‼️ 개인 학습 내용으로, 오류가 있을 수 있습니다.
논문 URL - https://arxiv.org/pdf/1907.11692
Training Procedure Analysis
4.1 Static vs. Dynamic Masking
- BERT는 입력 토큰을 무작위로 마스킹하고, 그 마스크된 토큰을 예측하는 방식에 의존한다.
- BERT의 원래 구현에서는 마스킹 작업을 데이터 전처리 단계에서 한 번만 수행하여, 하나의 고정(static)된 마스크만 생성했다.
- but, 모든 에폭(epoch)마다 동일한 시퀀스가 항상 동일하게 마스킹되어 등장하는 문제가 있다.
- 이를 피하기 위해 학습 데이터를 10번 중복(duplicate)시켰고, 이 과정에서 각 시퀀스는 10가지 서로 다른 마스킹 방식으로 구성되었다.
- BERT는 총 40 에폭 동안 학습하기 때문에 각 시퀀스별로 마스킹된 상태로 4번(40/10=4) 학습 중에 다시 나타나게 된다. 즉, 한 시퀀스가 같은 마스크로 4번씩 모델에 입력된다는 의미다.
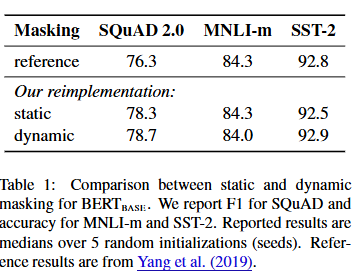
Table 1 : static, dynamic 마스킹 성과 비교
- static masking으로 재현한 모델은 원래의 BERT와 거의 비슷한 성능을 보였다.
- dynamic masking의 경우, static masking과 비슷하거나 약간 더 좋은 성능을 기록했다.
- 이 결과와 함께 dynamic masking은 더 좋은 효율성(메모리 및 관리 측면에서도 유리)을 제공하므로 이후의 모든 실험에서는 dynamic masking 방식을 사용했다.
4.2 Model Input Format and Next Sentence Prediction
-
원래의 BERT 사전학습 절차에서는, 모델이 두 개의 문서 조각(document segments)을 연결(concatenate)한 입력을 본다.
- 이 두 조각은 1) 50% 확률로 같은 문서에서 연속적으로 샘플링되거나, 2) 그렇지 않으면 서로 다른 문서에서 가져온다.
-
BERT는 마스킹 언어 모델링(Masked Language Modeling) 목표 외에도, 이 두 문서 조각이 같은 문서에서 왔는지, 또는 서로 다른 문서에서 왔는지를 예측하는 보조적인 NSP(Next Sentence Prediction) 손실을 학습하게 된다.
-
NSP 손실은 원래 BERT 모델을 훈련하는 데 중요한 요소라고 가정되었으며,Devlin 등(2019)은 NSP를 제거하면 QNLI, MNLI, SQuAD 1.1 등에서 성능 저하가 뚜렷하게 발생한다고 보고했다.
- 하지만 최근 일부 연구들은 NSP 손실이 실제로 필요한지에 대해 의문을 제기해 왔다.
-
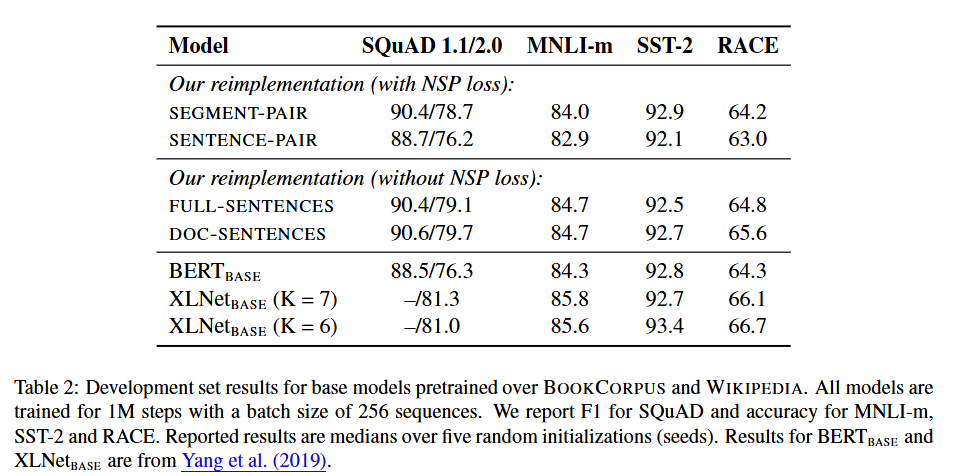
이런 차이를 더 잘 이해하기 위해 여러 가지 대체 학습 방식들을 비교한다.(Table 2)
| 방식 | 특징 |
|---|---|
| SEGMENT-PAIR+NSP | 여러 문장 포함, NSP 사용 (BERT 원래 방식) |
| SENTENCE-PAIR+NSP | 한 쌍의 단일 문장, NSP 사용, 다운스트림 성능 저하 |
| FULL-SENTENCES | 여러 문장, 문서 경계 넘어감, NSP 미사용 |
| DOC-SENTENCES | 여러 문장, 한 문서 내, NSP 미사용 |
결과
1) SEGMENT-PAIR+NSP vs. SENTENCE-PAIR+NSP
- SEGMENT-PAIR+NSP(BERT 원래 방식)과 SENTENCE-PAIR+NSP를 비교하면, 모두 NSP loss를 쓰지만 후자는 단일 문장 쌍을 사용한다는 차이점이 있다.
- 개별 문장 쌍(SENTENCE-PAIR+NSP)을 사용할 경우, 다운스트림 태스크 성능이 하락하는데 이는 모델이 긴 범위의 의존성(long-range dependencies)을 충분히 학습하지 못하기 때문이라고 가정된다.
2) FULL-SENTENCES vs. DOC-SENTENCES
- NSP(Next Sentence Prediction) 손실 없이, 한 문서 내에서 연속적으로 추출한 텍스트 블록(DOC-SENTENCES)만을 사용해 BERT를 학습한 결과, 이 방식이 기존에 공개된 BERT_BASE 결과를 오히려 능가함을 발견했다.
- 즉, NSP 손실을 제거하면 다운스트림 태스크 성능이 동등하거나 약간 더 향상되는 효과가 있으며, 이는 Devlin et al. (2019)의 주장(“NSP가 필수적이다”)과는 대조적이다.
4.3 Training with large batches
-
기존의 연구와 최근의 실험들은 BERT와 같은 딥러닝 모델에서 매우 큰 미니 배치(large mini-batch) 학습이 최적화 속도와 최종 태스크 성능 모두를 개선할 수 있음을 보여준다.
-
BERT에서도 대규모 배치 학습의 효과가 나타난다.
- Devlin et al.(2019)은 BERTBASE를 1백만 스텝 동안 배치 크기 256으로 학습했다.
- 계산량 기준으로 보면, 배치 256 × 1M스텝 ≈ 배치 2K × 12.5만스텝 ≈ 배치 8K × 3.1만스텝과 같다.
-
실험적으로, 동일 학습량(에포크당 전체 데이터 패스 수는 동일)을 가정하고 배치 크기를 키울수록 (예: 8K~32K) 마스킹 언어모델(perplexity) 및 다운스트림 성능이 모두 향상됨을 관찰했다.
4.4 Text Encoding
1. Byte-Pair Encoding(BPE)
- 정의 : 문자 단위와 단어 단위 토크나이징의 절충형 방식으로, 대규모 자연어 데이터의 다양한 어휘에 효과적으로 대응한다.
- 특징 : BPE는 전통적으로 10K~100K 규모의 서브워드(subword) 단위 어휘(vocabulary)를 사용하며, 이는 통계적 분석을 통해 훈련 데이터에서 추출된다.
- 장점 -> 어휘에 없는 희귀 단어나 새로운 단어도 적절히 쪼개서 처리할 수 있다.
- 단점 -> 유니코드 문자 집합은 수만~십만 개에 달하므로, 다양한 언어가 혼합된 큰 코퍼스를 다룰 때 상당히 많은 어휘 공간을 문자 단위가 차지할 수 있다.
2. byte-level BPE
- 정의 : 기본 단위를 "유니코드 문자"가 아니라 "바이트(byte, 256개)"로 삼는 방식이다.
- 특징 : 입력이 어떤 언어, 어떤 특수문자, 어떤 스크립트를 포함하더라도 'unknown' 토큰 없이 모든 텍스트를 인코딩할 수 있다.
비교
-
기존 BPE: 문자 단위 → 대용량코퍼스에선 문자수가 커짐, 특별한 토크나이저(문자수준 BPE와 룰기반 토크나이징) 필요, 'UNK'(unknown 토큰) 발생 가능
-
byte-level BPE: 모든 입력을 손실없이 토크나이즈(256개 바이트만으로 모든 언어 대응), 사전 전처리 불필요, 'UNK' 없음, 어휘표 50K로 제한 가능, 파라미터수 증가
결과
- 실험적으로, 두 방식 모두 다운스트림 성능 차이는 크지 않았지만 byte-level BPE는 약간의 성능 저하가 보이기도 했다.
- 하지만 어떤 텍스트든 "모르는 토큰" 없이 인코딩할 수 있는 보편적(universal) 설계의 장점이 더 크다고 판단, 해당 방식을 채택했다.
