리케이션 계층의 데이터) 추가 가능
- 각 페이로드의 크기는 최대 세그먼트 크기 (Maximum segment size) MSS로 제한됨
- MSS는 헤더를 포함한 세그먼트의 최대 크기가 아니라 페이로드 즉 어플리케이션 계층 데이터에 대한 최대 크기
TCP 세그먼트 구조
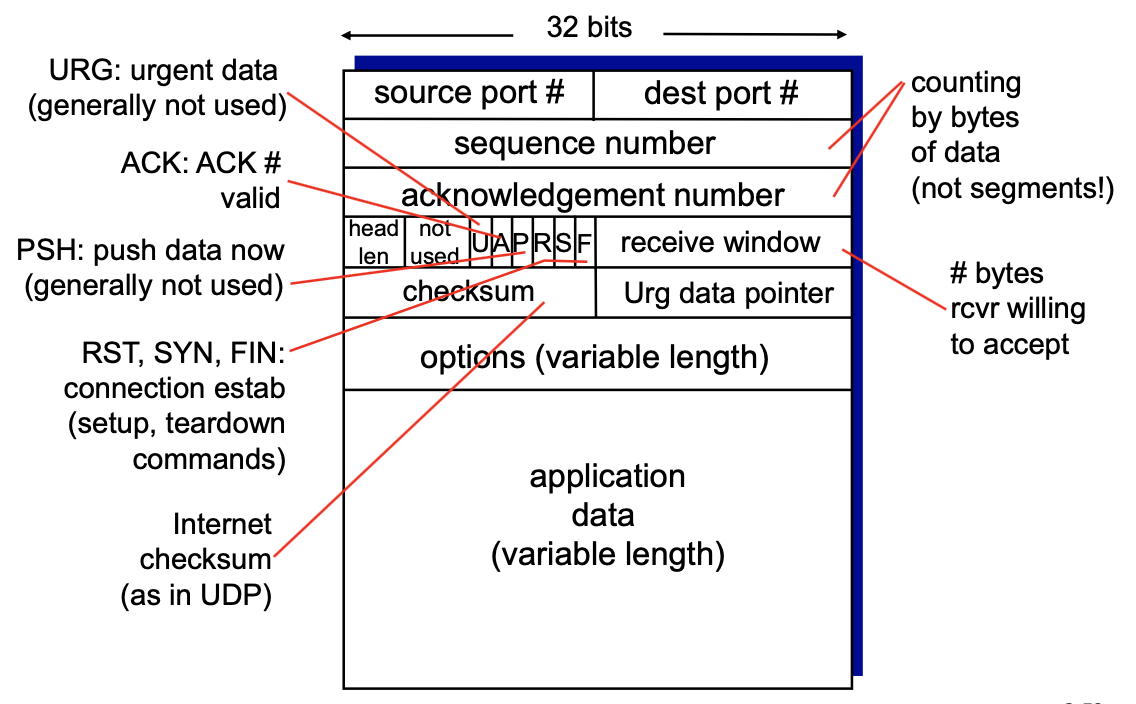
- 순서 번호 필드 : 송신 측에서 수신 측에 이 데이터가 몇번째 데이터인지를 알려줌
- 확인 응답 번호 필드 : 수신 측이 몇번째 데이터를 수신했는지 알려줌 → 필요한 다음 데이터 번호를 나타냄
- 수신 윈도우 : 흐름제어에 사용되며 수신자가 받아들이려는 바이트 크기를 나타냄 - 버퍼의 한계 크기
왕복시간(RTT) 예측과 타임아웃
- TCP 연결에서 적절한 타임아웃 시간 설정은 중요
- RTT보다 길어야 하며 너무 짧은 경우 타임 아웃이 너무 자주 발생하여 불필요한 재전송이 발생하고 너무 길 경우 세그먼트 손실에 대한 응답 속도가 길어짐
- SampleRTT 측정을 통해 적절한 타임아웃 시간을 설정
- 지수적 가동 이동 평균을 통해 이를 구함 - EstimatedRTT는 이전 값과 새로운 SampleRTT에 대한 가중된 조합
- EstimatedRTT = (1- a)*EstimatedRTT + a ** SampleRTT
- RTT의 변화율을 의미하는 DevRTT를 통해 SampleRTT가 EstimatedRTT로 부터 얼마나 벗아나는지 예측
- 실제 타임 아웃은 TimeoutInterval = EstimatedRTT + 4*DevRTT로 계산
신뢰적인 데이터 전달
- 인터넷의 네트워크 계층(IP)는 신뢰적인 데이터 전달 보장 X
- TCP는 파이프라인 세그먼트, 확인 응답, 재전송 타이머등을 이용해 신뢰적인 데이터 전달 보장
- 재전송은 타임아웃, 중복된 확인 응답에 의해 이루어짐
- TCP 송신측은 순서번호와 함께 세그먼트를 생성
- 세그먼트를 전송할 때 타이머를 실행
- 타임아웃이 발생하면 세그먼트를 재전송
- 송신측은 확인 응답 y를 받으면 누적 확인 응답을 사용하여 y 바이트 이전의 모든 바이트들의 수신을 확인하고 이전에 확인응답 안 된 세그먼트를 재전송
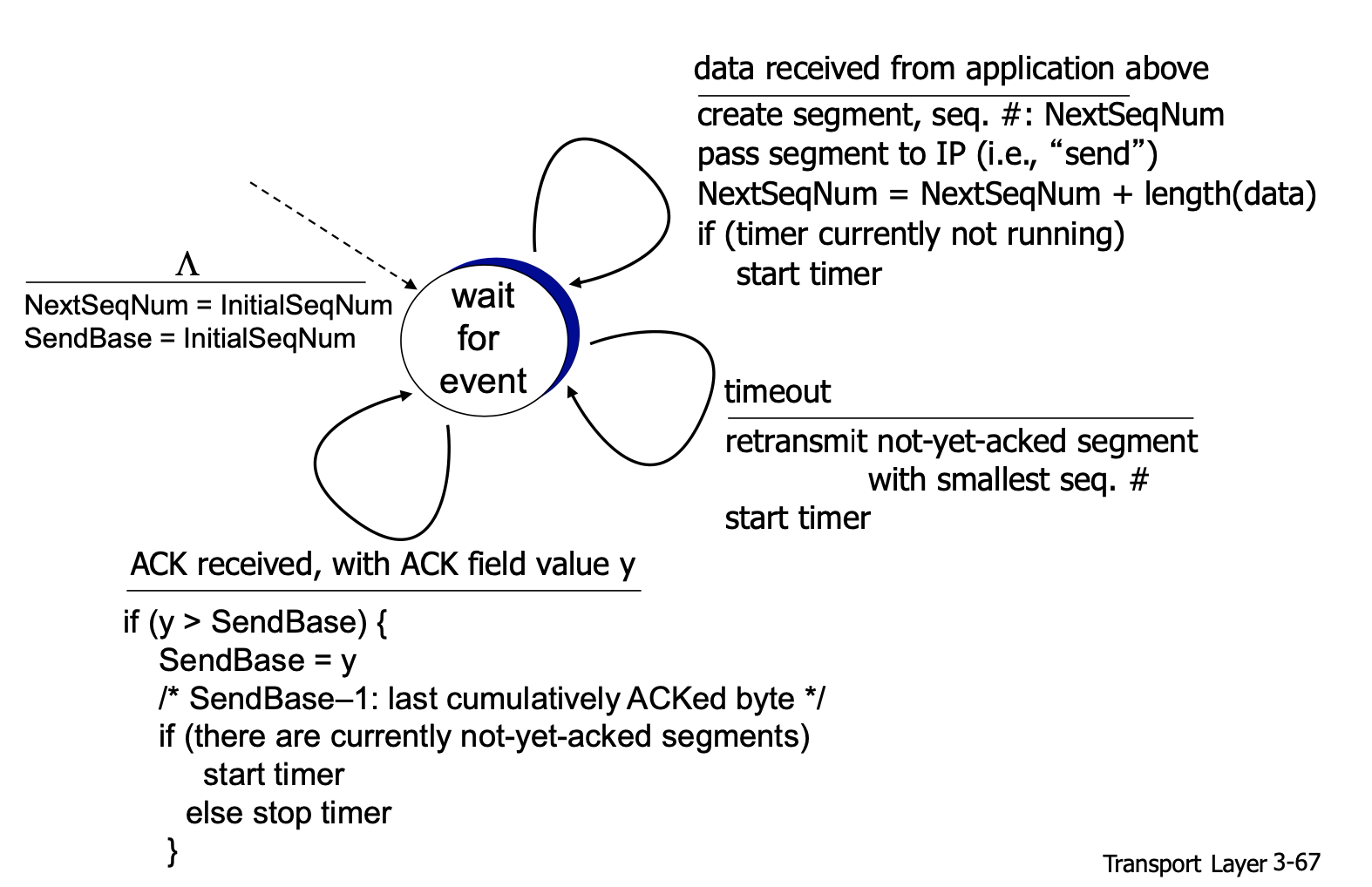
- TCP 송신자의 데이터 전송/재전송에 관련된 세가지 이벤트가 존재
- 어플리케이션에서 데이터를 받아 세그먼트로 캡슐화하여 이를 IP에 넘김
- 그 후 타이머가 다른 세그먼트에 실행중이지 않으면 타이머를 시작 → 확인되지 않은 가장 오래된 세그먼트를 추적
- 타임아웃이 발생하면 타임아웃을 일으킨 세그먼트를 재전송한 후 타이머를 다시 시작
- 수신자로부터 ACK y값을 전달 받으면 sendBase와 y를 비교
- y-1 바이트까지는 데이터가 무사히 전달되었다는것을 의미하기 때문에 sendBase가 y보다 작으면 y대입
- 그 후 아직 확인응답을 받지 않은 세그먼트가 존재하면 타이머 시작
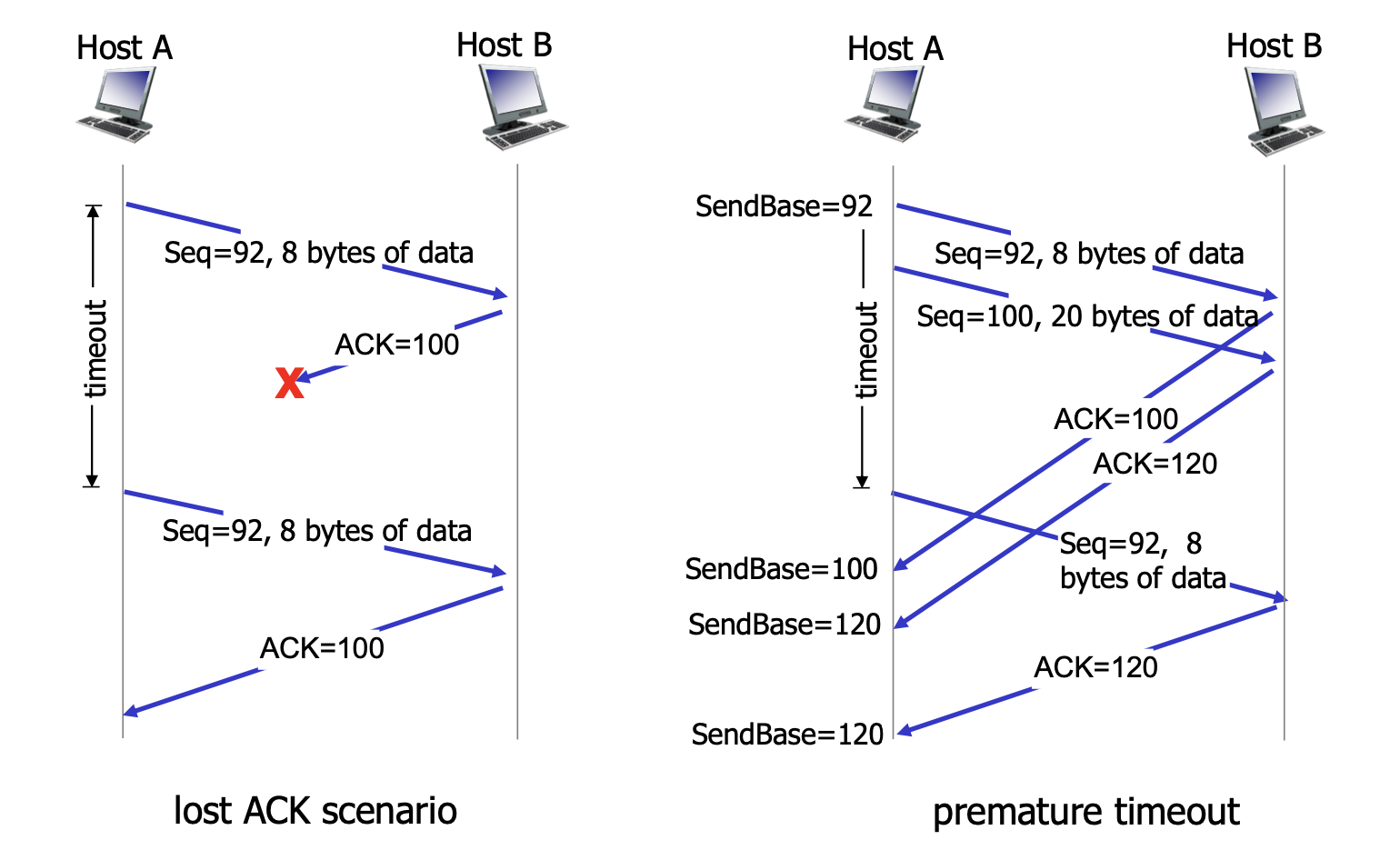
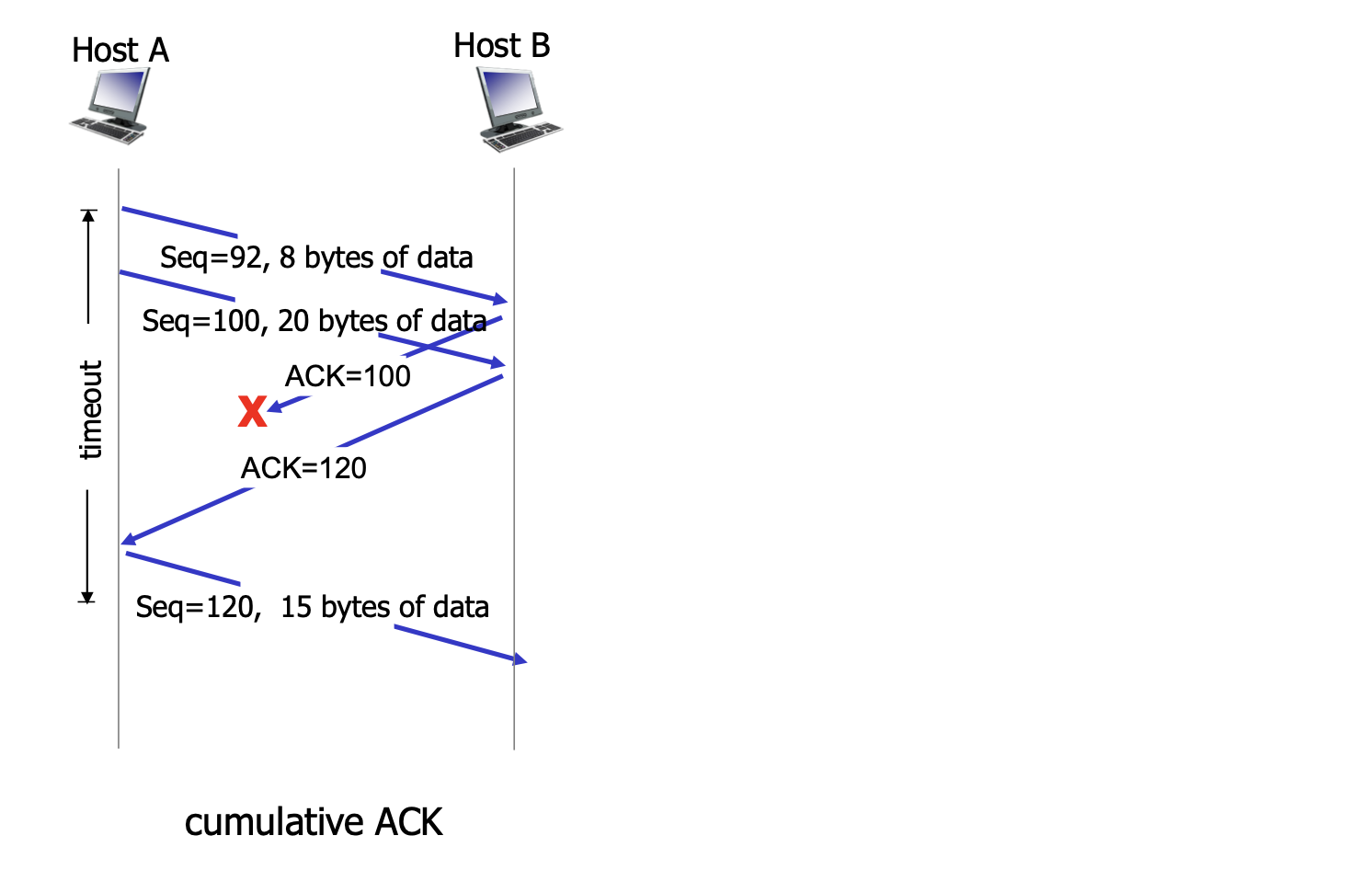
- 첫번째 시나리오 호스트 A가 호스트 B에게 순서번호 92와 8 q바이트의 데이터를 포함한 세그먼트 전송 B로 부터 오는 확인 응답 ACK 중간에 손실 타임 아웃이 일어나 세그먼트 재전송 B는 받은 세그먼트를 순서번호를 통해 이미 받았던 세그먼트임을 확인
- 두번째 시나리오 호스트 A가 연속해서 두 세그먼트를 전송 (92,8), (100,20) - 92번 세그먼트를 보낼 때 타이머 작동 두 세그먼트가 B에 둘다 무사히 도착해 두개의 ACK 전달(100, 120) 첫번째 세그먼트의 타임아웃 이전에 긍정 확인 응답을 수신하지 못함 타임 아웃 이벤트가 발생해 첫 번째 세그먼트를 재 전송 ACK 120을 전달 받으면 앞의 두가지 세그먼트를 수신자측에서 안전하게 전달받았다는것을 의미하기 때문에 sendBase에 120 대입
- 세번째 시나리오 호스트 A가 연속해서 두 세그먼트를 전송 (92,8), (100,20) - 92번 세그먼트를 보낼 때 타이머 작동 두 세그먼트가 B에 둘다 무사히 도착해 두개의 ACK 전달(100, 120) ACK 100이 중간에 손실 ACK 120이 무사히 도착하면 그 이전 데이터를 수신자측에서 안전하게 전달받았다는 뜻
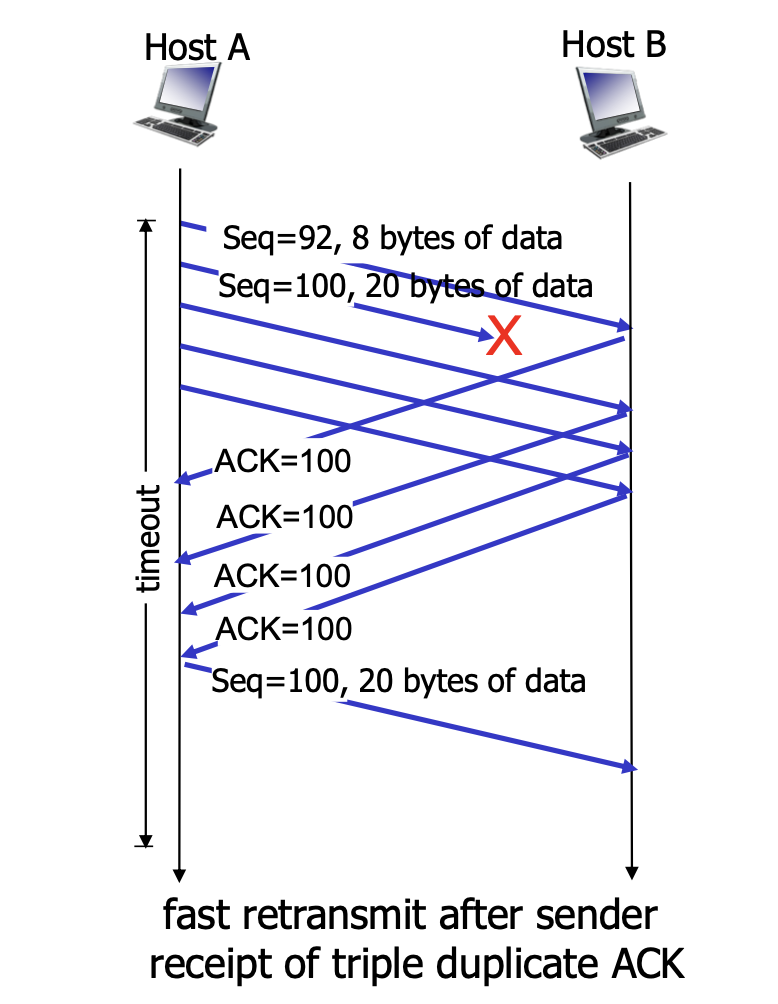
- 종종 타임아웃 주기가 길어지는 문제가 발생 - 손실된 패킷을 재전송하기까지 오래 걸림
- 중복된 ACK 확인을 통해 빠르게 손실된 패킷을 재전송가능
- 만약에 중간에 패킷이 손실됬다면 여러개의 중복 ACK가 발생
- 송신자가 3개의 중복된 ACK를 수신한다면 해당 순서번호를 지닌 데이터를 타임아웃이 만료되기 전에 빠르게 재전송함
흐름 제어 ( flow control )
- 흐름 제어 : 송신자가 수신자의 버퍼를 오버플로 시키는것을 방지
- 수신자가 메시지를 읽는 속도와 송신자가 메시지를 전송하는 속도를 같게 만듬
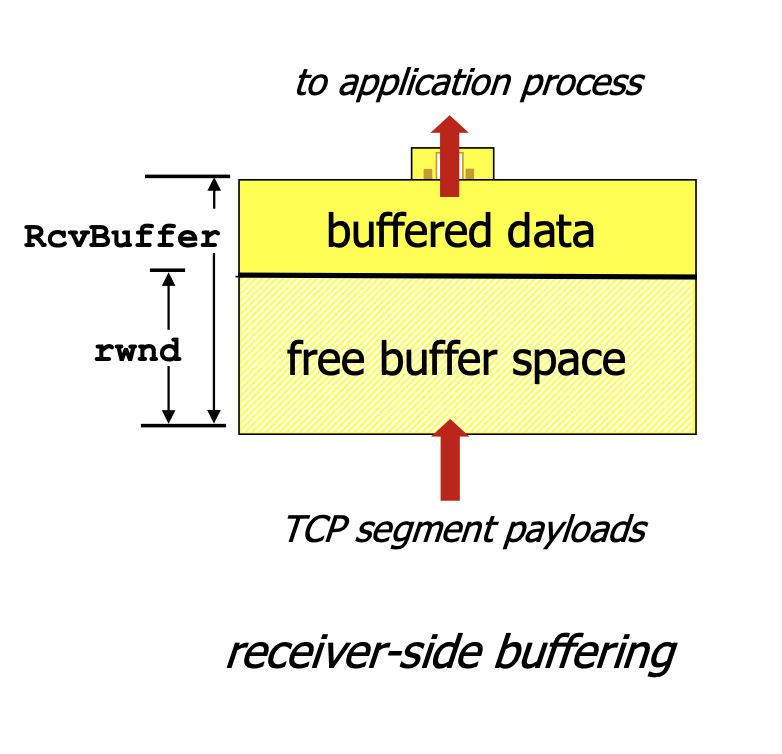
- TCP는 송신자가 수신 윈도우라는 변수를 유지하여 흐름제어 제공
- 수신자는 수신 윈도우를 송신자에게 지속적으로 알려줌
- 호스트 A와 B가 TCP 연결을 시작하면 B는 이 연결에 수신 버퍼를 할당
- rwnd라는 수신 버퍼에 남아 있는 공간을 송신자에게 보내는 모든 패킷의 헤더에 넣어줌
- 송신자는 전송 확인 응답이 안된 패킷의 크기가 rwnd를 넘지 않도록 조절
TCP 연결 관리
3-way handshake
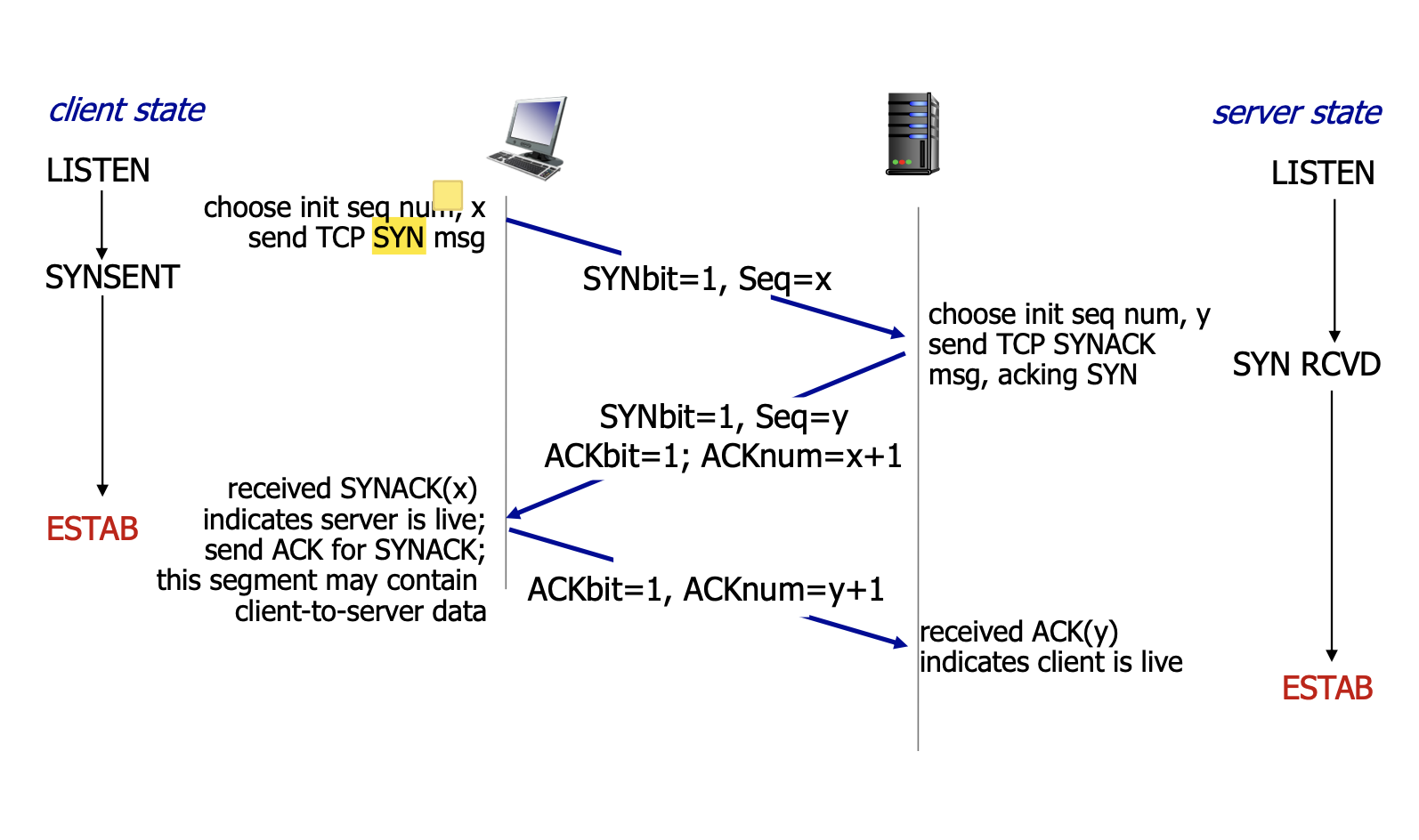
- 클라이언트는 서버로 SYN 세그먼트 전송 - 클라이언트의 순서 번호, SYN 비트 번호 삽입
- 클라이언트의 상태 : SYNSENT - SYN 세그먼트를 보낸 후 대기 상태
- 서버는 TCP 버퍼와 변수 할당
- 서버는 클라이언트로 SYNACK 세그먼트 전송 - 확인 응답 번호, 서버의 순서 번호, SYN 비트, ACK 비트 삽입
- 서버의 상태 : SYN RCVD - SYN 요청을 받고 상대방의 응답을 기다리는 상태
- 클라이언트는 TCP 버퍼와 변수 할당
- TCP 연결이 설정 되었기 때문에 SYN 번호 비트를 0으로 바꾼 후 ACK 세그먼트를 서버로 전송 - 확인 응답 번호, 비트 삽입
- ACK 비트는 데이터를 무사히 받았다는 것을 의미
- 세번째 응답부터 페이로드(어플리케이션측 데이터) 삽입 가능
4-way handshake
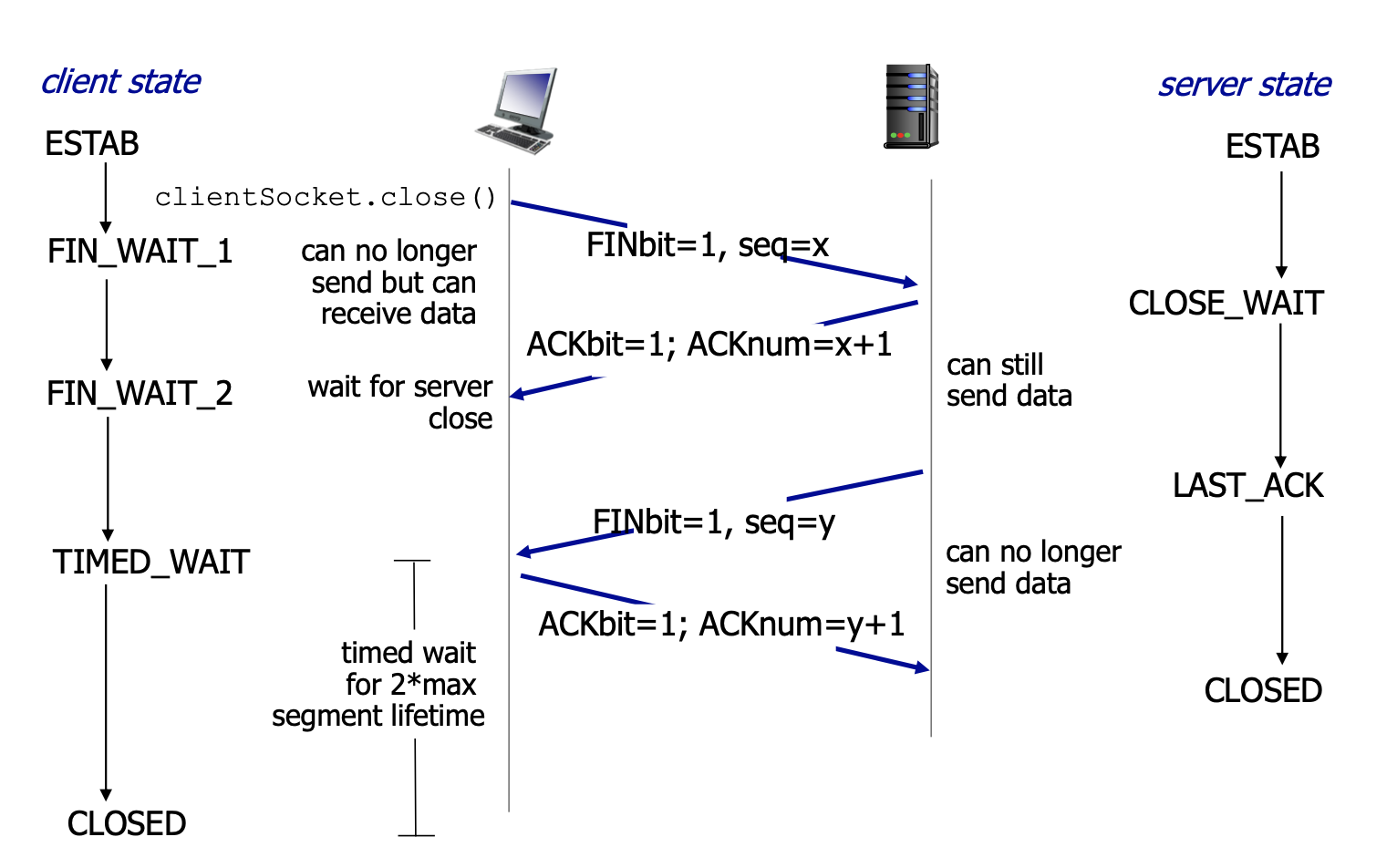
- 클라이언트가 연결을 종료하겠다는 FIN플래그를 전송한다. - FIN 비트를 1로 설정
- 클라이언트의 상태는 FIN_WAIT 상태로 들어가 서버의 응답을 기다림
- FIN_WAIT_1 : 서버의 ACK 응답 대기
- FIN_WAIT_2 : 서버의 FIN 플래그 대기
- 서버는 일단 확인메시지를 보내고 자신의 통신이 끝날때까지 기다리는데 이 상태가 ClOSE_WAIT상태다.
- 서버가 통신이 끝났으면 연결이 종료되었다고 클라이언트에게 FIN플래그를 전송한다. - FIN 비트를 1로 설정
- 클라이언트는 서버로부터 FIN 세그먼트를 전달 받으면 TIMED_WAIT 상태로 들어간 후 ACK 세그먼트를 보냄
- ACK 세그먼트가 중간에 손실될 경우 마지막 확인 응답을 재 전송
혼잡제어의 원리
- 혼잡 : 송신자가 너무 많은 데이터를 보내 네트워크가 감당하기 어려움
- 패킷을 잃어버리거나 딜레이가 길어지는 결과가 발생
혼잡의 원인과 비용
시나리오 1 : 2개의 송신자와 무한 버퍼를 갖는 하나의 라우터
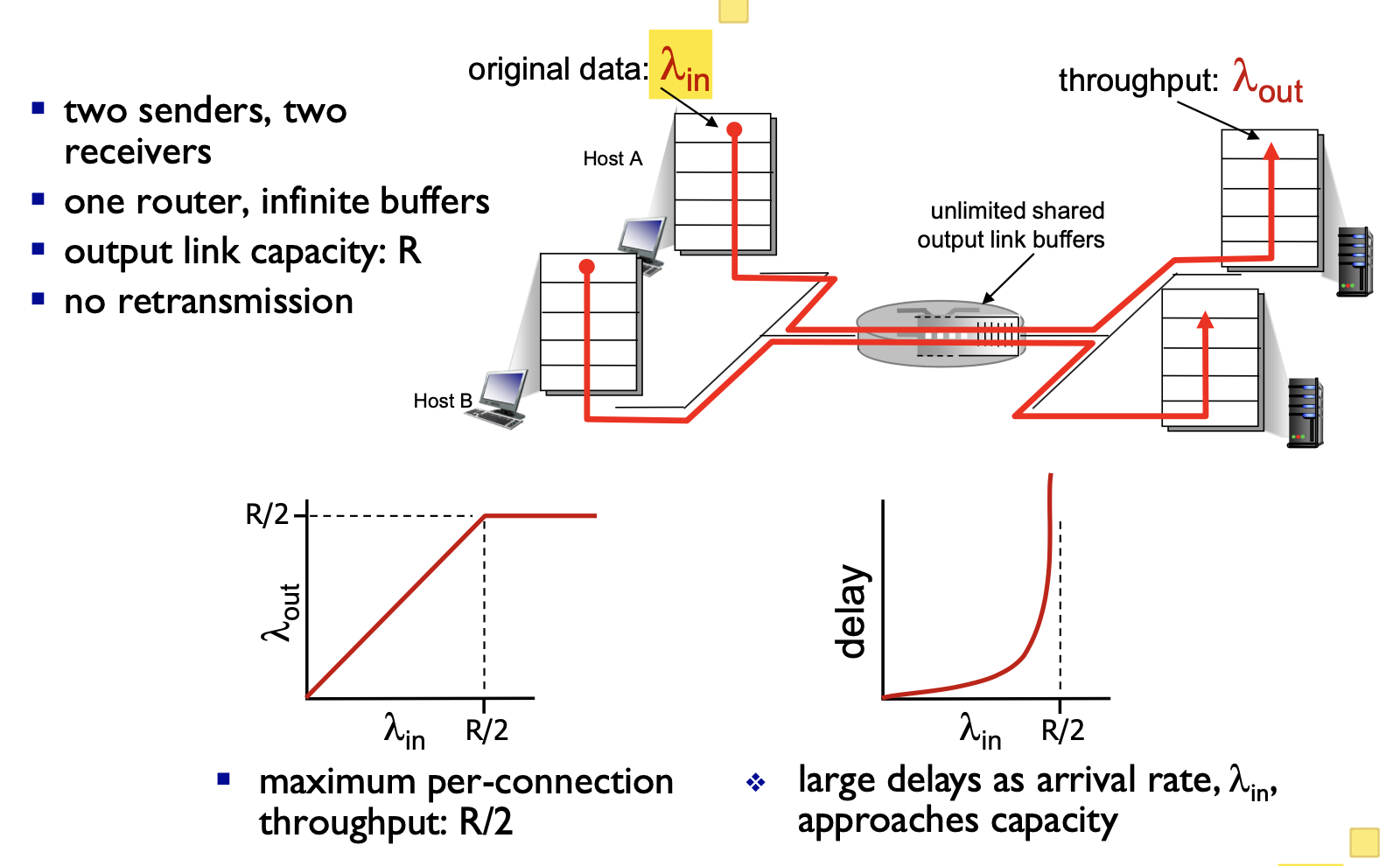
- 0과 R/2 사이의 전송률 사이에서 수신자의 처리량은 송신자의 전송량과 같음
- 전송률이 R/2 이상이 되면 수신자의 처리량은 증가하지 않음
- 전송률이 R/2를 초과하면 평균 지연량이 점점 커짐
- R/2 이상의 전송률을 지니는 것은 처리량 관점에서는 이상적이지만 지연 관점에서는 좋지 않음
- 패킷 도착률이 링크 용량에 근접함에 따라 큐잉 지연이 커짐
시나리오 2 : 2개의 송신자 유한 버퍼를 지닌 하나의 라우터
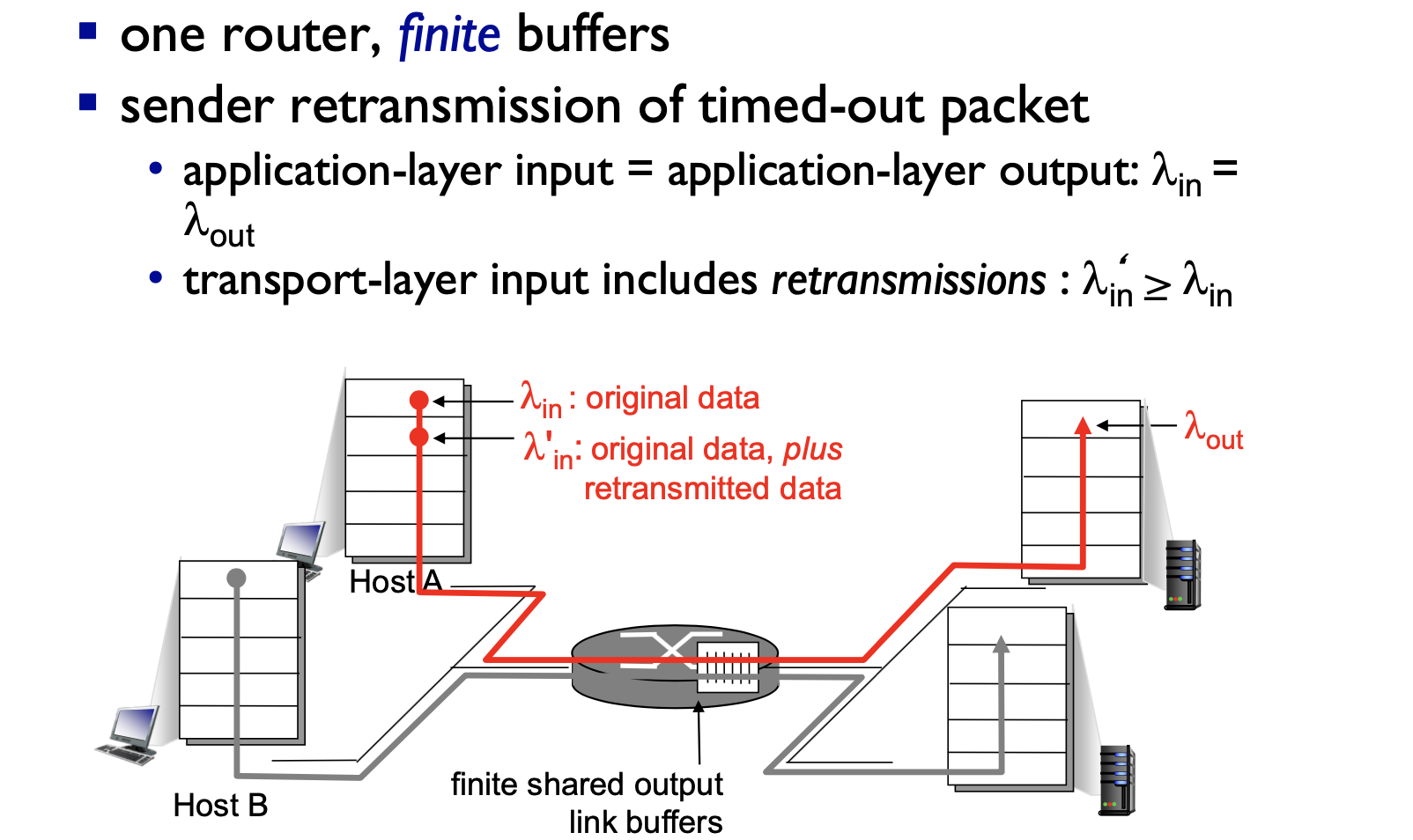
- 라우터의 버퍼의 양이 유한하다고 가정하면 이미 버퍼가 가득 찼을때 도착하는 패킷은 버려진다
- 각 연결을 신뢰적이라고 가정하여 버려진 패킷은 송신자에 의해 재 전송됨
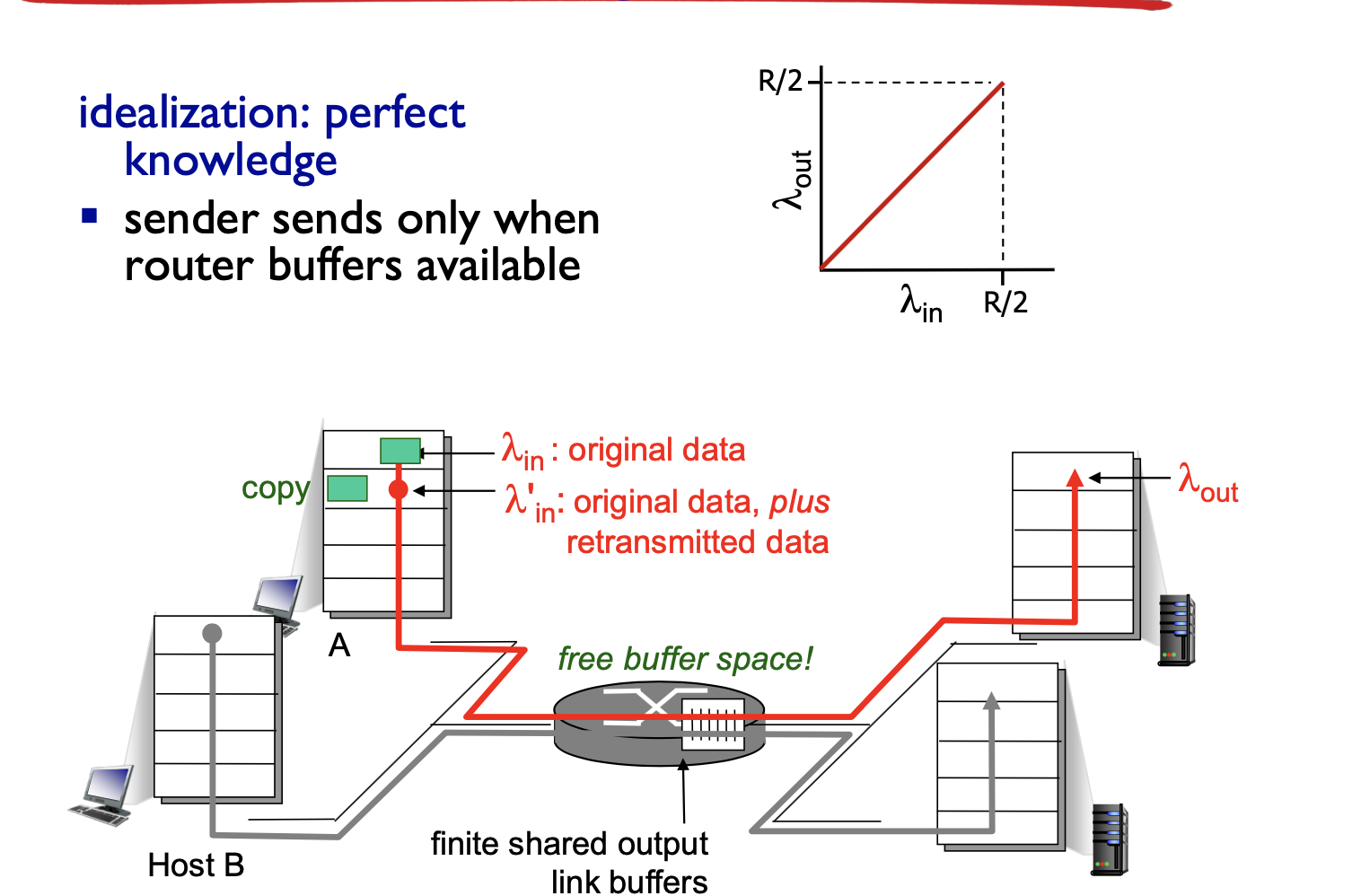
- 송신자는 버퍼가 비어있을 때만 패킷을 보내는 경우를 가정
- 패킷이 손실되지 않아 재전송 하지 않음
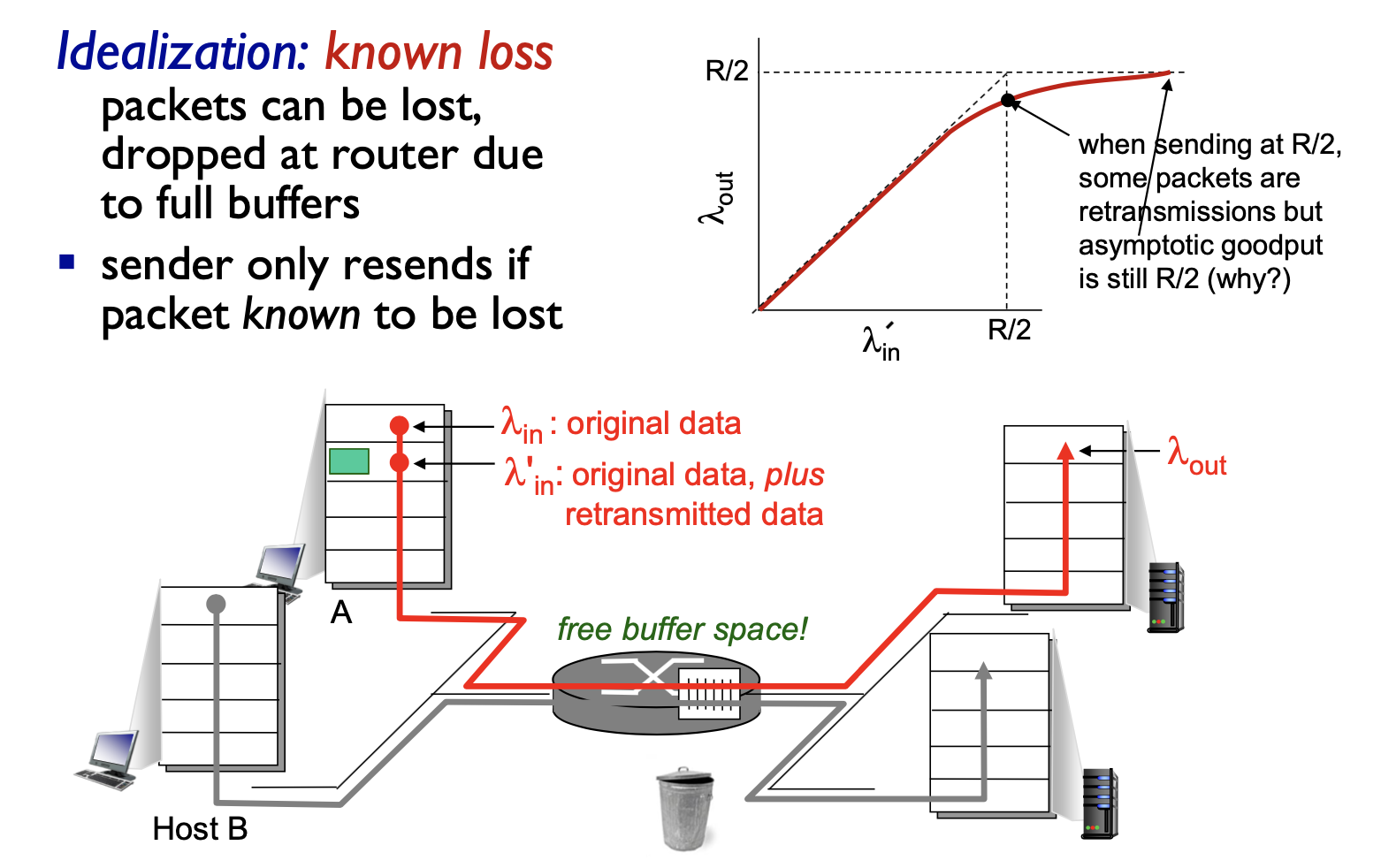
- 패킷이 유한 버퍼의 용량 때문에 손실 됬을 때 재전송하는 경우를 가정
- 송신자는 버퍼오버플로 때문에 버려진 패킷을 보상하기 위해 재전송을 수행
- 라우터에서 버려진 패킷에 대해서만 재전송을 하고, 처리되기 때문에 점차 R/2에 가까워지는 구조이다.
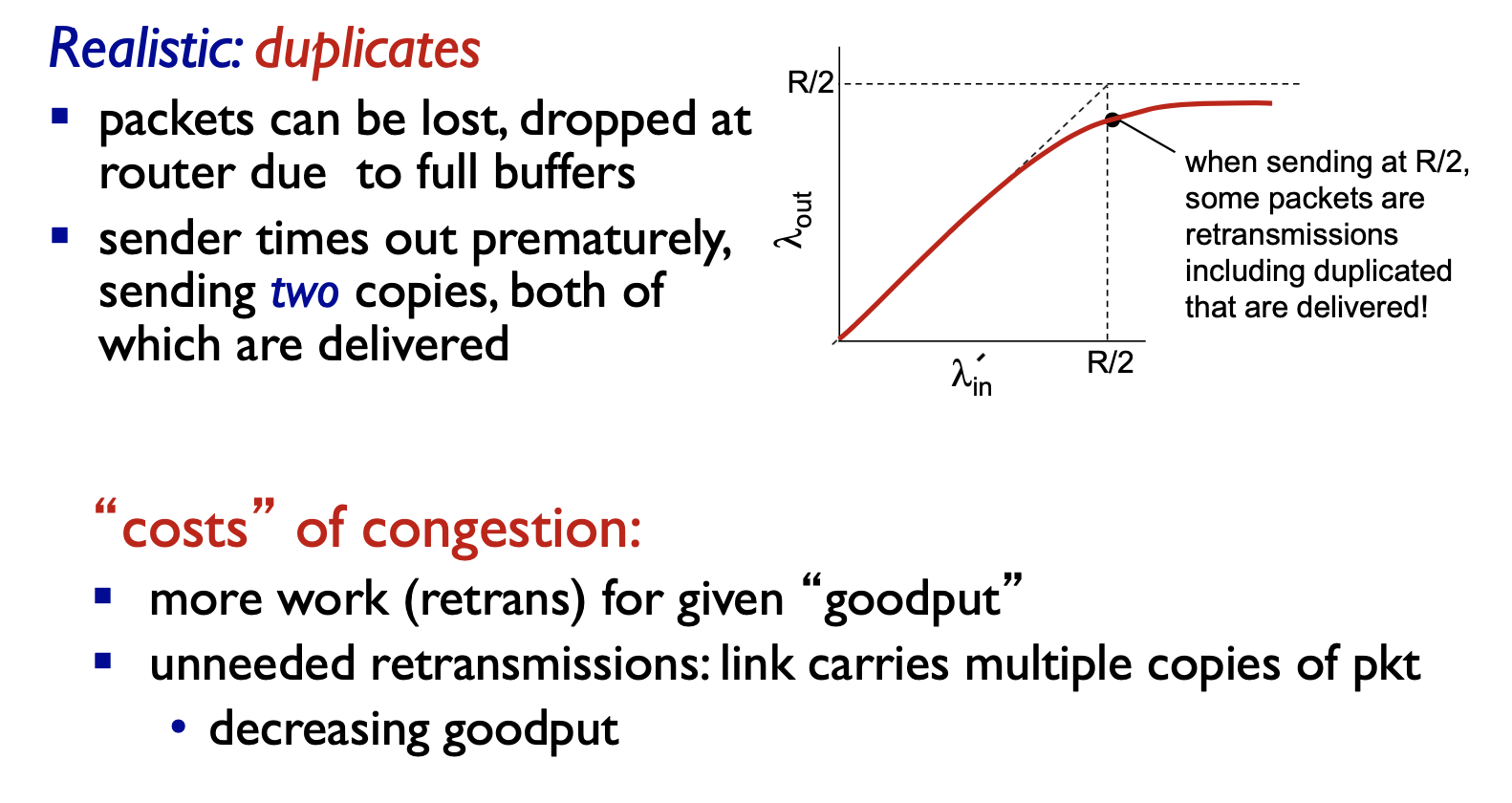
- 송신자에서 너무 일찍 타임아웃이 발생해 패킷이 손실되지 않았지만 재전송하는 경우를 가정
- 원래의 데이터 패킷, 재전송 패킷 둘다 수신자에게 도착
- 커다란 지연으로 인한 송신자의 불필요한 재전송은 라우터가 패킷의 불필요한 복사본들을 전송하는데 링크 대역폭을 사용하는 원인이 됨
시나리오 3 - 4개의 송신자와 유한 버퍼를 가지는 라우터, 멀티홉 경로
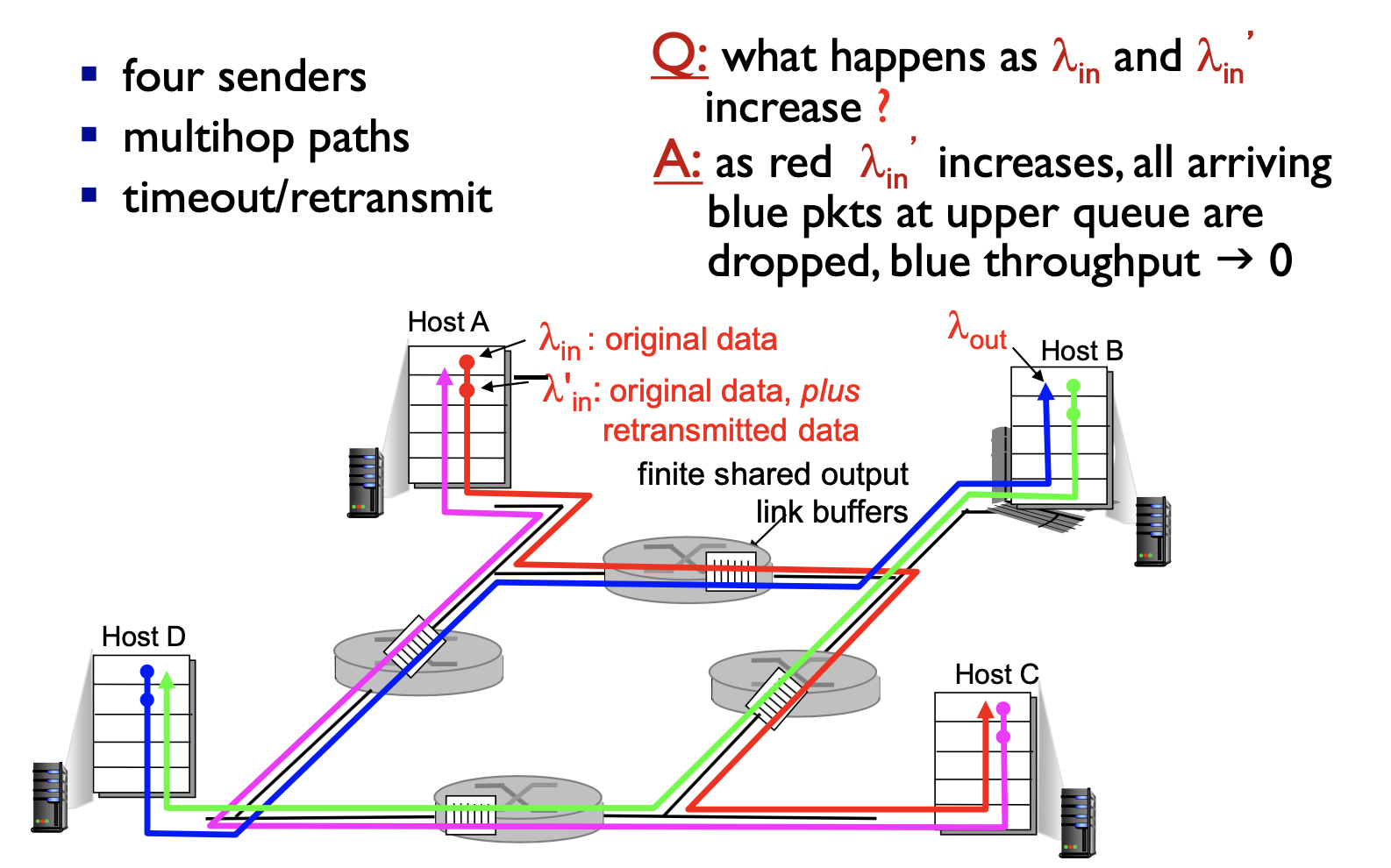
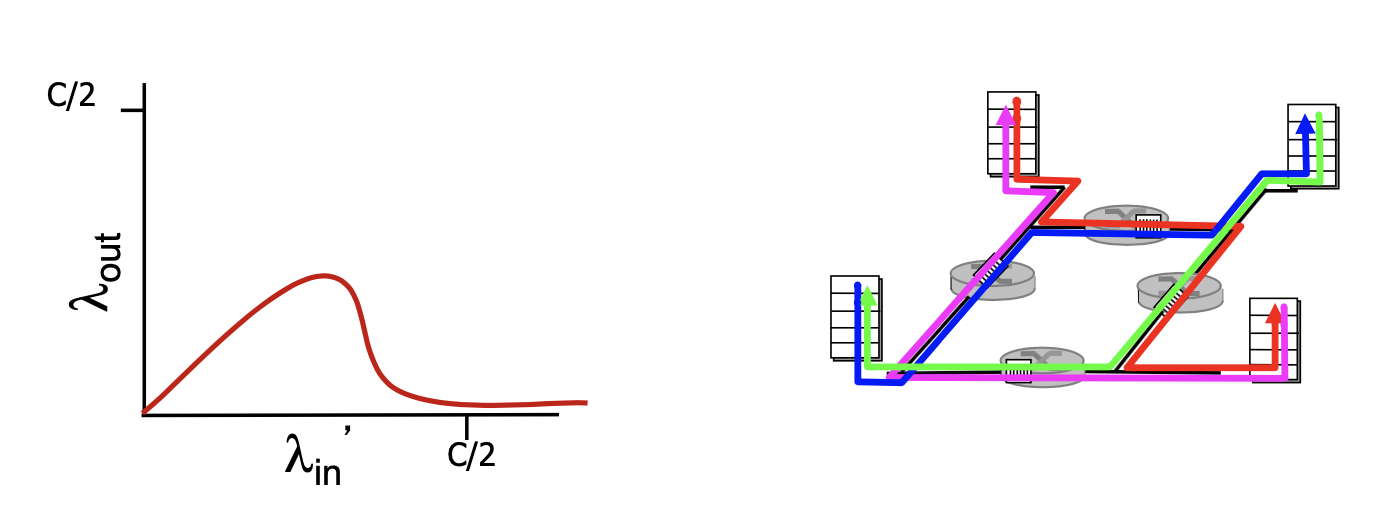
- 만약 A -> C, B->D로 각각 패킷을 전송한다고 했을 때, 서로 같은 멀티홉을 지나가는 순간이 존재하기 때문에 서로의 경로에 영향을 받게 된다. 즉, 너무 많은 패킷을 보내려다가 둘 다 못 보낼 수 있다는 뜻이다.
- λ'in 이 계속 증가하게 되면(재전송 발생 증가), 패킷이 경로 상에 버려지는 상황이 증가한다는 뜻으로, 버려지는 지점까지 패킷을 전송하기 위해 상위 라우터에서 사용되는 전송 용량은 낭비된다.
TCP 혼잡 제어
- 네트워크 혼잡에 따라 연결에 트래픽을 보내는 전송률을 각 송신자가 제한
- 혼잡 윈도우(congestion window) cwnd를 사용해 전송률 조절
- 송신측에서 ACK를 못받고 타임아웃되면 패킷 손실이 발생한 것으로 알고 Congestion으로 받아들인다. 따라서 송신측은 윈도우 크기(cwnd)를 줄여서 데이터 전송 속도를 조절한다.
- 송신측에서 패킷의 손실이 발생할 때까지 이용가능한 대역폭을 탐지하면서 전송률(Congestion Window Size, cwnd)을 증가시킨다.
- 가법적 증가(Additive Increase) : 손실이 발견될 때까지 매 RTT(왕복시간)마다 1MSS씩 cwnd를 증가시킨다. 추가로 매 ACK마다 cwnd는 MSS * (MSS/cwnd) 바이트씩 증가한다.
- 승법적 감소(Multiplicative Decrease) : 손실이 발생한 후에 cwnd를 절반으로 감소시킨다.
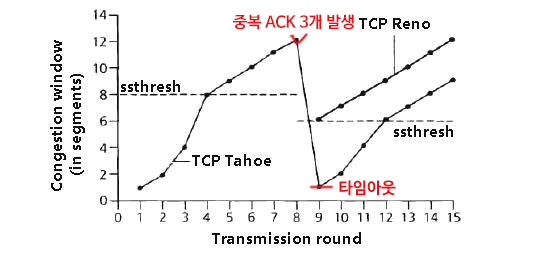
- 그래프 상에서 cwnd 값이 을 가지게 된다. 값이 꺾일 때마다 패킷의 손실이 발생한 것이다.

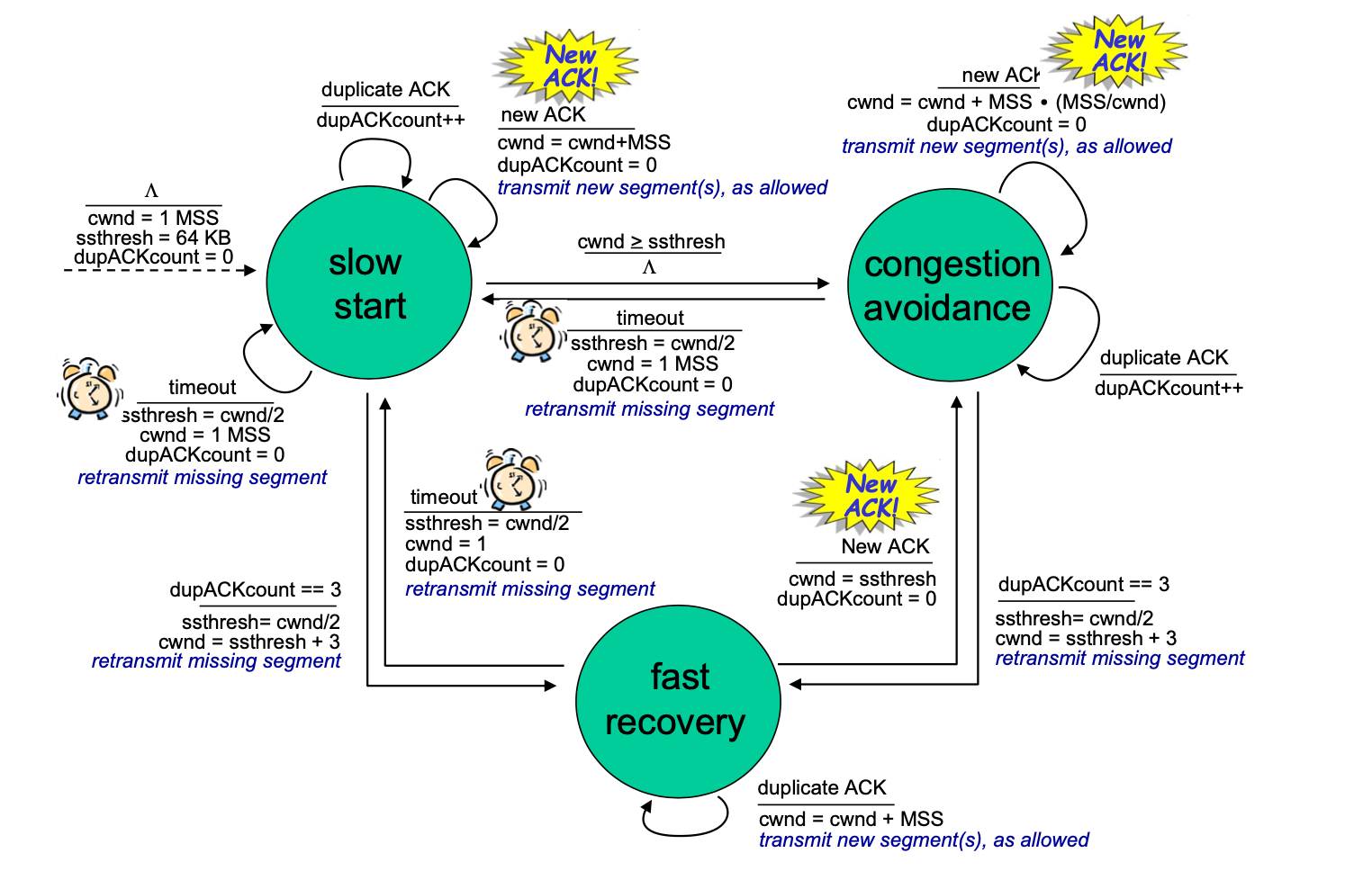
슬로 스타트
- cwnd의 값을 1 MSS로 시작하여 첫번째 확인 응답을 받을 때마다 2배로 증가
- 처음 전송률은 느리지만 시간일 지날수록 빨라짐
- 타임아웃에 의한 손실 이벤트가 발생할 경우 cwnd 값을 초기화 한 후 sstresh 값을 cwnd/2로 정함
- sstresh 값은 슬로 스타트의 임계치를 의미하며 추후 슬로스타트를 진행하며 cwnd 값이 이 값에 도달하면 슬로 스타트는 종료되고 혼잡 회피 모드로 들어감
- 3개의 중복 ACK 값이 검출되면 빠른 재전송을 수행해 빠른 회복 상태로 들어감
▶ 타임아웃에 대한 반응
- 타임아웃 또는 3개의 중복ACK 상황에서 항상 cwnd를 1 MSS 로 설정한다.
- 타임아웃에 의해 감지된 손실 : 전혀 전송되지 않은 것으로 간주하고, 심각한 ****혼잡 상황으로 받아들인다.
- cwnd = 1MSS (Slow Start 발생)
- cwnd는 지수적으로 증가하다가 에 달하면, 선형적으로 증가(혼잡 회피)한다.
- 3개의 중복 ACK에 의해 감지된 손실 : 다른 세그먼트(or 패킷)는 잘 도착했으므로 일부 세그먼트들은 전송해도 된다는 것으로 간주하고, 조금 혼잡한 상황으로 받아들인다.
- TCP Reno : cwnd는 절반으로 감소하고 이후에 선형적으로 증가한다.
- 이전의 TCP Tahoe 는 슬로 스타트(Slow Start)로 진입한다.
혼잡 제어와 흐름 제어의 차이
- Flow control은 (호스트와 호스트 간의 데이터 처리를 효율적으로 하기 위한 기법, End to End)
송신측과 수신측의 데이터처리 속도 차이를 해결하기 위한 기법이다.
- Congestion control은 (호스트와 네트워크 상의 데이터처리를 효율적으로 하기 위한 기법)
송신측의 데이터 전달과 네트워크의 처리속도 차이를 해결하기 위한 기법이다.

지금부터 공부하고 개발한것들을 꾸준하게 기록하자.