‼️ 개인 학습 내용으로, 오류가 있을 수 있습니다.
논문 URL - https://arxiv.org/abs/1706.03762
Introduction
-
순환 신경망(Recurrent Neural Networks), 장단기 메모리(Long Short-Term Memory)와 게이트 순환 신경망(Gated Recurrent Neural Networks)은 언어 모델링 및 기계 번역과 같은 시퀀스 모델링 및 변환 문제에서 SOTA 접근법으로 확고히 자리잡았다.
- 순환 신경망(RNN) : 시퀀스 데이터 처리에 특화된 신경망으로, 이전 상태의 정보를 현재 상태에 전달하는 구조
- 장단기 메모리(LSTM) : RNN의 변형으로 장기 의존성 문제를 해결하기 위해 게이트 메커니즘을 도입
- 게이트 순환 신경망(GRU) : LSTM의 간소화 버전으로 계산 효율성을 개선
-
순환 모델은 일반적으로 입력 및 출력 시퀀스의 심볼 위치에 따라 계산을 구성함
-
계산 시간 단계에 위치를 정렬함으로써, 이전 은닉 상태(ht-1)와 위치 t의 입력을 함수로 사용하여 은닉 상태 ht의 시퀀스를 생성.
-
이러한 순차적 특성은 훈련 예제 내에서 병렬화를 방해하며, 시퀀스 길이가 길어질수록 메모리 제약으로 인해 예제 간 배치 처리에 제한이 가해짐.
-
최근 연구에서는 인수분해 기법(factorization tricks)과 조건부 계산(conditional computation)을 통해 계산 효율성을 크게 향상시켰으며, 후자의 경우 모델 성능도 개선되었다. 그러나 순차적 계산의 근본적인 제약은 여전히 남아 있다.
-
Attention Mechanisms은 다양한 작업에서 강력한 시퀀스 모델링 및 변환 모델의 핵심 요소로 자리잡았으며, 입력 또는 출력 시퀀스 내 요소 간 거리와 무관하게 의존성 모델링을 가능하게한다. 이러한 Attention Mechanisms은 순환 신경망(RNN)과 결합하여 사용된다.
- Attention : 어텐션의 기본 아이디어는 디코더에서 출력 단어를 예측하는 매 시점(time step)마다, 인코더에서의 전체 입력 문장을 다시 한 번 참고한다는 점입니다. 단, 전체 입력 문장을 전부 다 동일한 비율로 참고하는 것이 아니라, 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중(attention)해서 보게 됩니다.(출처)
-
순환 구조(recurrence)를 배제하고, 오직 Attention mechanism만을 활용해 입력과 출력 간의 전역적 의존성(global dependencies)을 학습하는 트랜스포머(Transformer) 모델 아키텍처를 제안한다.
Conclusion
-
이번 연구에서 순환 계층(recurrent layers)을 완전히 제거하고, 다중 헤드 셀프 어텐션(multi-headed self-attention)으로 대체한 최초의 순수 어텐션(attention) 기반 시퀀스 변환 모델인 트랜스포머(Transformer)를 제안했다.
-
번역 작업에서 트랜스포머는 순환 신경망 또는 합성곱 층 기반 모델 구조보다 상당히 빠르게 학습되었다. WMT 2014 영어-독일어 및 영어-프랑스어 번역 과제에서 트랜스포머는 SOTA를 달성했으며, 특히 영어-독일어 작업에서는 기존의 모든 앙상블 모델을 능가하는 결과를 보였다.
-
트랜스포머(Transformer)를 텍스트 외에도 이미지, 오디오, 비디오 같은 다양한 입력 및 출력 양식에 적용하고, 대규모 입출력을 효율적으로 처리하기 위해 제한된 지역 어텐션(local, restricted attention) 메커니즘을 연구할 예정이다. 또한 생성(generation) 과정의 순차적 특성을 줄이는 것도 우리의 핵심 연구 목표 중 하나이다.
Figures
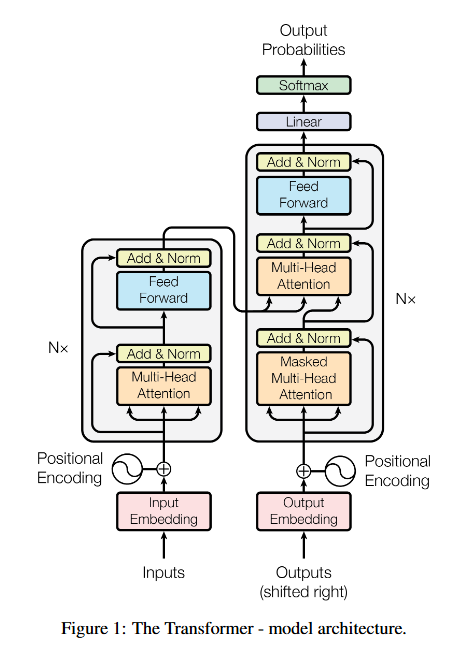
01. 작동 원리
-
Encoder
- 계층 구성 : 6개의 동일한 레이어 스택
- 구조
① Multi-Head Attention - 입력 시퀀스 내 모든 위치 간 관계 분석
② Feed Forward 신경망 - 개별 위치별 비선형 변환 적용 - 기술적 특징
- 잔차 연결(Residual Connection) 적용 후 레이어 정규화(LayerNorm)
- 입출력 차원: 모든 서브층/임베딩은 d_model = 512로 통일
-
Decoder
- 계층 구성 : 인코더와 동일한 6개 레이어 스택
- 추가 기능
③ 인코더-디코더 어텐션 - 인코더 출력에 대한 멀티헤드 어텐션 수행 - 변경 사항 : 마스크드 셀프 어텐션 적용
- 현재 위치보다 미래의 토큰을 참조하지 못하도록 마스킹
- i번째 예측은 1 ~ i-1 위치의 출력만 의존함 (auto-regressive 특성(자기 자신의 과거 데이터로 미래를 예측) 보장)
- 현재 위치보다 미래의 토큰을 참조하지 못하도록 마스킹
- 공통 구조 : 인코더와 동일한 잔차 연결 + 레이어 정규화 사용
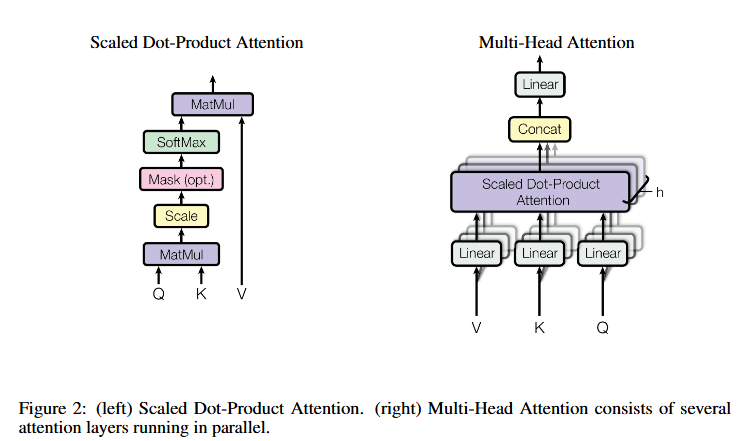
02. Attention
Scaled Dot-Product Attention
-
입력 구성
- 쿼리(Query, Q): 차원
d_q - 키(Key, K): 차원
d_k - 값(Value, V): 차원
d_v
- 쿼리(Query, Q): 차원
-
연산 과정
- 내적 계산 - 모든 쿼리-키 쌍의 내적(Q·K) 계산
- 스케일링 - 각 내적 값을
√d_k로 나눔 - 가중치 계산 - 소프트맥스(softmax) 적용 → 값(V)에 대한 가중치 생성
-
행렬 연산 구현
- 병렬 처리 - 쿼리(Q), 키(K), 값(V)을 행렬로 묶어 처리
-
수식 표현
- QK^T: 쿼리와 키의 유사도 행렬
- √d_k: 그래디언트 소실 방지를 위한 스케일링 인자
-
다른 어텐션 메커니즘 비교
유형 계산 방식 장단점 Dot-Product QK^T (스케일링 포함) 빠른 연산, 최적화된 행렬 곱 활용 Additive FFN(단일 은닉층)으로 호환성 계산 이론적 복잡도 유사 but 느린 구현 -
스케일링의 중요성
- 문제점 :
d_k값이 클 경우 -> 내적 값이 과도하게 커짐, 소프트맥스 그래디언트 소실 발생 - 해결책 :
√d_k로 스케일링하여 값의 범위 안정화
- 문제점 :
Multi-Head Attention
- 단일 어텐션 대신, 쿼리(Query), 키(Key), 값(Value)을 각각 선형 변환하여 병렬로 여러 개의 어텐션을 수행하는 방식
- 서로 다른 위치에서 다양한 표현 서브스페이스(subspace)의 정보를 동시에 참조 가능
- 다양한 표현 서브스페이스를 동시에 학습 가능.
- 단일 어텐션에서 발생하는 정보 손실(평균화 효과)을 방지.
- 연산 과정
① 선형 변환 : 쿼리(Q), 키(K), 값(V)를 각각 , , 차원으로 선형 변환- 프로젝션 행렬
- 프로젝션 행렬
② 병렬 어텐션 수행 : 각 변환된 Q, K, V에 대해 병렬로 어텐션 수행
③ 결과 결합 : 병렬로 생성된 모든 헤드를 결합하고 최종 선형 변환
- 결합 행렬:
- 설정 및 특징
- 헤드 수 (h): 8개
- 각 헤드의 차원:
- 계산 비용: 각 헤드의 차원이 줄어들어 단일 헤드 어텐션과 유사한 계산 비용 유지