
서두에 말하자면,
이번 포스팅은 전체 구현을 완료한 후에 작성한 것으로, 사고의 흐름이 아니라 최종적으로 발견한 해답 위주로 전개된다.
부분 부분, 고민했던 내용을 남기려 한다.
git book의 안내를 보며 시작하자.
In this section, you will implement memory-mapped pages. Unlike anonymous pages, memory-mapped pages are file-backed mappings. The contents in the page mirror data in some existing file. If a page fault occurs, a physical frame is immediately allocated and the contents are copied into the memory from the file. When memory-mapped pages are unmapped or swapped out, any change in the content is reflected in the file.
이 섹션에서는 memory-mapped page를 구현합니다. anonymous page와 달리 memory-mapped page는 파일 백업 매핑입니다.
페이지에 있는 내용은 기존 파일의 데이터를 미러링합니다.
page fault가 발생하면 물리적 프레임이 즉시 할당되고 파일에서 메모리로 내용이 복사됩니다.
memory-mapped page가 unmapped되거나 swapped out되면 내용의 변경 사항이 파일에 반영됩니다.
memory-mapped page는 file-backed page이다.
즉, disk에 원본이 존재하며 이를 복사해 RAM에 올려 사용한다.
하지만 늘 원본과 동일하진 않다. RAM에 올린 상태에서 수정이 이루어진다면? disk에 있는 원본 또한 변경사항을 반영해주어야 한다.
변경사항을 반영하는 시점은 아래 두 가지 경우이다.
- unmapped 될 때
- swapped out 될 때
mmap()
mmap, munmap system call을 구현해야한다.
우선 mmap 먼저 구현해보자.
system call, mmap을 구현하기 위해서는
file.c에 정의된 빈 함수인do_mmap을 재구성하여 이를 사용한다.
void *mmap (void *addr, size_t length, int writable, int fd, off_t offset);git book을 먼저 보자.
Maps length bytes the file open as fd starting from offset byte into the process's virtual address space at addr. The entire file is mapped into consecutive virtual pages starting at addr. If the length of the file is not a multiple of PGSIZE, then some bytes in the final mapped page "stick out" beyond the end of the file. Set these bytes to zero when the page is faulted in, and discard them when the page is written back to disk. If successful, this function returns the virtual address where the file is mapped. On failure, it must return NULL which is not a valid address to map a file.
파일의 offset byte에서 시작하여 length만큼 프로세스의 가상 주소 공간인 addr로 매핑합니다.
전체 파일은 addr에서 시작하여 연속적인 가상 페이지로 매핑됩니다.
파일의 length가 PGSIZE의 배수가 아닌 경우, 최종 매핑된 페이지의 일부 바이트는 파일 끝 너머로 "stick out" 됩니다.
page fault 가 있을 때 모든 바이트를 0으로 설정하고, 페이지가 디스크에 다시 기록될 때 이를 버립니다.
mmap()에 성공하면 파일이 매핑된 가상 주소를 반환합니다. 실패하면 파일을 매핑하는 데 유효한 주소가 아닌 NULL을 반환해야 합니다.
A call to mmap may fail if the file opened as fd has a length of zero bytes. It must fail if addr is not page-aligned or if the range of pages mapped overlaps any existing set of mapped pages, including the stack or pages mapped at executable load time. In Linux, if addr is NULL, the kernel finds an appropriate address at which to create the mapping. For simplicity, you can just attempt to mmap at the given addr. Therefore, if addr is 0, it must fail, because some Pintos code assumes virtual page 0 is not mapped. Your mmap should also fail when length is zero. Finally, the file descriptors representing console input and output are not mappable.
Memory-mapped pages should be also allocated in a lazy manner just like anonymous pages. You can use vm_alloc_page_with_initializer or vm_alloc_page to make a page object.
파일의 길이가 0바이트인 경우 mmap 호출이 실패할 수 있습니다.
addr이 페이지 정렬이 되어 있지 않거나, 매핑된 페이지 범위가 스택이나 실행 가능한 로드 시점에 매핑된 페이지를 포함하여 기존의 매핑된 페이지 집합과 겹치면 실패해야 합니다.
Linux에서는 addr이 NULL인 경우 커널이 매핑을 생성할 적절한 주소를 찾습니다. 간단히 하기 위해 주어진 addr에서 mmap을 시도할 수 있습니다.
따라서 일부 Pintos 코드는 가상 페이지 0이 매핑되지 않는다고 가정하기 때문에 addr이 0이면 실패해야 합니다. 길이가 0일 때 mmap도 실패해야 합니다. 마지막으로 콘솔 입력 및 출력을 나타내는 파일 설명자는 매핑할 수 없습니다.Memory-mapped page도 anonymous page와 마찬가지로 lazy 할당해야 합니다.
페이지 객체를 만들기 위해vm_alloc_page_with_initialize또는vm_alloc_pag를 사용할 수 있습니다.
.
.
system call을 먼저 정의해주자
위 gitbook의 내용을 추려보자면, 아래의 경우 NULL 반환을 해주어야 한다.
- 파일의 length가 0바이트인 경우
- addr이 페이지 정렬이 되어 있지 않거나 0인 경우
- 매핑된 페이지 범위가 스택이나 실행 가능한 로드 시점에 매핑된 페이지를 포함하여 기존의 매핑된 페이지 집합과 겹치는 경우
- fd가 콘솔 입력 및 출력인 경우
- 파일의 offset가 PGSIZE의 배수가 아닌 경우
case SYS_MMAP:
f->R.rax = mmap(f->R.rdi, f->R.rsi, f->R.rdx, f->R.r10, f->R.r8);
break;
...
void* mmap(void* addr, size_t length, int writable, int fd, off_t offset) {Add commentMore actions
if (addr != pg_round_down(addr) || addr == NULL) {
return NULL;
}
if (length == 0) {
return NULL;
}
if (fd == 0 || fd == 1) { // 표준 입출력 fd 에러
return NULL;
}
if (offset % PGSIZE != 0) {
return NULL;
}
if (spt_find_page(&thread_current()->spt, addr) != NULL) {
return NULL;
}
struct file* file = thread_current()->fd_table[fd];
if (file == NULL) {
return NULL;
}
if (do_mmap(addr, length, writable, file, offset) == NULL) {
return NULL;
}
return addr;
}system call 코드에서는 do_mmap()을 호출하며 종료된다.
do_mmap() 함수에서 mmap을 수행해주자.
do_mmap()
어떤 작업이 수행되어야 할지 먼저 생각해보자.
우선, mapping 하고자 하는 file의 크기는 하나의 페이지보다 클 수도 있다.
4KB 보다 크기가 크다면, 연속된 메모리에 mapping해준다.
또한,
memory mapped file 또한 lazy loading 되어야 한다.
lazy loading을 하기 위해서는 aux를 저장해두었다가 lazy_load_segment() 함수를 호출할 때 인자로 넘겨준다.
이 aux에는 file, offset, size 등의 정보가 포함되어야 한다.
이를 기억하고 한번 해보자!
우선, project2에서의 load_segment() 함수를 참고하여 진행한다.
file의 데이터는 byte 단위로 읽어오기 때문에 실제 bytes 수를 page 단위로 하여, 남는 bytes는 0으로 채운다.
따라서 실제 read_bytes, zero_bytes 를 계산해준다.
read_bytes와zero_bytes이 때 만난 에러가 있었다.
do_mmap()에서 인자로 받은 length를 기준으로 read_bytes를 설정하고, page 단위로 남는 bytes를 zero_bytes로 설정하였더니 커널 패닉이 생겼다.인자로 받는 length는 이미 페이지 단위로 mmap을 요청한다. 따라서 실제로 mapping하고자 하는 file의 size를 다시 얻어오고, 그 size를 기준으로 read_bytes, zero_bytes를 계산해야한다.
size_t read_bytes = file_length(f) < length ? file_length(f) : length;
mapping file의 page 개수
실은 이 page 개수가 왜 필요한지 지금은 알 수 없다.
munmap()을 할 때가 되면 필요성을 느끼게 되고, 나는 실제로 munmap()을 구현하는 과정에서 추가해주었다.
file은 4KB(page size) 보다 클 수 있다. 따라서 여러 페이지를 사용하여 하나의 file을 매핑해야한다면, 거꾸로 이를 unmap 해줄 때는 매핑된 모든 page를 unmapped 해주어야 한다.
이 때를 위해 이 file이 총 몇 개의 page를 사용했는지의 정보를 추가로 저장해야 한다.
void*
do_mmap(void* addr, size_t length, int writable,
struct file* file, off_t offset) {
struct file* f = file_reopen(file);
void* original_addr = addr;
size_t read_bytes = file_length(f) < length ? file_length(f) : length; // 실제 file size 확인
size_t zero_bytes = PGSIZE - read_bytes % PGSIZE;
/* munmap을 고려한 총 page 개수 */
int page_cnt;
if (read_bytes < PGSIZE) {
page_cnt = 1;
}
else if (read_bytes % PGSIZE != 0) {
page_cnt = read_bytes / PGSIZE + 1;
}
else {
page_cnt = read_bytes / PGSIZE;
}
while (read_bytes > 0 || zero_bytes > 0) {
size_t page_read_bytes = read_bytes < PGSIZE ? read_bytes : PGSIZE;
size_t page_zero_bytes = PGSIZE - page_read_bytes;
/* lazy_load_segment 인자(aux) 전달 */
struct vm_aux* vm_aux = malloc(sizeof(struct vm_aux));
if (vm_aux == NULL) {
return NULL;
}
vm_aux->file = f;
vm_aux->ofs = offset;
vm_aux->read_bytes = page_read_bytes;
vm_aux->zero_bytes = page_zero_bytes;
vm_aux->page_cnt = page_cnt;
/* page 등록 */
if (!vm_alloc_page_with_initializer(VM_FILE, addr, writable, lazy_load_segment, vm_aux)) {
return NULL;
}
// printf("*** addr: %p / read_bytes: %d / offset: %d\n", addr, read_bytes, offset);
read_bytes -= page_read_bytes;
zero_bytes -= page_zero_bytes;
offset += page_read_bytes;
addr += PGSIZE;
}
return original_addr;
}file의 실제 bytes size만큼을 page 단위로 매핑하기 위하여
lazy loading 사전 처리, 즉 SPT의 page를 생성해준다.
munmap()
void munmap (void *addr);Unmaps the mapping for the specified address range addr, which must be the virtual address returned by a previous call to mmap by the same process that has not yet been unmapped.
지정된 주소 범위
addr에 대한 매핑을 해제합니다.
addr은 아직 unmapped 되지 않은 동일한 프로세스에서 이전 호출로 반환된 가상 주소여야 합니다.
All mappings are implicitly unmapped when a process exits, whether via
exitor by any other means. When a mapping is unmapped, whether implicitly or explicitly, all pages written to by the process are written back to the file, and pages not written must not be. The pages are then removed from the process's list of virtual pages.프로세스가 종료될 때,
exit을 통해든 다른 방법으로든 모든 매핑은 암묵적으로 매핑 해제됩니다. 매핑이 해제되면 암묵적이든 명시적이든 프로세스에 의해 작성된 모든 페이지가 파일에 다시 기록되며, 작성되지 않은 페이지는 다시 기록되어서는 안 됩니다. 그런 다음 해당 페이지는 프로세스의 가상 페이지 목록에서 제거됩니다.
Closing or removing a file does not unmap any of its mappings. Once created, a mapping is valid until munmap is called or the process exits, following the Unix convention. You should use the file_reopen function to obtain a separate and independent reference to the file for each of its mappings.
파일을 닫거나 제거해도 매핑을 해제할 수 없습니다. 일단 생성된 매핑은 유닉스 규약에 따라
munmap이 호출되거나 프로세스가 종료될 때까지 유효합니다.file_reopen함수를 사용하여 각 매핑에 대해 파일에 대한 별도의 독립적인 참조를 얻어야 합니다.
f two or more processes map the same file, there is no requirement that they see consistent data. Unix handles this by making the two mappings share the same physical page, and the mmap system call also has an argument allowing the client to specify whether the page is shared or private (i.e. copy-on-write).
두 개 이상의 프로세스가 동일한 파일을 매핑하는 경우 일관된 데이터를 볼 필요가 없습니다. 유닉스는 두 매핑이 동일한 물리적 페이지를 공유하도록 하여 이를 처리하며, mmap 시스템 호출에는 클라이언트가 페이지가 공유되는지 비공개인지(i.e. copy-on-write) 지정할 수 있는 인수도 있습니다.
오케잇
얘도 system call이다.
system call을 먼저 등록하고, do_munmap()을 구현하자.
munmap()
case SYS_MUNMAP:
munmap(f->R.rdi);
break;
...
void munmap(void* addr) {
lock_acquire(&filesys_lock);
do_munmap(addr);
lock_release(&filesys_lock);
}별 거 없다.
바로 do_munmap()으로 가자.
do_munmap()
여기에서는 어떤 작업이 수행되어야 할까?
고민한 지점이 있다.
분명 위에서 mmap()을 구현했을 때, file 크기에 따라서 여러 page에 매핑될 수 있다고 했다.
그런데 이 여러 page의 어떠한 주소로 do_munmap()이 호출되었다고 하더라도 관련된 모든 page를 unmapped해주어야 한다.
고유의 번호를 매겨야 할까? 고민했는데 git book을 확인했더니 해답을 보다 쉽게 떠올릴 수 있었다.
must be the virtual address returned by a previous call to mmap
mmap system call에서 반환된 그 address가 인자로 온다고 보장한다.
그 address는 첫 번째 페이지의 시작 주소이다.
그러면 우리가 필요로 하는 정보는 단 하나다.
페이지가 총 몇개냐?
이는 page 구조체에 저장하기도 하던데, 나는 file 구조체에 aux와 같이 저장해줬다.
또 하나 더 고려해줄 것이 있다.
all pages written to by the process are written back to the file, and pages not written must not be.
프로세스에 의해 쓰여진 모든 페이지는 write back 되어야 한다.
하지만 쓰여지지 않은 페이지는 write back되어서는 안 된다.
이를 판단할 수 있는 방법은
pml4_is_dirty 매크로로 반환되는 dirty bit이다.
pml4 포스팅에서 잠깐 다뤘는데, 이 dirty bit는 수정되었는지 여부를 저장하는 bit이다.
0이면 수정되지 않음을, 1이면 수정됨을 의미한다.
이 bit를 변경하는 주체는 cpu이다. cpu가 file에 write를 하면 dirty bit를 1로 수정한다.
우리는 munmap 시스템콜에서 dirty bit가 1일 때, write back 해주면 된다.
void
do_munmap(void* addr) {
/* 'addr'은 mmap()에서 반환된 첫 번째 페이지의 시작 주소 */
struct thread* curr = thread_current();
struct page* p = spt_find_page(&curr->spt, addr);
if (p == NULL) return;
for (int i = 0; i < p->file.page_cnt; i++) {
// dirty bit 확인하고 원본에 반영
if (pml4_is_dirty(curr->pml4, p->va)) {
file_write_at(p->file.file, addr, p->file.read_bytes, p->file.offset);
pml4_set_dirty(curr->pml4, p->va, 0);
}
pml4_clear_page(curr->pml4, p->va);
addr += PGSIZE; // 연속된 다음 페이지로 이동
}
}이렇게 해주면 된다!
file_backed_initializer()
do_mmap() 함수에서 추가해준 aux는 lazy loading이 되며 uninit_initialize()를 거쳐서 file mapped page의 initializer 함수에 도달한다.
file mapped page에서 초기화해주어야 하는 것이 뭐가 있을까?
file의 정보가 필요할 것이다.
그리고 위에서 언급한 page의 개수의 정보도 필요할 것이다.
file_page 구조체를 먼저 수정해주자
- struct file_page
struct file_page {
struct file* file;
off_t offset;
size_t length;
int page_cnt;
};- file_backed_initializer
bool
file_backed_initializer(struct page* page, enum vm_type type, void* aux) {
/* Set up the handler */
page->operations = &file_ops;
struct file_page* file_page = &page->file;
struct vm_aux* vm_aux = (struct vm_aux*)aux;
file_page->file = vm_aux->file;
file_page->offset = vm_aux->ofs;
file_page->read_bytes = vm_aux->read_bytes;
file_page->page_cnt = vm_aux->page_cnt;
// printf("** file_backed_initializer -> read_bytes: %d\n", vm_aux->read_bytes);
return true;
}이렇게 추가해준다.
file_backed_destroy()
file backed page를 destroy해주는 함수이다.
dirty bit를 확인하고 write back 해준다.
static void
file_backed_destroy(struct page* page) {
struct thread* curr = thread_current();
if (page->frame && pml4_is_dirty(curr->pml4, page->va)) {
file_write_at(page->file.file, page->frame->kva, page->file.read_bytes, page->file.offset);
}
}이는 위에서 구현한 do_munmap()의 절차와 동일하게 느낄 수 있다.
munmap은 system call이고 file_backed_destroy()는 file backed type의 page일 때 매핑되는 destroy 함수이다.
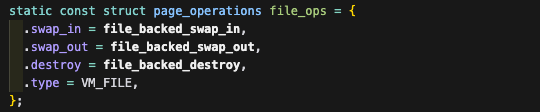
destroy는 여기에서 쓰인다!
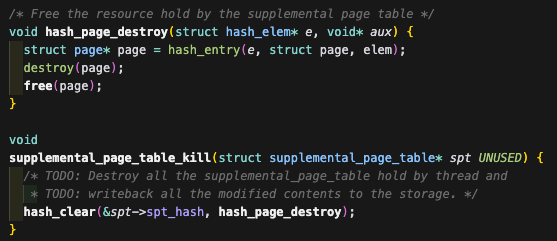
SPT를 삭제할 때 destroy를 호출한다.
munmap 시스템콜과 분리하여 생각하자.
여기까지가 초기 아이디어이다.
FAIL tests/userprog/fork-read
FAIL tests/vm/pt-write-code2
FAIL tests/vm/page-merge-par
FAIL tests/vm/page-merge-stk
FAIL tests/vm/page-merge-mm
FAIL tests/vm/mmap-write
FAIL tests/vm/mmap-exit
FAIL tests/vm/mmap-clean
FAIL tests/vm/mmap-inherit
FAIL tests/vm/mmap-off
FAIL tests/vm/mmap-kernel
FAIL tests/vm/swap-file
FAIL tests/vm/swap-anon
FAIL tests/vm/swap-iter
FAIL tests/vm/cow/cow-simple
15 of 141 tests failed.15 filed로 나름 성공적인 첫 시도였다.
(물론 첫 시도는 아니고 여기까지도 수많은 디버깅을 거치긴 함ㅜ)
이후에는 테스트 케이스 단위로 코드를 수정했다.
머리털 빠지게 하나 수정하면 10개가 터지고.. 하나 수정하면 2개가 터지고.. 이런 과정을 수없이 반복했다.
우선 fork-read 를 수정해보기로 한다.
'fork-read' pass
결론은 supplemental_page_table_copy() 함수의 문제이다.
(이를 발견하기까지 엄청 오랜 시간이 걸렸다.. 디버깅 끝에 lazy_load_segment 함수에서 어떤 변수가 음수 값을 가지는 문제를 발견했다. 자세한 건 오래돼서 기억이 휘발됐다ㅠㅠ)
여튼
SPT를 copy하는 과정은 fork와 함께 이루어진다.
이 때,
-
부모 프로세스가 참조하는 file 객체를 그대로 자식 프로세스에 전달하는 점이 첫번째 문제였다.
-
두번째 문제는 malloc으로 할당한 aux를 자식 프로레스에 그대로 전달한다는 점이었다.
이는 어느 한 프로세스에서 load가 완료된 이후 aux를 free해주면 다른 프로세스에서 load할 수 없다는 문제가 생긴다.
- file → reopen으로 독립적인 mapping을 해준다.
- aux → 새롭게 malloc 할당을 해준다.
위의 방법으로 문제를 해결할 수 있겠다.
bool
supplemental_page_table_copy(struct supplemental_page_table* dst UNUSED,
struct supplemental_page_table* src UNUSED) {
...
struct vm_aux* aux = (struct vm_aux*)src_page->uninit.aux;
struct vm_aux* dst_aux = malloc(sizeof(struct vm_aux));
if (dst_aux == NULL) return false;
dst_aux->file = file_reopen(aux->file);
if (dst_aux->file == NULL) {
free(dst_aux);
return false;
}
dst_aux->ofs = aux->ofs;
dst_aux->read_bytes = aux->read_bytes;
dst_aux->zero_bytes = aux->zero_bytes;
dst_aux->page_cnt = aux->page_cnt;
if (!vm_alloc_page_with_initializer(src_type, upage, writable, init, dst_aux)) {
...
'pt-write-code2' pass
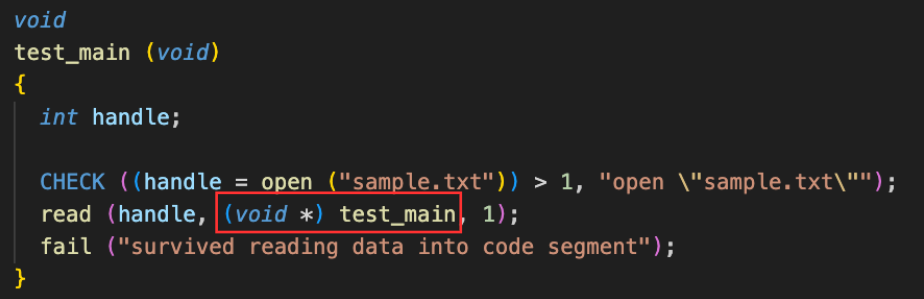
이 테스트는 'test_main 의 위치에 sample.txt 파일을 읽으려 했을 때,
exit(-1) 비정상적인 종료를 시키는가?'를 확인한다.
code segment에 접근하려 했을 때
exit(-1)로 종료되어야 한다.
(pt-write-code2) begin
(pt-write-code2) open "sample.txt"
pt-write-code2: exit(-1)write 권한을 추가로 확인해주어야 한다.
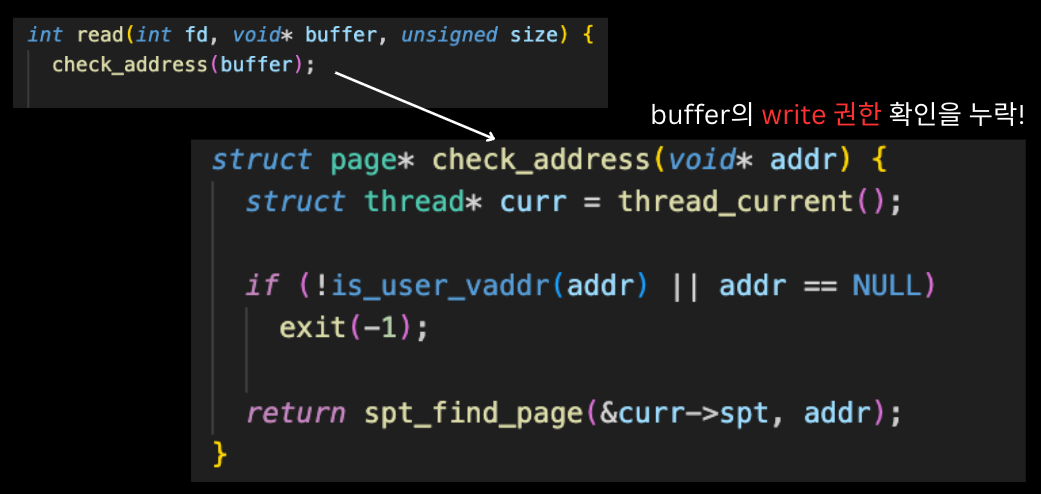
아래와 같이 system call에서 buffer의 check 함수를 수정해주었다.
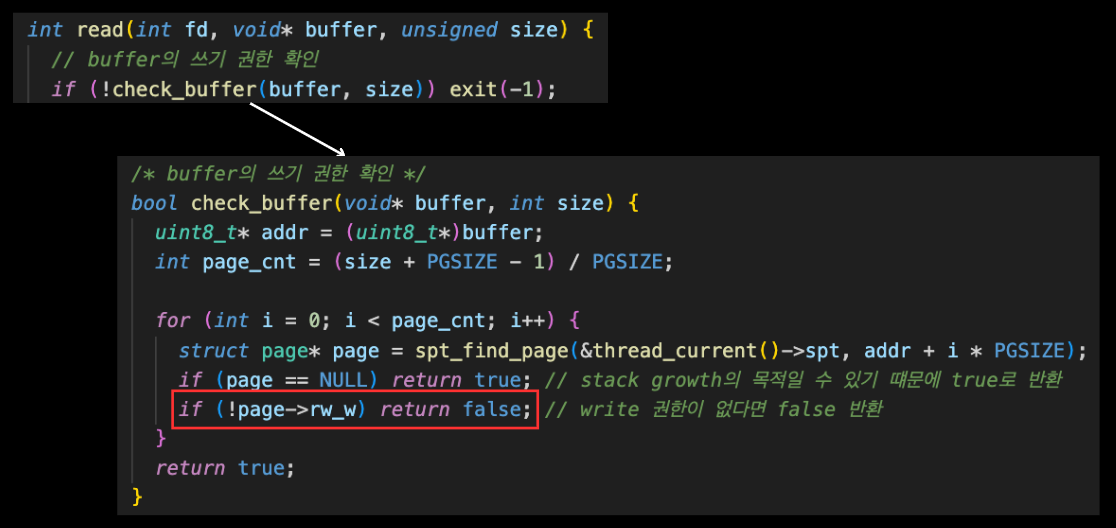
'page-merge-*' pass
이 테스트는 'race condition을 잘 해결하였는가'를 확인한다.
부모가 자식을 생성하고 같은 파일에 접근했을 때 의도적으로 race condition을 유발한다.
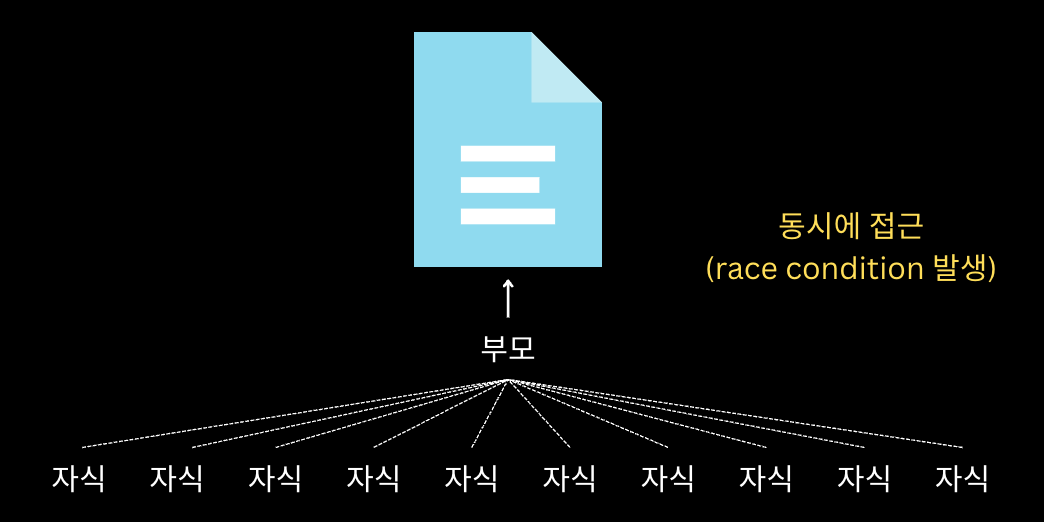
해결 방법은 file system에 접근하는 모든 시점을 lock으로 제어하는 것이다.
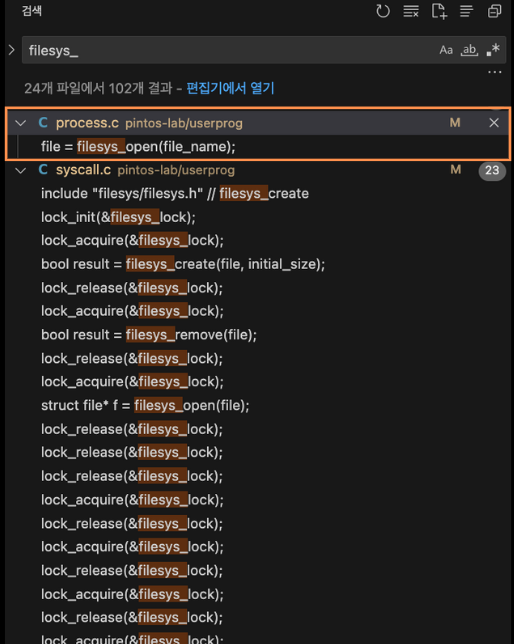
전체 파일에서 찾아보았을 때, syscall은 당연히 전부 lock을 걸어주었으며 딱 하나의 파일에서 file system에 접근한다.
process.c 파일의 load 함수이다.
여기에도 system call에서 사용한 filesys_lock을 걸어준다.
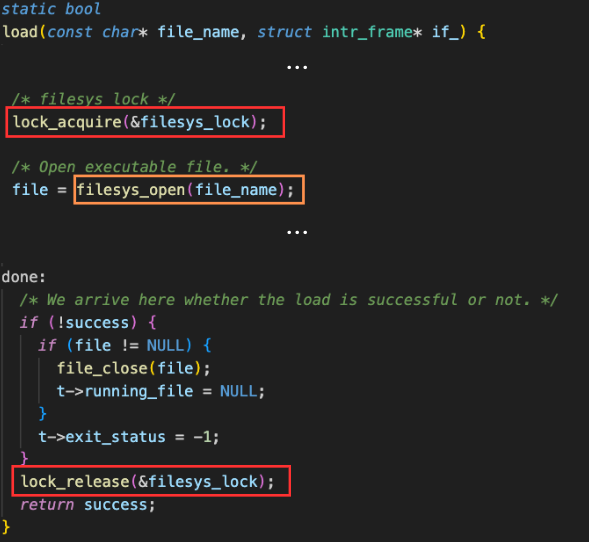
이렇게 말이다.
그러면 비로소 4개의 merge-* 테스트가 통과되는 것을 확인할 수 있다.
결국에는 4 failed로 마무리다.
FAIL tests/vm/swap-file
FAIL tests/vm/swap-anon
FAIL tests/vm/swap-iter
FAIL tests/vm/cow/cow-simple
4 of 141 tests failed.몇몇의 테스트들은 포스팅에서 다루지 않았다.
매우 사소했던 실수였었다.
kernel 영역을 length까지 확인해주지 않았다거나,
vm type을 VM_TYPE매크로로 감싸주지 않아서 의도와 다른 값을 전달하게 되었다거나 하는 자잘한 실수였다.
물론 이것들 모두 정말정말 어려운 디버깅 끝에 해결했지만 주요 수정사항만 다룬다..
다른 테스트 수정 사항은 깃허브 커밋으로 남겼으니 참고 바란다.
https://github.com/hyeona01/week12-pintos-lab/issues/21
이번 vm 프로젝트는 스스로 멱살잡고 뺨 때려가며 이악물고 해냈다.
지나고 보니, 어느 주차 보다도 스스로가 대견하다.
긴 5주동안 지칠대로 지친 나를 잘 달래는 일이 어려웠다.
모두가 그랬던 것 같다.
지긋지긋한 커널 패닉, 디버깅 지옥, 아무런 프린트도 찍히지 않고 종료되는 테스트들,
전부 아찔했지만 하나씩 하나씩 하다보니 이번에도 어느정도 해냈다.
swap까지 했다면 좋았겠지만, 이 또한 디버깅에 막혀있는 상태다. 아쉽다!
그래도 고생했다!
핀토스 안뇽! 또? 보자?

