‼️ 개인 학습 내용으로, 오류가 있을 수 있습니다.
논문 URL - https://arxiv.org/abs/2312.10997
Title
- Retrieval-Augmented Generation for Large Language Models: A Survey
-> LLM 모델을 위한 RAG : 설문 연구
Abstract
-
Large Language Models (LLMs) showcase impressive capabilities but encounter challenges like hallucination, outdated knowledge, and non-transparent, untraceable reasoning processes.
-> LLM은 인상적인 능력을 보여주었지만 할루시네이션(환각), 과거 지식, 불투명하고 추적되지 않는 추론 과정과 같은 문제에 직면해 있다. -
Retrieval-Augmented Generation (RAG) has emerged as a promising solution by incorporating knowledge from external databases.
-> RAG(검색 증강 생성)은 외부 DB로부터 지식을 통합함으로써 유망한 해결 방법으로 떠올랐다. -
This enhances the accuracy and credibility of the generation, particularly for knowledge-intensive tasks, and allows for continuous knowledge updates and integration of domainspecific information.
-> RAG는 특히 지식 집약적 작업에 대한 생성의 정확성과 신뢰성을 향샹시키고, 지속적인 지식 업데이트와 도메인별 정보의 통합이 가능케한다. -
RAG synergistically merges LLMs’ intrinsic knowledge with the vast, dynamic repositories of external databases.
-> RAG는 LLM의 내재된 지식과 외부 데이터베이스의 방대하고 역동적인 저장소와 결합하며 시너지 효과를 내는 기술이다. -
This comprehensive review paper offers a detailed examination of the progression of RAG paradigms, encompassing the Naive RAG, the Advanced RAG, and the Modular RAG.
-> 이 종합적인 리뷰 논문은 Naive RAG, Advanced RAG, Modular RAG을 포함한 RAG 패러다임의 발전 과정을 상세하게 분석한다. -
It meticulously scrutinizes the tripartite foundation of RAG
frameworks, which includes the retrieval, the generation and the
augmentation techniques.
-> 검색, 생성, 증강 기술을 포함하는 RAG frameworks의 3개의 기반을 면밀히 검토한다. -
The paper highlights the state-of-the art technologies embedded in each of these critical components, providing a profound understanding of the advancements in RAG systems.
-> 이 논문은 각각의 중요한 구성 요소에 내장된 SOTA 기술을 강조하여 RAG 시스템의 발전에 대한 심층적인 이해를 제공한다.
-
Furthermore, this paper introduces up-to-date evaluation framework and benchmark.
-> 이 논문은 최신 평가 framework와 벤치마크를 소개한다. -
At the end, this article delineates the challenges currently faced and points out prospective avenues for research and development.
-> 마지막으로 이 논문은 현재 직면한 과제를 설명하고 연구 개발을 위한 잠재적 방향을 제시합니다.
Figures
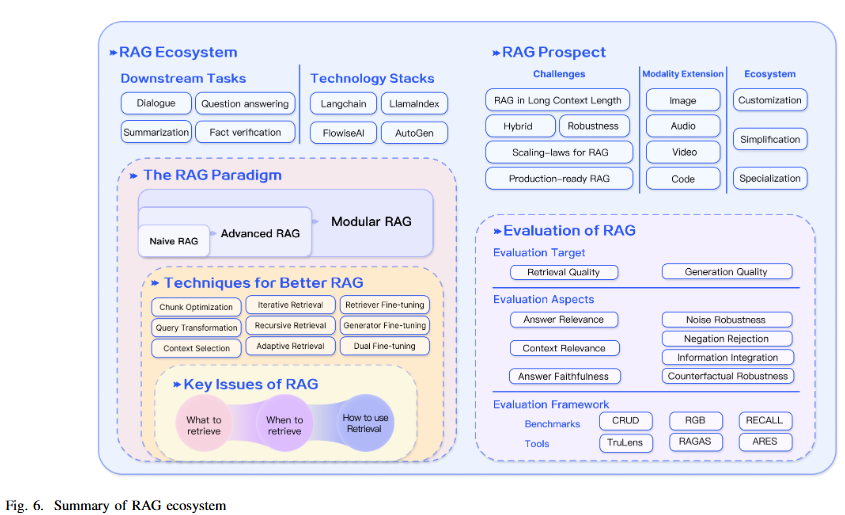
01. RAG 연구의 기술 트리
- RAG 연구의 기술 트리는 주로 아래 단계를 포함한다.
- 추론(inference)
- LLM 등장 초기에는 RAG 연구가 LLM의 강력한 문맥 학습(in-context learning) 능력을 활용하여 주로 추론 단계에 집중
- 미세조정(fine-tuning)
- 이후 연구에서는 LLM의 미세조정 단계와의 통합이 점차 심화됨
- 사전학습(pre-training)
- 최근에는 검색 증강 기법을 사전학습 단계에도 적용하여 언어 모델의 성능을 더욱 향상시키는 방안이 탐구되고 있다.
- 추론(inference)
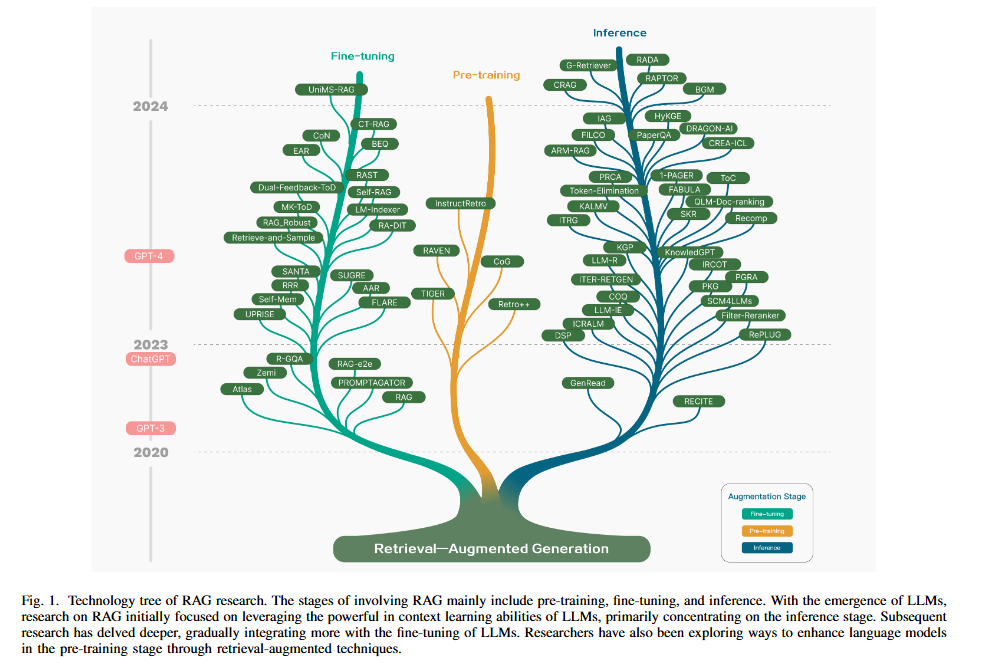
02. RAG 작동 과정
-
작동 과정은 3단계로 구성됨
-
Indexing - 문서는 chunk로 분할되고 vector로 인코딩된 후 vector DB에 저장된다.
-
Retrieval - 질문(쿼리)와 가장 연관성이 높은 Top k chunks를 의미적 유사성(semantic similarity*)을 기반으로 검색한다.
- semantic similarity : 두 텍스트(단어, 문장, 문서 등)가 의미나 문맥에서 얼마나 비슷하거나 연관되어 있는지를 측정하는 척도.
- 즉, 단순히 단어가 겉으로 얼마나 비슷한가(형태적 유사성)가 아니라, 실제로 내포하는 뜻이나 맥락이 얼마나 가까운지를 평가 -
Generation - 원본 질문과 검색된 chunks를 함께 LLM 모델로 입력한 후 최종 답변을 생성한다.
-
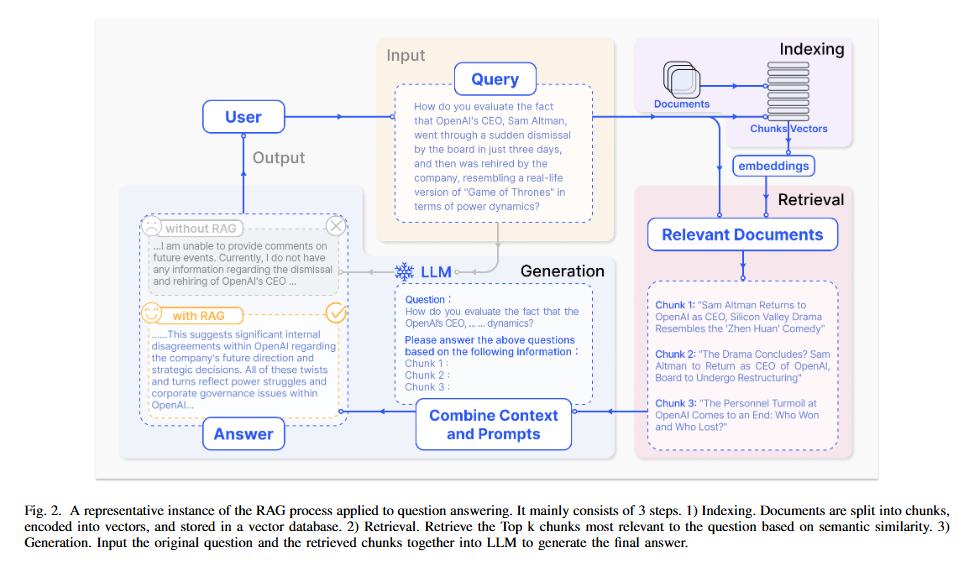
03. RAG의 3가지 패러다임 비교
| Paradigm | 구조 및 특징 | 주요 장점 | 한계점/특징 |
|---|---|---|---|
| Naive RAG | 인덱싱 → 검색 → 생성 (선형) | 단순, 빠른 구현 | 정확성·유연성 부족 |
| Advanced RAG | Naive RAG + 최적화 전략(사전/사후) | 성능·정밀도 향상 | 여전히 순차적 구조 |
| Modular RAG | 모듈화, 병렬·반복·적응적 처리 가능 | 유연성·확장성·맞춤화 가능 | 설계·구현 복잡도 증가 |
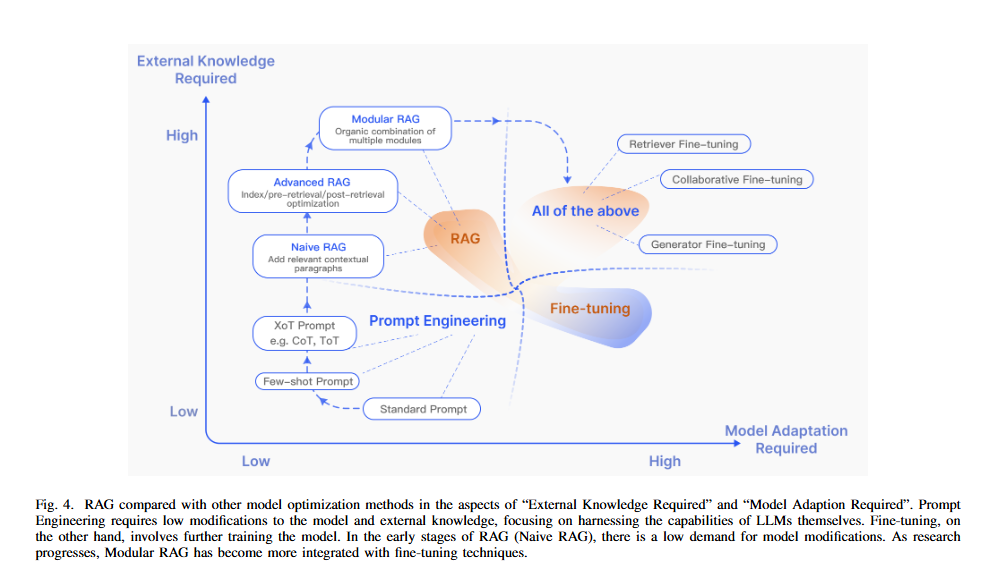
04. RAG와 기타 모델 최적화 방법 비교 ('외부 지식 필요도', '모델 적응 필요도' 관점)
-
프롬프트 엔지니어링
- 모델 자체나 외부 지식의 변경 없이 입력 프롬프트만 최적화
-
파인튜닝
- 도메인별 데이터로 모델을 추가 학습시켜 내부 파라미터를 조정
- 외부 지식보다는 모델 자체의 적응이 많이 필요하며, 정확도와 도메인 특화 성능이 높아지지만, 시간과 비용이 많이 든다.
-
RAG
- 외부 데이터베이스 등에서 실시간으로 정보를 검색해 LLM의 답변에 활용
- Naive RAG 초기에는 모델 자체 수정이 거의 필요 없고, 외부 지식 의존도가 높다.
- 연구가 진전되면서 Modular RAG는 파인튜닝 등과 결합되어, 모델 적응과 외부 지식 활용이 모두 강화되는 방향으로 발전하고 있다.
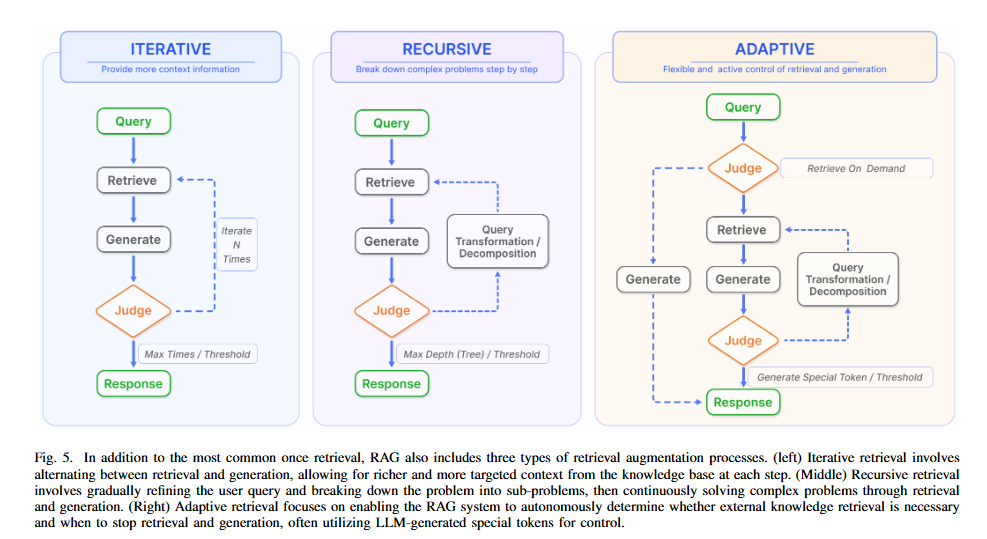
05. 검색-증강 과정의 3가지 유형
-
반복적 검색(Iterative Retrieval)
검색과 생성을 번갈아 여러 번 반복하여, 각 단계마다 지식베이스에서 더 풍부하고 목표에 맞는 문맥을 확보한다. 생성된 결과를 바탕으로 추가 검색을 수행해 점진적으로 답변의 품질을 높인다. -
재귀적 검색(Recursive Retrieval)
사용자의 질문을 점차 세분화해 하위 문제로 나누고, 각 하위 문제에 대해 검색과 생성을 반복적으로 수행한다. 이를 통해 복잡한 문제도 단계적으로 해결할 수 있다. -
적응적 검색(Adaptive Retrieval)
RAG 시스템이 외부 지식 검색이 필요한지, 언제 검색과 생성을 종료할지 스스로 판단한다. 주로 LLM이 생성한 특수 토큰 등을 활용해 검색 과정을 동적으로 제어한다.
06. RAG 생태계 요약