개발을 하다 보면, 아주 사소한 코드 하나가 전체 성능을 좌우하는 순간이 있습니다.
최근에 제가 딱 그런 경험을 했습니다.
배열을 순회하면서 단순히 값을 하나 더하는 코드였는데, 이게 너무 느린 겁니다.
처음엔 배열 크기가 문제인가 싶었고, 혹시 JVM 설정을 잘못했나 싶기도 했습니다.
하지만 원인은 아주 단순한 데 있었습니다.
바로 for문 순서.
정확히 말하면, 행을 먼저 순회하느냐, 열을 먼저 순회하느냐의 차이였는데 해당 이야기를 한번 해보려고 합니다.
자바에서 겪은 이상한 성능 이슈
열 우선 순회 (비효율적)
int size = 10240;
int[][] array = new int[size][size];
for (int j = 0; j < size; j++) {
for (int i = 0; i < size; i++) {
array[i][j]++;
}
}이 코드는 약 570ms가 걸렸습니다.
단순한 2중 반복인데도 성능이 이렇게 안 나오는 건 꽤 의외였습니다.
행 우선 순회 (효율적)
for (int i = 0; i < size; i++) {
for (int j = 0; j < size; j++) {
array[i][j]++;
}
}이 코드는 약 28ms밖에 걸리지 않았습니다. 거의 20배 가까이 빨라진 셈입니다.
왜 이렇게까지 차이 날까?
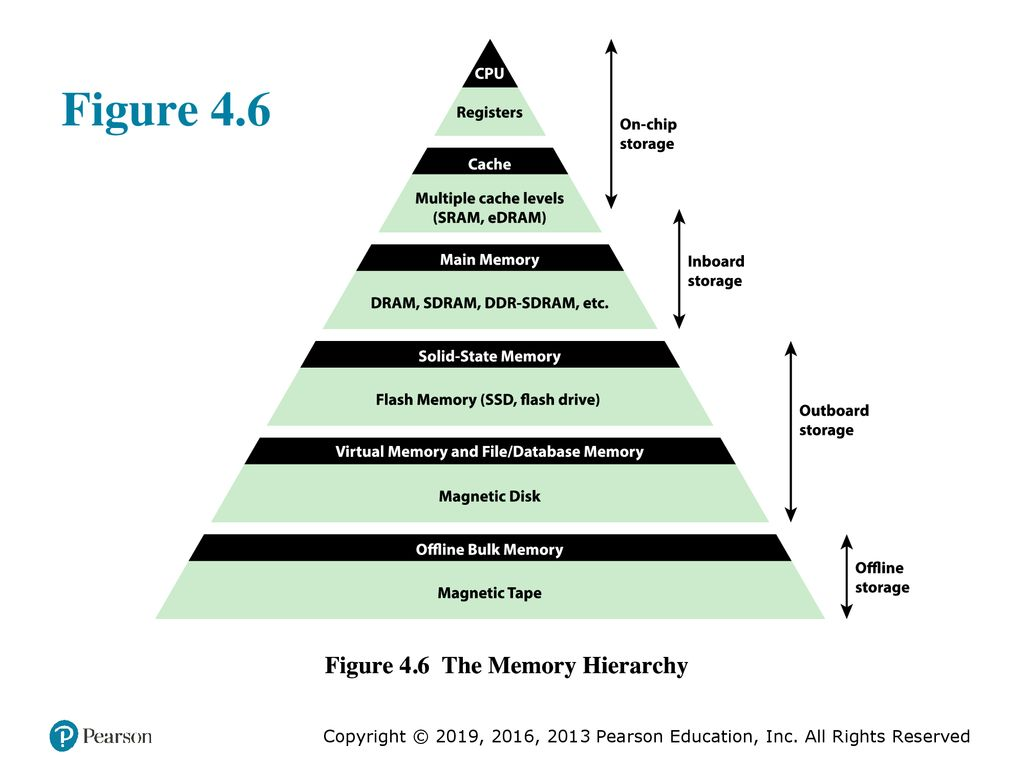
그 이유는 바로 CPU 캐시와 참조 지역성(Locality of Reference)이라는 개념에 있습니다.
요즘 CPU는 계산은 빠르지만, 메모리에서 데이터를 직접 읽는 건 느립니다.
그래서 그 중간 단계로 L1/L2/L3 캐시를 두고
자주 쓰거나 곧 쓸 것 같은 데이터를 미리 불러와서 보관합니다.
이때 어떤 데이터를 미리 캐시에 담을지를 결정하는 기준이 바로 참조 지역성입니다. 이 개념은 보통 아래 세 가지로 나뉘죠.
1. 시간 지역성 (Temporal Locality)
"방금 쓴 거, 곧 또 쓸 확률 높다"
int a = array[i][j];
int b = a + 10;
int c = a * 3;a를 여러 번 접근하니까 CPU는 이 데이터를 캐시에 오래 남겨두려 합니다.
예를 들어 요리할 때 자주 쓰는 소금은 계속 꺼내 쓰니까 굳이 찬장에 넣지 않고 싱크대 옆에 두는 거랑 비슷합니다.
2. 공간 지역성 (Spatial Locality)
"지금 쓴 거 주변도 곧 쓸 확률 높다"
for (int i = 0; i < 100; i++) {
sum += array[i];
}배열을 순서대로 접근하니, CPU는 한 번에 여러 개의 인접한 데이터를 캐시에 불러옵니다.
예를 들어 소금을 꺼냈다면, 후추도 꺼낼 가능성이 높죠. 조미료는 같이 넣어두는 이유입니다.
3. 순차 지역성 (Sequential Locality)
"앞으로도 순서대로 접근할 가능성이 높다"
for (int i = 0; i < array.length; i++) {
process(array[i]);
}패턴이 순차적일 때 CPU는 그 방향으로 데이터를 미리 준비합니다. 이것을 프리페치(prefetch)라고 하죠.
예를 들어 책을 읽고 있으면 다음 페이지를 미리 넘기기 쉽게 준비하는 것과 같습니다.
즉, CPU 입장에서 매우 예측 가능한 패턴이 되어 캐시를 효율적으로 사용할 수 있었던 것입니다.
이 개념을 Redis 키 설계에도 적용했습니다
이 개념을 이해하고 나니까, 자연스럽게 다른 영역에서도 생각이 확장됐습니다.
특히, Redis를 설계할 때 유사한 문제가 떠올랐습니다.
당시에 저는 Redis를 사용해서 사용자 알림 데이터를 저장하고 있었어요.
기존 키 구조:
notification:{userId}:{notificationId}단일 알림을 키로 관리하니,
- 개별 알림 접근은 빠르지만
- 유저의 전체 알림 조회 시에는 scan 또는 패턴 조회 필요
- 메모리 배치도 흩어지고, 성능에도 부담
개선한 키 구조:
user:notification:{userId} → Redis List or Sorted Set하나의 유저 알림을 단일 키로 묶고 리스트 형태로 저장.
효과는?
- 단일 키만 조회 → 빠른 응답
- 사용자별 키 구조로 명확한 접근 패턴
- Redis 내부 메모리 배치도 유저 기준으로 뭉침
- 결과적으로 hit ratio 증가, latency 감소
마치 자바에서 array[i][j]를 순서 있게 접근할 때와 같은 공간 지역성 효과를 Redis에서도 본 셈이었습니다.
그 이후로 생긴 습관
이 경험 이후로, 저는 어떤 구조를 설계하든 "이 데이터는 어떻게 접근될까?"를 먼저 고민합니다.
- 자바에서는 for문의 순서
- Redis에서는 키의 패턴과 집합성
이런 지역성을 고려하는 습관은 어디서든 성능 향상에 직결됩니다.
마무리하며
‘참조 지역성’은 단순히 컴퓨터 구조 이론이 아니라,
실제 실무에서 체감 가능한 성능 차이를 만드는 핵심 원리입니다.
배열 순회 하나에서 캐시를 고려하고, Redis 설계에서도 지역성을 고려하는 개발자.
결국, 좋은 서버보다 중요한 건 서버가 좋아하는 방식으로 데이터를 다루는 개발자라는 생각이 듭니다.
4개의 댓글

좋은 내용 공유 감사합니다! 너무 흥미롭게 잘 읽었습니다!
혹시 해당 내용 포스팅을 참고하여 제 블로그에 출처 남겨서 포스트를 작성해도 괜찮을까요?
이중 for문 항상 사용해왔지만 순서에 따라 성능 차이가 이렇게 날 줄은 몰랐네요. 연속된 수를 다룰 때 인간이 하는 사고방식이 프로그래밍에도 ‘지역성’이라는 개념으로 있는것도 신기합니다. 좋은 인사이트 감사합니다. ☺️