AWS CloudFront와 AWS ALB(Application Load Balancer)를 함께 사용할 때 발생할 수 있는 정적 리소스 문제와 그 해결책에 대해 이야기해보려고 해요. 저도 배포 과정에서 502 Bad Gateway 오류로 어려움을 겪었던 경험이 있어서, 여러분께 도움이 될 만한 내용을 공유하려고 합니다.
문제 상황
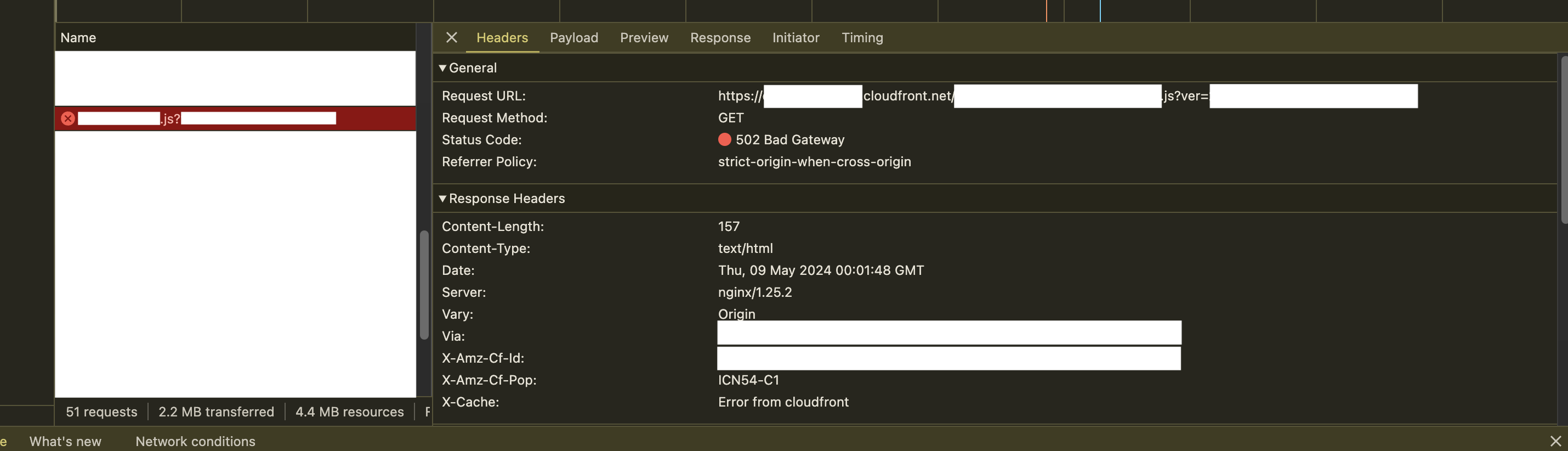
CloudFront를 통해 정적 리소스를 제공하던 중 50 Bad Gateway 오류가 발생했습니다. 이 오류는 ALB를 Origin으로 설정했을 때 주로 나타났어요. 서버가 아직 완전히 기동되지 않은 상태에서 CloudFront가 정적 리소스를 요청하면, 서버 상태가 "Healthy"로 표시되더라도 실제로는 비정상 상태이기 때문에 오류가 발생하게 됩니다.
문제 원인
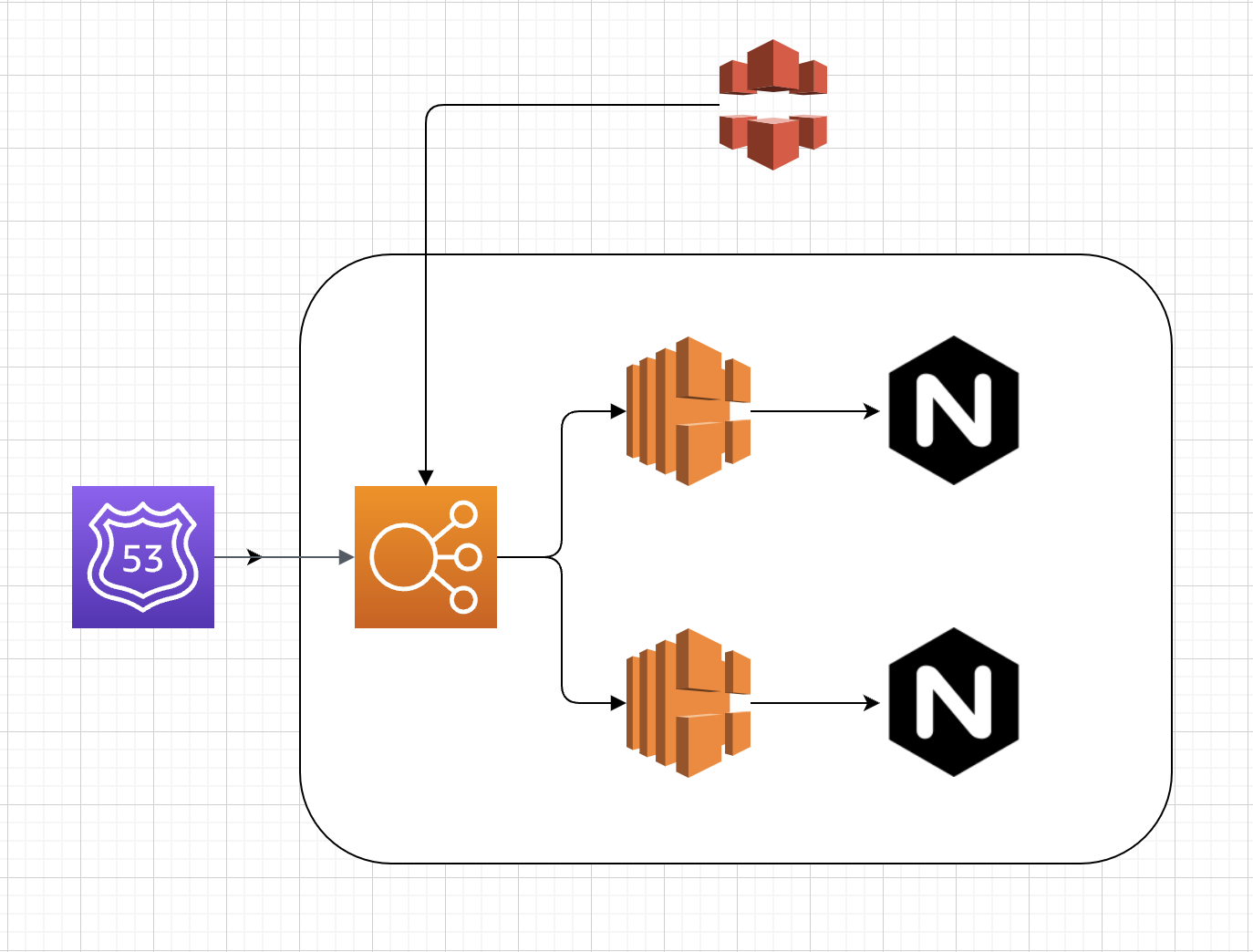
Cloud Front, ALB, EC2, Nginx를 사용해 인프라 구조를 작성해봤어요!
아래의 구조를 가지고 있을때 배포중 Cloud Front Invalidation 했을때 502 발생합니다.
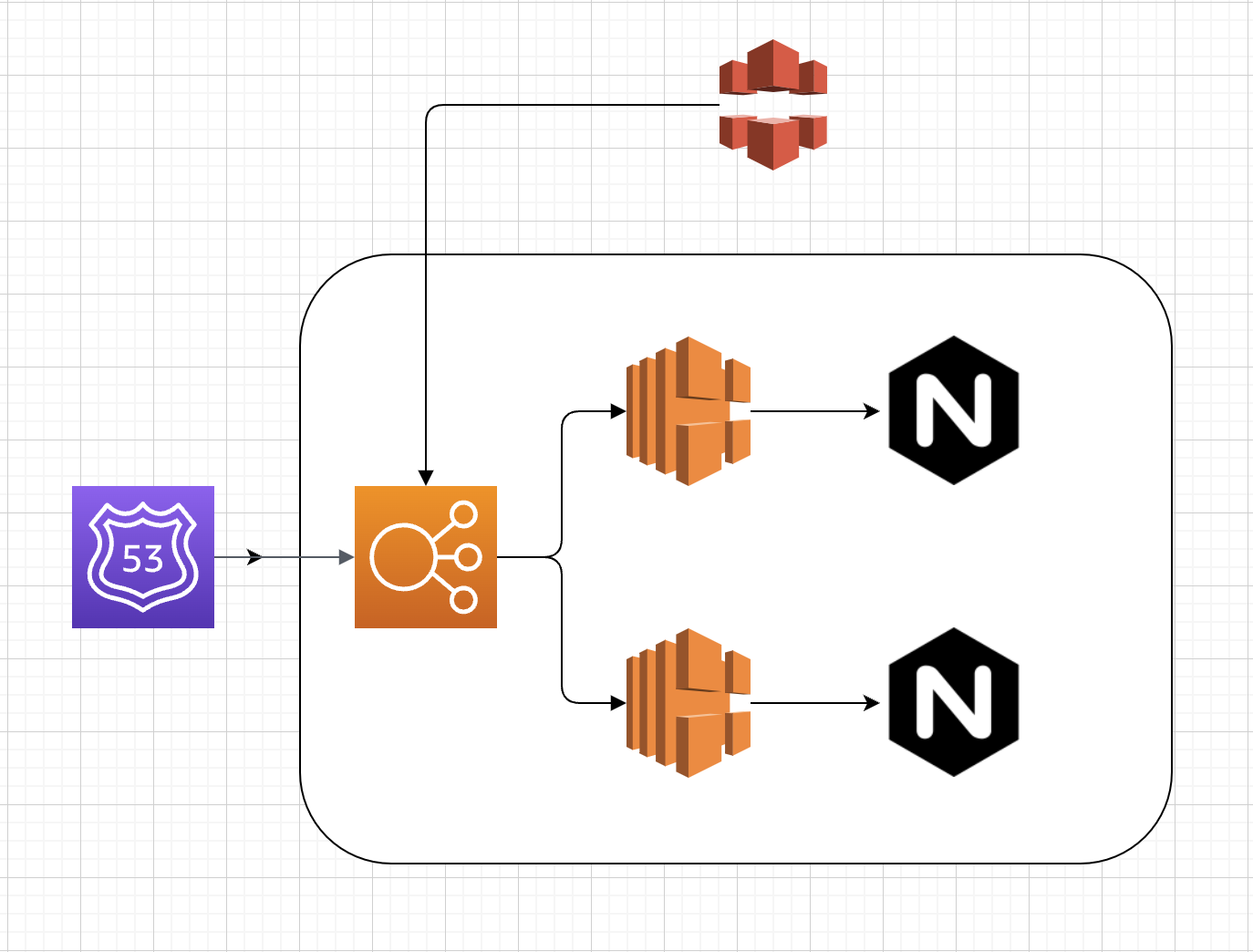
1. 서버 기동 지연: 서버가 완전히 기동되지 않았음에도 불구하고 ALB에서 서버를 "Healthy" 상태로 인식해요,서버 상태를 감지하는 데 필요한 최소 시간이 있기 때문이죠.
2. CloudFront 요청: 이 시간 동안 CloudFront가 정적 리소스를 요청하면, 서버가 준비되지 않아 502 오류가 발생합니다.
해결책
-
배포 스크립트 수정
- 도커를 켜고 타겟 서버 등록을 생략한 후, 서버가 완전히 기동된 것을 확인하고 CloudFront 무효화를 진행 (30초 대기 제거).
- 단, 위와 같이 설정했을때는 서버 1대는 업데이트가 되었고 다른 서버는 업데이트가 되지 않아 사용자에게 오류가 발생할 수 있어요...!
-
Nginx 백업 설정
- 1번 서버는 2번 서버로, 2번 서버는 1번 서버로 백업 지정하여 한 서버에 문제가 발생했을 때 백업 서버에서 요청을 처리하도록 합니다. (아래의 Nginx 설정을 참고해주세요)
upstream andrew_webserver {
server ${andrew_was_1}:9090 max_fails=3 fail_timeout=3;
server ${andrew_aws_2}:9090 backup;
}
server ${andrew_was_1}:9090 max_fails=3 fail_timeout=3;
- server: 로드 밸런싱할 서버의 주소와 포트를 지정합니다.
- max_fails: 서버가 몇 번 연속으로 실패한 후에 비정상 상태로 간주할지 지정합니다. 여기서는 3번 연속 실패 시 비정상으로 간주합니다.
- fail_timeout: 서버가 비정상 상태로 간주된 후 재시도하기 전까지 대기할 시간을 설정합니다. 여기서는 3초입니다
server ${andrew_aws_2}:9090 backup;
- backup: 메인 서버가 모두 비정상 상태일 때만 요청을 처리하는 백업 서버로 설정합니다.- 서버 상태 체크 인터벌 조정
- ALB의 상태 체크 주기를 늘려서 서버가 완전히 기동된 후에 "Healthy"로 인식되도록 설정할 수 있습니다. 이렇게 하면 서버 기동 지연 문제를 완화할 수 있어요.
4, CloudFront 캐시 TTL 조정
- CloudFront의 캐시 TTL(Time To Live)을 적절히 조정하여 서버가 완전히 기동되기 전까지 캐시된 콘텐츠를 제공하도록 할 수 있습니다. 이렇게 하면 사용자가 503 오류가 제거 될 수 있어요! 다만 데이터가 혼재 될 수 있을 가능성이 있으니 테스트는 필수에요
- ALB 타겟 그룹의 Deregistration Delay 설정
- ALB의 타겟 그룹에서 Deregistration Delay를 설정하여, 기존 연결이 완전히 종료된 후에만 타겟을 등록하거나 등록 해제할 수 있도록 할 수 있습니다.
결론
CloudFront와 ALB를 함께 사용할 때 발생할 수 있는 정적 리소스 문제를 해결하기 위해 배포 스크립트를 수정하고, Nginx 백업 설정을 활용하는 것이 효과적이었습니다. 추가적으로 서버 상태 체크 인터벌 조정, CloudFront 캐시 TTL 조정, ALB 타겟 그룹의 Deregistration Delay 설정, 그리고 Health Check URL 지정을 통해 더 안정적인 서비스를 제공할 수 있지 않을까요?