참고 문서
AWS Re:Post
Aurora Official Document
Postgresql Document
🚨 오류 분석: canceling statement due to conflict with recovery
오류 메시지:
업무 중 QA 확인 요청이 들어왔다. 로그를 살펴보던 중 처음 보는 오류가 발생한 것을 발견했다. 해당 이슈는 아주 간헐적으로 발생했지만, 트래픽이 많아지면 큰 문제가 될 수도 있었다. “빠르게 원인을 파악하고 수정하자!”는 생각으로 5시간 동안 분석한 내용을 정리해보았다.
만약 Primary - Replica 구조로 데이터베이스를 운영 중이라면, 이와 유사한 문제를 겪을 가능성이 높다. 같은 고민을 하고 있을 개발자들에게 조금이나마 도움이 되길 바란다! 🚀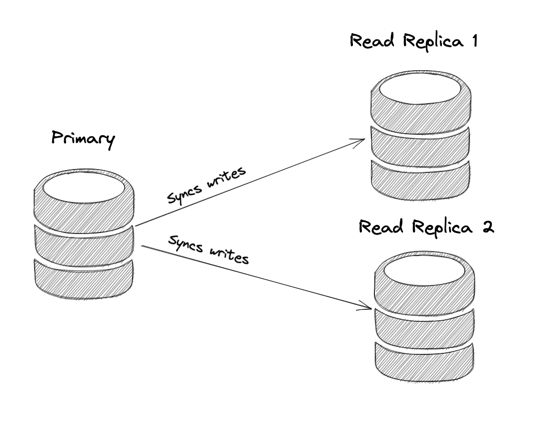
Caused by: ERROR: canceling statement due to conflict with recovery
Detail: User query might have needed to see row versions that must be removed.
🚪 들어가기전에…
📖 1. WAL (Write-Ahead Logging) 이란?
✅ WAL의 개념
WAL(Write-Ahead Logging)은 PostgreSQL 및 Aurora PostgreSQL에서 데이터 무결성을 보장하기 위한 로깅 메커니즘이다.
WAL은 데이터를 디스크에 반영하기 전에 변경 사항을 로그로 먼저 기록하는 방식으로 동작하며, 이를 통해 데이터베이스 크래시 복구(crash recovery) 및 복제를 지원할 수 있다.
✅ WAL의 핵심 원리
- 데이터 변경 요청(INSERT, UPDATE, DELETE, TRUNCATE 등)이 발생하면, 변경 사항이 먼저 WAL에 기록됨.
- 트랜잭션이 COMMIT되면 WAL이 디스크에 저장됨.
- WAL의 내용을 기반으로 실제 테이블 데이터를 디스크에 반영함.
- Aurora에서는 WAL이 Aurora 스토리지 계층을 통해 Replica(Reader) 노드로 전파됨.
📌 즉, WAL은 데이터를 안전하게 보호하고 복제하기 위한 핵심 기술이다.
📖 2. Aurora PostgreSQL의 Replication 방식
✅ Aurora PostgreSQL의 복제 방식
Aurora는 일반적인 PostgreSQL과 다르게 공유 스토리지 기반(Shared Storage-based) 복제 시스템을 사용한다.
즉, Aurora의 Primary(Writer) 노드와 Replica(Reader) 노드는 동일한 스토리지 계층(Aurora Storage Layer)을 공유하며,
각 Replica 노드는 Primary에서 발생한 변경 사항(WAL, 또는 Aurora의 Redo Log)을 Aurora 스토리지 계층에서 직접 읽어서 적용한다.
📌 즉, 일반 PostgreSQL처럼 Streaming Replication으로 WAL을 Primary에서 직접 Replica로 "PUSH"하는 방식이 아니라, Aurora의 Replica가 필요할 때 WAL을 "PULL"하는 방식이다.
✅ Aurora의 Replication 트리거 포인트 (WAL이 Replica로 전파되는 시점)
| 트리거 조건 | 설명 |
|---|---|
1. 트랜잭션 COMMIT; 시 WAL 전송 | Primary에서 COMMIT;이 실행되면 WAL(또는 Aurora Redo Log)이 즉시 Aurora 스토리지 계층에 반영됨. |
| 2. WAL 버퍼가 가득 차면 자동 전송 | wal_buffers 크기를 초과하면 트랜잭션이 COMMIT; 되지 않아도 WAL이 Aurora 스토리지 계층에 기록됨. |
3. fsync 또는 CHECKPOINT; 실행 시 WAL 전송 | Aurora는 fsync를 최적화하여 자동으로 관리하지만, CHECKPOINT;가 실행되면 WAL이 강제로 Aurora 스토리지 계층에 기록됨. |
| 4. Replica가 WAL을 읽어야 할 때 (PULL 방식) | Replica(Reader)는 Primary에서 WAL을 직접 받는 것이 아니라, Aurora Storage Layer에서 필요할 때 WAL을 읽어 적용함. |
📌 즉, Aurora의 Replica는 WAL을 요청할 필요 없이 Aurora Storage Layer에서 직접 읽어서 동기화한다.
💀 3. WAL이 기록되면서 Replica에서 튜플이 제거되는 과정
Aurora PostgreSQL에서는 Primary(Writer)에서 WAL(Write-Ahead Log)이 생성되면, 이를 기반으로 변경 사항이 Replica(Reader)에 반영됩니다.
이 과정에서 DELETE, UPDATE 등의 변경 사항이 Replica에서 적용되면서 기존 튜플이 더 이상 접근할 수 없게 되어 오류가 발생할 수 있습니다.
📌 즉, WAL이 기록되면서 Replica에서 기존 튜플이 제거되는 원리는 “MVCC + WAL 적용 방식”에 의해 결정됩니다.
🔥 1️⃣ MVCC에서의 튜플 삭제 원리 (Multi-Version Concurrency Control)
PostgreSQL 및 Aurora PostgreSQL은 MVCC(Multi-Version Concurrency Control)을 사용하여 튜플(행, row)을 관리합니다.
MVCC에서는 DELETE, UPDATE를 실행해도 기존 튜플이 바로 사라지지 않으며, 새로운 버전이 생성됩니다.
그러나 Replica에서는 WAL을 적용하면서 기존 튜플을 더 이상 접근할 수 없게 만들기 때문에, SELECT가 충돌할 수 있습니다.
🚀 예제: Primary에서 DELETE 수행 후 MVCC 상태 변화
DELETE FROM users WHERE id=2;트랜잭션 동작 과정
- DELETE 실행 시, 기존 튜플이 즉시 삭제되지 않고 "Dead Tuple"로 남음.
- 새로운 트랜잭션이 실행될 때, MVCC를 통해 해당 튜플이 더 이상 접근할 수 없는 상태가 됨.
- VACUUM이 실행되기 전까지 Primary에서는 Dead Tuple이 유지됨.
- 그러나 Replica에서는 WAL이 적용되면서 "해당 튜플이 접근 불가능한 상태"가 됨.
- 이 시점에서 SELECT가 해당 튜플을 조회하려고 하면 오류 발생 가능.
🔥 2️⃣ WAL이 기록되고 Replica에서 튜플이 제거되는 과정
✅ WAL을 통해 Replica에서 튜플이 제거되는 원리
- Primary에서 DELETE 또는 UPDATE 실행 → WAL에 변경 사항이 기록됨.
- Replica가 WAL을 적용하는 순간, 해당 튜플이 더 이상 접근할 수 없도록 MVCC 상태를 변경함.
- 만약 Replica에서 실행 중이던 SELECT가 해당 튜플을 참조하려 하면, PostgreSQL은 WAL 적용을 방해하는 SELECT를 강제 종료함.
- 이 시점에서
canceling statement due to conflict with recovery오류 발생!
🔥 3️⃣ WAL을 통한 튜플 제거가 발생하는 상세 과정
Primy에서 DELETE 후 WAL이 기록되고 Replica에서 적용될 때 튜플이 제거되는 과정을 단계별로 설명한 것입니다.
🚀 예제: DELETE FROM users WHERE id=2; 수행 후 WAL이 Replica에서 적용되는 과정
🟢 Step 1: Primary에서 DELETE 실행
DELETE FROM users WHERE id=2;| 트랜잭션 ID | id | name | XID (트랜잭션 ID) | 상태 |
|---|---|---|---|---|
| 500 | 2 | Alice | 1001 | ✅ 활성(Active) 튜플 |
| 501 | 2 | (삭제됨) | 1002 | ❌ Dead Tuple (삭제 예정) |
📌 Primary에서 DELETE가 발생하면 기존 튜플이 "즉시 삭제되지 않고" Dead Tuple이 됨.
📌 그러나 WAL을 통해 Replica로 변경 사항이 전달됨.
🟡 Step 2: Primary에서 WAL 기록
- DELETE가 발생하면 변경 사항이 WAL에 기록됨.
- 이제 WAL을 통해 변경 사항이 Replica에 전달될 준비가 됨.
SELECT * FROM pg_walfile_name_offset();| LSN (Log Sequence Number) | 트랜잭션 ID | 변경 내용 |
|---|---|---|
0/1638F20 | 1002 | DELETE id=2 |
📌 즉, WAL이 생성되면서 id=2가 삭제된 사실이 기록됨.
📌 이 WAL이 Replica에서 적용될 때 기존 튜플이 접근 불가능하게 됨.
🟠 Step 3: Replica에서 WAL 적용
- Replica에서 WAL을 적용하는 순간, MVCC는 기존 튜플을 "더 이상 볼 수 없게" 설정함.
- 즉, Primary에서는 Dead Tuple로 남아 있을 수도 있지만, Replica에서는 WAL이 적용되면서 "즉시 사라짐".
- 만약, 이 시점에서 해당 튜플을 SELECT하는 쿼리가 실행 중이었다면 오류 발생!
SELECT * FROM users WHERE id=2;📌 이제 id=2를 찾을 수 없음 → canceling statement due to conflict with recovery 오류 발생!
🔥 4️⃣ WAL이 Replica에서 튜플을 제거하는 과정 요약
| 단계 | Primary에서 수행된 작업 | WAL 기록 | Replica에서의 반응 |
|---|---|---|---|
| 1 | DELETE FROM users WHERE id=2; 실행 | WAL 기록 시작 | 아직 기존 튜플 존재 |
| 2 | 변경 사항을 WAL에 기록 | WAL에 id=2 삭제 내용 저장 | |
| 3 | WAL을 Replica로 전송 | ✅ 0/1638F20 LSN 업데이트 | |
| 4 | Replica에서 WAL 적용 시도 | WAL 리플레이 진행 | 기존 튜플 제거 |
| 5 | SELECT가 실행되면 충돌 발생 | 🚨 canceling statement due to conflict with recovery 오류 발생 |
📌 즉, WAL이 기록되면서 Replica에서 기존 튜플이 삭제되기 때문에, SELECT가 충돌하면서 오류가 발생할 수 있음.
🔥 5️⃣ 왜 WAL이 적용될 때 튜플이 제거되는가?
Replica는 WAL을 기준으로 데이터 변경을 적용하기 때문에, WAL이 삭제 정보를 포함하고 있다면 Replica에서는 즉시 해당 튜플이 접근할 수 없는 상태로 변경됨.
- Primary에서는 VACUUM이 실행될 때까지 Dead Tuple이 남아 있을 수 있음.
- 하지만, Replica에서는 WAL 적용 순간에 해당 데이터가 즉시 사라짐.
- 이 과정에서 SELECT가 오래 실행되고 있으면, 충돌이 발생하여
canceling statement due to conflict with recovery오류가 발생할 수 있음.
canceling statement due to conflict with recovery 오류의 원인
이 오류는 Aurora의 WAL(또는 Redo Log)이 Replica에서 적용될 때, SELECT 쿼리가 오래 실행되면서 충돌할 경우 발생한다.
✅ 오류 메시지
ERROR: canceling statement due to conflict with recovery
HINT: User query might have needed to see row versions that must be removed.📌 즉, Replica에서 실행 중인 쿼리가 삭제된 튜플(row versions)을 참조하려고 했으나, WAL이 적용되면서 해당 데이터가 삭제되어 더 이상 접근할 수 없게 된 상태에서 발생하는 오류다.
✅ 오류 발생 시나리오
| 시간 | Primary(Writer) 이벤트 | Replica(Reader) 이벤트 |
|---|---|---|
| 00:00:00 | DELETE FROM users WHERE id=2; 실행 | 아직 users 테이블에서 id=2를 조회 가능 |
| 00:00:01 | Primary에서 해당 삭제를 WAL에 기록 | SELECT * FROM users WHERE id=2; 실행 시작 |
| 00:00:02 | WAL이 Aurora Storage Layer에 저장됨 | |
| 00:00:03 | Replica가 WAL을 읽고 id=2를 삭제하려고 함 | 🚨 문제 발생: SELECT가 id=2를 참조 중! |
| 00:00:04 | WAL 적용을 위해 PostgreSQL이 SELECT를 강제 종료함 | 🚨 오류 발생: canceling statement due to conflict with recovery |
| 00:00:05 | SELECT가 강제 종료됨 | WAL 적용 완료, id=2가 Replica에서도 삭제됨 |
📌 즉, DELETE 후 WAL이 Replica에서 적용되는 타이밍과 SELECT 실행 타이밍이 겹치면 충돌이 발생하여 오류가 발생한다.
🫵🏻 Issue 설명과 해결 방법
canceling statement due to conflict with recovery 해결 방법
✅ 1️⃣ WAL 적용을 지연 (max_standby_streaming_delay) - 잘 설정 되어있음
ALTER SYSTEM SET max_standby_streaming_delay = '30s';
SELECT pg_reload_conf();📌 WAL 적용을 30초 동안 지연시켜 SELECT가 완료될 시간을 벌어줌.
📌 하지만 Aurora에서는 완전히 적용되지 않을 수도 있음.
✅ 2️⃣ Primary에서 WAL 보존 기간을 늘리기 (wal_keep_size) - 설정 되어있지 않음
ALTER SYSTEM SET wal_keep_size = '2048MB';
SELECT pg_reload_conf();📌 WAL을 일정 시간 동안 유지하여, Replica가 WAL을 급격히 적용하는 문제를 줄일 수 있음.
✅ 3️⃣ 긴 실행 시간의 SELECT 쿼리를 Primary에서 실행 - 느려질 수 있음
SET SESSION application_name = 'force_primary';📌 자주 변경되는 테이블이라면, SELECT를 Primary에서 실행하는 것이 더 안정적일 수 있음.
🚀 결론
🔥 canceling statement due to conflict with recovery 오류는 왜 발생하는가?
✅ DELETE / UPDATE / TRUNCATE 후 WAL이 Replica에 적용될 때, 동일한 데이터를 SELECT하고 있으면 충돌 발생!
✅ Aurora는 WAL을 직접 Primary에서 Replica로 "PUSH"하는 방식이 아니라, 공유 스토리지에서 직접 "PULL"하는 방식이므로 WAL 적용이 빠르게 이루어짐.
✅ SELECT가 오래 걸려서가 아니라, WAL 적용 타이밍과 SELECT 실행 타이밍이 겹칠 때 발생하는 오류다!