여러 블로그를 참고해도, GPT를 괴롭혀도, 유튜브를 보아도 손 닿지 않는 등어리가 늘 가려웠다.
오늘 좋은 기회로 동석 코치님께 VM의 구조에 대하여 설명을 듣게 되었다.
가려운 곳을 벅벅 긁어주시고 떠나셨다..
이런 Pintos의 설계를 코드를 보고 이해하셨다고 했는데, 그저 존경하게 된다.
수만 줄의 코드를 보고, 머릿 속으로 그림을 그리고 그 그림을 쉬운 말로 설명할줄 알려면 얼마나 많은 노력이 필요할까?
훗날에는 나도 그런 개발자가 될 수 있으리라 믿어, 설레면서도 도파민이 팡팡 터지는 시간이었다.
내가 바라본 Pintos는 여전히 마술같았다.
물론, 커널이 시작되는 init.c 파일부터 user program이 수행되는 흐름, system call까지 구현하였지만 여전히 그려지지 않았던 그림이 있다면 Virtual Memory가 아닐까 싶다.
그 부분이 큰 밑그림이었기에, 아는 듯 모르는 듯 마술같다.
.
나름대로 이해해보겠다고,
이번 VM 주차에 접어들어서는 책을 몇 시간을 들여다보기도, 코드를 다시 뜯어보기도 하였다.
Pintos 질의응답방에 올라오는 다른 반 동료 분들의 VM 구조를 촘촘히 살펴보기도 했다.
나는 내 것이 아닌 지식은 잘 삼키지 못한다.
내 것인 지식만 삼키고 그릴 수 있는 사람이다.
그래서인지 다른 이들이 그린 구조를 이해할 수 없었다. 구글링을 해보았을 때도 전부 다른 VM 구조로 더 혼란이 가중되었다.
그래도 각 주차의 코드를 구현할 수 있었던 건,
각 부분, 부분을 잘 이해했기 때문이라고 생각한다.
project 1에서는 thread 구조를 이해하는 것이 중요했고,
project 2에서는 process, userprogram, system call을 이해하는 것이 중요했다.
어쩌면 project 3의 virtual memory에 와서야 이 전체적인 구조를 고찰하고 이해하게 되는 것이 당연할지도 모르겠다.
하지만 지금 생각해보면, 이 구조도 모르고 어떻게 지금까지의 테스트를 통과시켰지????
의문이 든다. 완전 럭키현아였던 것
여튼 내가 오해했던 VM, 외면했던 VM을 정리해보고자 한다.
오늘 느낀건데, Pintos에 정답은 설계자만 알고있지 않을까??? 설계자를 제외한 이들이 추측한 글들은 거의 대부분의 오류를 가지고 있을 것 같다.
그래서 서두에 언급한다.
이 글은 틀릴 가능성이 높다.
(물론 동석코치님은 틀리지 않으시겠지만, 내가 그것을 100% 이해했다고 생각하지 않는다.)
.
.
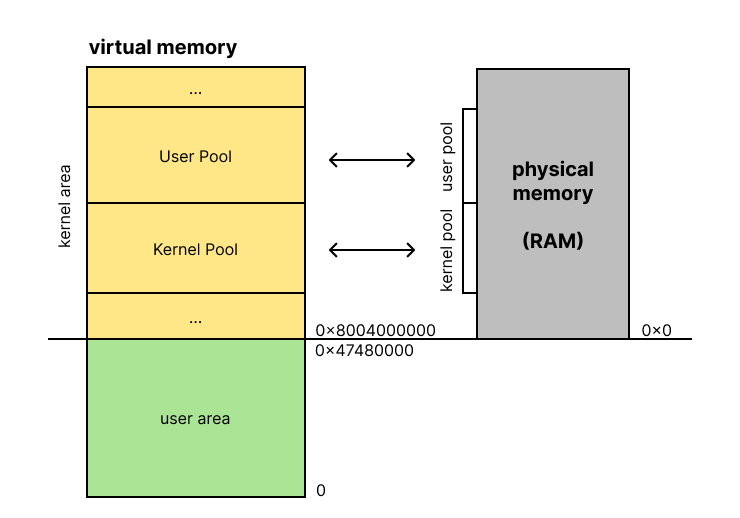
Pintos의 큰 그림에 관련된 이야기다.
- thread는 어디에 존재하는지?
- physical memory와 kernel area의 1:1 매핑은 도대체 어디부터 어디까지인지?
- 그렇다면 user area의 메모리는 어떻게 physical memory에 매핑되고 관리되는지?
- 실제로 va에서 pa로 번역하는 하드웨어(mmu)는 어떤 과정으로 번역하는지?
- 우리는 그 하드웨어를 위해 어떤 일들을 해야하는지?
- 하드웨어와 소프트웨어 코드 조각을 어떻게 분리하고 이해해야 하는지
등을
정돈되지 않은 서툰 말로 풀어나갈 예정이다.
thread는 어디에 존재하나?
사실 깊이 고민해본 적도 없다.
근데 아마 user area의 시작 주소가 곧, thread 구조체의 포인터 주소가 아닐까?(아니다.)
코드를 한 번 보자.
thread는 kernel mode에서 생성된다. thread_create()라는 루틴에 의해 말이다.
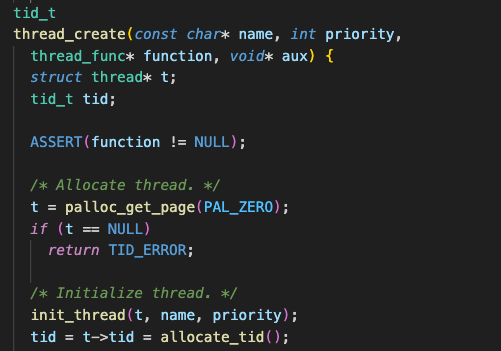
이렇게 palloc_get_page 를 통해 4KB만큼의 공간을 할당받는다.
반환 받은 VA를 t라는 포인터가 가리키게 되고,
t->tf라는 thread 내부의 intr_frame 구조체에 시작될 주소, 인자 등을 적절한 레지스터에 담으며 초기화 작업을 한다.
그리고 CPU scheduling에 의해 running 상태로 변환될 것이다.
그러면 이 thread, 4KB만큼의 공간은 도대체 어디에서 부여받은 것일까?
palloc_get_page()
palloc_get_page가 담당한다.

결국은 아래 루틴으로 딸깍, 메모리 할당!
이렇게 된 것인데,
어떻게 동작하는 것일까?
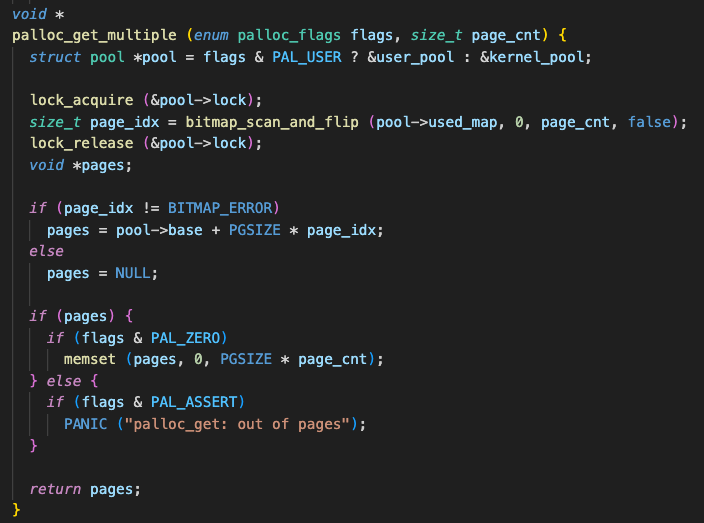
우선 pool이 두 가지로 나뉜다.
- user pool
- kernel pool
그리고 그 둘은 사용하는 physical memory 영역도 다르다.
그래서 os의 요청으로 해당 pool의 해당 size 만큼의 빈 공간을 할당해주고, 그 포인터를 넘겨주는 것이다.
참고로 두 영역은 여기에서base_mem,ext_mem의 값을 활용하여 거의 동일한 크기로 나눈다.
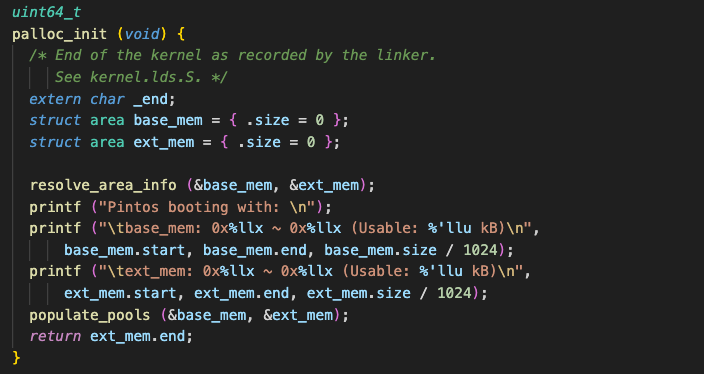
이 때, 그 사실을 기억해야 한다.
Kernel area는 physical memory 와 1:1 매핑된다는 사실!
따라서 이렇게 이해하면 좋다.
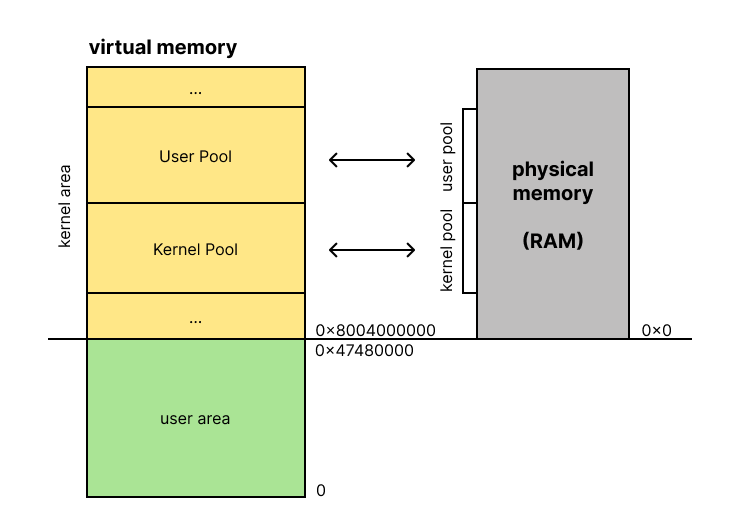
이걸 보면 또 연결되는 개념이 있다.
physical memory는 100%의 공간을 프로세스를 위해 사용할 수 없다고 배웠다.
그 이유가 여기에 있는 것이다. kernel의 코드, bss, stack 등의 영역, 혹은 boot strap의 영역 등이 차지하는 일부분을 제외해야 한다.
다시 본론으로 돌아가서,
그래서 thread는 어디에 저장되는 걸까??
thread_create()를 다시 보면 이렇다.
t = palloc_get_page(PAL_ZERO);4KB만큼의 공간을 kernel pool에서 받아오겠다는 의미이다.
(PAL_USE flag가 없다면 kernel pool로 간주한다.)
결국, thread 구조체는 kernel area안에서도, kernel pool에 위치하게 된다!
조금만 더하자면,
위에서 잠깐 살펴본 palloc_get_multiple() 함수를 통해 physical memory의 공간을 할당받게 되고,
이렇게 할당받은 공간은 결국, pml4(page table)에 기록되어, 주소 변환을 담당하는 하드웨어가 잘 찾아갈 수 있게 된다.
단순히 malloc의 대체품이 아니었음을.. ㅠ
(pintos에서 malloc은 heap segment가 아닌 pool을 통해 구현된다.)

context switching은 어떻게 가능한가?
thread의 연장선에 있는 내용이다.
Pintos는 RR 스케줄링을 채택하며, 일정한 time slice를 기준으로 preemptive 방식으로 CPU 제어권을 thread에 부여한다.
하지만 CPU는 스스로 다음 thread의 실행 지점을 찾을 수 없다.
CPU는 철저히 “지시된 주소” 에 따라 명령어를 수행하는 구조이기 때문이다.
따라서, 다음에 실행될 thread의 상태(실행 위치 등)를 어디엔가 저장해 두어야 한다.
Context를 저장하는 곳, register
CPU는 time slice에 따라, 혹은 프로세스가 종료됨에 따라, 혹은 인터럽트에 따라 스케줄링되는데
이 때, 다음에 실행될 thread의 수행 위치를 기억하려면 알다시피 레지스터에 저장을 한다.
PC 역할을 하는 rip로 시작 주소를 포인트하고, 각 용도에 맞는 레지스터를 통해 ELF 파일을 로드하여 수행할 수 있다.
근데 kernel pool에 존재하는 thread에서, 4KB 중 어디에 저장되어 있는지도 모르는 레지스터를 어떻게 참조할 수 있겠나?
이를 위해 thread 구조체의 메모리 구조는 정해져있다.
context switching이 이루어지는 시점에서 레지스터를 불러오고, 그 레지스터를 기반으로 원하고자하는 시점에서 다시 수행할 수 있도록 말이다.
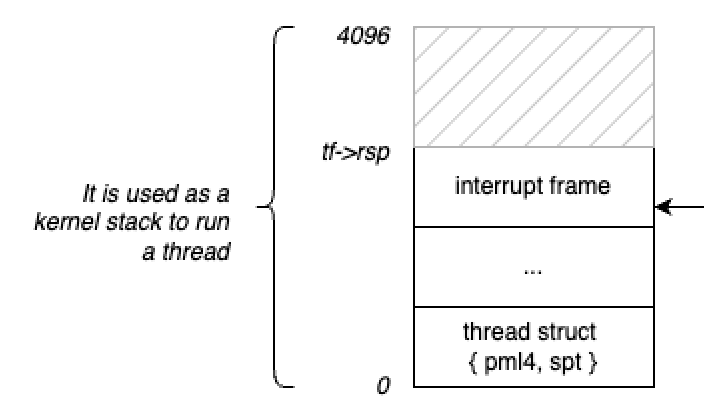
출처: 이동석 코치님
이렇게 thread 구조체의 rsp는 커널 스택의 top을 가리키며,
해당 스택에는 interrupt frame 및 레지스터 정보가 저장되어 있다.
이후에는 pml4/spt의 정보를 통해 해당 pml4를 CPU의 CR3 레지스터가 참조하게 하면서, 해당 프로세스의 page table이 활성화된다.
user program이 사용하는 메모리는 어떻게 매핑되는가?
그렇다면!! 이제 user program이 사용하는 메모리는 어떻게 매핑되는지 궁금해야 한다.
user pool 또한 kernel 영역에 관리하고 있지 않은가?
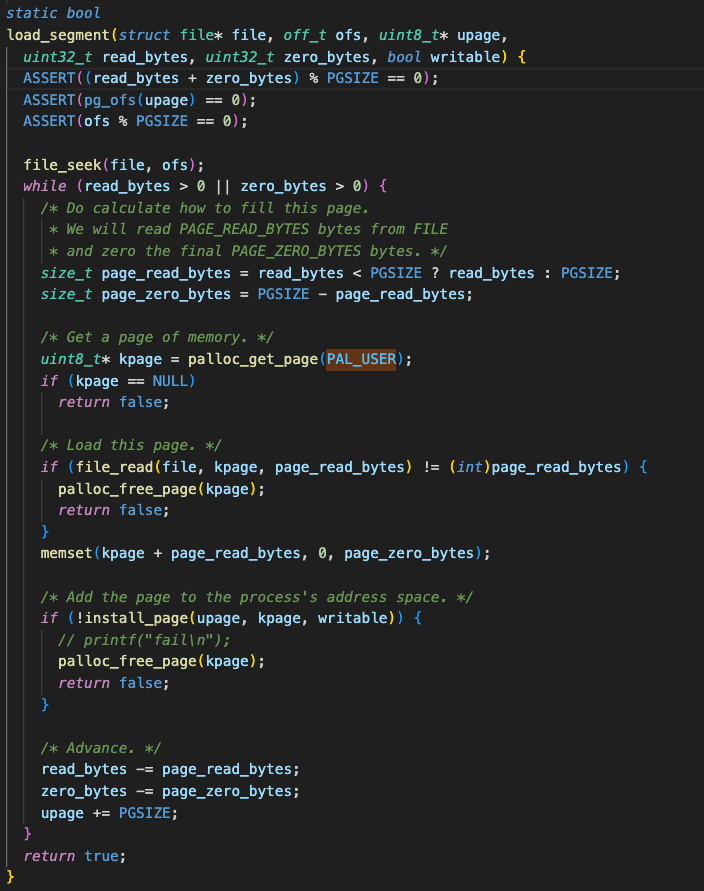
다음과 같이 user pool에서 4KB 메모리 공간을 할당 받는다.
uint8_t* kpage = palloc_get_page(PAL_USER);그리고 절대 빠져서는 안 될,
install_page 를 호출하여 pml4에 해당 va를 매핑하고있는 것을 확인할 수 있다.
그렇다면 load_segment가 호출되는 시점은 언제인가?
process_exec → load → load_segment
즉, 프로세스가 실행될 때이다.
프로세스에 어떤 파일이 실행될 때, os는 user pool에서 4KB(1 page) 만큼의 메모리 공간을 할당해준다. 그리고 할당받은 physical page는 반드시 pml4를 통해 virtual address에 매핑되어야 한다. 그래야 주소 변환으로 옳은 리소스를 참조할 수 있다.
따라서,
위의 유저 영역 virtual address는 해당 메모리 공간을 접근하기 위한 사용자 입장의 주소이며,
이 주소는 실제 physical memory(RAM)의 프레임과 pml4에 의해 매핑된다.
추가로,
유저가 접근할 수 없는 커널 영역의 virtual address는 KERNEL_BASE를 기준으로 구성되어 있으며,
Pintos에서는 커널 가상 주소를 physical address와 1:1로 매핑되도록 페이지 테이블을 구성하였다.
따라서, KERNEL_BASE를 빼면 해당 커널 주소가 참조하는 실제 physical address를 유추할 수 있다.
이렇게 user pool로 할당받은 메모리 공간에서 스택을 구성하고, ELF 파일을 로드하고, 실행한다.
Project2까지는 어떻게 메모리가 할당된 것인가?
사실 이 부분이 킥이다.
그래서 Project3에서는 뭐 어떻게 하라는건데?
이런 VM 구조도 잘 몰랐는데도 왜 Project2까지는 잘 되었던 건데?
Project3까지 왔다면 무조건 볼 수 밖에 없는 매크로가 있다.
#ifndef VM
...
#else
...
#else 로 감싸진 코드는
vs code에서 딤처리 해주기 때문에 그저 모르는 척 지나갔었다.
이렇게 말이다.
이것이 바로, Project2까지 우리가 physical memory를 할당받고, pml4에 매핑해주는 작업을 별도로 신경써 주지 않아도 실행되었던 이유다.
Project2에서는 메모리를 할당하고 pml4에 매핑한느 작업을 명시적으로 수행하였다.
위에서 살펴본대로,
Project2에서는 코드가 메모리 접근 전에palloc_get_page()로 물리 메모리를 미리 할당하고,
install_page()로 PML4에 직접 매핑까지 수행해주었다.
이로 인해 메모리 접근이 발생해도 page fault 없이 바로 접근이 가능했던 것!!!
VM 모드가 아니라면, 우리가 알고있는 위에서 본, 그 코드들이 수행된다.
가장 중요하게 변경될 함수는 두 개다.
load_segment(), setup_stack() 이다.
기존에는 load_segment()가 호출됨과 동시에 physical memory에 4KB 만큼을 할당받았다.
이 페이지가 실제로 사용되는지 아닌지는 중요하지 않다.
모든 호출에 의해 메모리를 할당하고 pml4에 매핑한다.
그렇게 되면,
메모리 낭비가 심해지겠지?
RAM 보다 큰 용량의 프로그램을 실행도 못할 것이다.
이를 개선하기 위해서 등장한 방법이 있다.
demand paging 이다.
demand paging?
한 번에 전체 메모리를 로드하지 않고,
필요한 부분을 필요할 때 physical memory에 로드하는 방법이다.
따라서, physical memory 보다 큰 사이즈의 프로그램도 정상적으로 동작시킬 수 있는 것이다.
실제로 필요할 때만 physical memory에 할당하는 방법(demand paging)을 사용해야만 우리가 원하는 '무한대로 메모리 사용하기 쇼'를 성공할 수 있다.
물론, 이 방법으로만 성공하는 것은 아니다. physical memory의 공간이 부족할 때는 적절한 알고리즘으로 페이지를 교체해야한다.
여튼, 실제로 사용할 때만 physical memory 공간을 내어주는 것을 바로 이번 Project3에서 구현해야한다.
Pintos에서는 이 방법을 사용하여 구현한다.
Supplemental Page Table: SPT
SPT는 pml4 즉, page table만으로는 demand paging을 구현할 수 없기 때문에, 이를 보조하는 역할을 하기 위해 존재한다.
demand paging을 구현하려면, 최초의 메모리 접근 시점에서 page fault를 발생시키고, physical memory와 mapping(pml4 등록) 해야 한다.
따라서, SPT는
해당 virtual address가 어떤 종류의 페이지인지 (file-backed인지, anonymous인지 등), 그리고 이를 복원하는 방법이 무엇인지 등의 정보를 저장하고 있다.
이를 알아야 하는 이유는 이전 포스팅에서 더 자세히 다뤘다.
간단히만 언급하겠다.stack 영역으로 예를 들자.
이는 file system에서 불러오는 segment가 아니라, 런타임에 생성되기 때문에 file system에서에서 불러오는 code 영역 등과 같은 루틴으로 처리할 수 없다.
그렇기에 각 type 별로 pml4에 매핑시키는 루틴을 달리 처리해주어야 한다.
그래서 우리는 Project 3의 '무한 메모리 쇼'를 성공시키기 위한 VM를 잘 구현해야 한다.
load_segment() 호출 시점에서는 SPT에만 정보를 업데이트하고,
실제로 메모리에 접근하는 시점에 page fault가 발생한다. 이 때의 루틴에서 vm_claim_page()가 호출되며 physical memory의 비어있는 frame을 확인하고, 그 frame과 해당 va를 pte에서 매핑해준다.
그런 lazy_load_segment() 루틴에 따라, 요구된 file을 로드하거나, 0으로 초기화하거나 하는 등 page type에 맞는 처리를 해주게 될 것이다.
그러면 mmu는 어떻게 주소 번역을 할까?
소프트웨어로 page table을 참조하여 PA로 변환하는 일은 생각보다 오랜 시간이 걸린다.
무한 메모리 쇼를 위해 page table을 통해 VM을 구현하였지만 page table 자체의 크기도 커지고, 그 모든 요소를 탐색하여 VA에서 PA로 변환하는 과정이 성능을 오히려 저하한다.
그래서 하드웨어의 힘을 빌리기로 한다.
이 주소 변환을 돕는 하드웨어가 바로 mmu이다.
mmu는 단순하게 일한다.
CPU에게 주소 변환 신호를 받으면, 곧바로 Page Table로 간다. 우리가 구현 중인 x84-64 Pintos에서는 pml4로 가겠지?
그런 다음, 그 VA의 VPN을 인덱스로 pml4 Table에서 PTE를 찾게 되고 PFN을 얻는다.
Page Fault
mmu가 VA를 가지고 pml4로 갔는데, 만약 매핑된 PA가 없다면?
mmu는 CPU에 page fault 예외를 발생시켜 커널 예외 핸들러로 진입하게 만든다.
이 때는 확인해야할 것이 하나 있다.
VA가 유효한가? address가 ① 유효한 범위 내에 있고, ② VA를 SPT에서 찾을 수 있다면 유효한 것이다.
그렇지 않으면 유효하지 않은 VA로의 접근이기 때문에 프로세스를 종료하는 등의 루틴을 수행한다.
유효하다면?
mmu를 위해 우리는 Page Table, pml4를 업데이트 해주어야 한다.
우선, 실제 physical memory의 빈 frame을 찾고, 그 frame의 physical address와 virtual address를 매핑하여 pml4에 저장한다.
pml4를 관리하는 일은 os가 담당한다.
mmu 관점
즉, mmu는 pml4밖에 모른다. 근데 빠르다.
VA를 받아서 pml4 Table로 갔다.
오잉 매핑된 PA가 없다.
잘못된 접근이다.
Page fault를 Kernel에 반환한다.
(lazy loading의 의도이든 뭐든 상관없다.)
OS(kernel) 관점
os는 속도가 빠른 mmu의 도움을 받아야 하므로, pml4를 잘 관리해야 한다.
더하여 laze loading(demand paging)을 하기 위해서
OS는 SPT를 추가로 관리하며, mmu가 va와 매핑되는 pa 정보를 pml4에서 찾을 수 없어 page fault를 반환하는 순간을 캐치해야 한다.
캐치한 이후, VA가 유효한지 확인하고 유효하다면 SPT를 참조하여 physical memory와 새롭게 매핑해주어야 한다.
참고로, SPT에 추가되는 시점은 process가 최초로 execute되고 load되는 시점이다.
즉, OS는 lazy loading을 위해 의도적으로 VA를 미리 매핑하지 않음으로써 page fault가 발생하고, 이에 대한 적절한 처리를 통해 비로소 lazy loading이 가능케 한다.

항상 양질의 포스팅 잘 보고 있습니다! 🙏