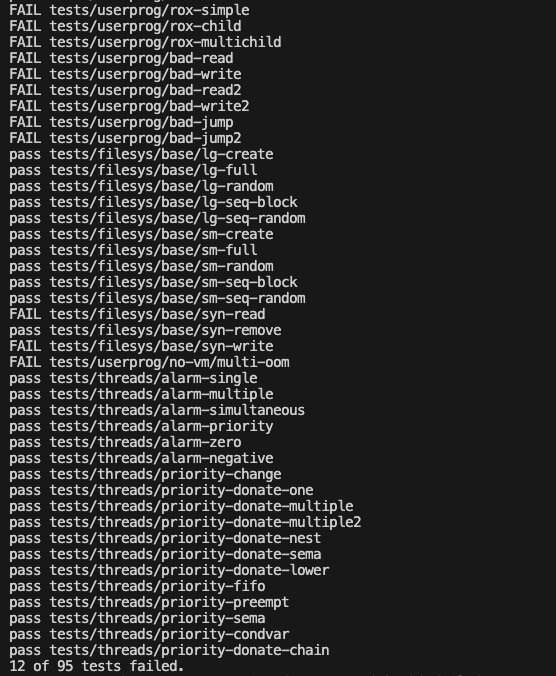
어제 종일 그저 박치기를 하다가 thread_current()에서 자꾸 터지길래
일단 정리하면서 요구사항을 하나씩 되짚어보기로 한다..
exec()
int exec (const char *cmd_line);
- 현재 프로세스를
cmd_line에 지정된 이름의 실행 파일로 변경합니다.- 성공하면 반환값은 없습니다.
- 프로그램을 로드하거나 실행할 수 없는 경우, 프로세스는 -1로 종료됩니다.
- 이 함수는 exec를 호출한 스레드의 이름을 변경하지 않습니다.
- 파일 설명자는 exec 호출 후에도 계속 열려 있습니다.
즉,
기존 프로세스에서 '작동되던 파일' → 'cmd_line으로 받은 실행 파일'
이렇게 덮어써주는 작업을 수행한다.
process_exec()를 실행시켜주면 된다.
이미 argument passing을 할 때 file 명을 파싱하여 해당 ELF file을 load 시켜주는 것은 완료하였다.
아 근데 cmd_line을 바로 process_exec() 인자로 넘겨주면 안 되는 문제가 있었다.
이유를 알아보자.
- process_exec()
아래와 같이load()를 수행하기 전, 현재 context를 kill한다. 즉, 주소 공간을 해제하고 새로운 파일을 위한 메모리를 새로 activate 시킨다.
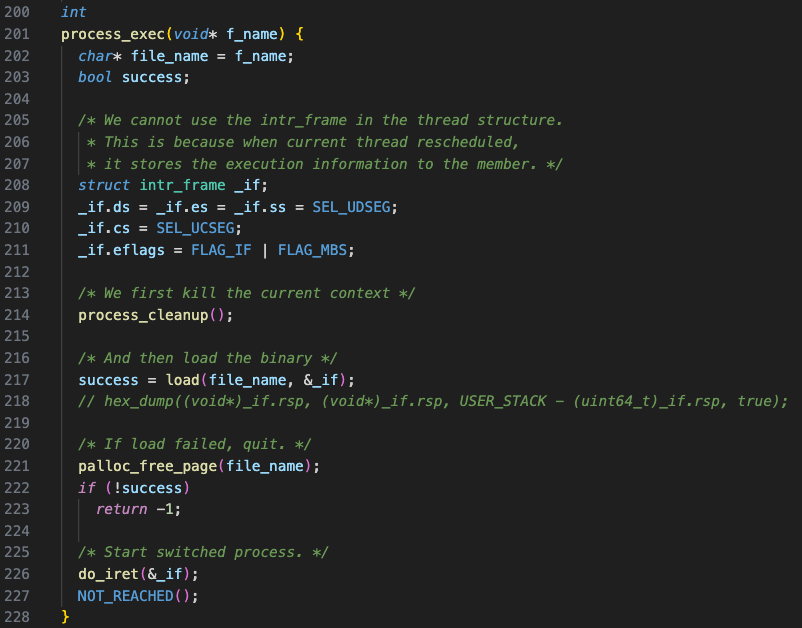
- process_cleanup()
따라서 기존 pml4(사용자 주소 공간) 내에 저장되어있던cmd_line문자열이 사라진다.
그래서 변경된 context, 커널 힙 영역으로cmd_line의 정보를 복사해 두어야 한다. process_exec()에서 계속 참조할 수 있도록 말이다.
.
.
이를 해결하기 위해,
exec 시스템 콜에서는 palloc_get_page를 사용하여 커널 힙에 복사한다.
int exec(const char* cmd_line) {
check_address(cmd_line);
char* new_cmd_line = palloc_get_page(PAL_ZERO); // user area -> kernel area 복사(이후 user stack 삭제됨)
if (new_cmd_line == NULL)
exit(-1);
strlcpy(new_cmd_line, cmd_line, PGSIZE);
if (process_exec(new_cmd_line) == -1)
exit(-1);
}여기에서 또, strlcpy를 사용한 이유는 따로 있다.
사실 cmd_line의 size가 어떻게 되는 지 알면, 익숙하게 사용하던 memcpy를 사용하면 된다.
while문을 돌려서 size를 얻고, 그 size를 인자로 memcpy를 하면 되지만(혹은 strlen 메서드를 사용해도 되겠다.)
사용하기 쉬우라고 만들어둔 strlcpy가 있더라.
문자열 길이를 매번 계산하거나 안전하게 null-terminator까지 복사하려면 strlcpy가 훨씬 편하고 안전하다.
- memcpy
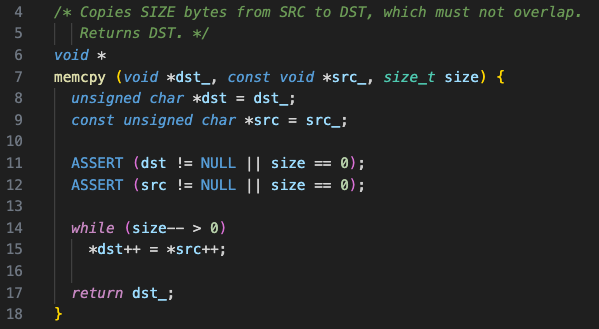
- strlcpy
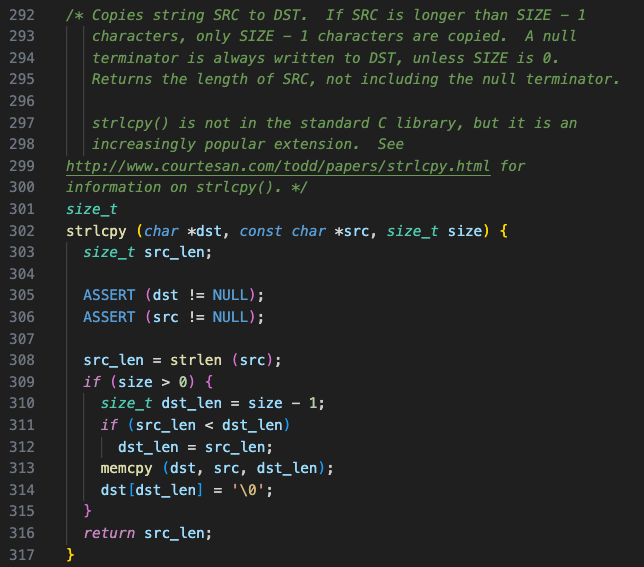
src로 들어오는 string을 dst로 들어오는 위치로 복사한다.
만약, src의 길이가 dst의 길이 보다 작다면 src의 길이 만큼만 복사한다.
.
string의 length만큼 copy한다고 해서 strlcpy인 것 같다. ㅎㅅㅎ
이제 남은 두 개의 시스템 콜은 아주 긴밀하게 연결되어 있다.
부모 프로세스가 fork()를 통해 자식 프로세스를 만드는데,
그 이후에 부모 프로세스는 자식 프로세스를 wait() 해야한다.
결국, wait() 시스템 콜이 없으면 fork()를 완전히 구현할 수 없고
fork() 시스템 콜이 없으면 wait()은 무의미하다.
우선 fork() 먼저 구현해본다.
fork()
pid_t fork (const char *thread_name);
- 현재 프로세스의 복제본인 THREAD_NAME이라는 이름의 새 프로세스를 생성합니다.
- 호출자(부모 프로세스)가 저장하는 레지스터 값을 복제합니다.
- 자식 프로세스는 file descriptor 및 가상 메모리 공간을 포함한 복제된 리소스를 가져야 합니다.
- 자식 프로세스가 리소스 복제에 실패하면 부모 프로세스의 fork() 호출은 TID_ERROR를 반환해야 합니다.
- 부모 프로세스는 자식 프로세스가 성공적으로 복제되었는지 확인할 때까지 포크에서 반환해서는 안 됩니다.
- 자식 프로세스의 pid를 반환해야 하며, 그렇지 않은 경우 유효한 pid가 아니어야 합니다.
- 자식 프로세스의 반환 값은 0이어야 합니다.
이 또한 process_fork()를 호출하는 시스템 콜이다.
syscall.c에는 아래와 같이 정의해준다.
tid_t fork(const char* thread_name, struct intr_frame* f) {
return process_fork(thread_name, f);
}중요한 건, process_fork()부터다..
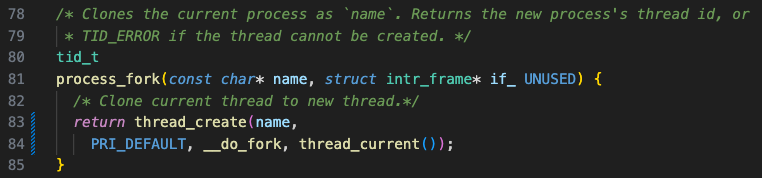
지금 구현되어 있는 건 그냥 현재 스레드에서 바로 새로운 스레드를 생성하는 코드이다.
새롭게 생성된 자식 스레드는 CPU 스케줄링을 받으면 __do_fork() 를 최초로 수행하게 된다.
1번 요구사항은 OK
2번 요구사항부터 해보자.
- 호출자(부모 프로세스)가 저장하는 레지스터 값을 복제합니다.
레지스터 값 복제
부모 프로세스에서 자식 프로세스로 레지스터 값을 넘겨주려면 어떻게 해야할까??

__do_fork()에 힌트가 있다. parent_if를 어떻게 자식 프로세스로 넘겨줄 것이냐?
지금 자식 프로세스는 최초로 생성되어, 새로운 intr_frame을 구성해갈 것이다.
그런데 fork는 부모와 똑같은 레지스터 값을 가져야 한다.(이후에는 변경될지라도 말이다)
parent_if를 부모 프로세스에서 별도로 백업해준다. thread_create()를 할 때는 부모 프로세스를 인자로 주기 때문에 부모 프로세스의 정보를 가지고 간다.
따라서, 부모 프로세스 내에 intr_frame을 백업해두고, 자식 프로세스의 레지스터를 초기화할 때, 이를 가져와 복제하면 된다.
- process_fork()
.
.
memcpy(&curr->parent_if, if_, sizeof(struct intr_frame)); // 레지스터 값 복제
tid_t pid = thread_create(name, PRI_DEFAULT, __do_fork, curr);
if (pid == TID_ERROR) {
return TID_ERROR; // 요구사항 4번
}
.
.
- __do_fork()
.
.
struct intr_frame if_;
struct thread* parent = (struct thread*)aux;
struct thread* current = thread_current();
struct intr_frame* parent_if = &parent->parent_if;
/* 1. Read the cpu context to local stack. */
memcpy(&if_, parent_if, sizeof(struct intr_frame));
.
. 이제 intr_frame 복제는 완료되었다. 이 시점에서 잊으면 안 되는 한 가지가 있다.
7번 요구사항이다.
- 자식 프로세스의 반환 값은 0이어야 합니다.
레지스터를 똑같이 복제하되, 바로 아래에 다음과 같이 반환값을 0으로 재설정 해준다.
static void
__do_fork(void* aux) {
struct intr_frame if_;
struct thread* parent = (struct thread*)aux;
struct thread* current = thread_current();
/* TODO: somehow pass the parent_if. (i.e. process_fork()'s if_) */
struct intr_frame* parent_if = &parent->parent_if;
bool succ = true;
/* 1. Read the cpu context to local stack. */
memcpy(&if_, parent_if, sizeof(struct intr_frame));
if_.R.rax = 0; // child process의 반환값은 0 .
.
현재 수정 중인 __do_fork()에서 3번 요구사항까지 수행해야한다.
- 자식 프로세스는 file descriptor 및 가상 메모리 공간을 포함한 복제된 리소스를 가져야 합니다.
→ __do_fork() 에서 위의 작업을 수행해야 fork 완성이다.
가상 메모리 공간 복제
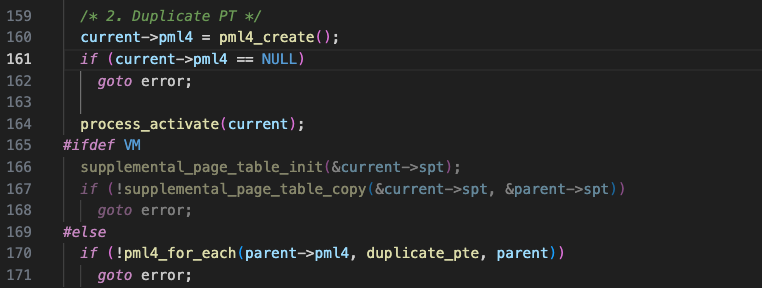
여기까지는 구현되어있다.
코드를 보면, 현재 프로세스(자식 프로세스)의 pml4, 즉, Page Table을 생성하고 CPU가 참조할 페이지 테이블을 해당 PML4 table로 설정한다.(CR3 레지스터가 가리키게 한다.)
그런 다음, 부모 프로세스의 page table의 각 entry를 복제하면 된다.
복제하는 로직은 duplicate_pte() 에 구현하면 된다.
다행히, 요 함수는 TODO 주석으로 아주 상세하게 가이드를 제시한다.
주석대로 하나씩 해나가면 된다.
다시 한 번 기억하자. page table의 각 entry를 복제하는 과정이다!
- duplicate_pte
static bool
duplicate_pte(uint64_t* pte, void* va, void* aux) {
struct thread* current = thread_current();
struct thread* parent = (struct thread*)aux;
void* parent_page;
void* newpage;
bool writable;
/* 1. TODO: If the parent_page is kernel page, then return immediately. */
if (is_kernel_vaddr(va)) {
return true;
}
/* 2. Resolve VA from the parent's page map level 4. */
parent_page = pml4_get_page(parent->pml4, va);
if (parent_page == NULL) {
return false;
}
/* 3. TODO: Allocate new PAL_USER page for the child and set result to
* TODO: NEWPAGE. */
newpage = palloc_get_page(PAL_USER | PAL_ZERO);
if (newpage == NULL) {
return false;
}
/* 4. TODO: Duplicate parent's page to the new page and
* TODO: check whether parent's page is writable or not (set WRITABLE
* TODO: according to the result). */
memcpy(newpage, parent_page, PGSIZE);
writable = is_writable(pte);
/* 5. Add new page to child's page table at address VA with WRITABLE
* permission. */
if (!pml4_set_page(current->pml4, va, newpage, writable)) {
/* 6. TODO: if fail to insert page, do error handling. */
return false;
}
return true;
}이렇게 하면 부모 프로세스의 가상 메모리 공간을 똑같이 복제하게 된다.
Page table(pml4) 그리고 그 table의 각 entry까지 복제하였다.
file descriptor 복제
마지막이다.
file descriptor 또한 부모에게서 상속받는다.
총 64개의 entry가 있다. file duplicate를 사용하여 각 엔트리를 복제해주면 된다.
/* 3. Duplicate file descriptor table */
for (int fd = 0;fd < 64; fd++) {
if (parent->fd_table[fd] == NULL) {
continue;
}
current->fd_table[fd] = file_duplicate(parent->fd_table[fd]);
}지금까지 어떤 요구사항이 남아있는지 확인하자.
현재 프로세스의 복제본인 THREAD_NAME이라는 이름의 새 프로세스를 생성합니다.호출자(부모 프로세스)가 저장하는 레지스터 값을 복제합니다.자식 프로세스는 file descriptor 및 가상 메모리 공간을 포함한 복제된 리소스를 가져야 합니다.자식 프로세스가 리소스 복제에 실패하면 부모 프로세스의 fork() 호출은 TID_ERROR를 반환해야 합니다.- 부모 프로세스는 자식 프로세스가 성공적으로 복제되었는지 확인할 때까지 포크에서 반환해서는 안 됩니다.
- 자식 프로세스의 pid를 반환해야 하며, 그렇지 않은 경우 유효한 pid가 아니어야 합니다.
자식 프로세스의 반환 값은 0이어야 합니다.
좀 더 쉬운 것 같은 6번 먼저 해보자.
- 자식 프로세스의 pid를 반환해야 하며, 그렇지 않은 경우 유효한 pid가 아니어야 합니다.
기억하면 좋을 것은
process_fork() 함수는 부모 프로세스가 수행하고,
__do_fork() 함수는 자식 프로세스가 수행한다는 점이다.
이유는 process_fork()를 통해 부모가 자식을 생성하는데, 이 때, 자식 프로세스의 실행 시작점(rip)를 __do_fork()로 지정하면서 생성했기 때문이다.
따라서 부모 프로세스가 자식 프로세스의 pid를 반환하려면 process_fork()를 수정하면 되겠다.
tid_t
process_fork(const char* name, struct intr_frame* if_ UNUSED) {
/* Clone current thread to new thread.*/
struct thread* curr = thread_current();
memcpy(&curr->parent_if, if_, sizeof(struct intr_frame)); // 레지스터 값 복제
tid_t pid = thread_create(name, PRI_DEFAULT, __do_fork, curr);
if (pid == TID_ERROR) {
return TID_ERROR;
}
return pid; // 부모 프로세스의 반환값은 자식 프로세스의 pid
}마지막 5번을 해결해보자.
- 부모 프로세스는 자식 프로세스가 성공적으로 복제되었는지 확인할 때까지 포크에서 반환해서는 안 됩니다.
부모 프로세스는 자식 프로세스가 성공적으로 복제될 때까지 기다려야 한다.
이유는 1. 동기화 문제와 2. 자식 프로세스의 복제 성공 여부를 리턴해주어야 하기 때문이다.
부모 프로세스와 또옥같은 상태를 가진 자식 프로세스를 생성하는 것이 목적인데, fork를 수행하던 중에 부모 프로세스가 다른 작업을 수행하게 되어 변화가 생긴다면 어떨까?
결국에는 부모 프로세스와 똑같이 복제하는 것이 불가하게 된다.
이것이 위험한 이유는, 부모 프로세스가 fork 이후에 특정 메모리를 free 했다고 하자. 그런데 자식 프로세스는 이미 해당 메모리를 복제한 이후라면, 자식 프로세스는 접근해서는 안 될 자원에 접근하게 될 수도 있다.
pintos에서는 synchronization을 구현하기 위하여 semaphore를 사용하고 있다.
그러면, 이렇게 해결할 수 있겠다.
- 부모 프로세스 ->
thread_create()이후, 자식이__do_fork()를 마무리할 때까지 sema_down - 자식 프로세스 ->
__do_fork()가 마무리 되면 sema_up
또 한 가지!
중요한 점은 자식 프로세스가 정상적으로 복제되지 못했다면 부모는 TID_ERROR를 반환해야 한다는 점이다.
즉, 부모는 자식의 초기화 성공 여부를 끝까지 감시하고, 실패 시 올바르게 대응할 책임이 있다.
이러한 구조는 좀비 프로세스 방지, 그리고 프로세스 생성 실패 시 리소스 누수 방지 측면에서도 중요하다.
1. thread 구조체에 추가
struct semaphore fork_sema; /* parent process는 child process의 생성이 완료되기까지 추적 */2. 부모 프로세스 sema_down
실은 여기에서 엄청엄청 오래 고민헀다. process_fork()에서 자식 프로세스의 정보를 어떻게 알 수 있을까?
thread_create()를 통해 자식 프로세스의 pid를 반환받는다.
그 pid로 thread 객체를 얻어오고, 그 thread 객체의 fork_sema 필드를 찾아야 한다.
나는 유튜브를 통해 힌트를 얻었다.
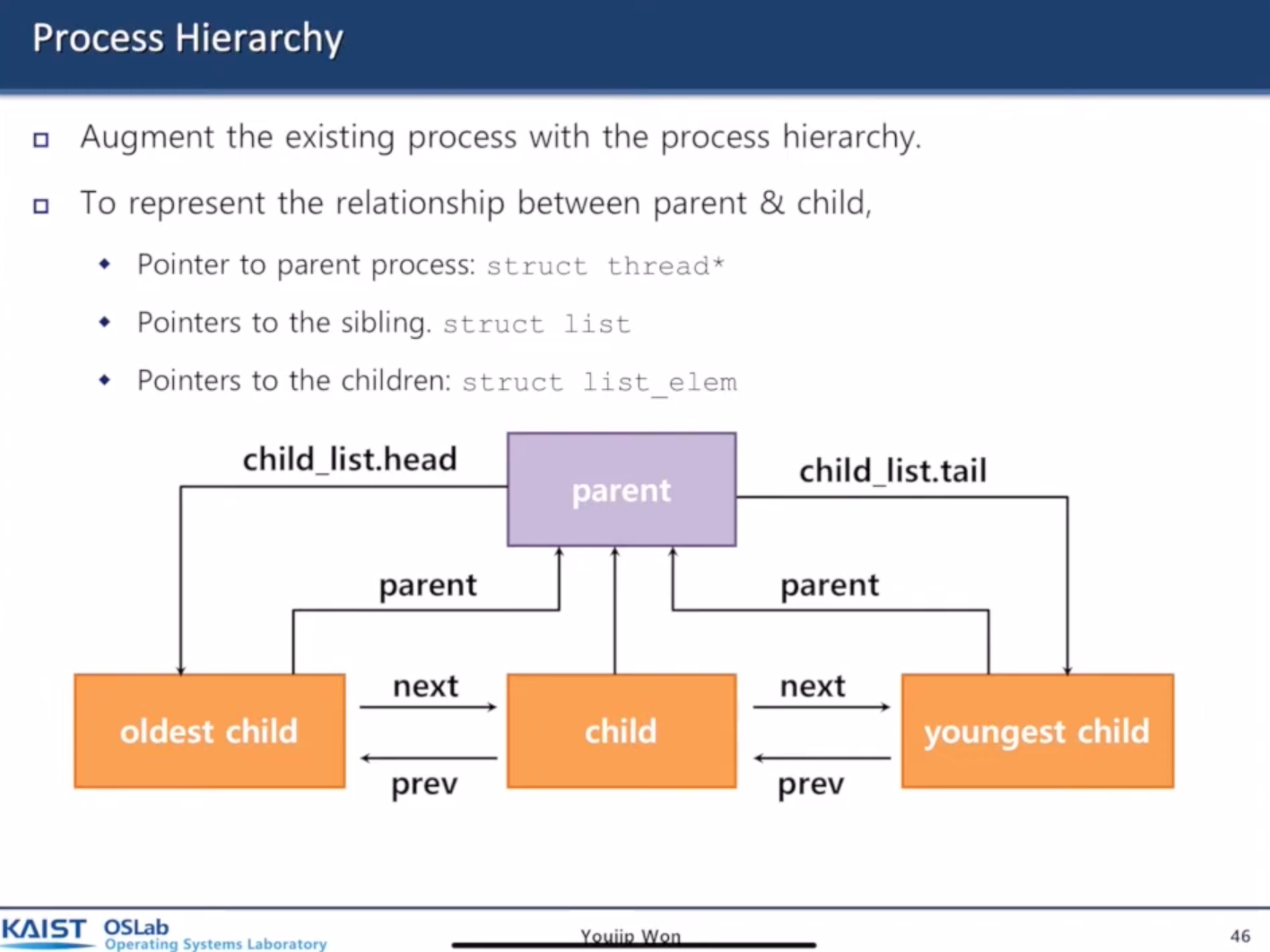
parent와 child의 hierarchy는 list 구조로 관리하면 좋다.
왜냐, 하나의 parent는 여러 child를 가질 수 있기 때문이다.
그러면 또 하나의 고민 지점이 생긴다.
어느 시점에 부모의 child list에 추가해주면 될까?
내 고민의 해답은 thread_create() 시점에서 추가해주는 것이었다.
thread_create()는 자식 스레드 객체(t)를 완전히 초기화하고 반환한 이후이므로, 이 시점에는 fd_table, sema, list_elem 등이 모두 유효하게 설정되어 있다.
반면, __do_fork() 내부에서는 thread_current()는 자식이지만, 아직 부모 입장에서 접근 가능한 리스트에는 등록되지 않은 상태일 수 있다.
따라서, thread_create() 시점에서 추가해주기로 한다.
thread_create()를 수행하는 주체는 부모 프로세스인 점을 상기한다면 쉽게 떠올릴 수 있다
- thread 구조체에 추가
struct thread {
.
.
struct list child_list;
struct list_elem child_elem;
.
.- child list 초기화
static void
init_thread(struct thread* t, const char* name, int priority) {
.
.
sema_init(&t->wait_sema, 0);
list_init(&t->child_list);
.
.
}- child list에 추가
tid_t
thread_create(const char* name, int priority,
thread_func* function, void* aux) {
struct thread* t;
tid_t tid;
.
.
/* file descriptor 초기화 */
t->fd_table = calloc(64, sizeof(struct file*));
/* parent thread의 child list에 추가 */
list_push_back(&thread_current()->child_list, &t->child_elem);
.
.
return tid;
}하나 더 언급하자면 ㅎㅎ 직전 포스팅에서 fd_table 초기화를 process_init()에서 해주었는데, 이렇게 하면 __do_fork() 에서 fd_table이 초기화되기 전에 접근하게 되더라. 그래서 thread_create()에서 초기화해주는 것으로 변경!
- child list에서 해당 pid를 가진 child를 찾아, sema_down
tid_t
process_fork(const char* name, struct intr_frame* if_ UNUSED) {
/* Clone current thread to new thread.*/
struct thread* curr = thread_current();
memcpy(&curr->parent_if, if_, sizeof(struct intr_frame)); // 레지스터 값 복제
tid_t pid = thread_create(name, PRI_DEFAULT, __do_fork, curr);
if (pid == TID_ERROR) {
return TID_ERROR;
}
struct thread* child = get_child_process(pid);
sema_down(&child->fork_sema); // 자식 프로세스가 load 될 때까지 대기
return pid; // 부모 프로세스의 반환값은 자식 프로세스의 pid
}여기에서는 보조 함수로 get_child_process() 를 추가로 정의했다.
3. 자식 프로세스 sema_up
이제 자식 프로세스의 fork가 정상적으로 마무리되면 sema_up을 해주면 된다.
static void
__do_fork(void* aux){
.
.
process_init();
sema_up(¤t->fork_sema);
/* Finally, switch to the newly created process. */
if (succ)
do_iret(&if_);
error:
thread_exit();
}완성이다.
Q. 왜 fork()를 통해 프로세스를 생성할까?
프로세스를 생성하기 위해서는 초기화해야하는 것들이 많다.
부팅되고, main thread를 생성하기 위해 초기화했던 많은 것들을 기억하는가?fork()가 없다면 process를 하나 생성할 때마다 동일한 작업을 해주어야 한다.
메모리 세그먼트 분할, 레지스터 초기화, 파일 디스크립터 초기화, 페이지 테이블 설정 등.. 모든 실행 컨텍스트를 새로 준비해야 한다.반면 부모 프로세스를 그저 복제하면 훨씬 간단해진다.
시간은 물론, 코드 복잡도가 크게 줄어들고 안정적으로 생성할 수 있게 된다.
즉, fork()는 복잡한 초기화 과정을 보다 간결하게 제공하는 역할을 한다.
wait()
int wait (pid_t pid);
- 자식 프로세스
pid를 기다리고 자식 프로세스의 종료 상태를 반환합니다.- 자식 프로세스
pid가 아직 살아 있으면 종료될 때까지 기다립니다.
그런 다음 자식 프로세스pid가 종료 시 전달된 상태exit_status를 반환합니다.exic(pid)를 호출하지 않았지만 커널에 의해 종료된 경우(예: 예외로 인해 종료된 경우) -1를 반환해야 합니다.- 부모 프로세스가 wait를 호출할 때 이미 종료된 자식 프로세스를 기다리는 것은 허용되지만,
커널은 부모 프로세스가 자식 프로세스의 종료 상태를 가져오거나 자식 프로세스가 커널에 의해 종료되었음을 알 수 있도록 허용해야 합니다.
fork 이후에 부모 프로세스는 자식 프로세스를 기다린다.
init.c를 보면 이렇게 기다린다는 사실을 알 수 있다. 그리고 테스트 케이스에서도 이렇게 기다리고 있다.
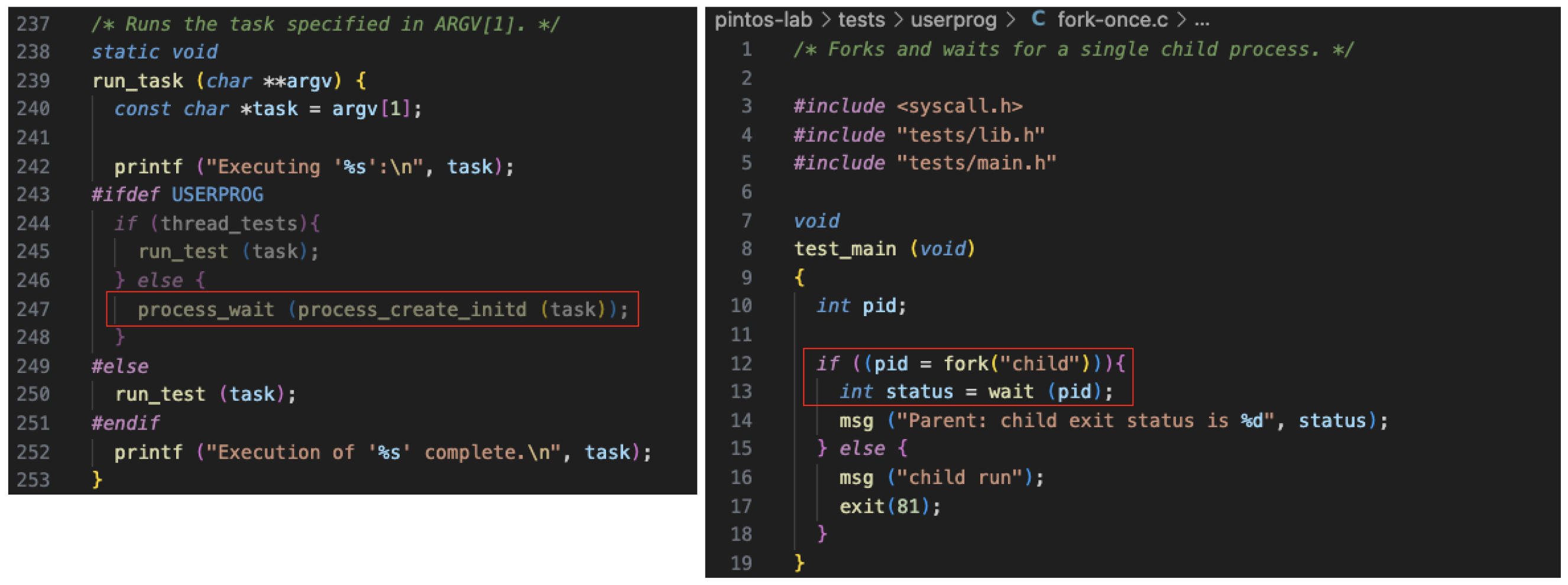
wait를 구현해야 fork도 완성된다.
해보자
여기서 개념이 꼬이지 않게 조심해야하는데,
위에서 fork하면서 semaphore로 분명 기다렸다.
"그렇게 기다리면 된 거 아냐?"
아니다.
fork가 동기화로 자식 프로세스의 복제가 마무리되기를 보장했던 것이고,
wait의 목적은 자식 프로세스가 완전히 종료될 때까지 대기하고,
그 종료 상태(exit_status)를 수거해 부모가 확인할 수 있도록 하는 것이다.
이유가 궁금할 수도 있다. wait을 하는 이유는 직전 포스팅에서 다뤘다. 다만 pintos에서는 그냥 이렇게 설계한 거라고 보면 될 것 같다.
요약하자면, 좀비 프로세스를 방지하기 위함이다.
pintos에서는 부모 프로세스가 fork 시점에서 곧바로 대기하지만 unix 운영체제에서는 부모 프로세스가 곧바로 대기하는 경우도 있고, 그렇지 않은 경우도 있다. 부모 프로세스도 자신의 작업을 수행하다가 exit 하기 전, 자식 프로세스를 기다리는 것이다.
여튼 fork가 완료되기를 기다린 것처럼 exit을 기다리면 되기 때문에 쏘 이지다.
머릿속으로 정리해보자. 시점이 중요하다.
1. thread 구조체에 wait을 위한 sema 추가
2. wait 시스템콜 내에서 해당 pid를 가지는 프로세스 sema down
3. exit 시스템콜 내에서 sema up
이제 구현해보자.
- thread 구조체
struct thread {
.
.
struct semaphore wait_sema; /* wait */
.
.- wait 시스템 콜에서 sema down
int
process_wait(tid_t child_tid UNUSED) {
struct thread* child = get_child_process(child_tid);
if (child == NULL) {
return -1;
}
/* child process가 exit되기를 기다림 */
sema_down(&child->wait_sema);
/* child process가 exit되면 child_list에서 삭제 */
list_remove(&child->child_elem);
return child->exit_status;
}child list에서 삭제해주는 것도 잊지말자.
- exit 시스템 콜에서 sema up
void
process_exit(void) {
struct thread* curr = thread_current();
/* fdt 정리 */
for (int i = 0; i < 64;i++) {
curr->fd_table[i] = NULL;
}
free(curr->fd_table);
/* 프로세스 정리 */
process_cleanup();
/* sema up - parent process에게 알림 */
sema_up(&curr->wait_sema);
}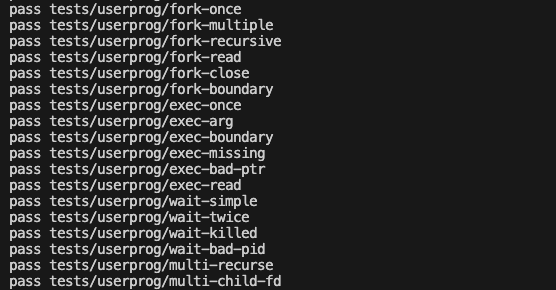
끝이다ㅠ
사실은 엄청나게 나를 괴롭힌 에러가 있었다.
thread_current()를 호출할 때마다 ASSERT로 종료되는 점이었다.
fork once는 되는데, 또 안 될 때도 있고, multiple은 계속 안 되더라.
일관성이 없어서 원자성 문제인가 싶다가도, 디버깅 프린트문을 찍어보면 다 잘 삽입되고 있다.
이상하다!!
한 삼일? 정도를 디버깅했는데 도무지 답이 안 나왔다.
근데 이 문제의 원인은 kernel area를 과하게 사용했다는 점에 있었다.
이번에도 나의 수호천사 권호님이ㅠㅠ 도와주셨다.. 그는 신일까?
결론은 argument passing에서 argv의 배열을 너무 크게 선언했기 때문이다.
kernel stack은 각 프로세스마다 4kB 내의 자원만 감당할 수 있는데, 이는 thread 구조체와 스택이 공유하게 된다.
따라서 argv[128]처럼 커다란 배열을 선언하면 kernel stack overflow가 발생하고, thread_current() 내부에서 검사하는 magic 값이 깨지는 것이다.
char* argv[64]; // 인자 최대 크기로 제한(인자 스트링 저장)이렇게 64로 얌전히 수정한다..
argv[128] → 128 * 8 = 1024 바이트
argv[64] → 512 바이트
이렇게 줄이면 스택 공간이 줄어들어 struct thread의 magic 값을 침범하지 않게 되어 문제가 해결된다.
으앙 바로 되었다......ㅠ
스택에 큰 데이터를 올리는 것이 얼마나 위험한지 절실히 배웠따.. 🥲
.
.
남은 것들은 아래와 같다!
더 해봅시다! All pass 보자.