
기본 키 매핑 방식
기본 키를 매핑하는 방법은 두 가지가 있다.
- 직접 할당 : @Id만 사용한다
- 자동 생성 : @GeneratedValue와 속성 값을 사용한다
기본 키 자동 생성 전략
IDENTITY 전략

기본 키 생성을 데이터베이스에 위임한다. MySQL의 방언을 사용하면 AUTO INCREMENT로 기본 키가 생성된다.
이 옵션을 사용하면 엔티티 값을 넣을 때 id 값을 빼도 테이블에 데이터가 INSERT된 후에 후에 PK 값을 자동으로 세팅해 준다.
영속성 컨텍스트에서는 데이터의 PK값으로 관리를 하는데, 그럼 IDENTITY 전략을 사용할 때는 영속성 컨텍스트에서 어떻게 관리가 되는걸까?
JDBC는 INSERT 시점에 생성되는 PK값을 들고오는 동작을 자동으로 실행하기 때문에 영속성 컨텍스트에서 관리할 수 있다.
SEQUENCE 전략
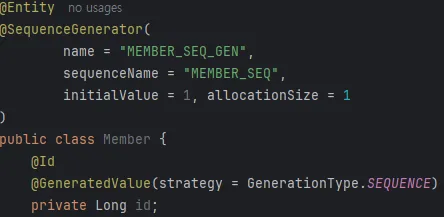
데이터베이스 시퀀스를 사용하여 유일한 값을 기본 키로 생성하는 전략이다.
시퀀스란?
데이터베이스에서 기본 키를 생성하기 위해 사용하며 일련번호를 하나씩 증가 시키며 유일한 값을 생성하는 객체이다.
INSERT 쿼리가 실행될 때 데이터베이스에서 미리 생성된 시퀀스 객체를 가져와 Id 값으로 넣어준다.
PK와 매치되는 변수는 Long 타입 사용이 권장 된다.
속성 값을 통해 매핑할 데이터베이스 시퀀스의 이름, 시작 값 등을 지정할 수 있다.
속성
| 속성 | 설명 | 기본 값 |
|---|---|---|
| name | 식별자 생성기 이름 | 필수 |
| sequenceName | 데이터베이스에 등록되어 있는 시퀀스 이름 | hibernate_sequence |
| initialValue | DDL 생성 시에만 사용됨, 시퀀스 DDL을 생성할 때 처음 1 시작하는수를 지정한다. | 1 |
| allocationSize | 시퀀스 한 번 호출에 증가하는 수(성능 최적화에 사용됨데이터베이스 시퀀스 값이 하나씩 증가하도록 설정되어 있으면 이 값을 반드시 1로 설정해야 한다 | 50 |
| catalog, schema | 데이터베이스 catalog, schema 이름 |
TABLE 전략
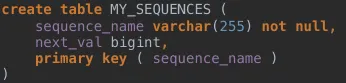
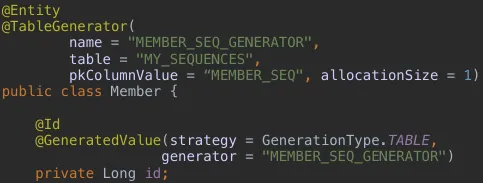
키 생성 전용 테이블을 만들어서 데이터베이스 시퀀스를 흉내내는 전략이다.
오라클의 sequence, MySQL의 auto increment와 같이 기본 키 생성을 위한 테이블을 만들기 때문에, 모든 데이터베이스에 적용 가능하지만 테이블을 하나 더 만들어 사용하기 때문에 성능 문제가 발생할 수 있다.
속성
| 속성 | 설명 | 기본 값 |
|---|---|---|
| name | 식별자 생성기 이름 | 필수 |
| table | 키생성 테이블명 | hibernate_sequences |
| pkColumnName | 시퀀스 컬럼명 | sequence_name |
| valueColumnNa | 시퀀스 값 컬럼명 | next_val |
| pkColumnValue | 키로 사용할 값 이름 | 엔티티 이름 |
| initialValue | 초기 값, 마지막으로 생성된 값이 기준이다. | 0 |
| allocationSize | 시퀀스 한 번 호출에 증가하는 수(성능 최적화에 사용됨) | 50 |
| catalog, schema | 데이터베이스 catalog, schema 이름 | |
| uniqueConstraints(DDL) | 유니크 제약 조건을 지정할 수 있다. |
AUTO 전략
데이터베이스 방언에 따라 지금까지 설명한 전략 중 하나를 자동으로 선택한다.
예를 들어, 오라클은 sequence로 MySQL은 IDENTITY를 선택한다.
권장하는 전략
기본 키 제약 조건
1. null 아님
2. 유일 값이어야 함
3. 불변성
대체 키를 사용하는 것이 권장되는 전략이다.
그 이유는 많은 시간이 지나도 기본 키의 제약 조건을 모두 만족하는 자연 키는 찾기 어렵기 때문이다
만약 사람의 주민 번호를 pk로 사용하는 테이블이 있는데, 데이터베이스에 주민 번호 저장이 금지 된다면 모든 키를 변경해야 한다.
그래서 시퀀스 또는 uuid와 같이 비즈니스와 전혀 관계 없는 대체 키를 기본 키로 사용하는 것이 좋다.
결론적으로,
- Long 타입 사용
- 대체 키 사용
- 데이터베이스에 맞는 키 생성 전략 사용
이렇게 전략을 선택하는 것이 좋다.

천외천...?