우선순위 역전
요구사항
https://casys-kaist.github.io/pintos-kaist/project1/priority_scheduling.html
우선순위 스케줄링의 한 가지 문제는 "우선순위 역전"입니다.
높은 우선순위, 중간 우선순위, 낮은 우선순위 스레드 H , M , L을 각각 고려해 보겠습니다. H 가 L 을 기다려야 하고 (예: L 이 보유한 잠금 ), M이 준비 목록에 있는 경우, 낮은 우선순위 스레드는 CPU 시간을 확보하지 못하므로 H는 CPU를 결코 확보하지 못합니다.
이 문제에 대한 부분적인 해결책은 L 이 잠금을 보유한 동안 H 가 L 에 우선순위를 "기부"한 후, L이 잠금을 해제하면(즉, H가 잠금을 획득하면) 기부한 우선순위를 회수하는 것입니다.
우선순위 기부를 구현하세요. 우선순위 기부가 필요한 모든 상황을 고려해야 합니다. 여러 우선순위가 단일 스레드에 기부되는 다중 기부를 처리해야 합니다. 중첩된 기부도 처리해야 합니다. H 가 M이 보유한 잠금을 기다리고 있고 M이 L 이 보유한 잠금을 기다리고 있는 경우, M 과 L 모두 H 의 우선순위 로 승격되어야 합니다 . 필요한 경우 중첩된 우선순위 기부의 깊이에 합리적인 제한(예: 8단계)을 적용할 수 있습니다.
잠금에 대해서는 우선순위 제공을 구현해야 합니다. 다른 Pintos 동기화 구성 요소에 대해서는 우선순위 제공을 구현할 필요가 없습니다. 모든 경우에 우선순위 스케줄링을 구현해야 합니다.
요구사항만 읽어도 어지럽다.
어지럽지만, 이를 완벽하게 이해하는 것이 중요하다.
요구사항을 완전히 알게 되면, 어떤 것들 고려해야 하고, 어떤 로직이 추가되어야 하는 지 알 수 있다.
그러니 잘 이해해보자!
이번 요구사항은 두 가지를 고려해야 한다.
1. 단일 스레드에 다중 기부
2. 중첩된 기부
도대체 뭔말이지?
multiple donations 다중기부
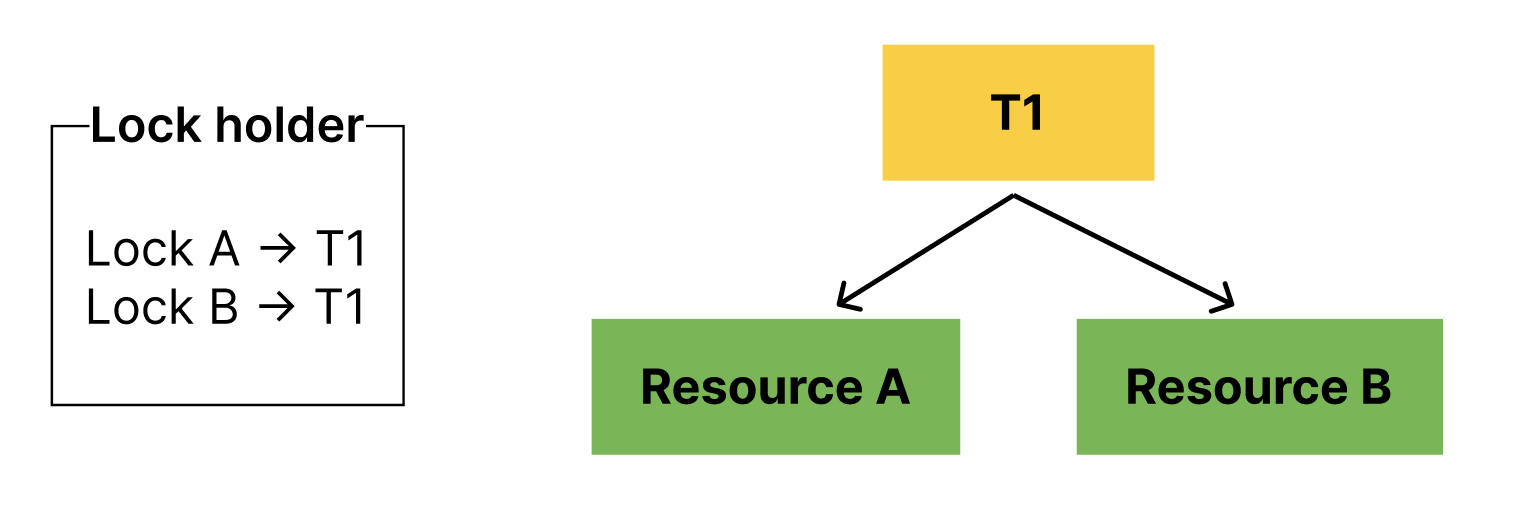
스레드는 여러 공유 자원에 접근할 수 있다.
이 말은 즉, 스레드는 여러 개의 lock을 획득할 수도 있다.
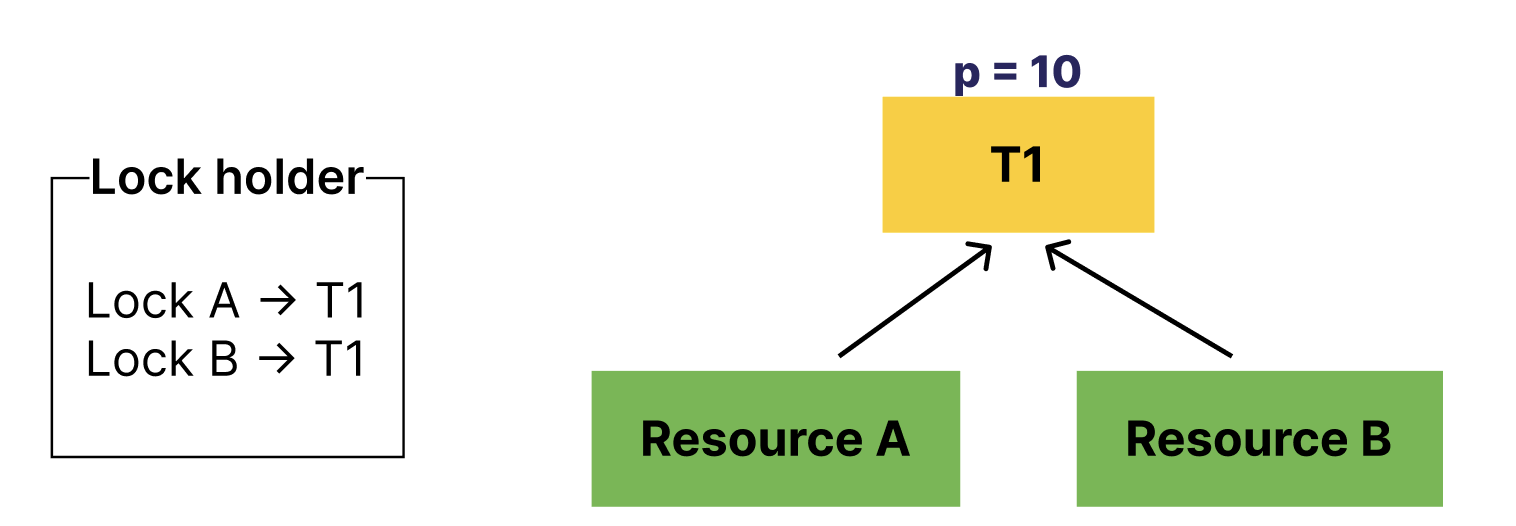
이 상황에서 resource A, resource B를 기다리는 스레드가 등장하면 어떻게 될까?
이렇게 되면 T2, T3은 본인보다 우선순위가 낮은 T1을 기다리는 상황이 발생한다.
정상적으로 우선순위 스케줄링이 이루어진다면,
T3이 먼저 수행되어야 하며 T2, T1 순서로 스케줄링 되어야 한다.
그래서 T2, T3는 T1에게 우선순위를 기부해주어야 한다.
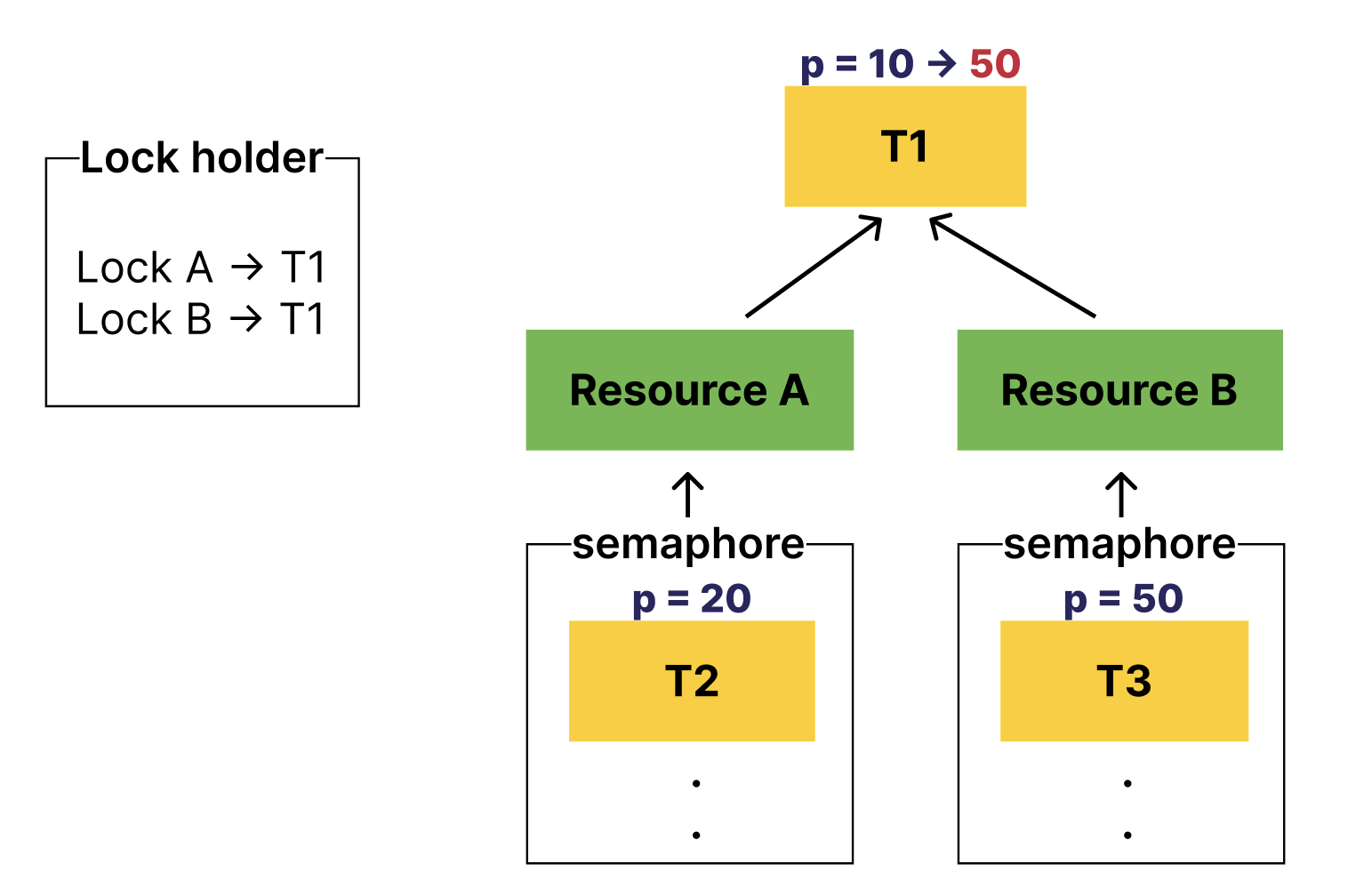
그렇다면 이 상황에서 Lock B를 release해주면 어떻게 될까?
기부받았던 T3의 우선순위를 반환해야할 것이고,
T1은 우선순위를 재산정하여 T2의 우선순위를 또다시 기부받게 될 것이다.
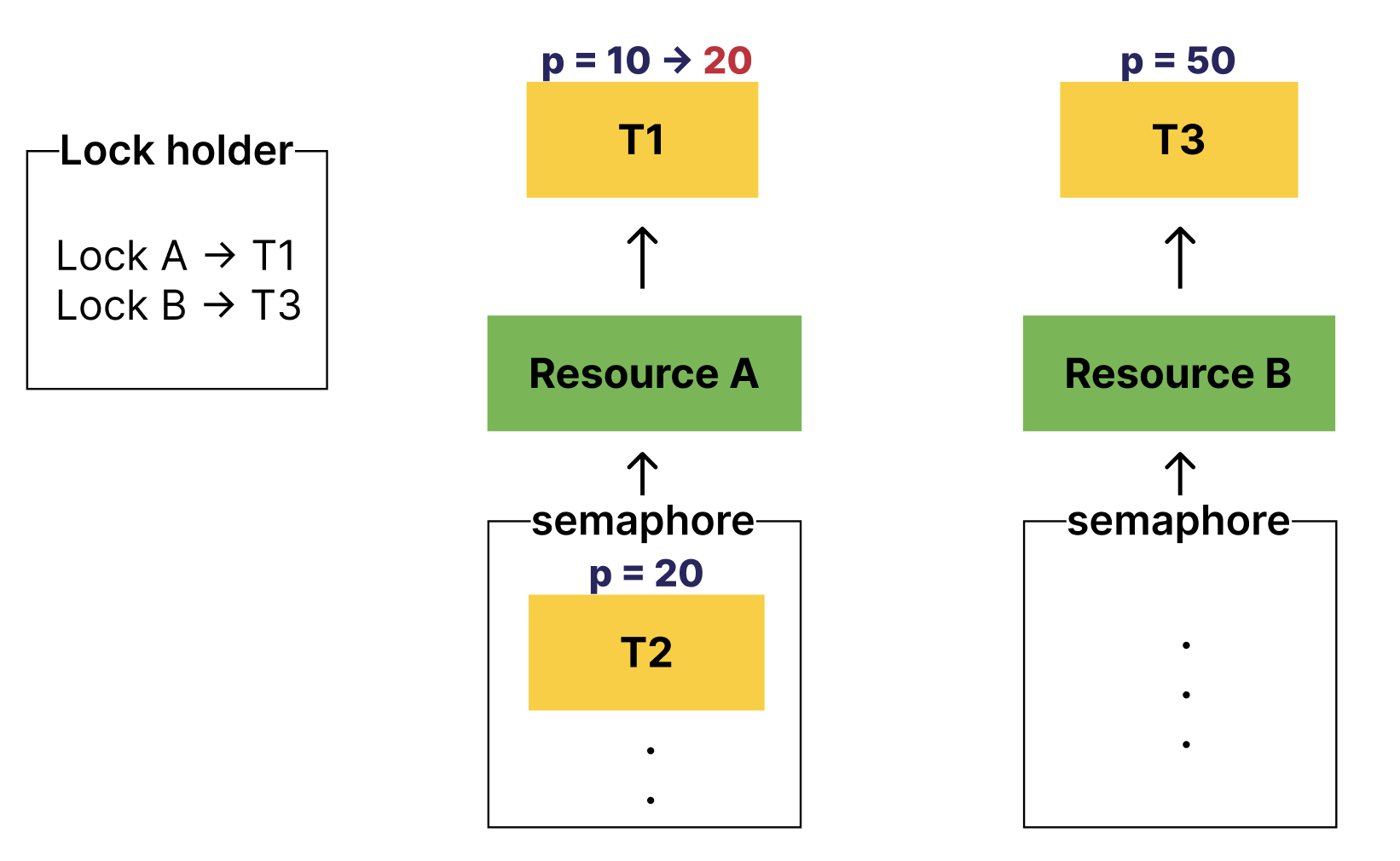
이렇게 말이다.
또 Lock A를 release하게 되면 T1의 우선순위는 원래 본인의 우선순위인 10으로 바뀌겠지?
여기까지 보면 두 가지 아이디어를 떠올릴 수 있다.
1. 원래의 priority를 기억해야한다.
2. T1에게 기부한 스레드(T2, T3)를 알아야 한다. → release 시점에서 재산정을 해야하기에
오케이 그러면 다음 nested donation도 이해해보자.
nested donation 중첩된 기부
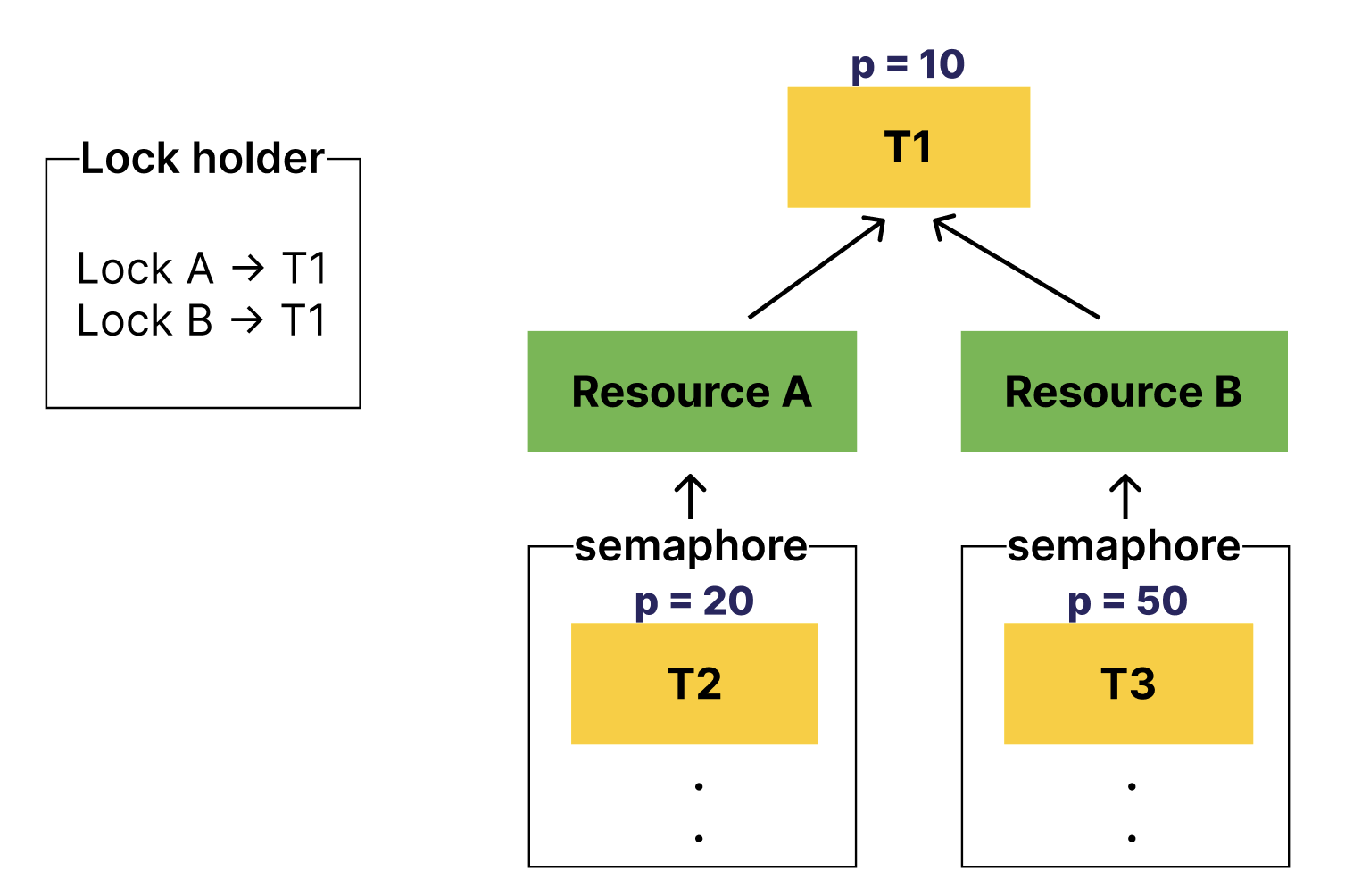
어떤 스레드는 A 자원의 release를 기다리면서도, B 자원의 lock을 가지고 있을 수 있다.
그 B 자원을 기다리는 스레드는 당연히 존재할 수 있다.
이렇게 꼬리에 꼬리를 물고 공유 자원의 release를 기다리는 상황, 그리고 우선순위가 역전되는 상황에서 nested donation을 고려해야 한다.
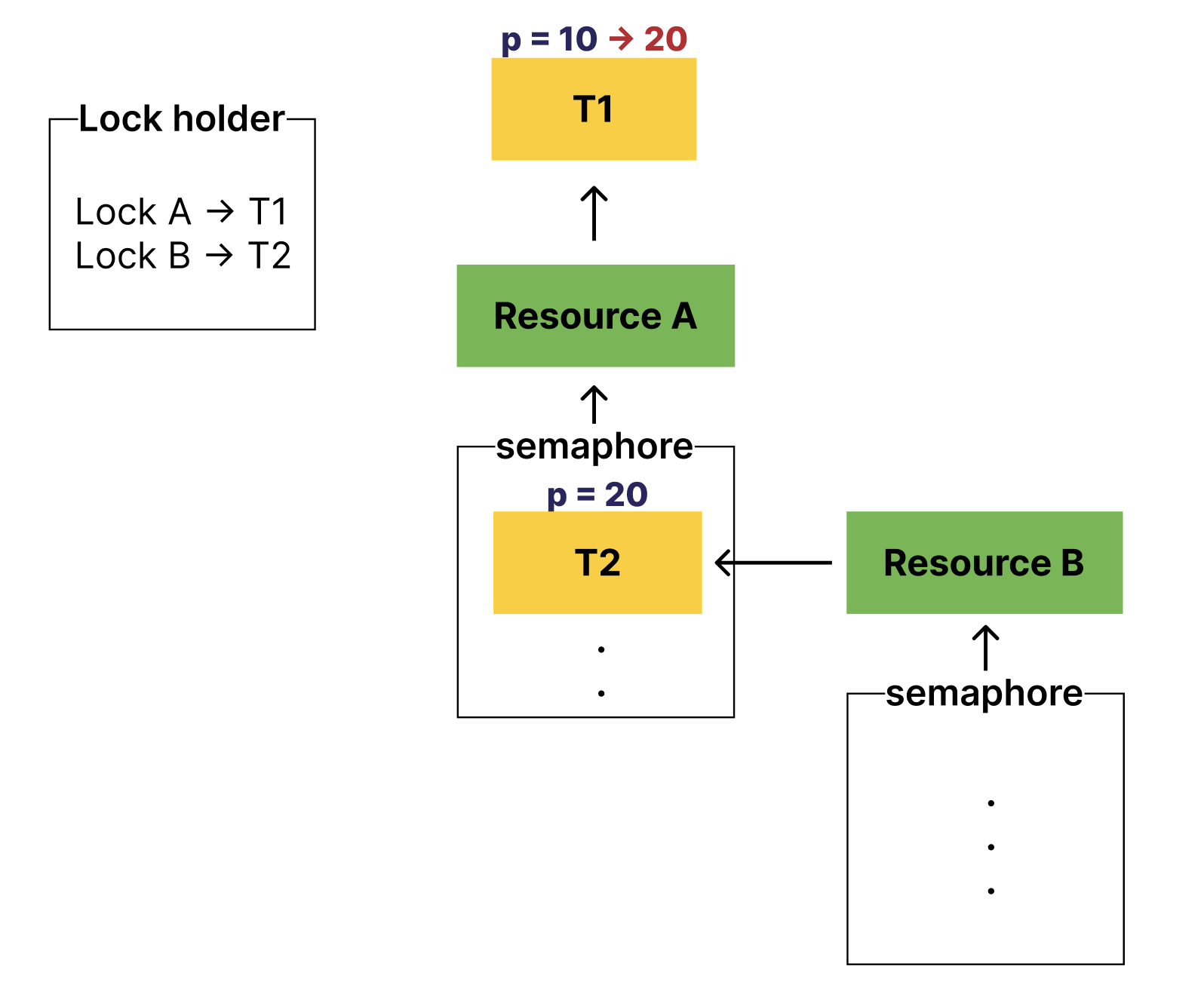
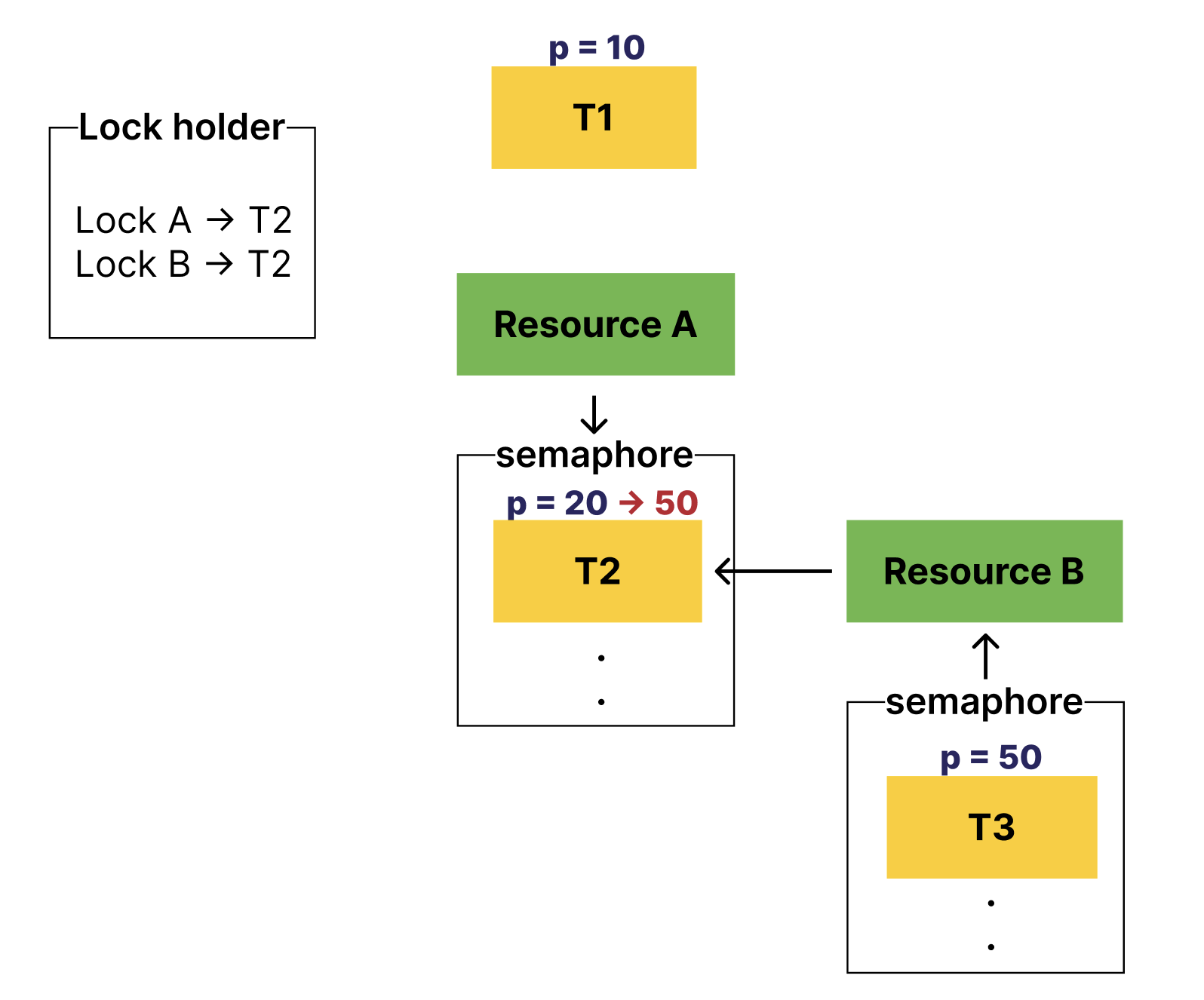
위의 상황에서 T1은 T2의 우선순위를 기부받는다.
이 때, resource B를 기다리는 스레드가 추가되는 상황이 충분히 생길 수 있다.
아래처럼 말이다.
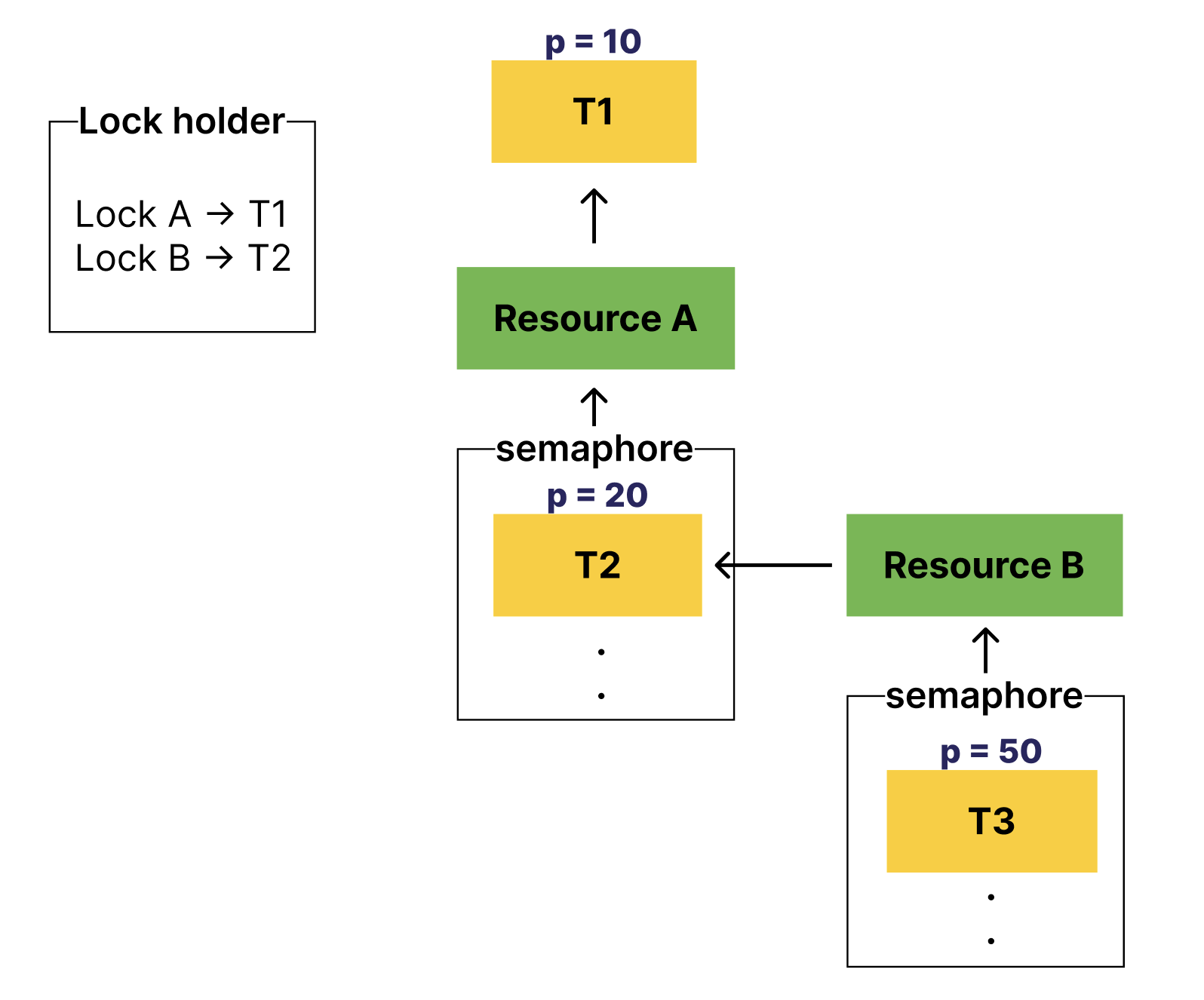
이렇게 상황이 바뀌었다.
T1의 우선순위는 가장 낮으며,
resource A를 기다리는 T2은 T1보다 우선순위가 높다.
resource B를 기다리는 T3은 T2보다 우선순위가 높다.
이런 경우, T3의 우선순위가 T1, T2에 기부되어야 한다.
중첩되어있는 모든 스레드 중, 자신보다 우선순위가 낮은 스레드까지 모~두 기부해 주어야 한다.
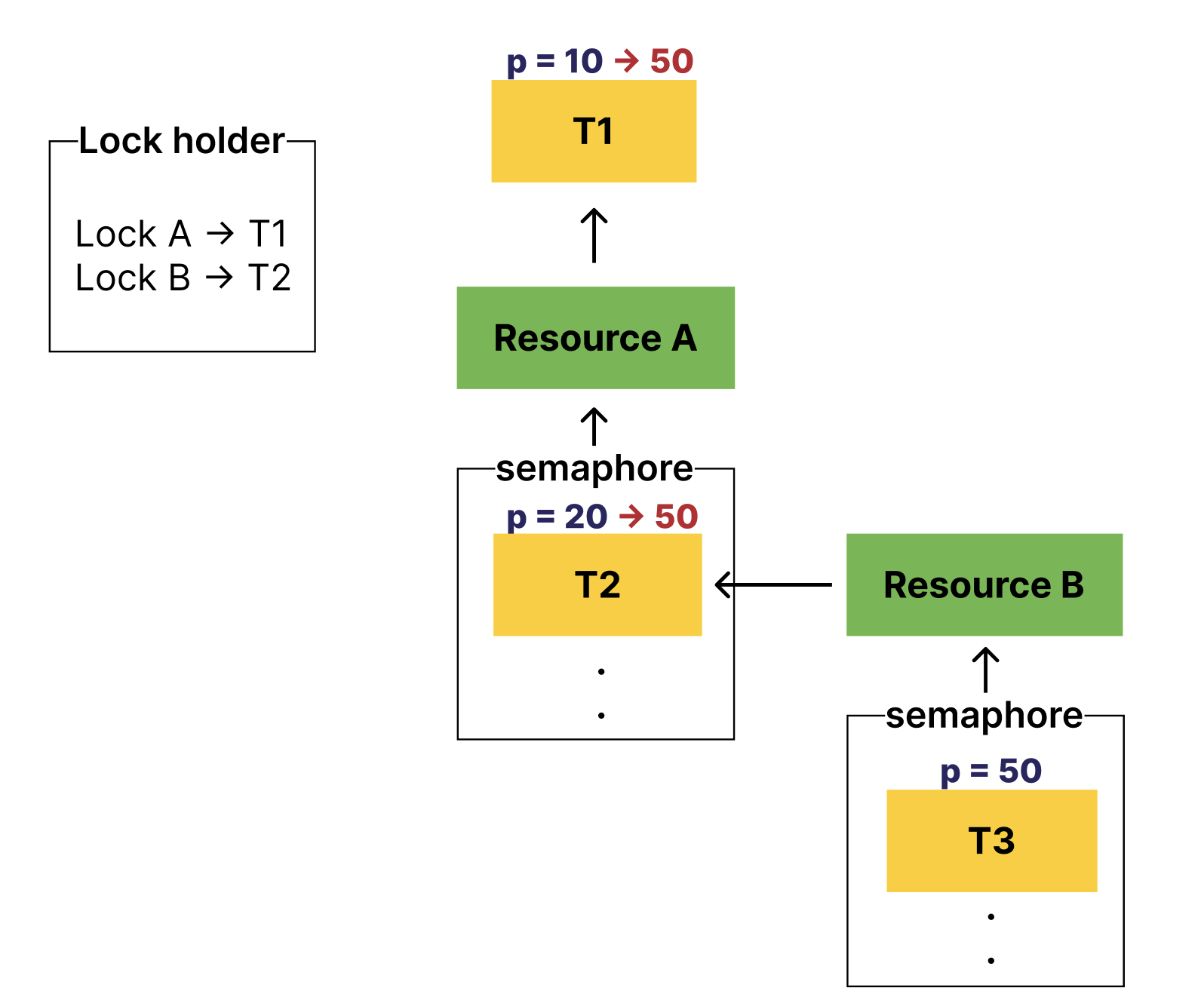
이렇게 말이다.
그렇다면 Lock A가 release 된다면 어떨까?
T1을 기다리는 스레드는 T2로 단일하기 때문에 원래 우선순위인 10으로 복원시켜줘야 한다.
이렇게 말이다!
그렇다면 또, Lock B가 release 된다면 어떨까?
당연히 T2의 우선순위가 복원되어야 한다.
.
.
nested donation에서는 기다리는 스레드가 추가되는 순간에 고려할 점이 많아지겠다.
T3은 T2에 기부하고, T2가 대기하고 있는 상태라면 T2가 대기 중인 resource의 holder, T1에게 기부해야 한다.
만약, T1도 대기 중인 상태였다면, T1이 대기 중인 resource의 holder에게도 기부해야 한다.
이렇게 중첩을 고려해야 하며 이는 8단계로 제한한다고 한다.
이 과정을 잘 살펴보면 또 하나의 아이디어가 떠오른다.
T2가 어떠한 Lock을 기다리는 상태인지 여부를 알아야 한다.
즉, 어떤 스레드가 Lock을 기다리는 지, 기다리고 있다면 어떤 Lock을 기다리고 있는 지를 알아야 한다.
자, 이제 정리를 해보자.
우선순위를 어떻게 기부받고, 복원해야 할까?
현재 내가 가진 lock의 반환을 기다리는 스레드들에게 donation받아 우선순위 스케줄링을 수행한 이후, lock을 반환하는 시점에서 원래 나의 priority(original priority)로 다시 복원시켜줘볼까?
그렇게 하려면 original_priority라는 필드가 thread에 추가되어야 하겠다!
lock_acquire() 시점에서 lock holder에게 priority donaiton을 하면 되지 않을까?
lock_release() 시점에서는 donated priority를 회수하면 되지 않을까?
multiple, nested 기부를 고려하자
중첩, 다중을 고려하면 나에게 우선순위를 기부한 스레드의 목록을 내가 가지고 있어야 한다.
그래야, 그 스레드 중에 가장 우선순위가 높은 스레드의 우선순위를 기부받을 수 있다.
그리고 lock을 release할 때, 나에게 기부한 스레드 목록에서 해당 lock을 기다렸던 스레드는 삭제해주어야 한다. 이제 나와 상관없어졌기 때문이다.
이 과정에서 나에게 기부한 스레드 목록에서 해당 lock을 기다린 건지 혹은 내가 소유한 다른 lock을 기다리는 건지 알아야한다.
때문에 추가로,기다리고있는 lock의 정보를 알아야 한다.
해당 lock과 관련된 스레드를 삭제한 다음, 남아있는 기부 스레드 목록이 있다면, 그들 중 가장 높은 우선순위로 재산정해야 한다.
그러면 이제 언뜻 감이 잡힌다.
thread가 가져야 하는 정보들이 몇 가지 추가된다.
- 내가 기다리는 Lock → release할 때 해당 lock을 기다리는 스레드들만 삭제해주어야 한다.
- 나에게 기부한 스레드 리스트 → 가장 높은 우선순위로 기부 받아야 한다.
구현 과정
thread.h / thread
아래와 같이 thread 구조체에 필드를 추가해준다
wait_on_lock: 내가 기다리고 있는 자원의 lock
donations: 나에게 우선순위를 기부해준 스레드 리스트
donation_elem: donation을 하게 될 경우, donations 리스트에 들어갈 element
struct thread {
.
.
/* donation을 위하여 선언 */
int original_priority;
struct lock* wait_on_lock;
struct list donations;
struct list_elem donation_elem;
.
.
}thread.c
추가한 필드를 초기화해준다.
static void
init_thread(struct thread* t, const char* name, int priority) {
ASSERT(t != NULL);
ASSERT(PRI_MIN <= priority && priority <= PRI_MAX);
ASSERT(name != NULL);
memset(t, 0, sizeof * t);
t->status = THREAD_BLOCKED;
strlcpy(t->name, name, sizeof t->name);
t->tf.rsp = (uint64_t)t + PGSIZE - sizeof(void*);
t->priority = priority;
t->original_priority = priority;
t->wait_on_lock = NULL;
list_init(&t->donations);
t->magic = THREAD_MAGIC;
}우선순위를 기부해주는 시점은 lock을 획득하려는 시점이다.
즉, lock_acquire() 이 수행되는 시점이다.
먼저, 우선순위를 기부하는 함수를 먼저 정의해보자.
donate_priority()
현재 스레드가 기다리는 lock의 holder,
그 holder가 기다리는 lock의 holder,
그 holder가 기다리는 lock의 holder....
이렇게 중첩을 고려하여 우선순위를 기부한다.
void donate_priority(void) {
// 'sema - waiters' 대기열에 들어가기 전에 우선순위 donation
struct thread* curr = thread_current();
// holder에게 우선순위 부여(중첩 고려)
while (curr->wait_on_lock != NULL) {
struct thread* holder = curr->wait_on_lock->holder;
if (curr->priority > holder->priority) {
holder->priority = curr->priority;
curr = holder;
}
else {
break;
}
}
}lock_acquire()
lock을 기다리게 되는 시점에, 현재 스레드의wait_on_lock을 추가한다.
그리고 현재 스레드를 기다리게 하는 중첩 스레드들 중, 우선순위가 낮은 스레드에게 우선순위를 기부한다.
void
lock_acquire(struct lock* lock) {
ASSERT(lock != NULL);
ASSERT(!intr_context());
ASSERT(!lock_held_by_current_thread(lock));
struct thread* curr = thread_current();
/* lock을 가진 스레드가 있다면 우선순위 기부 후, 대기 */
if (lock->holder) {
// holder의 donations에 현재 스레드 추가
list_insert_ordered(&lock->holder->donations, &curr->donation_elem, thread_compare_donate_priority, NULL);
// 현재 스레드가 실제로 기다리는 lock 추가
curr->wait_on_lock = lock;
// 현재 스레드의 우선순위보다 낮은 중첩 스레드에게 우선순위 기부
donate_priority();
}
sema_down(&lock->semaphore);
/* lock을 가질 순서가 되면, lock을 가진다. */
curr->wait_on_lock = NULL;
lock->holder = curr;
}자, 이제 lock을 release하는 경우가 남았다.
release해줄 때 크게 두 가지 일이 발생한다.
1. 해당 lock의 반환을 기다리며 나에게 우선순위를 기부한 스레드들을 '나에게 우선순위를 기부한 스레드의 목록 donations'에서 삭제해준다.
2. 갱신된 '나에게 우선순위를 기부한 스레드의 목록 donations'에서 다시 우선순위를 갱신한다.
remove_with_lock()
1번을 수행하는 함수를 정의한다.
void remove_with_lock(struct lock* lock) {
// lock을 release 하는 시점에 해당 lock으로 나를 기다렸던 스레드의 우선순위 반환
// (각자 다른 lock으로 나를 기다릴 수 있기 때문에(다중), 해당 lock을 가진 thread만 삭제)
struct thread* curr = thread_current();
struct list_elem* d_elem = list_begin(&curr->donations);
while (d_elem != list_end(&curr->donations)) {
struct thread* t = list_entry(d_elem, struct thread, donation_elem);
if (lock == t->wait_on_lock) {
list_remove(&t->donation_elem); // 이제 관련 없는 스레드는 지워줌
}
d_elem = list_next(d_elem);
}
}refresh_priority()
2번을 수행하는 함수를 정의한다.
void refresh_priority(void) {
// 내가 가진 donations 중에 가장 높은 우선순위를 기부받음
struct thread* curr = thread_current();
curr->priority = curr->original_priority;
if (list_empty(&curr->donations)) {
return;
}
list_sort(&curr->donations, thread_compare_donate_priority, NULL);
struct thread* max_thread = list_entry(list_front(&curr->donations), struct thread, donation_elem);
if (max_thread->priority > curr->priority) {
curr->priority = max_thread->priority;
}
}
이제 release 해보자.
lock_release()
해당 lock으로 나에게 기부한 스레드를 삭제한다.
그렇게 업데이트된 donations 리스트로 우선순위를 재계산한다.
마지막으로 lock을 해제하며,sema_up()을 호출한다.
void
lock_release(struct lock* lock) {
ASSERT(lock != NULL);
ASSERT(lock_held_by_current_thread(lock));
/* 해당 lock으로 기부받은 우선순위 삭제(중첩 처리) */
remove_with_lock(lock);
/* 현재 스레드 우선순위 재계산 */
refresh_priority();
/* lock을 해제함 */
lock->holder = NULL;
sema_up(&lock->semaphore);
}이제 다시 확인하자

야호!ㅠㅠ 너무!!! 어렵다.
도무지 multiple, nested는 자력으로 풀기에 시간이 부족해서 다른 블로그를 참고하여 흐름을 파악하고, 아이디어를 얻었다.
MLFQ Scheduler는 내일 또 도전한다!
