3.9 Heterogeneous Data Structures (이기종 데이터 구조)
구조체(struct)
서로 다른 타입의 변수들을 하나로 묶어 저장
메모리에 연속적으로 저장되며, 각 필드는 고정된 오프셋(offset)을 가진다.
하나의 구조체 내의 서로 다른 컴포넌트들은 이름을 이용해서 참조된다. 구조체의 포인터가 첫 번째 바이트의 주소이다. 이 점은 배열과 유사하다.
struct rec{
int i;
int j;
int a[2];
int *p;
};위와 같은 구조체가 선언되었다면 네 개의 필드를 가지고 총 24바이트의 크기이다.
| 0-3 | 4-7 | 7-11 | 12-15 | 16-19 | 20-23 |
|---|---|---|---|---|---|
| i | j | a[0] | a[1] | p | p |
이렇게 연속된 공간에 위치하기 때문에 각 필드에 접근하기 위해서는 오프셋 값을 더해주면 된다.
만약, j 필드에 접근하기 위해서는 ‘구조체 rec의 주소’에서 ‘필드 j의 오프셋 4’만큼 이동한다.
공용체(union)
여러 필드가 동일한 메모리 공간을 공유하고 가장 큰 필드의 크기만큼 메모리를 차지한다.
하나의 객체가 다수의 자료형에 따라 참조될 수 있도록 해준다.
공용체는 여러 가지 측면에서 유용할 수 있지만, C언어의 자료형 체제에서 제공하는 안전망을 패하가기 때문에 오히려 치명적인 버그를 발생시킬 수도 있다. 서로 다른 두 개의 필드를 상호 배타적으로 사용한다는 점을 미리 알고 있는 경우 유용하게 사용할 수 있다.
예를 들면, 각 leaf 노드는 값을 가지고 내부 노드는 값 없이 자식 노드의 포인터만 가질 때 유용하게 사용할 수 있다.
구조체를 사용한다면 총 8 + 8 + 8*2 = 32 byte 크기를 가진다.
struct node_s{
struct node_s *left;
struct node_s *right;
double data[2];
};공용체를 사용한다면 총 8 + 8 or 8*2 = 16 byte 크기를 가진다.
union node_u{
struct {
union node_u *left;
union node_u *right;
} internal;
double data[2];
};데이터 정렬(alignment)
CPU가 구조체나 변수의 데이터에 더 빠르게 접근하는 것을 목적으로 하는 메모리 배치의 규칙
많은 컴퓨터 시스템들은 기본 자료형들에 대해 사용 가능한 주소를 제한하고 있어서 어떤 객체의 주소는 어떤 값 K(일반적으로 2, 4, 8)의 배수가 되도록 요구한다.
컴퓨터의 CPU는 특정 바이트 크기 단위로 메모리를 읽고 쓰기 때문이다. 이때, 데이터가 자신의 크기만큼 정렬된 주소에 놓이면 그 단위로 읽고 쓰기 때문에 성능이 향상된다.
만약 해당 크기 단위로 데이터가 저장되지 않았다면 한 번만 읽어도 될 것을 두 번 읽게 된다. 따라서 컴퓨터는 메모리에서 데이터를 읽을 때 일정한 단위에 맞춰 읽는 게 훨씬 빠르고 안정적이다.
| 타입 | 크기 (바이트) | 정렬 기준 (바이트) |
|---|---|---|
| char | 1 | 1 |
| short | 2 | 2 |
| int | 4 | 4 |
| float | 4 | 4 |
| long, double, 포인터 | 8 | 8 |
padding
매 데이터가 같은 단위일 수는 없다. 그래서 딱 맞아떨어지지 않는다면 크기에 맞춰 확장하고 그만큼의 패딩을 삽입한다.
struct S1{
char c;
int i;
}위의 예시에서 c는 1byte, i는 4byte다.
우리는 단순히 c는 0번 오프셋, i는 0+1 오프셋에 저장된다고 생각하지만, 이 데이터 정렬 방법에 따라 i는 4번 오프셋에 저장된다.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| c | padding | padding | padding | i | i | i | i |
순서를 바꾸면 크기는 동일하지만 패딩의 위치가 달라진다.
struct S2{
int i;
char c;
}| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| i | i | i | i | c | padding | padding | padding |
어랏.. 왜 끝에도 패딩이 추가될까? 이는 구조체의 크기도 4의 배수로 맞춰줘야 하기 때문이다.
그래서 변수의 순서를 바꿨을 때, 총 크기는 같지만 패딩 위치가 달라진다.
데이터 정렬 규칙, 큰 순서대로!
근데 C언어에서는 자료형의 크기가 큰 순서대로 배치하라고 한다. 어차피 차지하는 공간은 같은데 왜일까?
-
중간에 패딩이 있으면 CPU가 데이터를 읽다가 끊긴다.
-
메모리 절약이 되는 경우가 있다.
struct S3{ char a; int i; char b; char c; char d; }이렇게 배치되었을 때 메모리의 크기는
1 + 3(padding) + 4 + 1 + 3(padding) … = 20 bytes 이다.
하지만 규칙대로 큰 자료형을 앞에 배치하면 확실히 절약된다.
struct S4{ int i; char a; char b; char c; char d; }4 + 1 + 1 + 1 + 1 8 = bytes이다.
3.10 Combining Control and Data in Machine-Level Programs
버퍼 오버플로우
배열 같은 메모리 공간에 허용된 크기보다 많은 데이터를 써서 인접한 메모리를 덮어쓰는 것이며 악의적인 목적으로 특정 메모리에 덮어쓰게끔 유도하기도 한다.
함수가 호출되면 다음과 같이 스택에 프레임이 만들어진다.
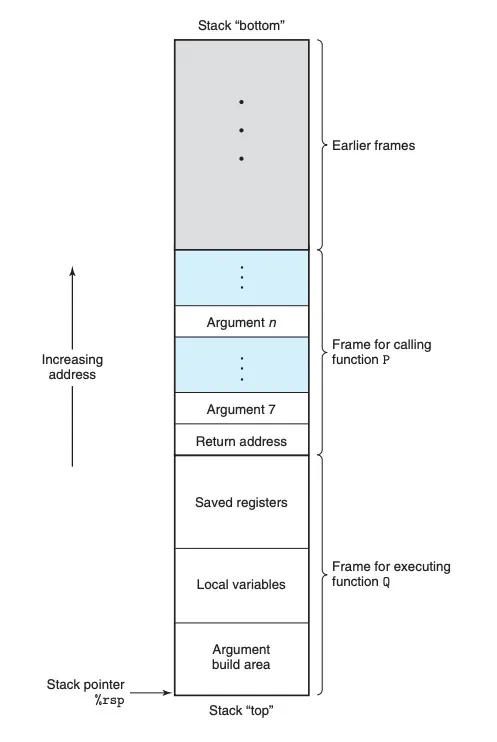
Return address가 위쪽에 위치해 있다. 그리고 함수 내에서 사용되는 변수 등의 데이터는 낮은 주소부터 쌓인다. 버퍼 오버플로우는 이렇게 낮은 주소부터 쌓이는 데이터가 허용된 버퍼보다 커서 Return Address까지 침범하는 경우 발생한다.
이런 함수를 실행한다고 하자
void func() {
char buf[8]; // 8바이트짜리 배열
}buf는 스택 프레임의 아래쪽(낮은 주소)에 위치한다. 만약에 buf에 할당된 크기 보다 더 큰 크기의 값을 넣는다면 버퍼에서 흘러넘쳐 Return Address까지 덮어쓰게 된다.
[ 공격 과정 ]
void func() {
char buf[8];
gets(buf); // ⚠️ 위험한 함수
}함수 gets()는 입력 길이를 제한하지 않기 때문에, 사용자가 100바이트를 입력해도 buf를 넘어서 스택의 위쪽까지 데이터를 쓰게 된다.
이 때, 입력 값에 악의적인 쉘 코드를 추가하여 리턴 주소의 위치까지 침범한다면 위험하다. 리턴 주소의 저장된 값이 손상된다면 ret 인스트럭션은 프로그램을 전혀 예상하지 못한 곳으로 점프하게 한다.
버퍼 오버플로 대응 방법
-
스택 랜덤화
프로그램이 실행될 때마다 스택, 힙, 라이브러리의 시작 주소를 무작위로 배치하여, 공격자가 정확한 메모리 주소를 추측하기 어렵게 만든다.
공격자는 악성 코드를 삽입하고 이를 실행시키기 위해, 정확한 메모리 주소(특히 스택 주소)를 알아야 한다. 하지만 프로그램의 스택 주소는 쉽게 예측할 수 있는 구조이다.
스택 랜덤화 방법을 사용하면 공격자가 악성 코드를 삽입하더라도 정확한 주소를 알 수 없기 때문에 실행 성공 확률이 낮아진다.
-
스택 손상 검출
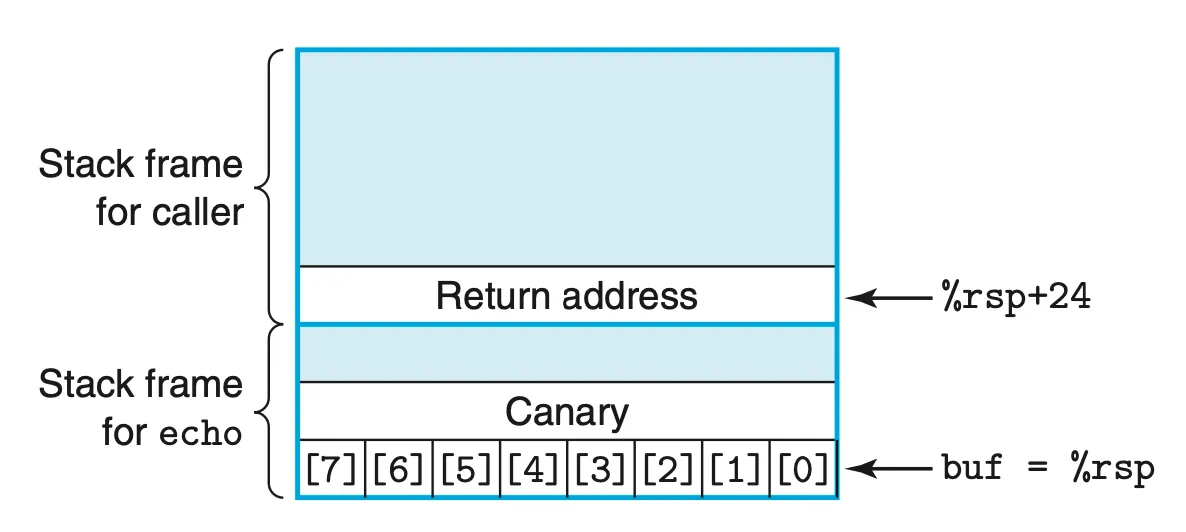
스택이 손상되는 것을 감지하여 손상이 되었을 때 프로그램을 종료시키는 방법이다.
Canary(
까나리..)는 리턴 주소와 지역 변수 사이에 배치되는 특별한 값으로, 함수 종료 시 이 값이 변했는지를 검사해 스택이 손상되었는지 판단한다. -
실행코드 영역 제한
스택이나 힙 같은 메모리 영역을 실행 불가능(Non-Executable)으로 설정하여, 악성 코드가 실행되지 않도록 막는 방식이다. 이를 NX bit(Non-eXecutable bit) 또는 DEP(Data Execution Prevention)라고도 한다.

가독성이 좋네요.