‼️ 개인 학습 내용으로, 오류가 있을 수 있습니다.
논문 URL - https://arxiv.org/abs/2310.11511
Title
- Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
-> Self-RAG: Self-Reflection(자기 성찰)을 통한 검색, 생성 및 비평 학습
Abstract
-
Despite their remarkable capabilities, large language models (LLMs) often produce responses containing factual inaccuracies due to their sole reliance on the parametric knowledge they encapsulate.
-> LLM은 비록 뛰어난 능력을 지니고 있지만, 내부적으로 내포하고 있는 파라미터적 지식에만 의존하기 때문에, 부정확한 답변을 자주 생성한다. -
Retrieval-Augmented Generation (RAG), an ad hoc approach that augments LMs with retrieval of relevant knowledge, decreases such issues.
-> 언어 모델에 관련 지식을 검색하여 추가하는 임시적 방법인 검색 기반 생성(RAG)은 위와 같은 문제를 완화시킨다. -
However, indiscriminately retrieving and incorporating a fixed number of retrieved passages, regardless of whether retrieval is necessary, or passages are relevant, diminishes LM versatility or can lead to unhelpful response generation.
-> 검색이 필요하지 않거나, 검색된 구절이 관련이 없을 때에도 일정한 수의 구절을 무조건적으로 가져와 사용하면, 언어 모델의 활용도가 줄어들거나 쓸모없는 답변을 만들 수 있다. -
We introduce a new framework called Self-Reflective Retrieval-Augmented Generation (SELF-RAG) that enhances an LM’s quality and factuality through retrieval and self-reflection.
-> 우리는 검색과 자기 성찰을 통해 언어 모델(LM)의 품질과 사실성을 향상시키는 새로운 프레임워크인 Self-Reflective Retrieval-Augmented Generation(SELF-RAG)을 소개한다. -
Our framework trains a single arbitrary LM that adaptively retrieves passages on-demand, and generates and reflects on retrieved passages and its own generations using special tokens, called reflection tokens.
-> 우리의 프레임워크는 하나의 임의의 언어 모델(LM)을 훈련시켜서, 필요할 때마다 지문을 적응적으로 검색하고, 검색된 지문과 자신이 생성한 내용을 특수 토큰(반성 토큰, reflection tokens)을 사용해 생성 및 평가한다. -
Generating reflection tokens makes the LM controllable during the inference phase, enabling it to tailor its behavior to diverse task requirements.
-> 반성 토큰(reflection tokens)을 생성함으로써 언어 모델(LM)은 추론 단계에서 제어가 가능해지며, 다양한 작업 요구사항에 맞게 행동을 조정할 수 있다. -
Experiments show that SELF-RAG (7B and 13B parameters) significantly outperforms state-of-the-art LLMs and retrieval-augmented models on a diverse set of tasks.
-> 실험 결과, 7B 및 13B 파라미터를 가진 SELF-RAG는 다양한 작업에서 최신 LLM 및 검색-증강 모델을 크게 능가하는 성능을 보인다. -
Specifically, SELF-RAG outperforms ChatGPT and retrieval-augmented Llama2-chat on Open-domain QA, reasoning and fact verification tasks, and it shows significant gains in improving factuality and citation accuracy for long-form generations relative to these models.
-> 구체적으로, Self-RAG는 오픈 도메인 질의응답(Open-domain QA), 추론, 그리고 사실 검증 과제에서 ChatGPT와 검색이 추가된 Llama2-chat보다 뛰어난 성능을 보이며, 이들 모델에 비해 장문 생성에서 사실성과 인용 정확도 향상에 현저한 이점을 보인다.
Figures
01. Self-RAG 개요(RAG와 비교)
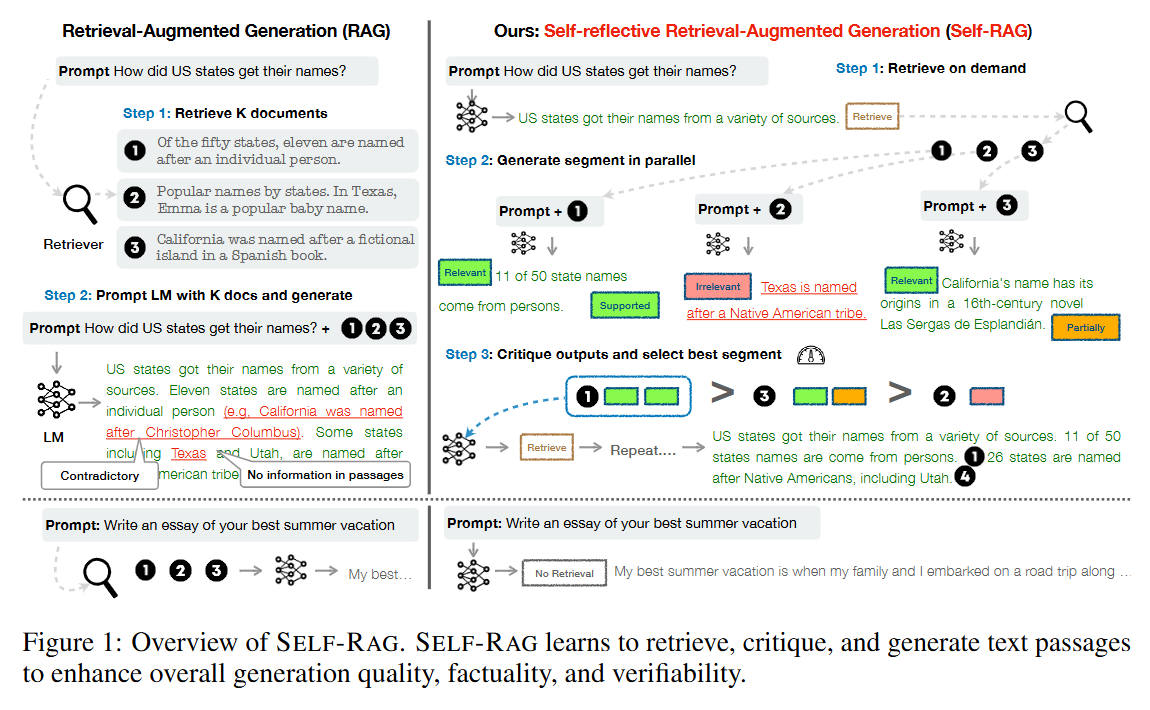
02. Self-RAG 학습 예시(검색 불필요 & 검색 필요)

03. Self-RAG 성능
* ablation : 모델이나 알고리즘의 구성 요소(예: 모듈, 레이어, 하이퍼파라미터, 특정 기능 등)를 실험적으로 제거하는 행위를 의미한다.
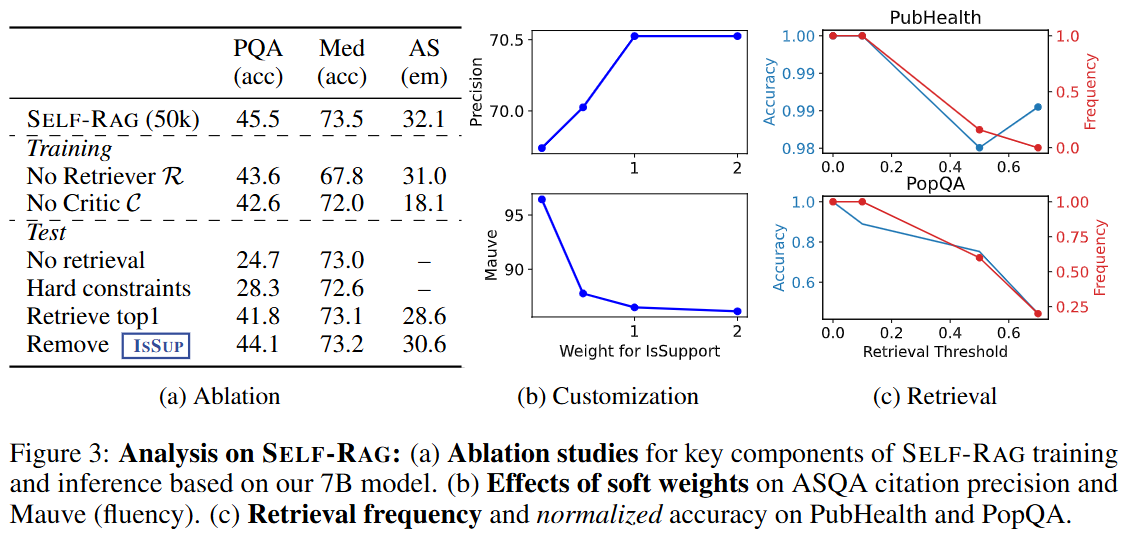
(a) SELF-RAG의 ablation study(구성요소 제거 실험) 결과
- 구성요소를 제거하거나 변경했을 때, 세 가지 평가 지표(PQA, Med, AS)에서의 성능 변화
- SELF-RAG (50k): 전체 모델 성능 (PQA: 45.5, Med: 73.5, AS: 32.1)
- Training 단계에서의 Ablation
- No Retriever R: 검색기(Retriever)를 제거 → 성능 하락 (PQA: 43.6, Med: 67.8, AS: 31.0)
- No Critic C: 비평가(Critic)를 제거 → 성능 큰 폭 하락 (PQA: 42.6, Med: 72.0, AS: 18.1)
- Test 단계에서의 Ablation
- No retrieval: 검색 없이 동작 → PQA 성능 급락 (24.7), Med는 비슷 (73.0)
- Hard constraints: 강한 제약 적용 → Med 성능 소폭 상승 (72.6)
- Retrieve top1: 검색 결과 1개만 사용 → 전반적 성능 하락
- Remove IsSUP: IsSUP(특정 지원 토큰) 제거 → 성능 소폭 하락
(b) ASQA 인용 정확도 및 유창성(Mauve)에 대한 soft weight(가중치) 효과
- Precision(정밀도)과 Mauve(유창성) 지표가 IsSupport 가중치 변화에 따라 어떻게 변하는지 그래프로 나타냄.
- IsSupport 가중치가 증가할수록 Precision은 상승, Mauve는 감소.
- 즉, 지원 토큰의 가중치를 높이면 정확도는 오르지만, 유창성(자연스러움)은 다소 떨어짐.
(c) PubHealth와 PopQA에서 검색 빈도 및 정규화된 정확도 변화
- PubHealth, PopQA 데이터셋에서의 검색 빈도와 정규화된 정확도
- Retrieval Threshold(검색 임계값)가 높아질수록 Accuracy(정확도)는 감소, Frequency(검색 빈도)도 감소.
- 즉, 임계값을 높이면 검색이 덜 일어나고, 이에 따라 정확도도 떨어짐.
04. 학습 규모 및 Human analysis
- SELF-RAG는 학습 데이터가 많을수록 성능이 전반적으로 향상됨을 확인함
- Huaman analysis 평가에서도 PopQA와 Bio 분야 모두에서 높은 신뢰성과 사실성, 인용 관련성 점수를 받음
=> SELF-RAG가 다양한 도메인에서 신뢰할 수 있는 답변과 인용을 생성할 수 있음을 시사함

(a) PopQA
- 학습 데이터가 늘어날수록 PopQA에서의 성능이 꾸준히 증가
(b) PubHealth
- 데이터가 늘어날수록 성능이 빠르게 향상되다가, 이후 약간 감소
(c) ASQA (prec)
- 학습 데이터가 늘어날수록 인용 정확도가 크게 향상됨
(d) Human evaluation on PopQA and Bio generation
- PopQA와 Bio(생의학) 생성 결과에 대해 여러 기준으로 사람 평가 점수 결과
- S & P: Support & Plausibility(근거 및 그럴듯함)
- IsREL: 인용이 관련 있는지
- IsSUP: 인용이 주장을 뒷받침하는지
