목표
- 타이타닉 데이터를 학습하고 생존자/사망자 예측을 해보자
- 머신러닝 전체 과정을 진행해보자
1. 문제정의
- 생존/사망을 예측해보자
2. 데이터 수집
#사용할 라이브러리 불러오기
import numpy as np (다차원 배열(ndarray)과 벡터화 연산을 지원합니다.)
import pandas as pd (표 형태의 데이터를 다루는 데 특화된 라이브러리입니다.)
import matplotlib.pylab as plt (기본적인 그래프를 그릴 수 있는 시각화 라이브러리입니다.)
import seaborn as sns (Matplotlib 기반의 고급 시각화 라이브러리입니다.)
#사용할 데이터 파일 가져오기
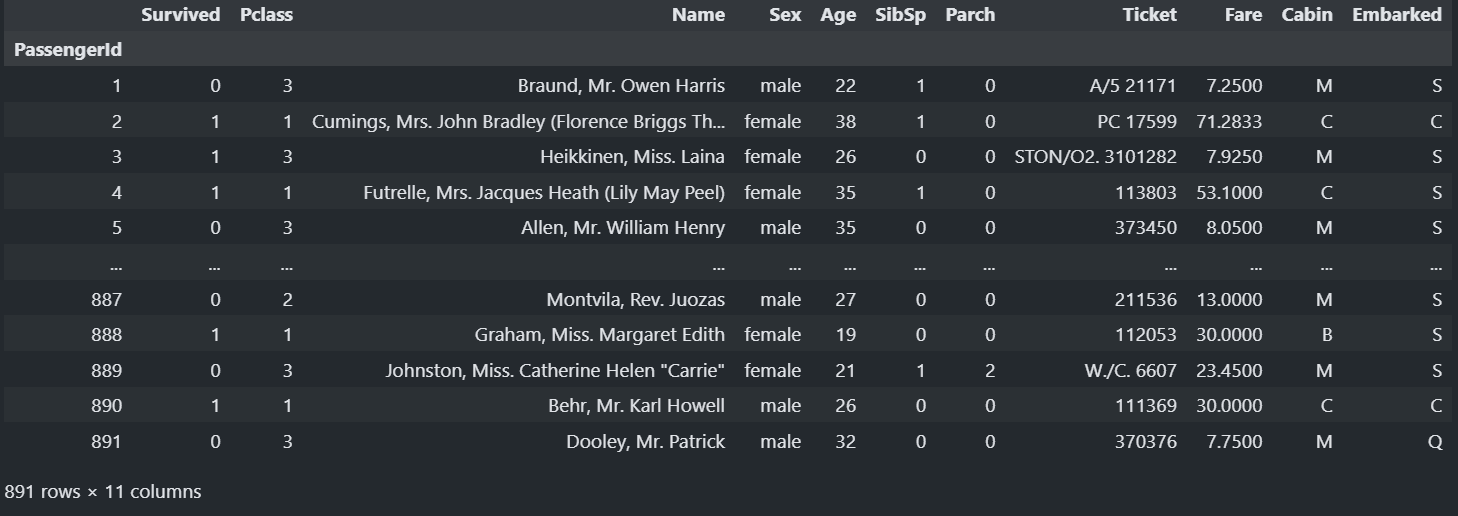
train = pd.read_csv("./data/train.csv",index_col="PassengerId") #index_col : 인덱스로 사용할 컬럼 지정
test = pd.read_csv("./data/test.csv",index_col="PassengerId")
train
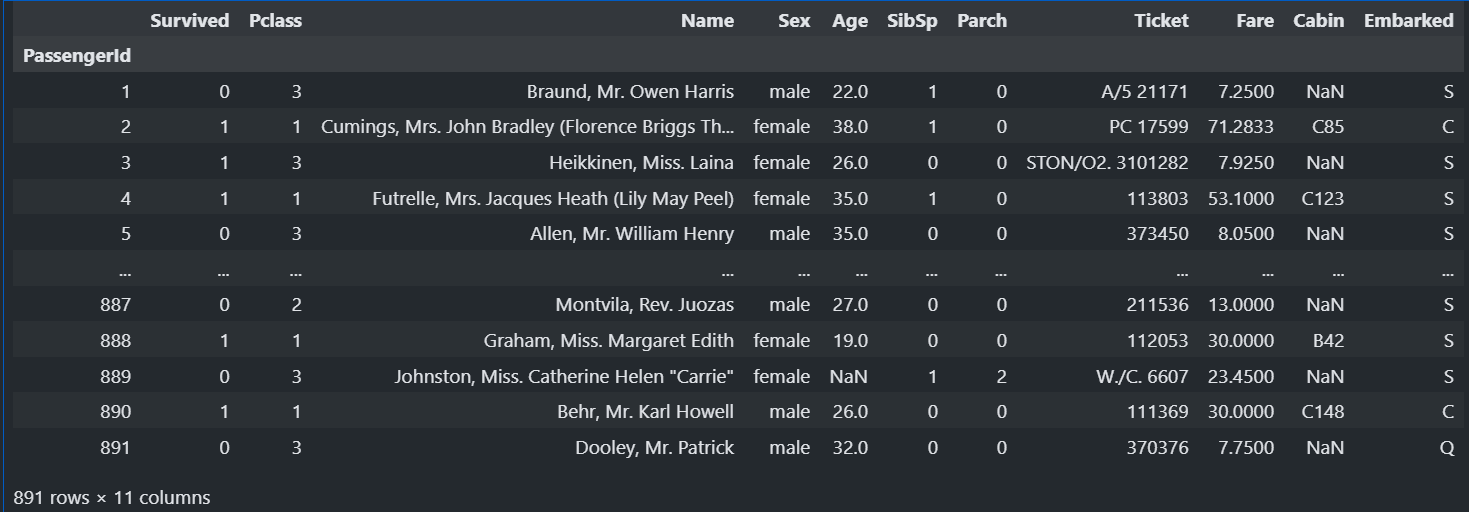
#train test 크기 확인
train.shape , test.shape
#train에는 생존여부 컬럼이 추가되어 있음.
3.데이터 전처리
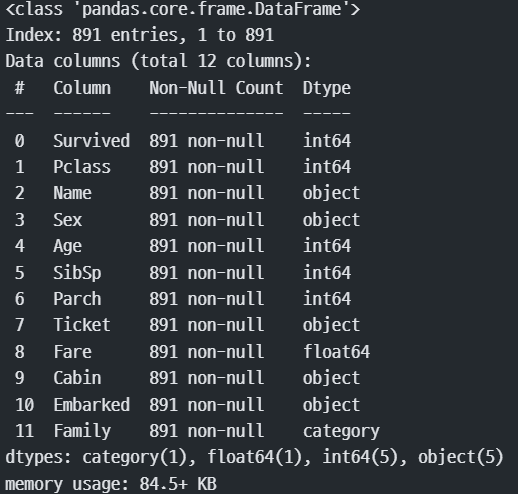
#데이터 정보 확인해야함
train.info() #정보 확인
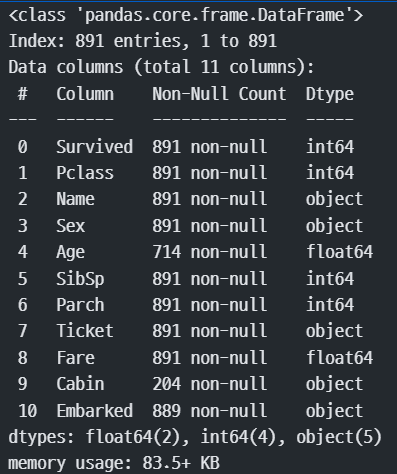
#결측치가 있는 컬럼 : Age, Cabin, Embarked
#데이터 타입 문자 -> 수치형으로 변환 필요 -> 인코딩(원핫, 레이블 인코딩)
#원핫 인코딩이란 범주형 데이터를 머신러닝 모델이 이해할 수 있도록 숫자로 바꾸는 방법 중 하나. 주어진 범주형 변수의 각 고유 값마다 하나의 컬럼을 만들어서, 해당 값에만 1을 주고 나머지는 0으로 채움.
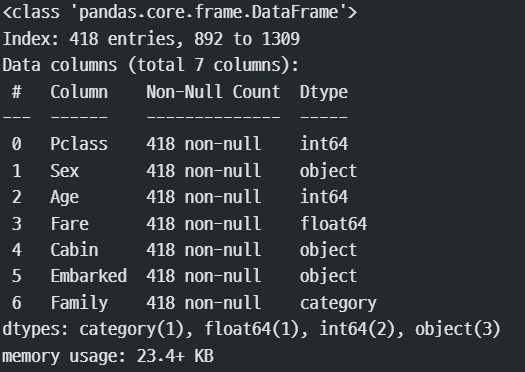
test.info()
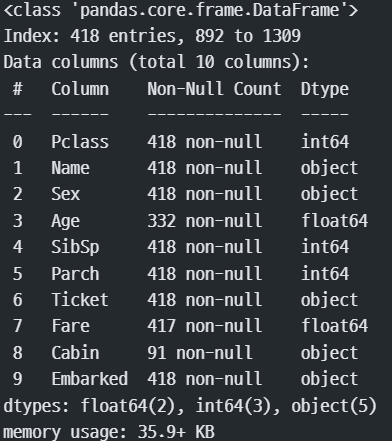
#결측치 : age, Fare, Cabin
#Survived : 생존/사망 데이터가 없음 -> 캐글이 알고 있다.
#캐글이란 데이터 과학과 머신러닝 관련 문제를 해결하는 온라인 플랫폼

결측치 채우기
- 결측치가 있는 행 전체를 삭제하는 방법
- 삭제하려는 데이터가 너무 많을때는 불가능, 모델링에 치명적이지 않은 데이터여야 가능
- 결측치를 다른 값으로 대체하는 방법
- 평균값, 최빈값, 중앙값 등이 있음
#결측치가 있는 컬럼 : Age, Cabin, Embarked
#train - Embarked 채우기
train['Embarked'].describe()
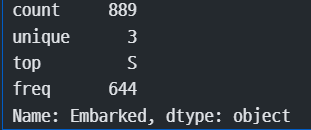
#Embarked : 승객이 탑승한 항구(port)를 나타내는 컬럼
train['Embarked'].valuecounts() #S가 가장 많이 탔다 !! - 최빈값으로 채워주자

train["Embarked"].isnull()
train[train["Embarked"].isnull()] # 불리언 인덱싱 방식으로 출력

#불리언 인덱싱이란 Pandas에서 특정 조건을 만족하는 데이터만 선택하거나 필터링할 때 사용하는 방법. 주어진 조건에 따라 True/False 값을 반환하는 불리언 배열을 이용하여 데이터를 선택함.
#비어있는 데이터를 채워주는 함수 : fillna()
train["Embarked"] = train["Embarked"].fillna("S")
train["Embarked"].isnull()
test-Fare 결측치 채우기
#상관관계 확인 : corr()
train.corr(numeric_only= True) #문자열로 된 컬럼 포함 X
# -1 ~ 1 값을 갖게 되는데 -1, 1에 가까울수록 상관 관계가 높다
# Pclass가 Fare와 상관 관계가 높다!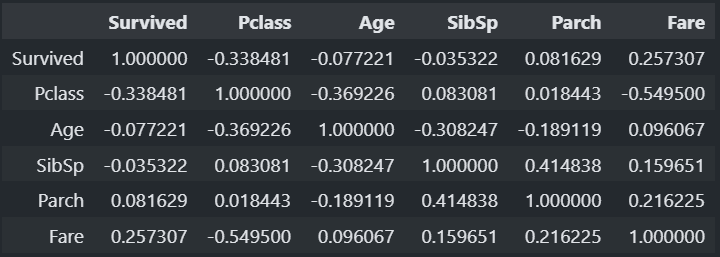
#기술통계랑 확인
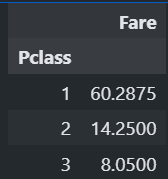
train["Fare"].describe() # 평균값이 의미가 없으 중앙값을 사용하자!
train[["Pclass","Fare"]].groupby(["Pclass"]).median()
#클래스별로 중앙값 출력해보면!
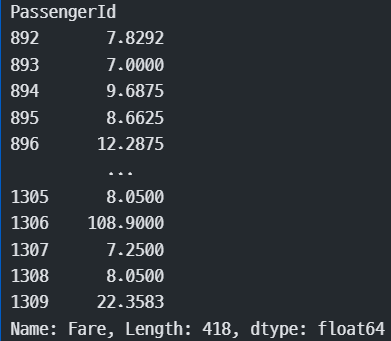
test[test["Fare"].isnull()] #Fare가 null인 데이터 확인!

#test에서 Fare가 null인 값을 채워주자
test["Fare"] = test["Fare"].fillna(8.05)
test["Fare"] #확인해보면!
Age 결측치 채우기
- train, test 모두 채우기
- 평균값, 최빈값, 중앙값 → 평균값으로 채워주자
- 다른 컬럼과의 상관관계를 보고 채워주자
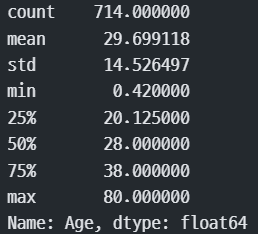
#기술통계량
train["Age"].describe()
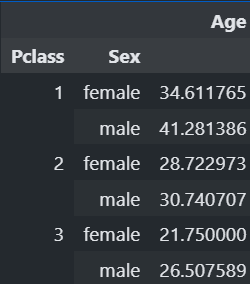
#Age 컬럼과 상관관계가 높은 컬럼은 Pclass 컬럼
train.corr(numericonly=True)

gb = train[["Pclass","Sex","Age"]].groupby(["Pclass","Sex"]).mean()
#gd에 넣어서 확인해보면!
gb
#다중인덱스(멀티인덱스, 중복인덱스)
gb.loc[(1,"female")]

#Age의 결측치를 채우기 위해서 pclass 와 Sex를 확인 후
#Age 평균값을 인덱싱해서 채워주자!!
#apply() → df에서 특정 컬럼에 접근해서 데이터 값 전부 함수처리
def fill_age(row) :
if np.isnan(row["Age"]) : # 결측치를 확인하는 함수 : np.isnan(대상)
return gb.loc[(row["Pclass"],row["Sex"])] # gb에 접근해서 반환할 값을 실어보냄
else : # 결측치가 아니라면
return row["Age"]
train["Age"] = train.apply(fill_age, axis=1) # train 데이터를 일일이 확인한 후 시리즈 생성
# train["Age"]를 교체train.info()
#.info로 확인
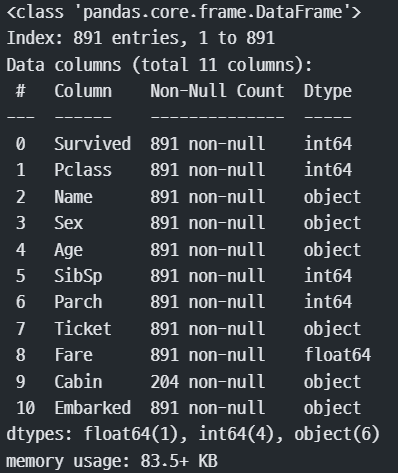
pd.DataFrame(train)
#멀티인덱스를 사용해서 데이터 타임이 object으로 바뀌어버림 -> 형변환이 필요!!
train["Age"]=train["Age"].astype(np.int64)
#test 데이터 Age 채우기
test["Age"] = test.apply(fill_age, axis=1)
test["Age"] = test["Age"].astype(np.int64)
Cabin 결측치 채우기
train.info()
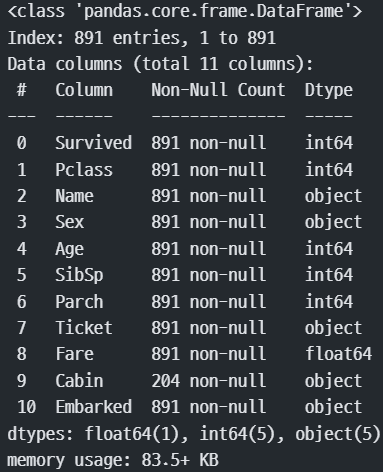
#cabin의 값을 중복없이 확인
train['Cabin'].unique()

#Cabin → 층 + 방번호
#결측치가 너무 많아서 채워주기는 어렵고 결측치라는 표시로 "M"으로 채울 것
train["Cabin"] = train['Cabin'].fillna('M')
test["Cabin"] = test['Cabin'].fillna('M')
#Cabin에서 첫번째 글자만 추출
train['Cabin'] = train['Cabin'].str[0]
test['Cabin'] = test['Cabin'].str[0]
train
test.info()
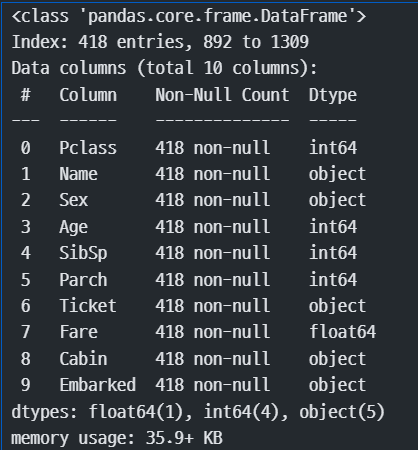
4. EDA
- 이상치를 판단해야 되는지 시각화로 확인
- 특성공학(feature Engineering) : 컬럼 삭제, 컬럼 추가(합계,평균)
train['Name'].head(5)
#Cabin 시각화
sns.countplot(data = train,
x = 'Cabin',
hue = 'Survived')
plt.show()
#Cabin이 결측치일 때 사망자 비율이 높으므로 예측 지표로 삼을 수 있음
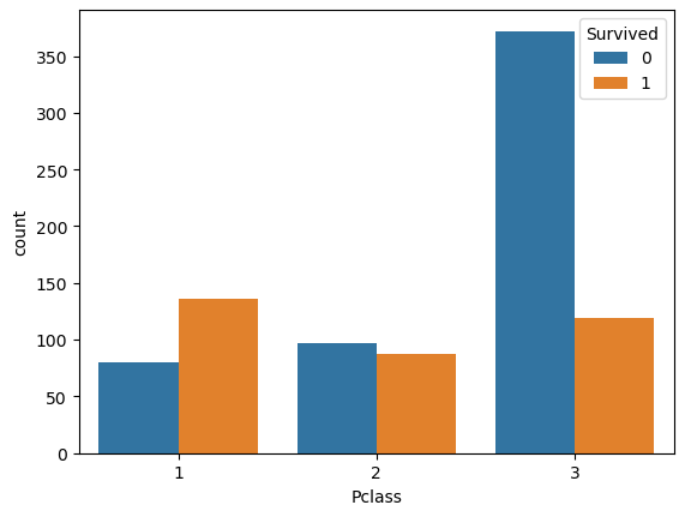
#Pcalss 시각화
sns.countplot(data = train,
x = 'Pclass',
hue = 'Survived')
plt.show()
#1등칸은 생존자 비율이 높고, 3등칸은 사망자 비율이 높다!
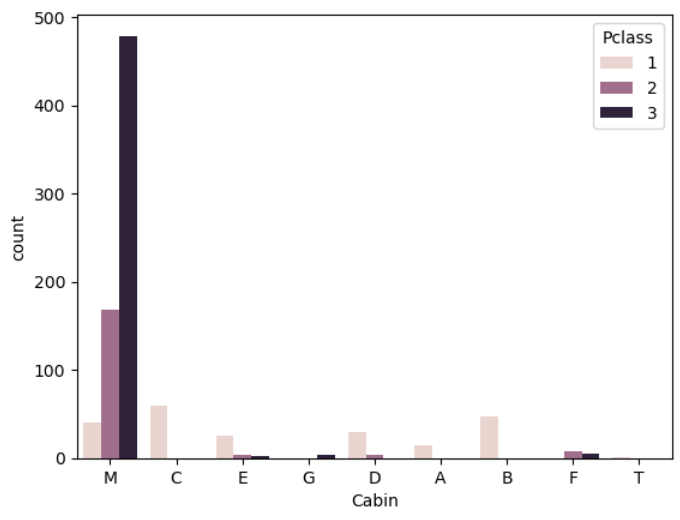
sns.countplot(data=train,
x='Cabin',
hue="Pclass")
plt.show()
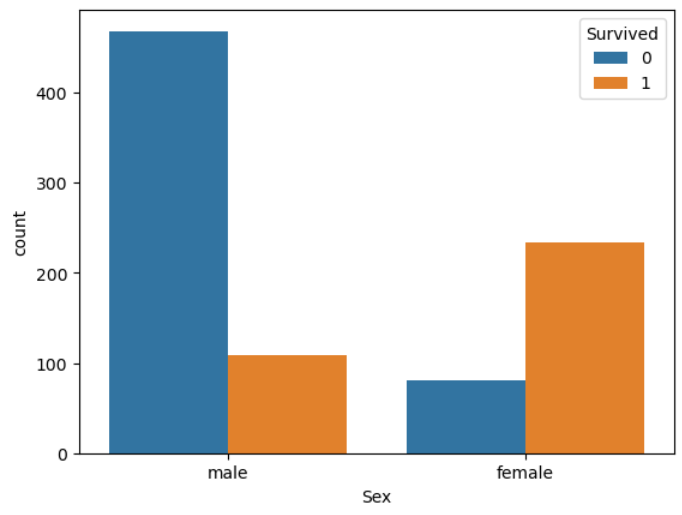
#성별 시각화
sns.countplot(data=train,
x='Sex',
hue='Survived')
plt.show()
#남성의 사망률이 높다! -> 3등칸이면서, 남성이면서, Cabin이 "M"인 경우 사망의 확률이 높다!!
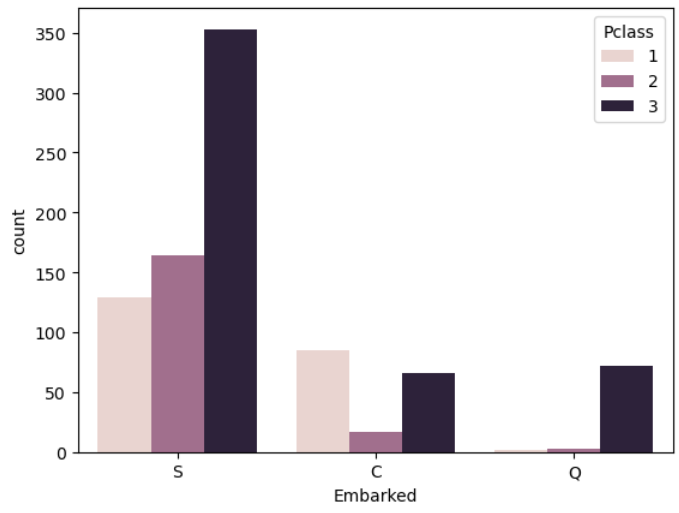
#승선상에 따른 생존여부 비율 확인
sns.countplot(data=train,
x= 'Embarked',
hue = 'Survived')
#S에서 탄 사람이 몇등칸에 탔는지 확인
sns.countplot(data=train,
x='Embarked',
hue='Pclass')
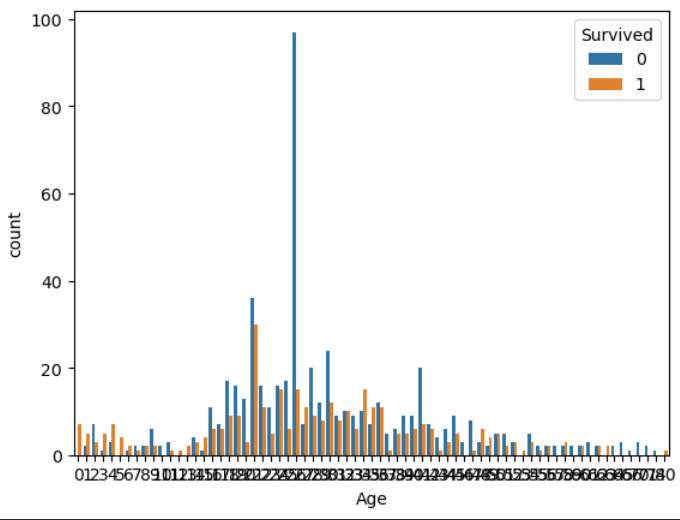
#나이 데이터 시각화
sns.countplot(data=train,
x='Age',
hue='Survived')
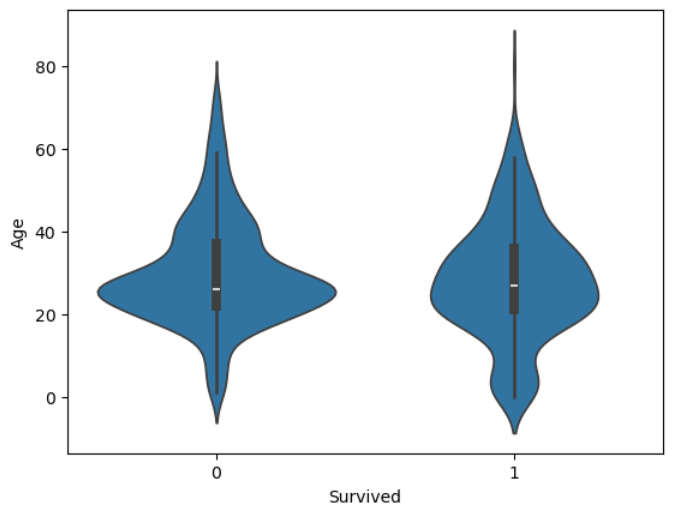
#바이올린 플랏 : 바이올린 형태로 데이터의 분포와 밀도를 곡선으로 표현한 그래프
sns.violinplot(data=train,
x='Survived',
y='Age')
#가오리 닮았음
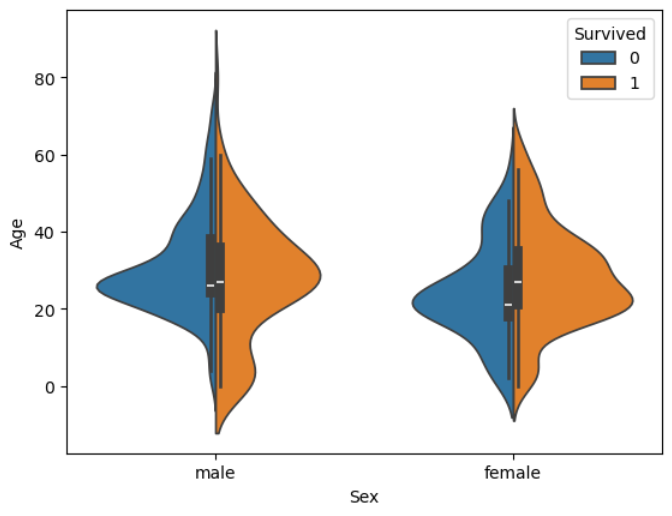
#바이올린 플랏 : 바이올린 형태로 데이터의 분포와 밀도를 곡선으로 표현한 그래프
sns.violinplot(data=train,
x='Sex',
hue='Survived',
y='Age',
split=True)
#어린아이중 남자아이가 유독 많이 생존함 -> 혈토을 유지하기 위한 남아선호사상 관념이 자리잡혀 있었음.
#변형가오리!
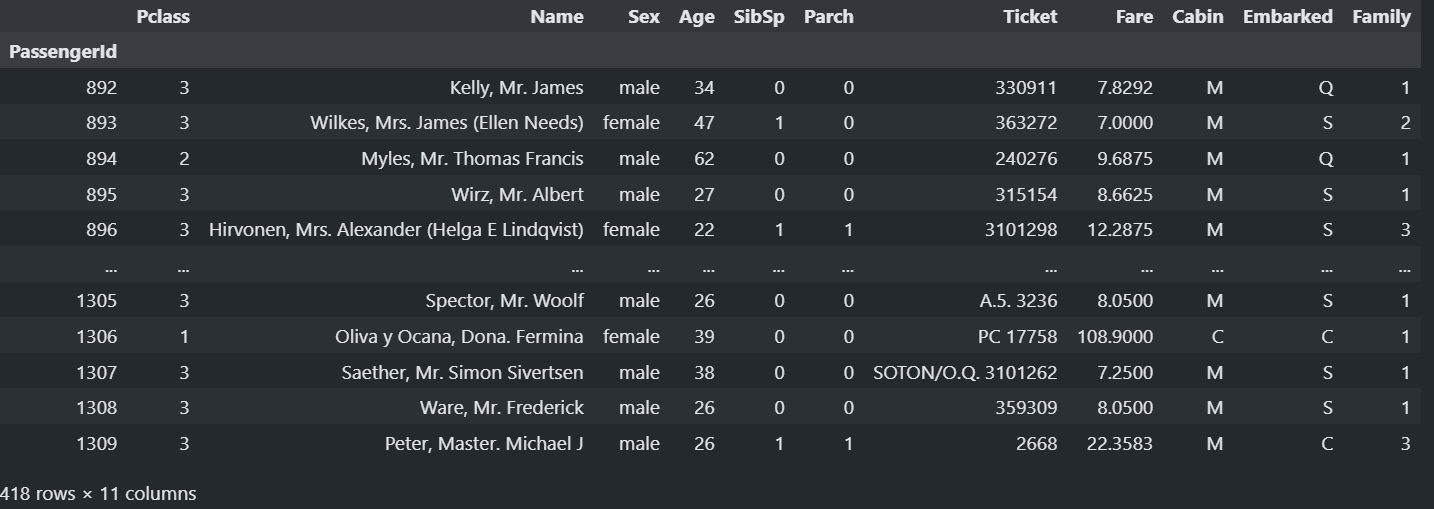
train #찍어보면!
특성공학
- 특성들을 파악하여 합치거나 나누었을 때 유의미한 결과를 내도록 변형
- Parch, sibsp 두 특성 합쳐서 Family라는 새로운 특성을 만들 수 있음
train['Family'] = train['SibSp'] + train['Parch'] + 1 #나 자신도 더해주자
test['Family'] = test['SibSp'] + test['Parch'] + 1
test #확인해보면!!!!

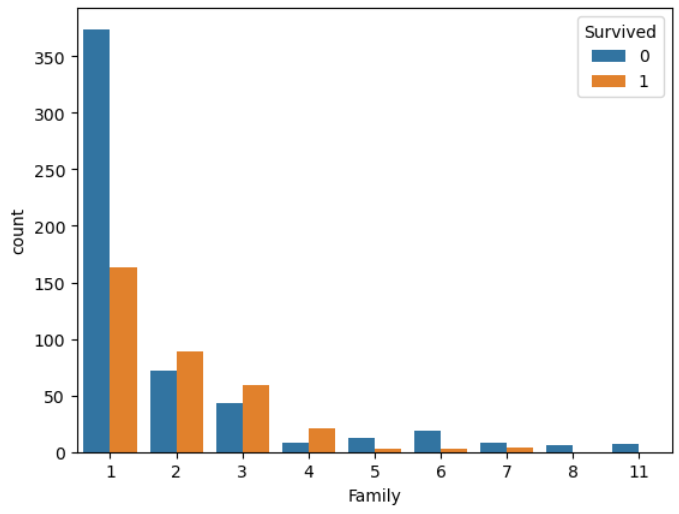
#가족원 수가 생존여부와 상관이 있는지 확인
sns.countplot(data=train,
x='Family',
hue='Survived')
#1명일 때 사망률이 높다.
#2~4일 때 생존율이 높다.
#5명 이상일 때 사망률이 높다.
#사소한 관찰의 오류 : 데이터가 편향되어 있어서 특징이 안보임. => 범주화(숫자 -> 문자형으로 변환)
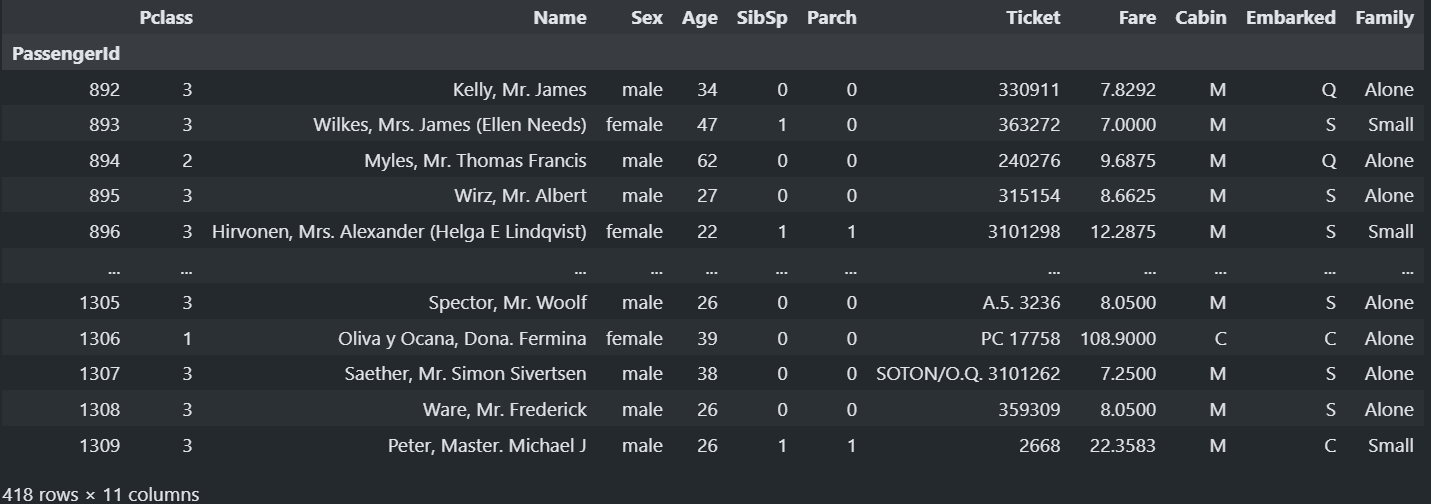
#카테고리화 진행
train['Family']=pd.cut(train['Family'], bins=[ 0, 1 , 4, 11], labels=['Alone','Small','Large']) # bins[ 앞의 값 초과, 뒤값 이하]
test['Family']=pd.cut(test['Family'], bins=[ 0, 1 , 4, 11], labels=['Alone','Small','Large'])
test
sns.countplot(data=train,
x='Family',
hue='Survived')
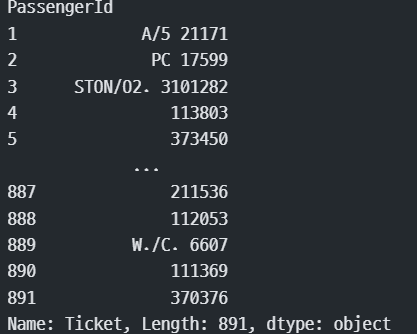
train['Name']
train['Ticket']
train.info()

#Name, SibSp, Parch, Ticket 삭제
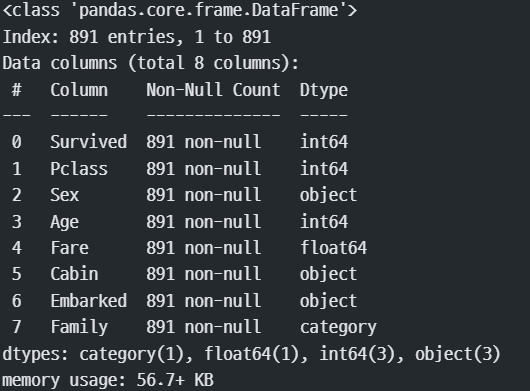
train.drop(['Name', 'SibSp', 'Parch', 'Ticket'],axis=1, inplace=True )
test.drop(['Name', 'SibSp', 'Parch', 'Ticket'],axis=1, inplace=True )
train.info()
test.info()

#X,y 분리
ytrain= train['Survived']
X_train= train.drop('Survived',axis=1)
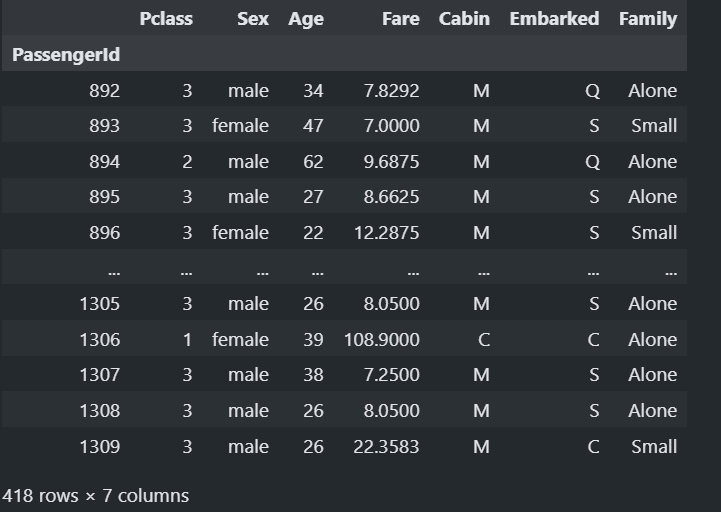
X_test = test
X_test

#문자형 데이터를 수치형으로 인코딩!(원핫인코딩 -getdummies)
X_train = pd.get_dummies(X_train)
X_test = pd.get_dummies(X_test)
X_train.shape , X_test.shape # 원핫인코딩 후 컬럼 개수의 차이가 발생

#Xtrain 에는 있고, X_test에는 없는 컬럼 찾기
#집합자료형 {}
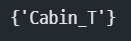
set(X_train.columns) - set(X_test.columns) # 'Cabin_T' 는 train에만 있는 특성

#불리언 인덱싱으로 CabinT가 True인 데이터 확인
X_train[X_train['Cabin_T']==1]

#이런식으로 나옴
#test에 Cabin_T 컬럼을 추가
X_test['Cabin_T'] = 0
Xtest.info()

#X_train 의 컬럼 순서 변경
#임의의 변수에 CabinT를 담아두자
temp = X_train['Cabin_T']
temp

#CabinT 삭제
X_train.drop('Cabin_T', axis=1,inplace=True)
X_train.info()

#다시 Xtrain과 temp를 병합
X_train = pd.concat([X_train, temp], axis=1)
X_train

set(X_train.columns) - set(X_test.columns)
set() -> 출력됨
5. 모델 선택
- KNN, DT, randomForest, Logistic Regression
knn 모델
from sklearn.neighbors import KNeighborsClassifier
#객체생성
knn = KNeighborsClassifier()
6. 학습
knn.fit(Xtrain, y_train)

7. 학습 및 평가
knn.score(Xtrain, y_train)

#결과값 나옴
#예측
pre = knn.predict(X_test) # 정답데이터는 캐글에..
pre #출력해보면

result = pd.readcsv("./data/gender_submission.csv")
result

result['Survived'] = pre # knn이 예측한 답으로 교체
#csv파일로 내보내기
result.to_csv("./data/gender_submission_knn.csv",index=False)
###혼자해보기
#DT
from sklearn.tree import DecisionTreeClassifier
#객체 생성
dt = DecisionTreeClassifier(random_state=42)
#학습
dt.fit(Xtrain, y_train)

#예측
dtpredictions = dt.predict(X_test)
dt_predictions

#결과 저장
result['Survived'] = dt_predictions
result.to_csv('./data/gender_submission_dt.csv', index=False)
#랜덤포레스트
from sklearn.ensemble import RandomForestClassifier
#객체 생성
rf = RandomForestClassifier(random_state=42)
#학습
rf.fit(X_train, y_train)
#예측
rf_predictions = rf.predict(X_test)
#결과 저장
result['Survived'] = rf_predictions
result.to_csv('./data/gender_submission_rf.csv', index=False)
#LogisticRegression
from sklearn.linear_model import LogisticRegression
#객체 생성
lr = LogisticRegression(random_state=42, max_iter=1000)
#학습
lr.fit(X_train, y_train)
#예측
lr_predictions = lr.predict(X_test)
lr_predictions
#결과 저장
result['Survived'] = lr_predictions
result.to_csv('./data/gender_submission_lr.csv', index=False)
마무리를 하며 너무 어려워요..!
