‼️ 개인 학습 내용으로, 오류가 있을 수 있습니다.
Title
- Consumer Credit Risk Models via Machine-Learning Algorithms
-> ML 알고리즘을 통한 고객 신용 리스크 모델
Abstract
-
We apply machine-learning techniques to construct nonlinear nonparametric forecasting models of consumer credit risk.
-> 우리는 ML 기술을 비선형적 비모수적 고객 신용 리스크 예측 모델에 적용했다.- 비모수 추정(Nonparametric Estimation) : 데이터가 특정 확률 분포(예: 정규 분포)를 따른다는 가정을 하지 않고, 주어진 데이터 자체의 특성을 바탕으로 확률 분포나 함수(확률밀도함수, 회귀함수 등)를 직접 추정하는 통계적 방법
-
By combining customer transactions and credit bureau data from January 2005 to April 2009 for a sample of a major commercial bank’s customers, we are able to construct out-of-sample forecasts that significantly improve the classification rates of credit-card-holder delinquencies and defaults, with linear regression R2’s of forecasted/realized delinquencies of 85%.
-> 주요 상업 은행 고객 거래 데이터와 신용 평가 기관 데이터를 결합(2005년 1월 ~ 2009년 4월)함으로써, 신용카드 보유자의 연체 및 부도 분류율을 유의미하게 개선하는 표본 외 예측을 구축할 수 있었다. 예측된/실현된 연체에 대한 선형 회귀 R2(R-squared)는 85%였다.- R2 score : 회귀 모델의 성능 지표(1에 가까울 수록 설명력이 높다 == 성능 우수)
- Using conservative assumptions for the costs and benefits of cutting credit lines based on machine-learning forecasts, we estimate the cost savings to range from 6% to 25% of total losses.
-> ML 예측에 기반한 신용 한도 축소 비용에 대해 보수적으로 가정할 때, 비용 절감이 총 손실의 6% ~ 25% 범위에 이를 것으로 추정한다.
- Moreover, the time-series patterns of estimated delinquency rates from this model over the course of the recent financial crisis suggest that aggregated consumer credit-risk analytics may have important applications in forecasting systemic risk.
-> 게다가 최근 금융 위기(2008) 동안 이 모델로 추정된 연체율 시계열 패턴은 집계된 고객 신용-리스크 분석이 시스템적 위험 예측에 중요한 역할을 할 수 있음을 시사한다.
Figures
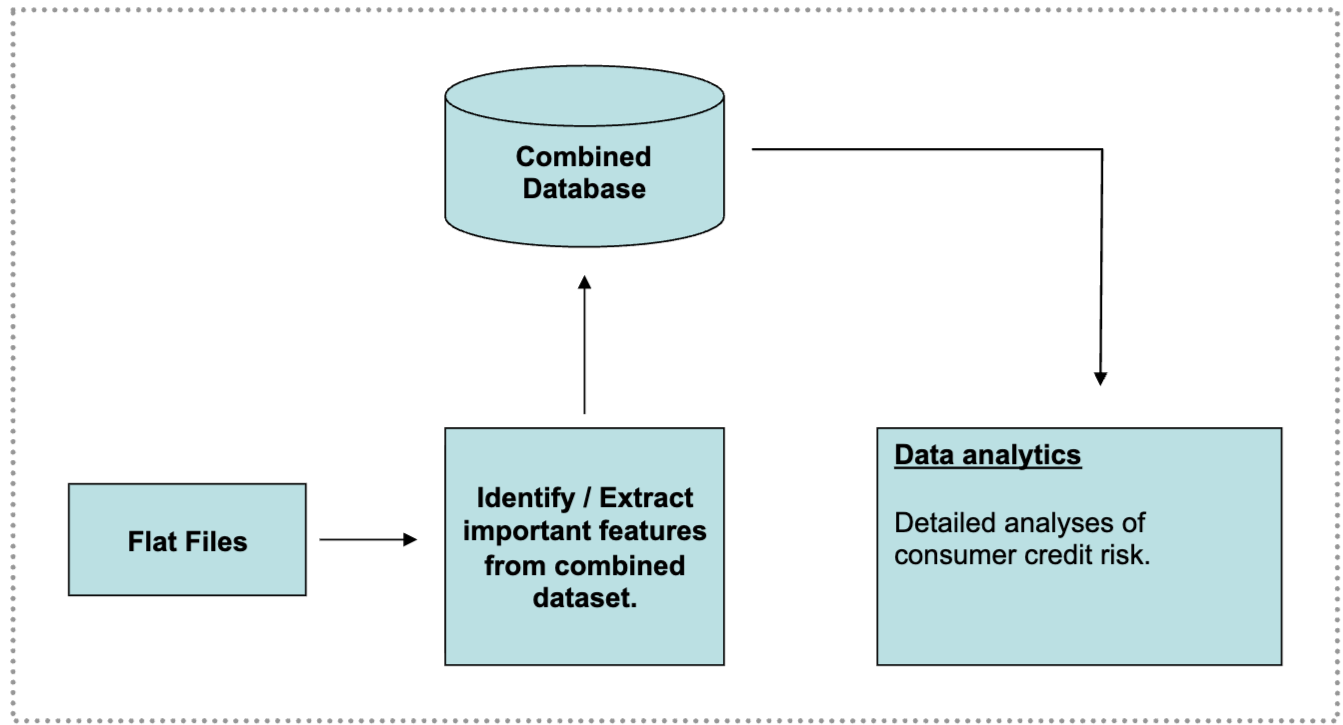
01. 고객 신용 리스크 ML 모델에 사용된 고객 거래 및 신용 평가 통합 DB 구조
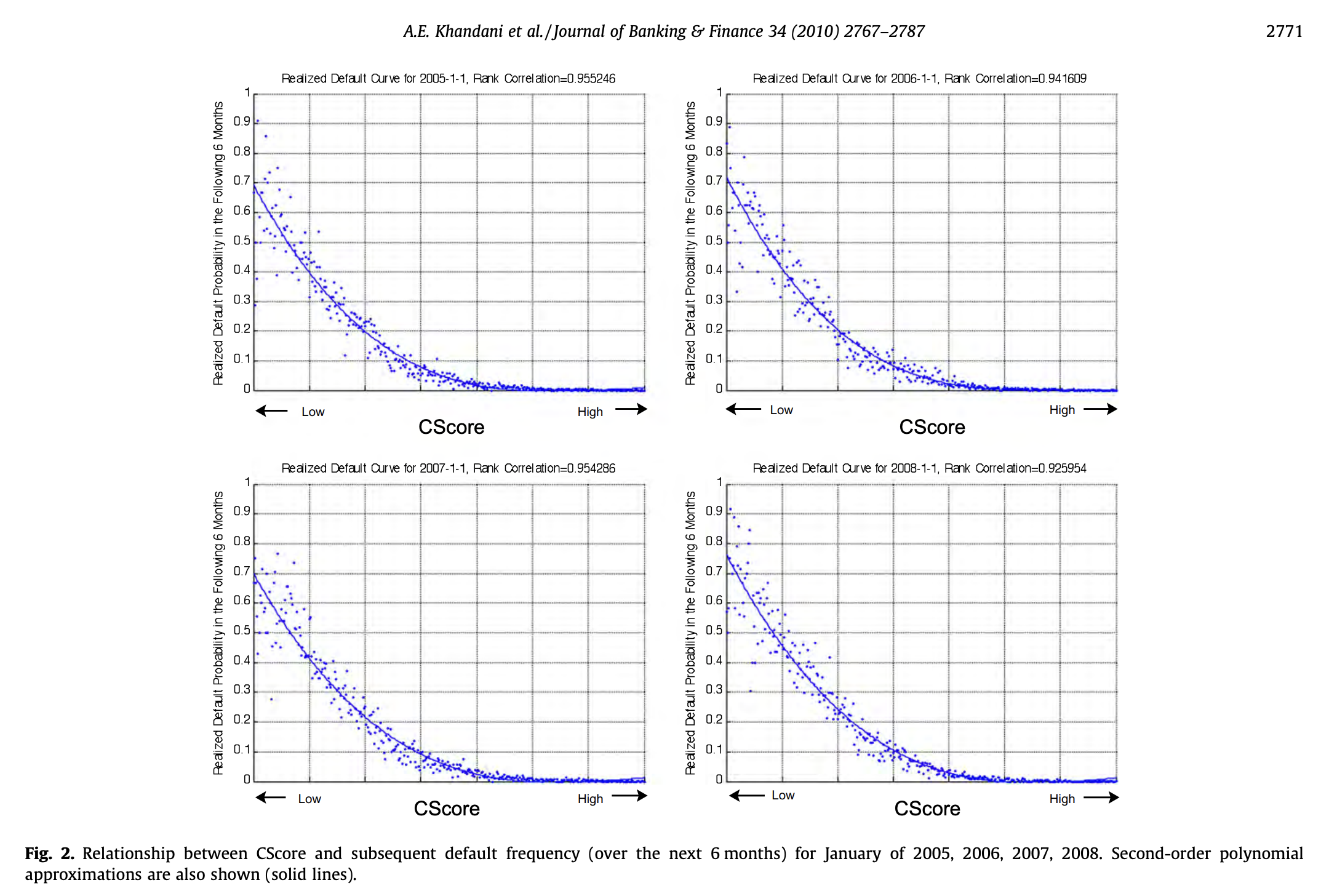
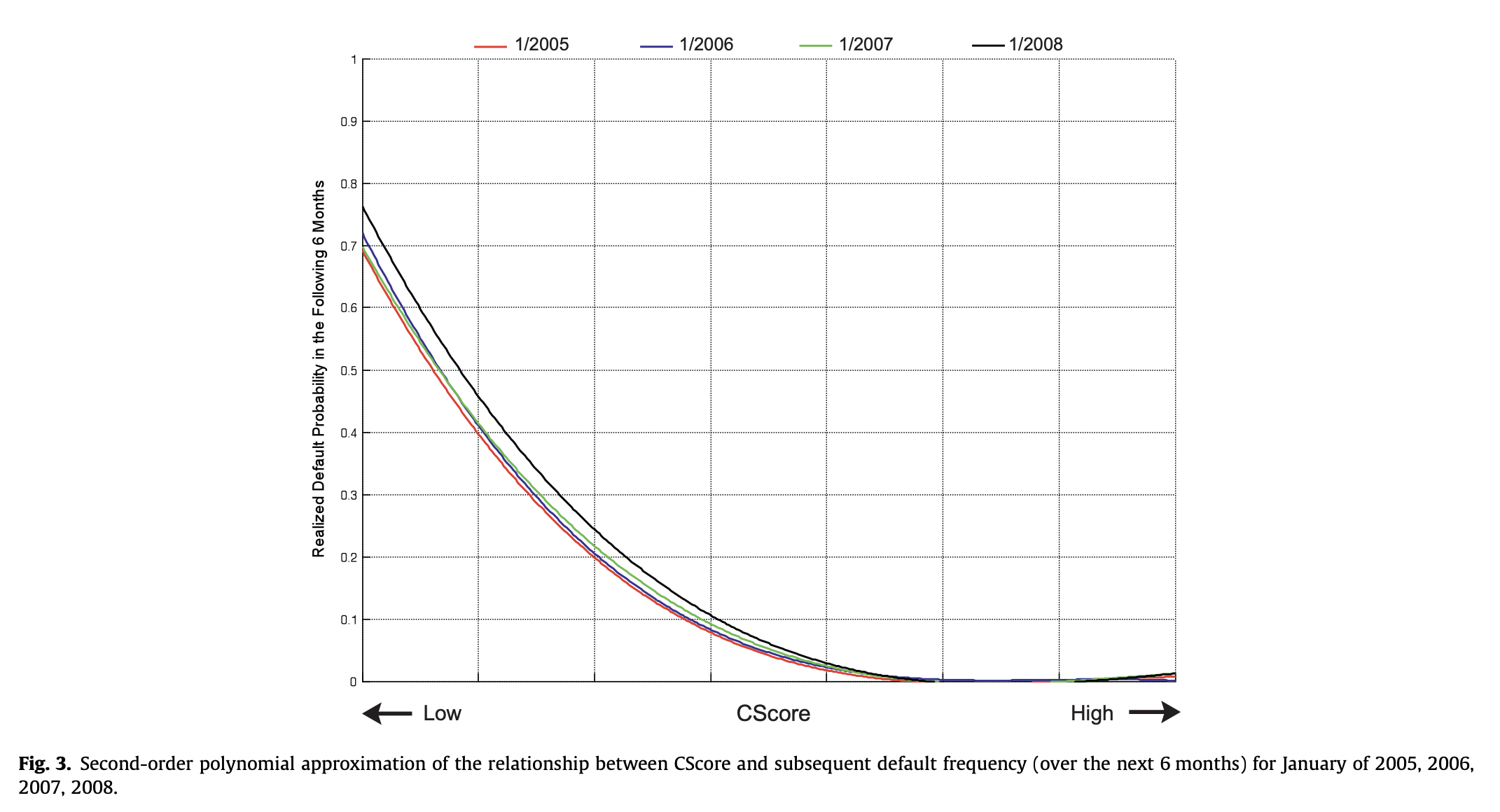
02. CScore(신용 점수) 및 연체율 관계
- 2005년, 2006년, 2007년, 2008년 1월 기준 CScore와 향후 6개월간의 연체 빈도 간의 관계.
- 2차 다항식 근사도 함께 표시됨 (실선)
- 2차 다항식 근사도 함께 표시됨 (실선)
03. CScore 관계 근사
- CScore와 후속 부도 빈도(향후 6개월) 간의 관계에 대한 2차 다항식 근사 (2005년, 2006년, 2007년, 2008년 1월)
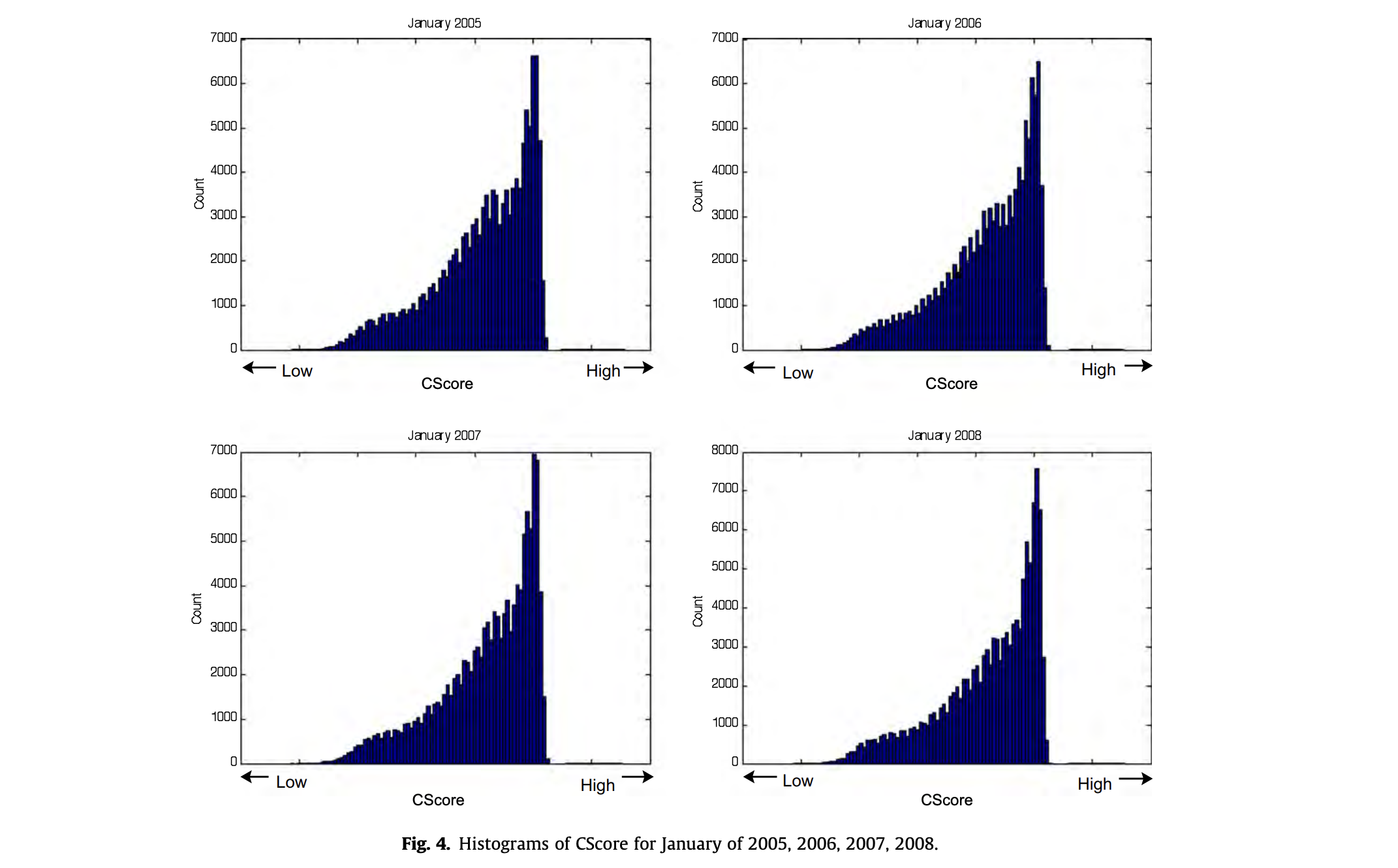
04. CScore 분포(2005~2008, 1월)
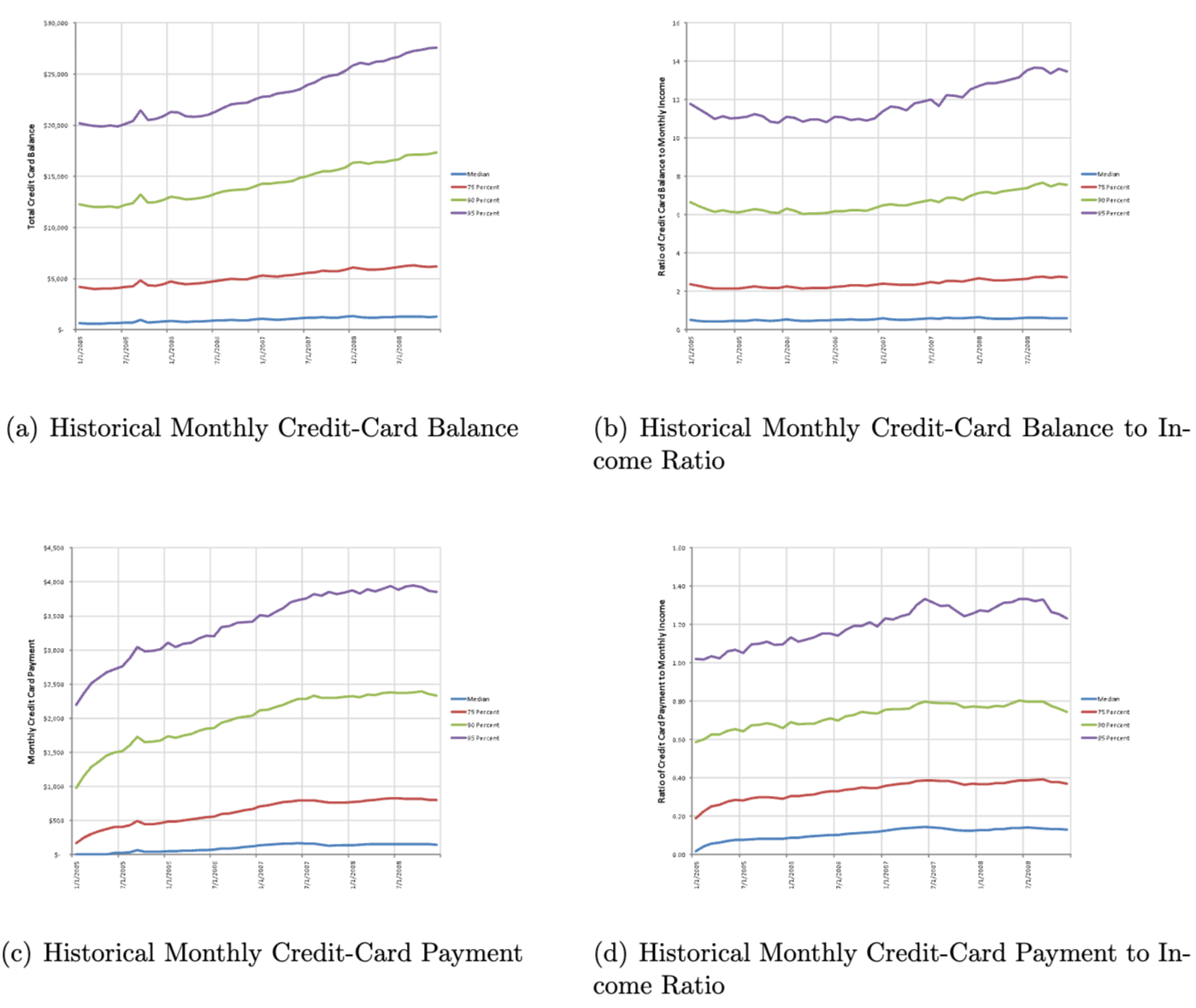
05. 신용카드 특성 및 소득 관계
- 신용카드 잔액, 상환금액 및 월별 소득과의 관계 특성
- (a) : 고객의 모든 신용카드 총 잔액(월말 기준)
- (b) : 신용카드 잔액과 월별 소득의 비율
- (c) : 신용카드 상환금액
- (d) : 신용카드 상환금액과 월별 소득의 비율(x축 날짜 이전 6개월간의 평균 소득 및 신용카드 상환금액 또는 이용 가능한 월 수만큼의 평균값이 사용됨)
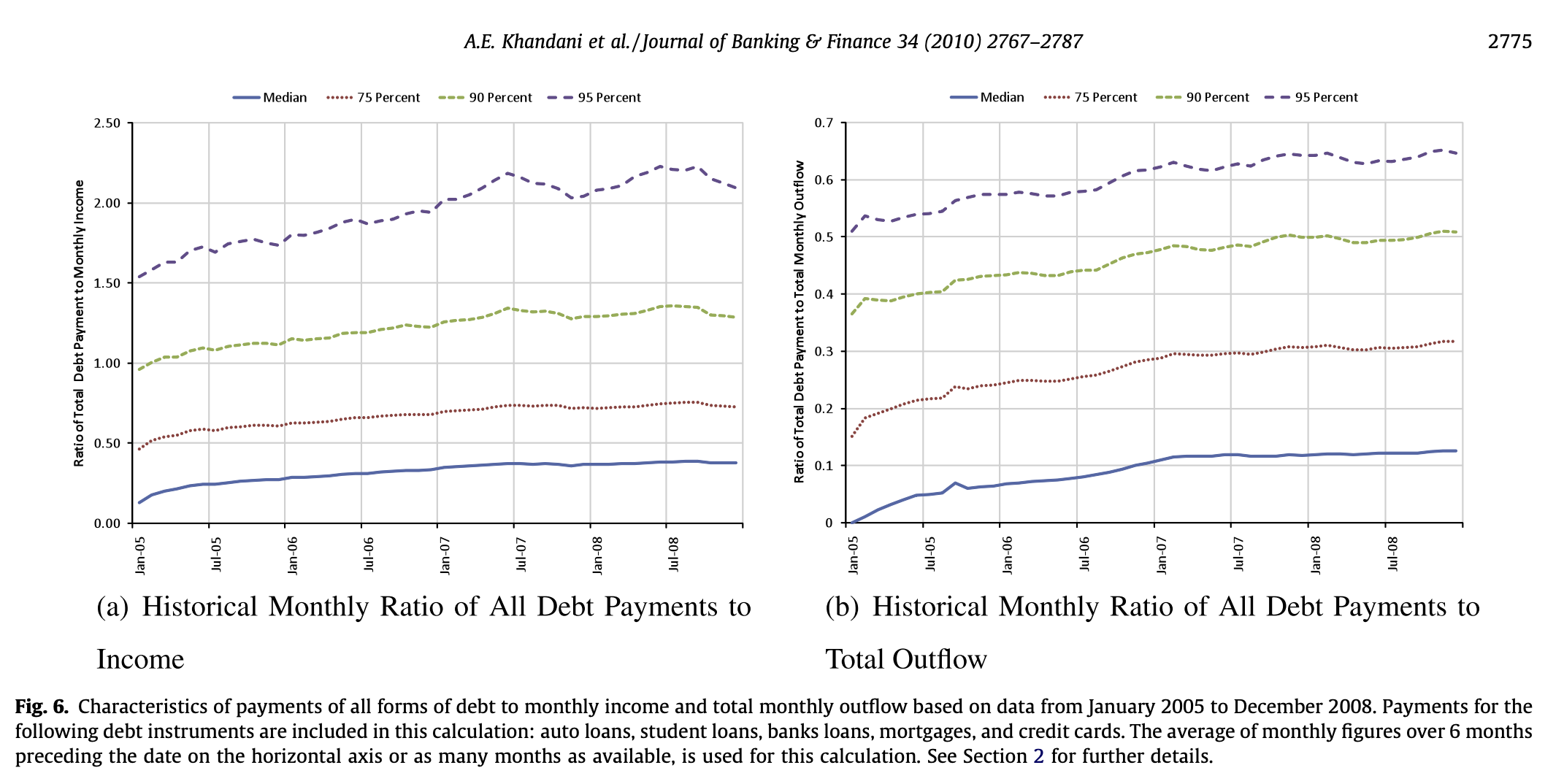
06. 월 소득/지출 대비 부채
- 월 소득 및 총 월간 지출 대비 모든 형태의 부채 상환액 특징
- 자동차 대출, 학자금 대출, 은행 대출, 주택 담보 대출 및 신용 카드 부채 상품에 대한 상환액이 포함됨
- x축 날짜 이전 6개월간의 월별 수치 평균 또는 가능한 해당 개월 수만큼의 평균이 사용됨
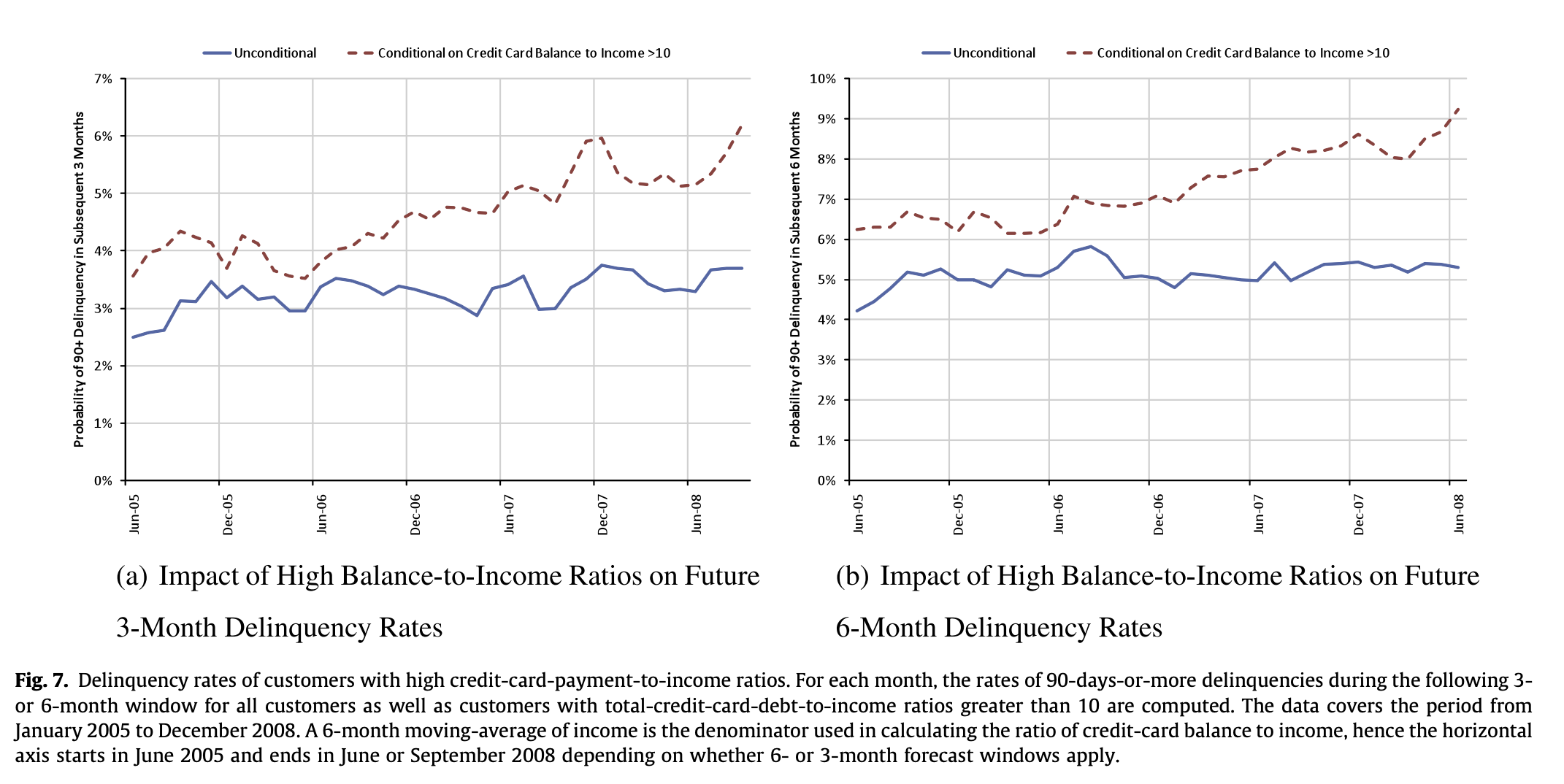
07. 고신용카드상환액비율 연체율
- 높은 신용카드 상환액 대비 소득 비율을 가진 고객의 연체율
- 월별 총 신용카드 부채 대비 소득 비율이 10을 초과하는 고객에 대해 이후 3개월 또는 6개월 기간 동안 90일 이상 연체율이 계산됨
- 신용카드 잔액 대비 소득 비율 계산에 사용되는 분모는 6개월 이동 평균 소득이며, x축은 2005년 6월에 시작하여 6개월 또는 3개월 예측 기간이 적용되는지에 따라 2008년 6월 또는 9월에 종료됨
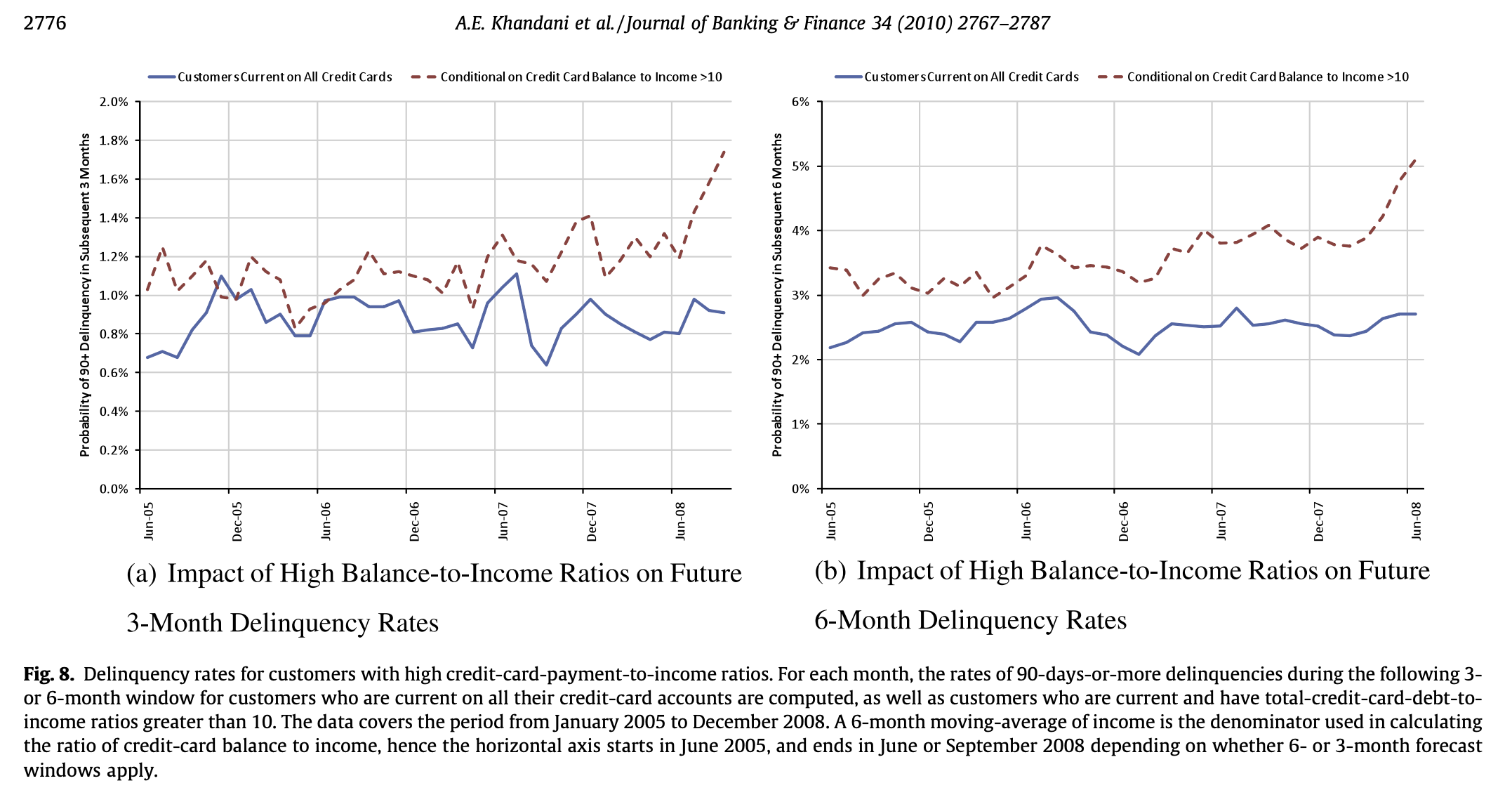
08. 고소득 대비 부채 비율
- 높은 신용카드 결제액 대비 소득 비율을 가진 고객의 부실률
- 월별 신용카드 계좌에 대해 정상 상환 중인 고객과 정상 상환 중이며 총 신용카드 부채 대비 소득 비율이 10을 초과하는 고객들의 향후 3개월 또는 6개월 범위에서 90일 이상 연체율을 계산
- 신용카드 잔액 대비 소득 비율을 계산하는 데 사용되는 소득의 6개월 이동 평균이 분모이므로, x축은 2005년 6월에 시작하며, 6개월 또는 3개월 예측 범위 적용 여부에 따라 2008년 6월 또는 9월에 종료됨
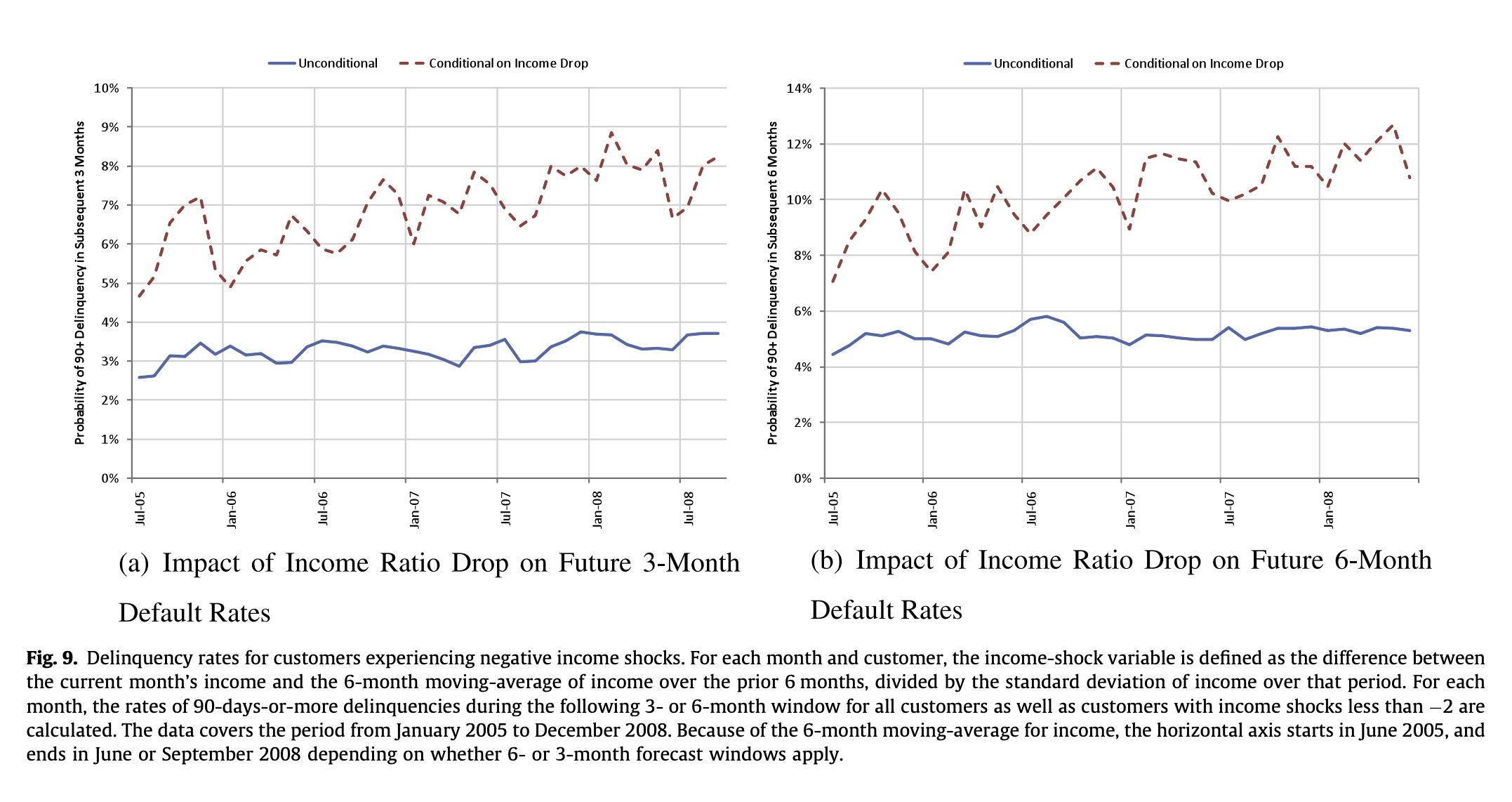
09. 소득 충격 연체율
- 부정적 소득 충격을 경험한 고객의 연체율.
- income-shock variable = 현재 월 소득과 이전 6개월간의 소득 6개월 이동 평균 간의 차이를 해당 기간 동안의 소득 표준 편차로 나눈 값
- 각 월별로, 3개월 또는 6개월의 다음 기간 내 90일 이상 연체율이 모든 고객과 income shocks가 −2 미만인 고객에 대해 계산됩니다.
- 소득에 대한 6개월 이동 평균 때문에, x축은 2005년 6월에 시작하며, 6개월 또는 3개월 예측 기간이 적용되는지에 따라 2008년 6월 또는 9월에 끝납니다.
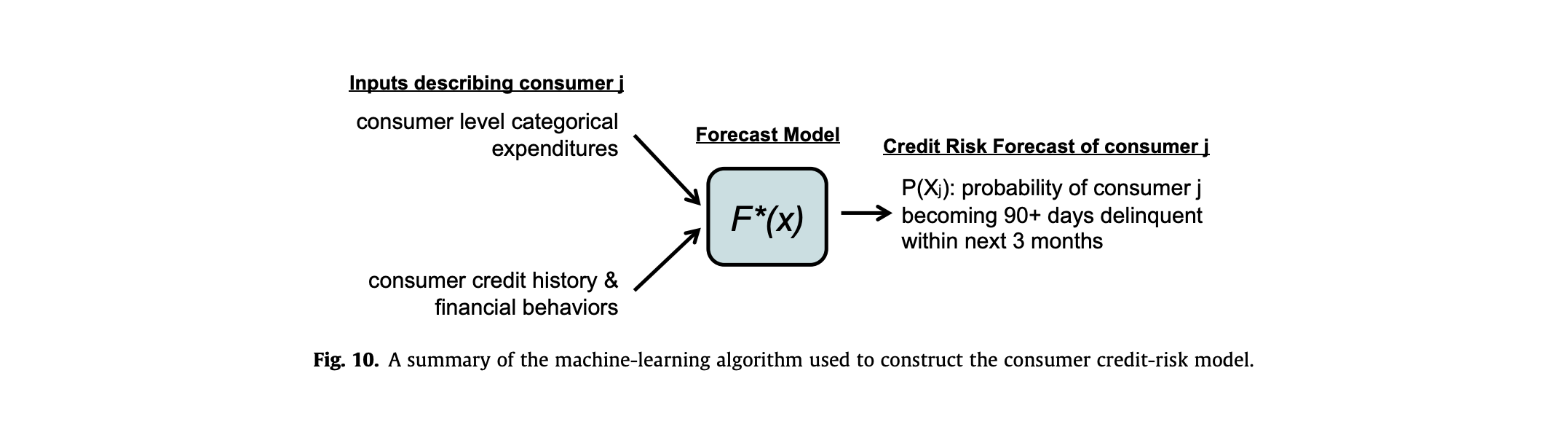
10. 고객 신용-리스크 모델 구성에 사용된 ML 알고리즘 요약
-
90일 이상 연체될 확률 예측
-
입력 (Inputs describing consumer j): 모델이 신용 위험을 예측하기 위해 사용하는 데이터
- 소비자 수준의 범주형 지출 (consumer level categorical expenditures): 개별 소비자가 어떤 종류의 상품이나 서비스에 지출하는지에 대한 정보. (ex. 식료품, 의류, 오락 등에 대한 지출 패턴 등)
- 소비자 신용 기록 및 금융 행동 (consumer credit history & financial behaviors): 개인의 신용카드 사용 내역, 대출 상환 기록, 소득 변화, 저축 행동 등 과거의 금융 거래 및 신용 관련 정보
-
예측 모델 (Forecast Model):
- x : 위에서 설명한 입력 변수들의 벡터
- F^* : 학습된 함수(알고리즘)
-
신용 위험 예측 (Credit Risk Forecast of consumer j):
- 개별 소비자 j의 신용 위험 출력
- 소비자 j가 향후 3개월 이내에 90일 이상 연체될 확률을 의미함
- 이 확률이 높을수록 해당 소비자의 신용 위험이 높다고 판단할 수 있음
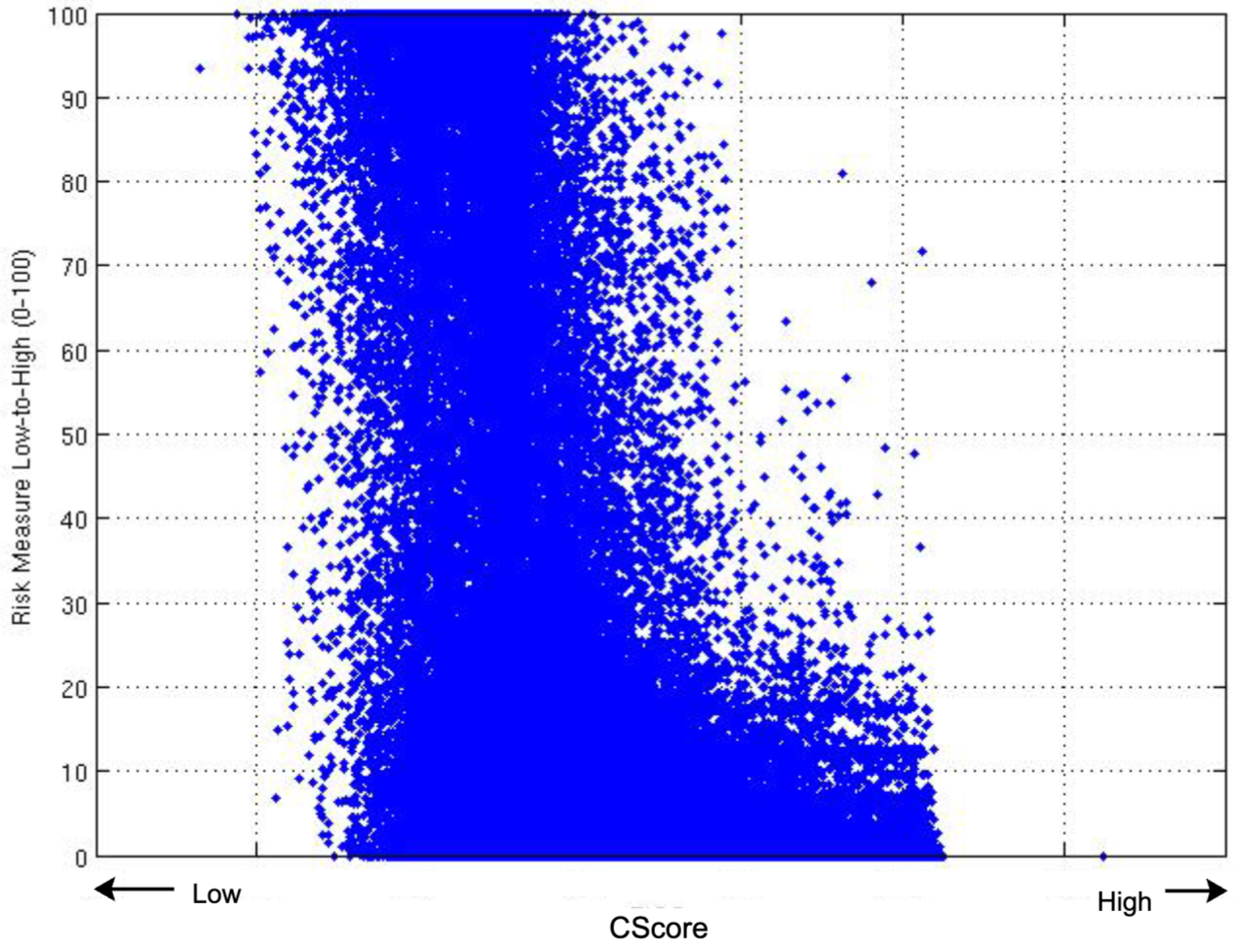
11. CScore와 예측 비교
- 2008년 12월 CScore(x축, 값이 높을수록 신용 위험이 낮음)와 2008년 10월부터 12월까지의 실제 연체 이벤트 및 2008년 9월의 특징 벡터를 사용한 후속 3개월 동안의 90일 이상 연체율에 대한 머신러닝 예측을 비교함
- 보정(calibration)이 완료된 후, 머신러닝 모델을 2008년 12월 특징 벡터에 적용하고, 결과로 나온 “적합값(fitted values)”을 2008년 12월 CScore와 함께 (y축에) 플로팅함
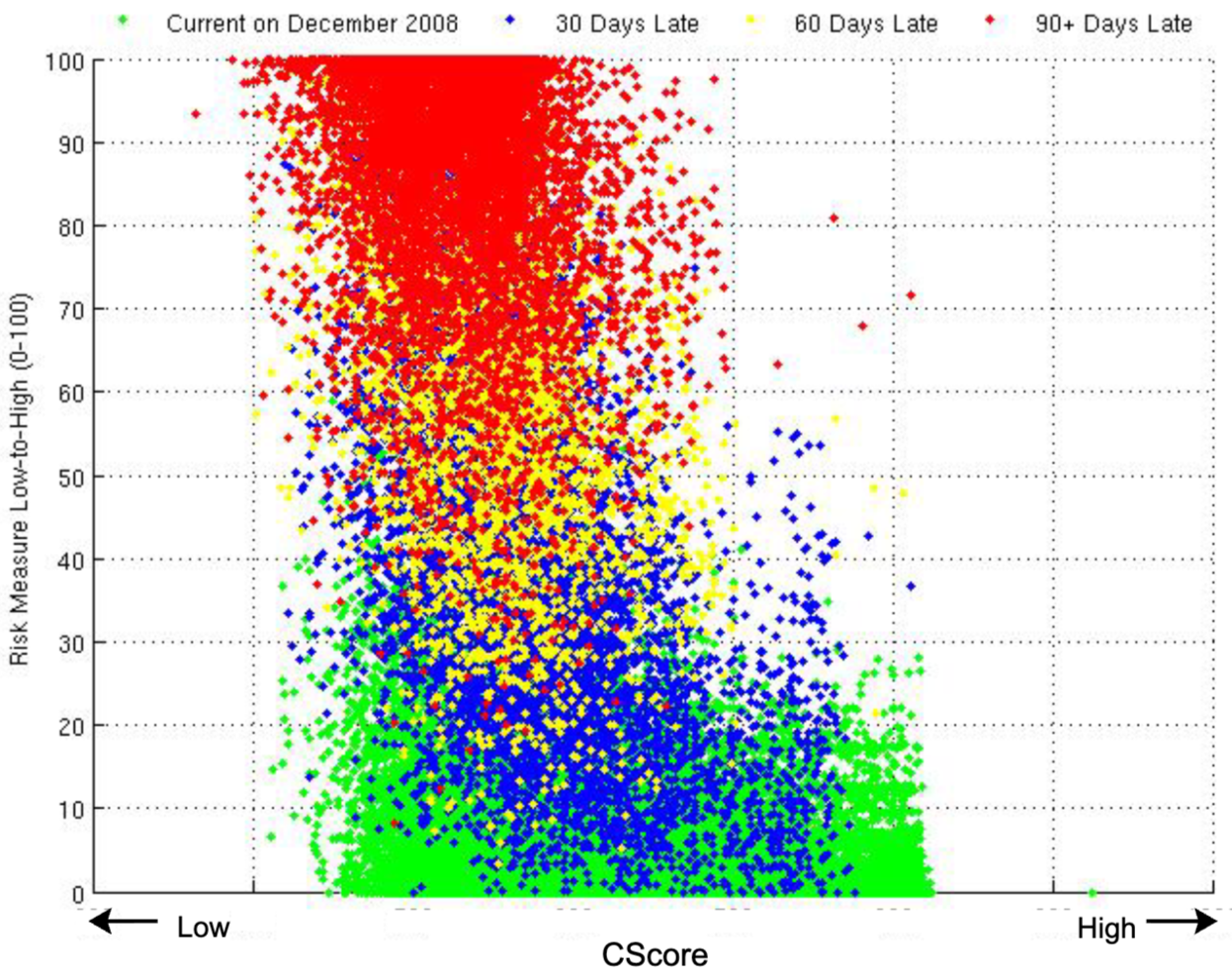
12. 연체율 예측
- 2008년 12월 CScore (x축, 값이 높을수록 신용 위험이 낮음)와 머신러닝 기반 90일 이상 연체율 예측을 2008년 10월부터 12월까지의 실제 연체 이벤트 및 2008년 9월 특성 벡터를 사용하여 3개월 단위로 비교한 색상 구분 결과
- 보정된 머신러닝 모델을 2008년 12월 특성 벡터에 적용하고, 그 결과로 나온 "적합값"을 2008년 12월 CScore와 함께 y축에 표시했습니다.
- 색상 코딩은 2008년 12월 기준으로 계정이 정상(연두색), 30일 연체(파란색), 60일 연체(노란색), 90일 이상 연체(빨간색)인지 여부를 나타냄
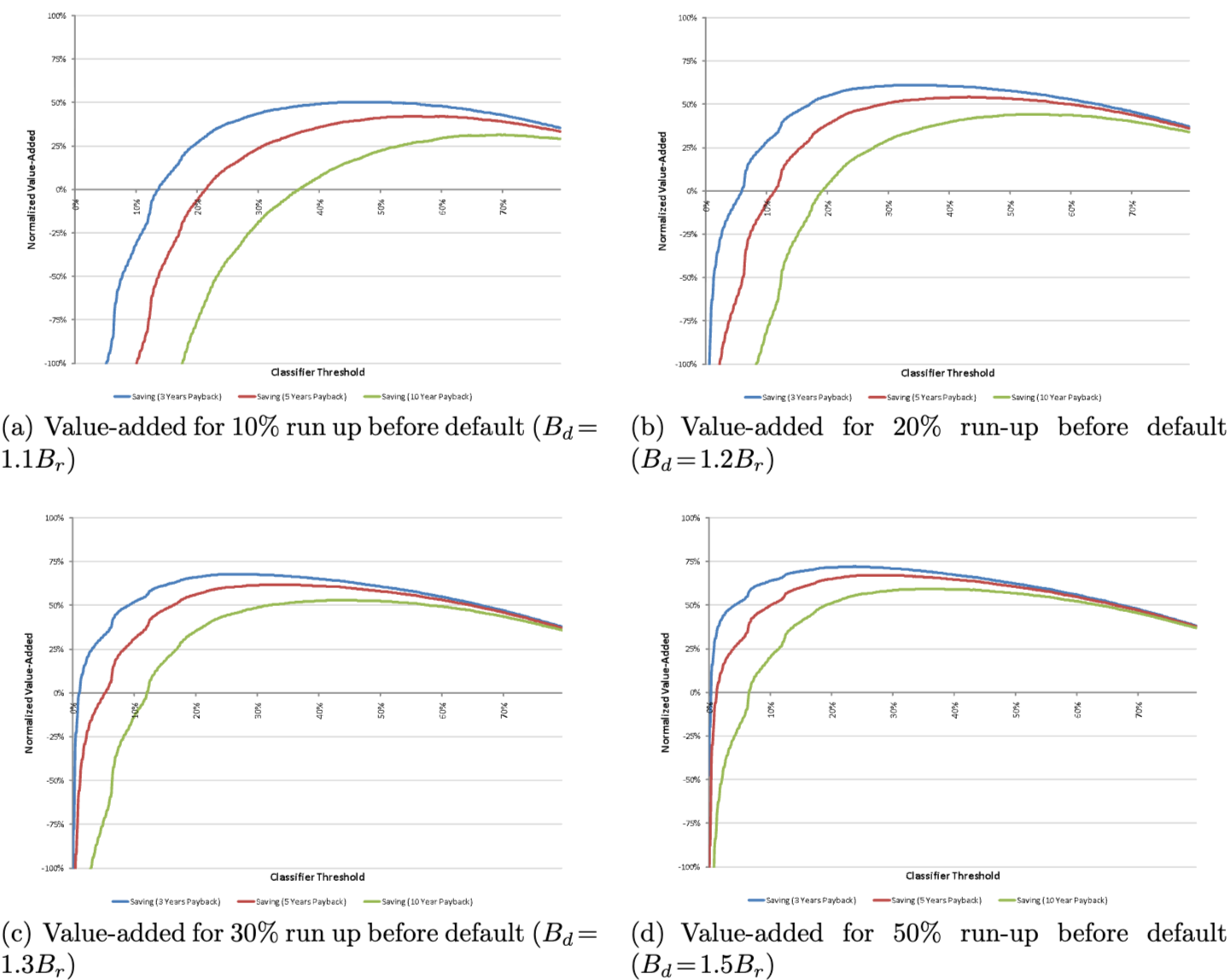
16. VA 예측치 부도 분석
- 2008년 12월 machine-learning 예측치에 따른 부가가치(VA)는 90일 이상 연체에 대해 2009년 1월부터 3월까지 3개월 예측 기간 동안, 매개변수 r = 5%, 부도 전 가격 상승 10%, 20%, 30% 또는 50%, 그리고 상각 기간 N이 3년, 5년 또는 10년인 경우를 나타냄
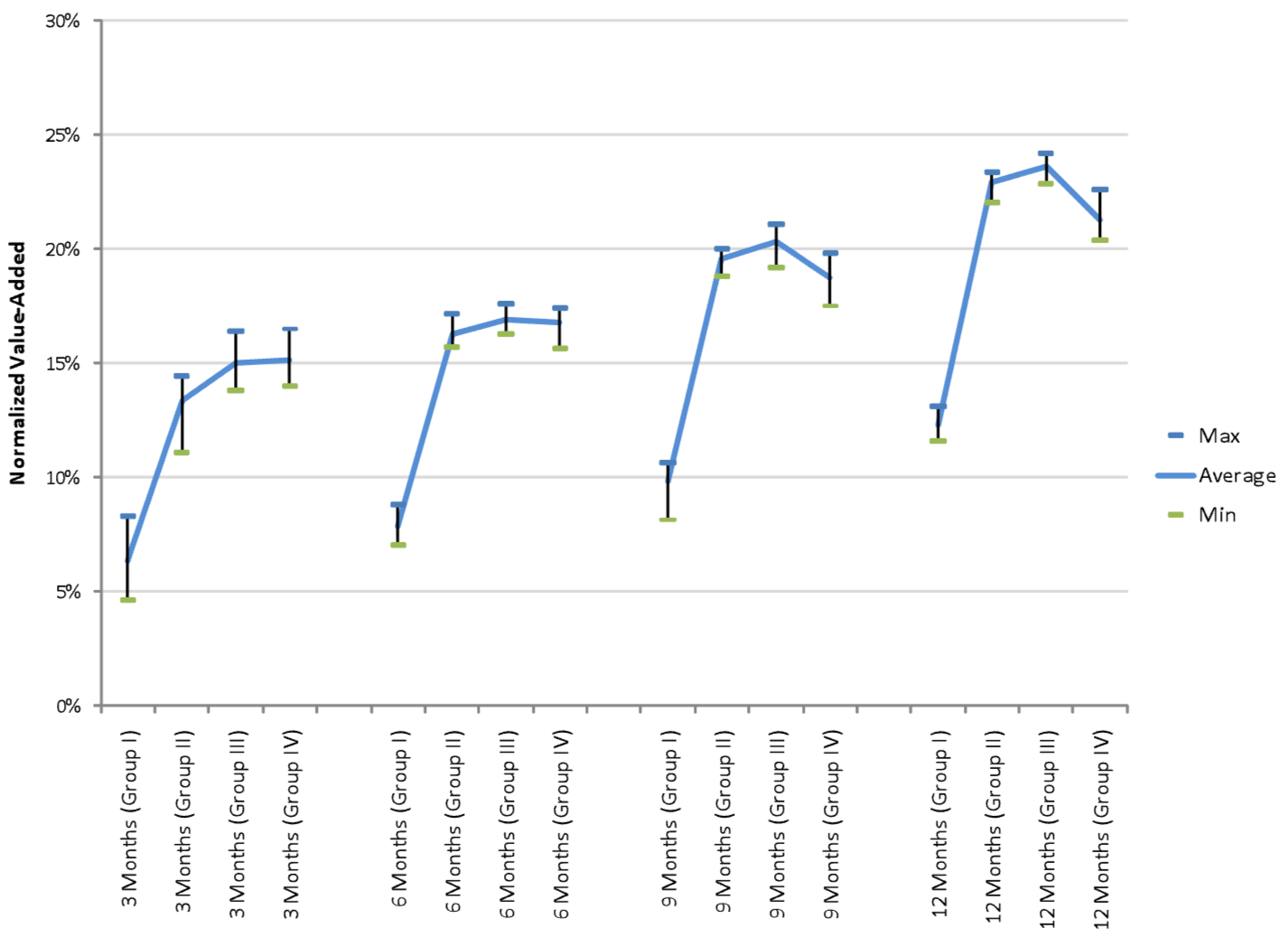
18. 머신러닝 예측 가치
- 머신러닝 예측의 부가가치(value-added)는 90일 이상 연체 예측에 대해 3개월, 6개월, 9개월, 12개월의 예측 기간을 사용하였으며, 2005년 1월부터 2008년 4월까지의 데이터를 활용함
- 이는 무작위로 선택된 10% 데이터 하위 표본의 네 개의 동일한 층화된 하위 표본에 대해 이루어졌으며, 결측이 없는 피처(feature)의 수에 따라 층화됨
- 그룹 I은 가장 적은 가용 피처를 가진 계정 표본("thinnest")이며, 그룹 IV는 가장 많은 피처를 가진 계정 표본("thickest")을 의미함
- 최소 및 최대 VA 값은 전체 데이터 세트를 사용하여 10-fold 교차 검증(cross validation)을 통해 계산되었으며, 이는 다음을 포함하는 방정식을 사용함
- 상각 기간 N = 3년, 부도 전 상승(run-up before default) 30% (Bd = 1.3Br), r = 5%, 그리고 ROC-tangency 분류 임계값(classification threshold)
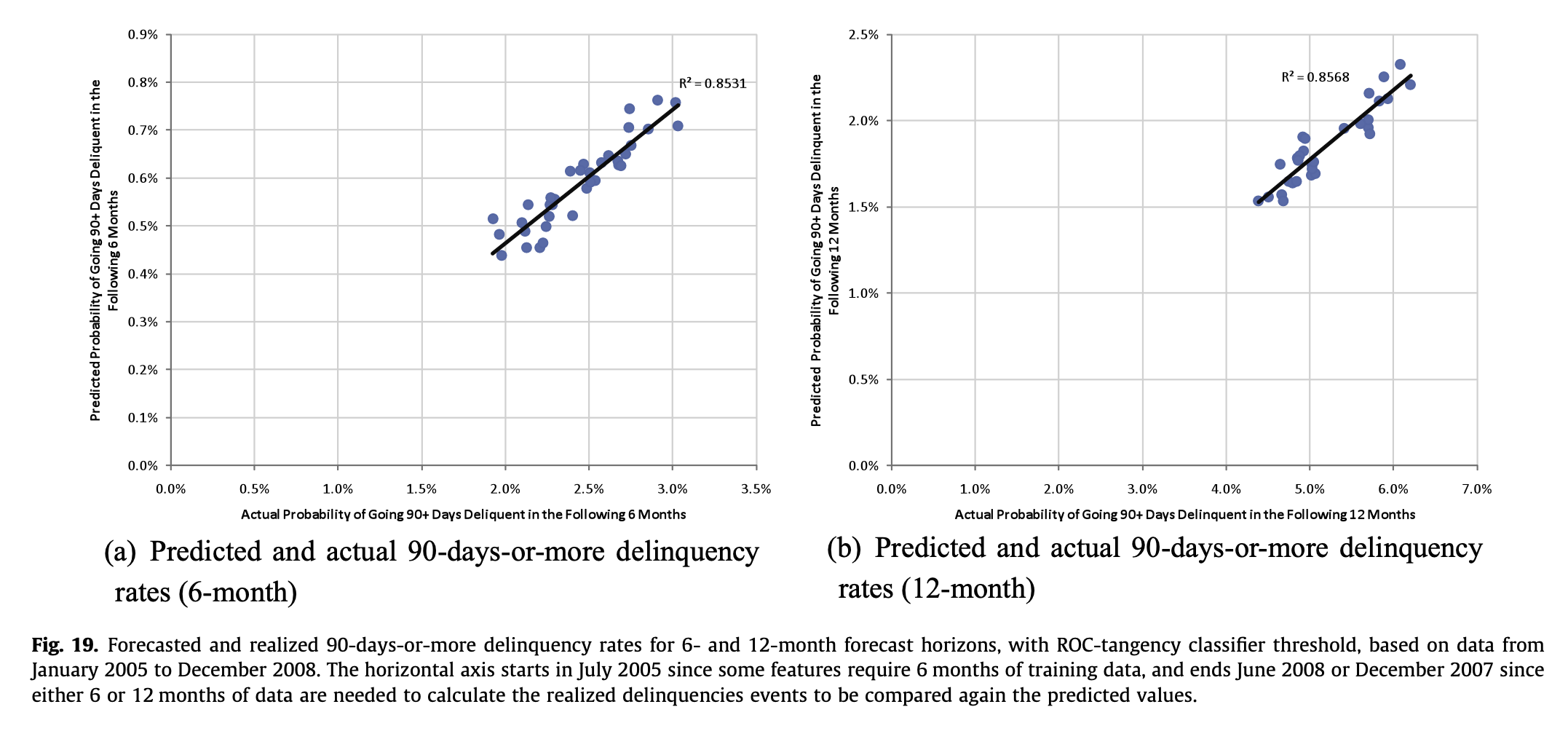
19. 예측 연체율 비교
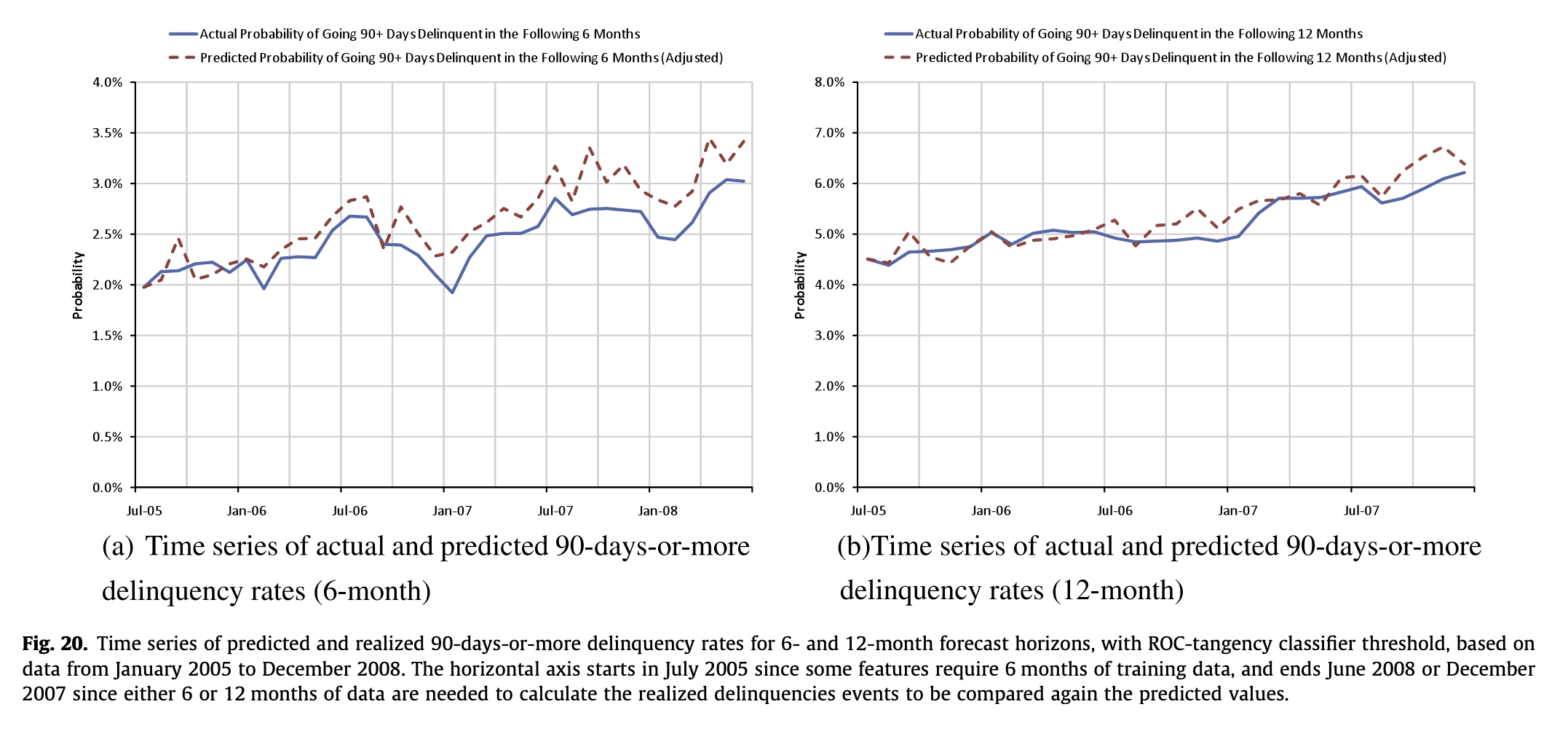
- 예측 및 실현된 90-days-or-more delinquency rates (6개월 및 12개월 예측 horizon)은 ROC-tangency classifier threshold를 사용하였으며, 2005년 1월부터 2008년 12월까지의 데이터를 기반으로 함
- x축은 일부 feature가 6개월의 training data를 요구하기 때문에 2005년 7월에 시작하며, 2008년 6월 또는 2007년 12월에 종료됨(이는 예측된 값과 비교하기 위해 실현된 delinquencies events를 계산하는 데 6개월 또는 12개월의 데이터가 필요하기 때문)
20. 예측 연체율 시계열 분석
- ROC-tangency 분류기 임계값을 사용한 6개월 및 12개월 예측 시점별 예측 및 실제 90일 이상 연체율 시계열
- x축은 일부 feature가 6개월의 학습 데이터를 필요로 하기 때문에 2005년 7월에 시작하며, 예측값과 비교할 실제 연체 이벤트를 계산하기 위해 6개월 또는 12개월의 데이터가 필요하므로 2008년 6월 또는 2007년 12월에 종료됨