‼️ 개인 학습 내용으로, 오류가 있을 수 있습니다.
논문 URL - https://arxiv.org/abs/2501.09136
Foundations of RAG
RAG 의 핵심 요소
- Retrieval(검색)
- 외부 데이터 소스(지식 base, API, vector DB 등)에서 쿼리와 연관된 데이터를 검색한다.
- 고급 검색(Advanced Retrieval)은 딥러닝 기반의 임베딩(embedding)과 트랜스포머(transformer) 모델을 활용해, 단순 키워드 일치가 아닌 의미 기반(semantic) 검색을 수행한다.
- Augmentation(증강)
- 검색된 데이터에서 가장 연관성이 높은 정보를 추출하고 요약한 후 쿼리 맥락에 맞게 정리한다.
- Generation(생성)
- 검색된 정보를 LLM의 사전 학습된 지식과 결합하여 일관성있고 적절한 응답을 생성한다.
RAG Paradigms
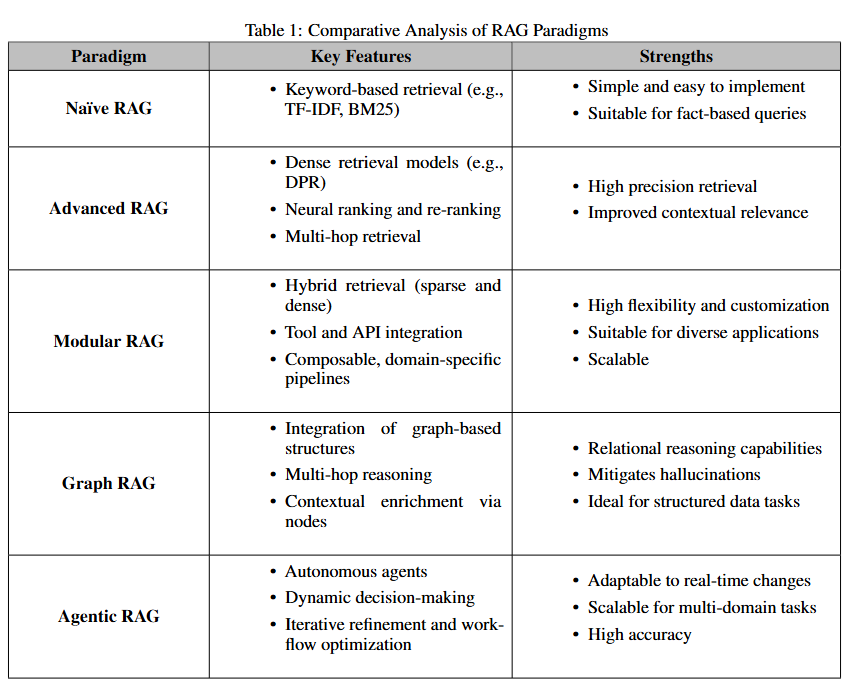
01. Naïve RAG
-
기본 개념: Naïve RAG는 검색-증강 생성(RAG)의 기본 구현체로, 단순한 "검색-읽기" 워크플로우를 사용한다.
-
검색 방식: TF-IDF, BM25* 같은 키워드 기반 검색 기술을 활용하여 정적 데이터셋에서 문서를 검색한다.
- "Best Matching 25"의 약자로, 문서와 질의(query) 간의 관련성을 평가하기 위해 사용되는 랭킹 함수
-
생성 프로세스: 검색된 문서를 언어 모델(LM)의 생성 능력을 증강하는 데 활용하여 응답을 생성한다.
-
장점:
- 단순성과 구현 용이성을 지닌다.
- 사실 기반 질의 처리에 적합하며, 복잡한 맥락을 요구하지 않는 작업에 적용된다.
-
한계:
- 맥락 인식 부족: 어휘 일치(lexical matching)에 의존하기 때문에 질의의 의미적 뉘앙스를 포착하지 못한다.
- 단편화된 출력: 전처리나 맥락 통합 과정이 부족해 응답이 일관성 없거나 지나치게 일반화되는 경향이 있다.
- 확장성 문제: 대규모 데이터셋에서 키워드 기반 검색을 사용하는 것은 관련 정보 식별에 어렵다.
-
의의: 이러한 한계점에도 불구하고, Naïve RAG 시스템은 검색(retrieval)과 생성(generation)의 통합을 입증하는 중요한 개념 검증(proof-of-concept) 역할을 하며, 더 정교한 패러다임의 기반을 마련했다.
02. Advanced RAG
-
개발 배경: Naïve RAG의 한계(의미 이해 부족, 단순 검색 방식)를 극복하기 위해 개발되었다.
-
핵심 기술:
- 의미 기반 검색: 질의와 문서를 고차원 벡터 공간에 매핑해 의미적 정렬을 개선하는 Dense Vector Search를 활용한다.
- 맥락 재정렬: 신경망 모델을 통해 검색 결과를 재정렬하여 관련성 높은 정보를 우선시하는 Contextual Re-Ranking을 적용한다.
- 반복 검색: 다중 문서 간 추론이 가능한 Iterative Retrieval(멀티홉 검색)을 도입해 복잡한 질의를 처리한다.
-
적용 분야: 연구 종합(합성), 맞춤형 추천 시스템 등 고정밀도와 세밀한 이해가 필요한 작업에 적합하다.
-
한계: 대규모 데이터셋 및 다단계 질의 처리 시 계산 복잡성과 확장성 문제가 남아있다
03. Modular RAG
-
핵심 개념: RAG 패러다임의 최신 진화형으로, 유연성과 맞춤화를 강조한다. 검색-생성 파이프라인을 독립적·재사용 가능한 모듈로 분해해 도메인별 최적화와 작업 적응성을 확보한다.
-
특징:
- 하이브리드 검색: 희소 검색(BM25)과 밀집 검색(DPR)을 결합해 다양한 질의 유형에 대한 정확도를 극대화한다.
- 외부 도구 통합: 실시간 데이터 분석·전문 계산을 위해 API·DB·계산 도구를 통합한다.
- 조합형 파이프라인: 검색기·생성기 모듈을 독립적으로 교체·개선할 수 있어 특정 작업에 맞는 유연한 구성을 지원한다.
-
적용 사례: 금융 분석 시스템이 실시간 주가 API 조회, 밀집 검색 기반 과거 트렌드 분석, 맞춤형 언어 모델을 결합해 투자 인사이트를 생성하는 방식으로 활용된다.
-
장점: 다중 도메인 복잡 작업에 적합하며 확장성과 정밀도를 동시에 제공한다.
04. Graph RAG
-
핵심 개념: 기존 RAG 시스템을 그래프 기반 데이터 구조와 통합해 다중 홉 추론(multi-hop reasoning) 및 맥락 강화를 개선한다.
-
특징:
- 노드 연결성: 엔터티 간 관계 포착 및 추론
- 계층적 지식 관리: 구조화/비구조화 데이터를 그래프 계층으로 통합
- 맥락 강화: 그래프 경로 기반 관계 이해 강화
-
적용 분야: 의료 진단, 법률 연구 등 구조적 관계 추론이 중요한 도메인
-
한계:
- 확장성 제한: 대규모 데이터 처리 시 그래프 구조 의존성 문제
- 데이터 의존성: 고품질 그래프 데이터 필요
- 통합 복잡성: 비구조화 데이터 시스템과의 통합 난이도
05. Agentic RAG
-
핵심 개념:
- 자율적 에이전트와 동적 의사결정을 기반으로 한 패러다임 전환을 구현한다.
- 기존 정적 시스템과 달리 반복적 개선 및 적응형 검색 전략을 통해 복잡한 실시간·다중 도메인 질의를 처리한다.
-
특징:
- 자율적 의사결정: 쿼리 복잡도에 따라 검색 전략을 자동 평가·관리한다.
- 피드백 루프: 검색 정확도와 응답 관련성을 지속적으로 개선한다.
- 워크플로 최적화: 실시간 애플리케이션에서 작업을 동적으로 조율해 효율성을 확보한다.
-
적용 분야: 고객 지원, 금융 분석, 적응형 학습 플랫폼 등 동적 적응성과 맥락 정밀도가 중요한 영역에서 우수한 성능을 보인다.
-
한계:
- 조율 복잡성: 다중 에이전트 상호작용 관리의 어려움.
- 계산 부하: 복잡한 워크플로에서의 자원 소모 증가
- 확장성 제약: 대규모 쿼리 처리 시 자원 한계
전통적 RAG 시스템의 주요 한계
-
정적 워크플로우와 제한된 적응성으로 다단계 추론 및 실제 문제 처리에 취약하다.
-
맥락 통합 문제: 검색된 정보를 응답에 자연스럽게 통합하지 못해 단편적·일반화된 결과를 생성한다.
(e.g. 알츠하이머 치료 최신 동향 쿼리 시 연구 결과를 환자 맞춤형 설명으로 연결하지 못하거나, 건조지역 농업 지속가능성 질의에 특화된 방법을 누락한다.) -
다단계 추론 부족: 복잡한 질의에 대한 다중 문서/단계 추론이 어려워 정교한 분석이 제한된다.
-
확장성 및 지연 문제: 대규모 데이터셋 처리 시 검색 지연과 자원 효율성 저하가 발생한다.
-
-
Agentic RAG 혁신:
-
자율적 에이전트: 동적 의사결정·반복적 추론·적응형 검색 전략을 도입해 기존 모듈식 구조의 한계를 극복한다.
-
핵심 강점:
- 워크플로우 최적화: 지연 시간 감소 및 확장성 개선
- 반복적 정제: 피드백 루프를 통한 출력 정확도 향상
- 맥락 이해 강화: 다중 도메인 복잡 작업 처리 능력 확대
-
의의: 차세대 AI 애플리케이션의 핵심 기술로 자리매김하며, 실시간 분석 및 맞춤형 의사결정 분야에서 혁신적 가능성을 제시한다.
-
Agentic Intelligence의 핵심 원칙과 배경
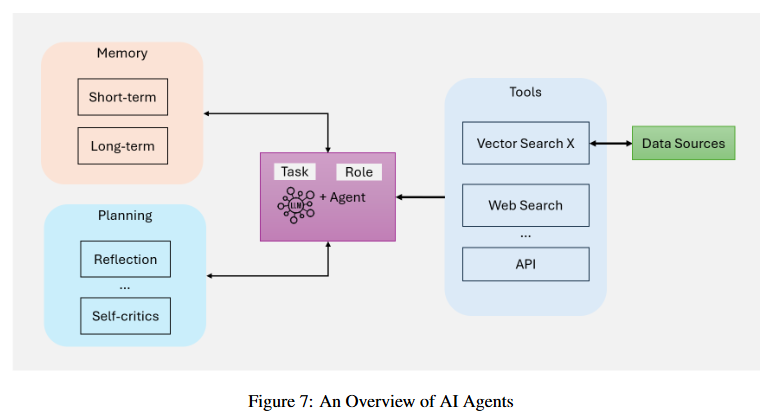
AI 에이전트 핵심 구성 요소
1) LLM(역할 및 작업 정의):
- 추론 엔진 역할: 사용자 질의 해석, 응답 생성, 대화 일관성 유지
- 도메인 특화: 금융 분석·의료 진단 등 특정 작업에 맞춤화된 역할 수행
2) 메모리 시스템:
- 단기 메모리: 현재 대화 상태 및 즉시 맥락 추적
- 장기 메모리: 축적된 지식·경험을 벡터 DB에 저장해 재사용
3) 계획 및 자기 검토:
- 반복적 추론: 복잡 작업을 단계별로 분해하여 실행(예: "Maker-Checker" 프로세스)
- 자기 비판(Self-Critique): 생성 결과의 정확성·적절성 평가 후 수정
4) 도구 통합
- 벡터 검색: 의미 기반 문서 검색
- 웹 검색/API: 실시간 데이터 수집(예: 주가·날씨 정보)
- 전문 계산 도구: 수학적 분석·시뮬레이션 수행
핵심 패턴
1) Reflection
-
핵심 개념: 에이전트 워크플로우에서 반복적 평가·개선을 가능케 하는 기초 설계 패턴
-
작동 메커니즘:
- 자기 피드백: 에이전트가 출력물의 오류, 불일치, 개선점을 식별·수정하여 코드 생성·텍스트 생산·질의응답 성능을 향상시킨다.
- 외부 도구 통합: 단위 테스트·웹 검색으로 결과 검증 및 공백 보완.
-
다중 에이전트 시스템:
- 역할 분담: 한 에이전트는 출력 생성, 다른 에이전트는 비판을 담당해 협업적 개선을 촉진한다(예: 법률 연구 시 판례 재평가를 통한 정확성 확보).
- 검증 사례: Self-Refine, Reflexion, CRITIC 연구에서 성능 향상이 입증되었다.
2) Planning
- 계획(Planning) 패턴은 에이전트 기반 워크플로우에서 복잡한 작업을 소규모 하위 작업으로 분해하고 동적 의사결정을 가능케 하는 핵심 설계 원리이다.
- 다단계 추론과 유연한 문제 해결에 필수적이다.
3) Tool Use
-
핵심 개념: 외부 도구·API와의 상호작용을 통해 에이전트의 능력 확장 및 정확도 향상을 지원한다
-
주요 기능:
- 정보 수집: 웹 검색·벡터 DB 조회
- 계산 수행: 수학적 모델링·데이터 분석
- 데이터 조작: 외부 시스템(예: CRM·ERP)과의 실시간 연동
-
기술 발전:
- GPT-4 함수 호출: 도구 선택·실행 자동화
- 다중 도구 관리: 작업별 최적 도구 동적 선택(예: 날씨 API + 경제 지표 DB 병행 사용).
-
도전 과제:
- 도구 선택 최적화: 대규모 도구 풀에서의 효율적 선택(예: 휴리스틱 기반 접근법)
- 오류 전파 방지: 도구 실행 실패 시 대체 전략 수립.
4) Multi-Agent
-
핵심 개념: 전문화된 에이전트들이 병렬 처리 및 작업 분담을 통해 복잡한 워크플로우를 효율적으로 관리하는 설계 패턴
-
주요 특징:
-
작업 분해: 복잡한 목표를 하위 작업으로 분할해 전문 에이전트에게 할당(예: 마케팅 전략 수립 → 시장 조사·경쟁사 분석 에이전트 분리)
-
동적 협업: 중간 결과 공유 및 조율을 통한 일관성 유지(예: 의료 진단 시 증상 분석·처방 생성 에이전트 협업)
-
자율성: 각 에이전트는 독립적 메모리·도구·계획 방식을 보유
-
동적 협업을 위한 적응형 전략
- 프롬프트 체이닝(Prompt Chaining)
-
정의: 복잡한 작업을 순차적 단계로 분해하여 각 단계의 결과가 다음 단계 입력으로 사용되는 패턴
-
목적:
- 정확도 향상: 단순화된 하위 작업 처리로 LLM의 인지 부하 감소 및 환각(hallucination) 최소화
- 단계별 검증: 각 단계에서 출력 검증을 통해 최종 결과 품질 제어
-
적용 시기
- 적합 시나리오:
- 작업이 고정된 하위 단계로 명확히 분해 가능할 때
- 단계별 추론이 최종 결과 품질을 결정하는 경우(예: 다언어 번역·문서 생성)
- 비적합 시나리오: 실시간 응답이 요구되거나 동적 환경에서의 복잡한 의사결정이 필요한 경우
- 적합 시나리오:
- 라우팅(Routing)
-
정의: 입력을 분류한 후 전문적인 처리 과정으로 전달하는 패턴
-
목적:
- 효율성 향상: 작업 유형별 최적화된 처리로 자원 낭비 감소
- 응답 품질 강화: 특화된 프로세스에 따른 정확도 개선
-
적용 시기
- 적합 시나리오:
- 서로 다른 유형의 입력이 별도의 처리 전략을 필요로 할 때
- 비용 효율성·성능 균형이 요구될 때(예: 단순/복잡 질의 분리)
- 비적합 시나리오: 입력 분류 기준이 모호하거나 실시간 동적 분기가 빈번한 경우
- 적합 시나리오:
- 에이전트 워크플로우 패턴: 병렬화(Parallelization)
- 개념 및 특징
- 정의: 작업을 독립적인 여러 프로세스로 나누어 동시에 실행함으로써 처리 속도 향상과 지연 시간 감소를 달성하는 패턴
- 유형
- 섹셔닝(Sectioning): 독립적 하위 작업 분할 및 병행 처리- 보팅(Voting): 여러 모델의 결과를 비교·검증해 정확도 및 신뢰도 향상
- 적용 시기
- 작업이 독립적으로 분리 가능해 동시에 처리할 수 있을 때- 다중 출력이 결과 신뢰도를 높이는 경우(예: 코드 취약점 점검)
- Orchestrator-Workers 패턴 요약
-
개념: 중앙에 위치한 오케스트레이터(Orchestrator) LLM이 복잡한 작업을 동적으로 하위 작업으로 분해하고, 각 하위 작업을 전문화된 워커(Worker) LLM에 할당한 뒤, 이들의 결과를 종합하여 최종 출력을 생성하는 워크플로우 패턴이다.
-
특징:
- 하위 작업은 사전에 정의되지 않고, 오케스트레이터가 입력의 복잡성에 따라 실시간으로 결정한다.
- 워커들은 각자 특화된 역할과 지식을 바탕으로 할당된 작업을 수행한다.
- 오케스트레이터는 작업 분배뿐 아니라 결과 통합과 조율도 담당한다.
- 동적이고 유연한 작업 분해와 할당이 가능하여 실시간 적응력이 뛰어나다.
-
적용 사례:
- 코드베이스 내 여러 파일을 자동으로 수정하는 복잡한 소프트웨어 작업.
- 여러 출처에서 정보를 수집하고 종합하는 실시간 연구 및 분석 작업.
- 시스템 장애 대응 시 로그, 메트릭, 배포 이력 등 다양한 데이터를 수집·분석하여 원인 보고서 작성
- Evaluator-Optimizer 패턴
- 개념: 초기 출력을 생성한 후, 평가 모델의 피드백을 바탕으로 반복적으로 내용을 개선하는 워크플로우 패턴이다.
- 적용 시기: 명확한 평가 기준이 존재하고, 반복적 개선을 통해 응답 품질이 크게 향상될 때 효과적이다.
