‼️ 개인 학습 내용으로, 오류가 있을 수 있습니다.
논문 URL - https://arxiv.org/abs/1810.04805
Title
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
-> BERT : 언어 이해를 위한 Deep 양방향성 Transformer 사전학습 모델
Abstract
- We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers.
-> 우리는 새로운 언어 표현 모델인 BERT(양방향 트랜스포머 기반 인코더 표현)를 소개한다.
-
Unlike recent language representation models (Peters et al., 2018a; Radford et al., 2018), BERT is designed to pretrain deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers.
-> 최근의 언어 표현 모델과 달리, BERT는 모든 층에서 왼쪽과 오른쪽 문맥을 동시에 고려하여, 레이블이 없는 텍스트로부터 딥 양방향 표현을 사전 학습하도록 설계되었다. -
As a result, the pre-trained BERT model can be finetuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial taskspecific architecture modifications.
-> 그 결과, 사전 학습된 BERT 모델은 추가적인 출력 레이어 하나만 더해도, 질문 답변이나 언어 추론과 같은 다양한 작업에 대해 최첨단 성능의 모델을 만들 수 있으며, 작업별로 아키텍처를 크게 수정할 필요가 없다.
-
BERT is conceptually simple and empirically powerful.
-> BERT는 개념적으로 단순하고 실제로 강력하다. -
It obtains new state-of-the-art results on eleven natural language processing tasks, including pushing the GLUE score to 80.5% (7.7% point absolute improvement), MultiNLI accuracy to 86.7% (4.6% absolute improvement), SQuAD v1.1 question answering Test F1 to 93.2 (1.5 point absolute improvement) and SQuAD v2.0 Test F1 to 83.1 (5.1 point absolute improvement).
-> BERT는 11개의 자연어 처리 작업에서 새로운 최첨단의 결과를 달성했다.
Figures
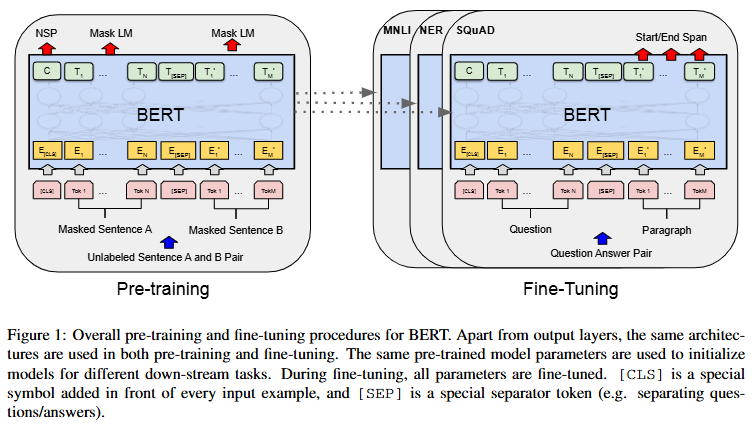
01. BERT 사전 학습 및 미세조정 절차 개요
- 사전 학습 및 미세조정에 동일한 구조가 사용된다.
- 서로 다른 다운스트림 작업(후속 작업)에 대해서도 동일한 사전 학습된 모델 파라미터가 초기값으로 사용된다.
- 미세조정 중 모든 파라미터는 함께 조정된다.
[CLS]는 모든 입력 예제의 앞에 추가되는 특수 기호이며,[SEP]는 질문과 답변을 구분하는 등 구분자 역할을 하는 특수 토큰이다.
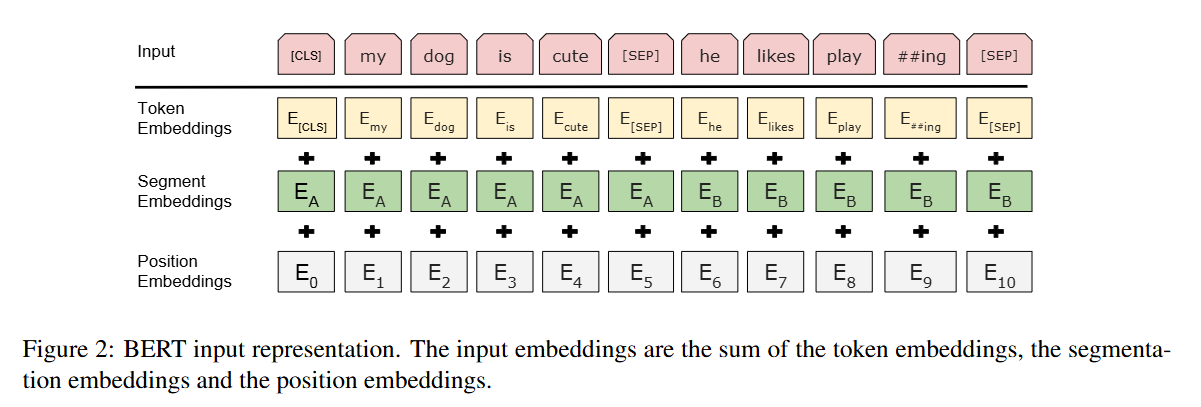
02. BERT 입력 표현
- 입력 임베딩은 token embedings, segmentation embeddings, position embeddings의 합계이다.
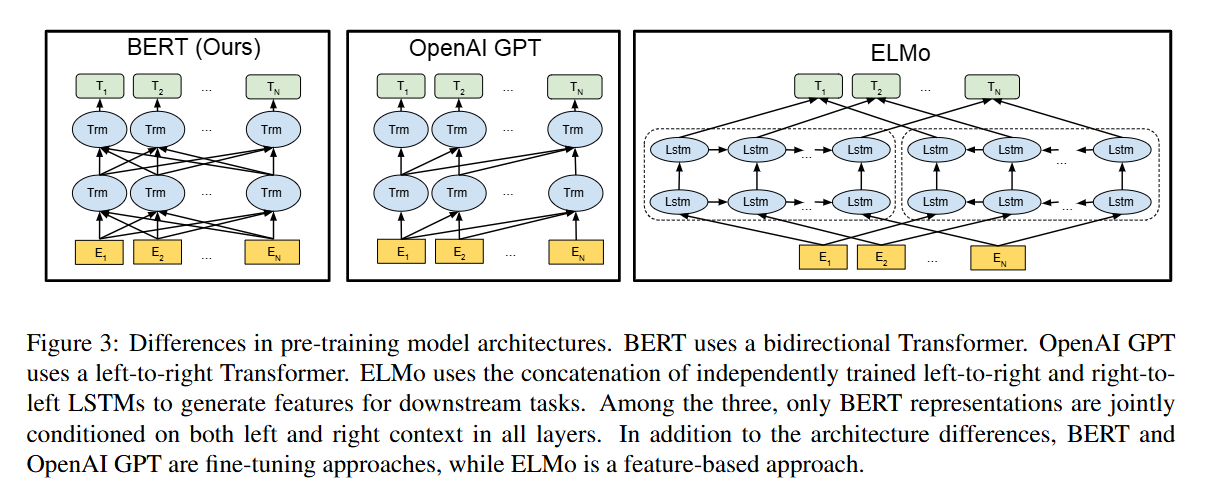
03. 사전 학습 모델별 구조 차이
| Model | Transformer | Approach |
|---|---|---|
| BERT | 양방향 | fine-tuning |
| OpenAI GPT | left -> right | fine-tuning |
| ELMo | left-to-right & right-to-left로 독립적으로 훈련된 LSTM 연결(concat) -> 다운스트림 작업에 활용할 특징을 생성 | feature-based |
+) fine-tuning vs. feature-based
-
파인튜닝 방식은 사전 학습 모델의 가중치를 초기값으로 삼아, 새로운 데이터에 맞게 모델 전체 또는 일부를 추가로 학습한다. 이 과정에서 모델이 해당 작업에 최적화되며, 보통 출력층(분류기 등)을 추가해 학습한다.
-
피처기반 방식은 사전 학습된 모델의 파라미터는 그대로 두고, 입력 데이터를 모델에 통과시켜 얻은 임베딩(특징 벡터)만을 별도의 분류기나 회귀 모델 등에 입력값으로 사용한다. 즉, 사전 학습 모델은 "특징 추출기" 역할만 하며, 본체는 업데이트하지 않는다.
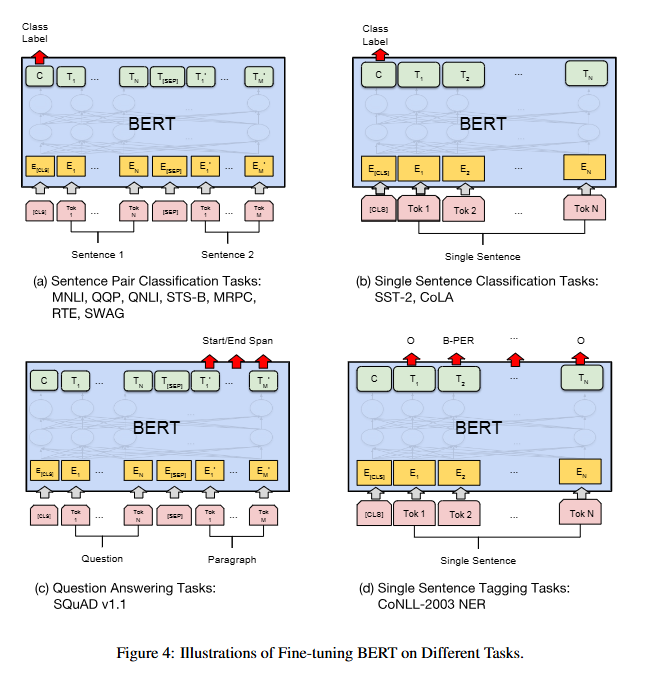
04. 작업별 미세조정 BERT 차이
- (a) : 문장 쌍 분류 작업
- (b) : 단일 문장 분류 작업
- (c) : 질의 응답 작업
- (d) : 단일 문장 태깅 작업
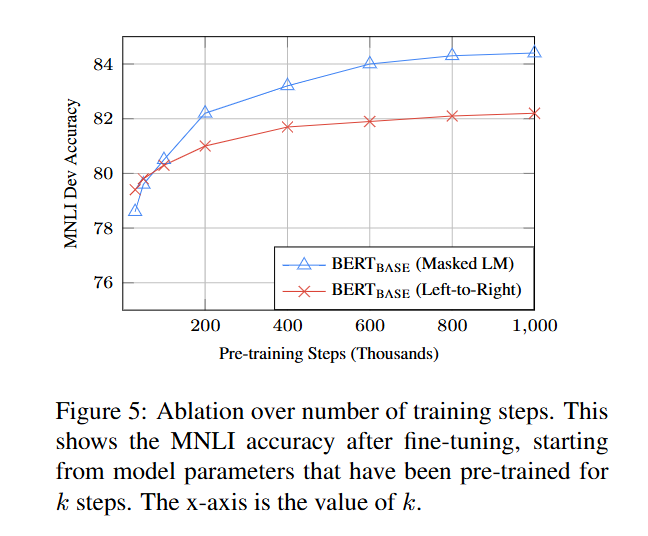
05. 훈련 단계 수에 따른 ablation 실험
-
ablation : 모델의 구성 요소(예: 특정 레이어, 입력 특성, 하이퍼파라미터 등)를 일부러 제거하거나 변경해가며, 그 요소가 모델 성능에 얼마나 기여하는지 분석하는 실험 방법
-
모델 파라미터를 k 단계(x축)만큼 사전 학습한 후 파인튜닝했을 때의 MNLI 정확도(y축)