‼️ 개인 학습 내용으로, 오류가 있을 수 있습니다.
논문 URL - https://arxiv.org/abs/1706.03762
Why Self-Attention
-
셀프 어텐션 레이어(self-attention layers)의 다양한 측면을 순환 레이어(recurrent layers), 합성곱 레이어(convolutional layers)와 비교한다.
-
셀프 어텐션을 사용하는 동기를 설명하기 위한 세 가지의 바람직한 기준(desiderata)
- 레이어당 총 계산 복잡도
- 병렬화 가능한 계산량(필요한 순차 연산의 최소 횟수로 측정)
- 네트워크 내 장거리 의존성 간의 경로 길이
-
장거리 의존성 학습과 경로 길이의 중요성
- 많은 시퀀스 변환(sequence transduction) 작업에서 핵심적인 과제이다.
- 이러한 종속성을 학습하는 능력에 영향을 미치는 주요 요소는 네트워크 내에서 순방향(forward) 및 역방향(backward) 신호가 이동해야 하는 경로의 길이이다.
- 입력 시퀀스와 출력 시퀀스의 임의의 위치 조합 사이에서 이 경로가 짧을수록 장거리 의존성을 학습하기 더 쉬워진다.
- 서로 다른 레이어 유형으로 구성된 네트워크에서 두 입출력 위치 간의 최대 경로 길이를 비교한다.
-
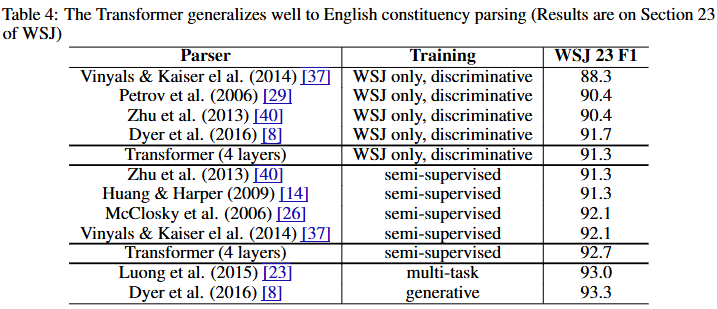
Table 1 설명
- self-attention 레이어는 모든 위치를 일정한 수의 순차적 연산으로 연결(O(1))하는 반면, recurrent 레이어는 O(n)의 순차적 연산이 필요하다.
- 계산 복잡도 측면에서, self-attention 레이어는 시퀀스 길이 n이 표현 차원 d보다 작을 때 recurrent 레이어보다 빠르며, 이는 기계 번역의 최신 모델(예: word-piece 및 byte-pair 표현)에서 일반적으로 사용되는 문장 표현의 경우 대부분 해당된다.
- 매우 긴 시퀀스를 다루는 작업의 계산 성능을 향상시키기 위해, self-attention을 각 출력 위치를 중심으로 입력 시퀀스의 크기 r 이웃만 고려하도록 제한할 수 있다. 이 경우 최대 경로 길이는 O(n/r)로 증가한다.(Self-Attention(restricted) 모델)
-
합성곱 레이어의 연결성 한계
- 표준 합성곱: 커널 크기 k < n인 단일 합성곱 레이어는 모든 입출력 위치 쌍을 연결하지 못함
- 연속 커널(contiguous): O(n/k) 레이어 스택 필요
- 확장 합성곱(dilated): O(logₖ(n)) 레이어 필요 → 네트워크 내 최장 경로 길이 증가

- 계산 복잡도 (Complexity per Layer)
• Self-Attention: 모든 토큰 쌍의 상호작용을 계산하므로 O(n2d)(행렬 곱셈 QKT 및 SoftMax⋅V 비용).
• RNN: 각 시간 단계에서 d×d 가중치 연산이 nn번 반복되므로 O(nd2).
• CNN: 커널 크기 kk와 채널 차원 dd에 의존적 (O(knd2)).
• Restricted Self-Attention: 각 토큰이 주변 rr개 토큰만 참조해 O(rnd)로 복잡도 감소.
- 활용 사례:
• n<dn<d일 때 Self-Attention이 RNN보다 효율적 (기계 번역에서 일반적)
• 매우 긴 시퀀스(문서)에는 Restricted Self-Attention이 적합
- 순차 연산 (Sequential Operations)
• RNN: 순차적 처리로 O(n)의 병렬화 불가능한 연산 필요.
• Self-Attention/CNN: 모든 위치에서 병렬 처리 가능 (O(1)).
- 의미: RNN 대비 Transformer의 학습/추론 속도 우월성.
- 최대 경로 길이 (Maximum Path Length)
• Self-Attention: 임의의 두 토큰 간 직접 연결 (O(1)).
• RNN: nn번의 순차적 단계 필요 (O(n)).
• CNN: 계층적 구조로 O(logkn) (3×3 커널 2층으로 5-gram 포착).
- 영향:
• 장거리 의존성 학습은 경로 길이가 짧을수록 용이 → Self-Attention이 RNN/CNN보다 유리.
• Restricted Self-Attention은 O(n/r)로 효율성과 장거리 학습 사이 트레이드오프
- 제한된 Self-Attention의 활용
• 목적: 긴 시퀀스(예: DNA 서열)에서 계산 부하 완화.
• 방법: 각 토큰이 주변 r개 토큰만 참조 (e.g., r=128).
• 장단점:계산 복잡도는 O(rnd)로 감소하지만, 장거리 의존성 학습 능력 저하 (O(n/r)).
Training
데이터 학습 및 배칭
데이터셋 사양
| 언어 쌍 | 데이터셋 | 문장 쌍 수 | 토큰화 방식 | 어휘장 크기 |
|---|---|---|---|---|
| 영어-독일어 | WMT 2014 | 4.5M | Byte-Pair Encoding | 37,000 |
| 영어-프랑스어 | WMT 2014 | 36M | Word-Piece | 32,000 |
학습 구성
- 배치 생성 전략: 근사 시퀀스 길이 기준 문장 쌍 그룹화
- 배치 용량:
- 소스 언어 ~25,000 토큰
- 타겟 언어 ~25,000 토큰
- 토큰화 특징:
- BPE(Byte-Pair Encoding) : 원천-목표 공통 어휘장 사용
- Word-Piece : 더 큰 데이터셋에 최적화된 분할
하드웨어 & 스케쥴
하드웨어 구성
- 장비: 단일 머신
- GPU: NVIDIA P100 8개
학습 시간 비교
| 모델 유형 | 스텝 시간 | 총 스텝 수 | 총 학습 시간 |
|---|---|---|---|
| Base 모델 | 0.4초 | 100,000 | 12시간 |
| Big 모델 | 1.0초 | 300,000 | 3.5일 |
하이퍼파라미터
- Base 모델: 논문 내 기술된 기본 설정 적용
- Big 모델: 표 3 최하단에 명시된 확장 설정 사용
optimizer
옵티마이저 구성
- 알고리즘: Adam Optimizer
- Momentum + RMSProp 결합체
- 적응형 학습률: 파라미터별 독립적인 학습률 조정
- 모멘텀 적용: 과거 기울기 추세 반영(β₁=0.9)
- 하이퍼파라미터:
- β₁ = 0.9 (모멘텀 계수)
- β₂ = 0.98 (제곱 그래디언트 계수)
- ε = 10⁻⁹ (수치 안정성 상수)
학습률 스케줄링
- 웜업 단계: 4,000 스텝
- 웜업 기간: 선형 증가 (step_num/warmup_steps)
- 후속 조정: step_num⁻⁰·⁵ 비례 감소
정규화
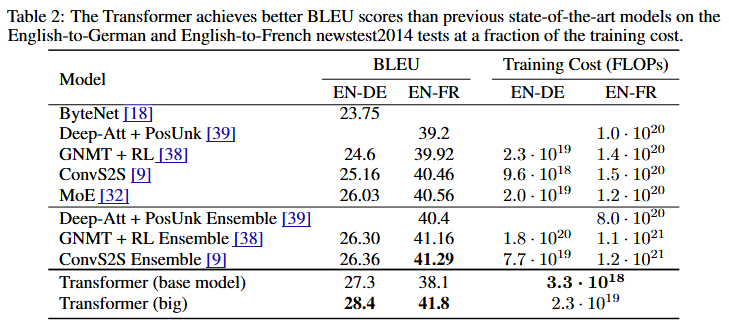
표2 해석
-
성능 대비 비용
- Transformer base 모델: ConvS2S 대비 3배 적은 FLOPs*로 더 높은 BLEU* 달성
- FLOPS(FLoating point Operations Per Second)는 컴퓨터의 성능을 나타내는 단위로, 초당 부동소수점 연산 횟수를 의미
- BLEU(Bilingual Evaluation Understudy)는 기계 번역의 품질을 평가하는 알고리즘
- big 모델: 28.4/41.8 BLEU로 모든 단일 모델을 능가하며 앙상블 모델과 유사 성능
- Transformer base 모델: ConvS2S 대비 3배 적은 FLOPs*로 더 높은 BLEU* 달성
-
기술적 진보
- 기존 RNN/CNN 기반 모델(ByteNet, GNMT) 대비 최대 4.65 BLEU 점수 향상
- 앙상블 없이 단일 모델로 SOTA 달성 가능성 입증
-
경제적 효용
- Deep-Att+PosUnk Ensemble 대비 1/35 학습 비용으로 유사 성능(41.8 vs 40.4)
-
모델에서 사용된 3가지 정규화 기법
1. 잔차 연결 드롭아웃(Residual Dropout)
- 각 서브레이어 출력에 적용(Pdrop=0.1)
- 임베딩과 위치 인코딩 합계에도 적용
- 과적합 방지 및 모델 일반화 향상2. 레이블 스무딩(Label Smoothing)
- εls=0.1 값으로 적용
- 모델의 과신 예방을 통해 BLEU 점수 향상
- 퍼플렉서티는 약간 악화되지만 정확도 개선3. 층 정규화(Layer Normalization)
- 잔차 연결 후 적용되는 정규화
- 특징 차원(d_model) 기준 평균/분산 계산
- 안정적인 학습과 수렴 속도 개선
Results
Machine Translation
-
트랜스포머(Big 모델)는 WMT 2014 영어-독일어 번역 태스크에서 28.4 BLEU라는 새로운 SOTA(State-of-the-Art)를 달성했으며, 이는 앙상블을 포함한 기존 최고 모델 대비 2.0 BLEU 이상 향상된 수치이다.
-
특히 Base 모델도 기존 모든 단일/앙상블 모델을 능가하면서도 훨씬 적은 학습 비용(FLOPs 기준)으로 이러한 성능을 달성했다.
-
이는 트랜스포머 아키텍처의 계산 효율성과 성능 우수성을 동시에 입증하는 결과로, 기존 RNN/CNN 기반 모델 대비 1/4 수준의 학습 비용으로도 더 높은 번역 품질을 보여주었다.
-
주요 성과
- Big 모델: 41.0 BLEU 달성
- 기존 단일 모델 대비 우수성 입증
- SOTA 모델 대비 1/4 이하의 학습 비용 (효율성 증명)
- 드롭아웃 비율 Pdrop=0.1 적용 (기본값 0.3과 차별화)
- Big 모델: 41.0 BLEU 달성
-
학습 및 추론 세부 설정
- 체크포인트 평균화
- Base 모델: 최종 5개 체크포인트(10분 간격) 평균
- Big 모델: 최종 20개 체크포인트 평균
- 빔 서치(Beam Search)*
- 빔 크기: 4
- 길이 패널티: α=0.6 (개발 세트 실험 기반 최적화)
- 출력 길이: 입력 길이 +50 (조기 종료 가능)
* 빔서치 : 각 타임스텝마다 상위 K개(빔 크기) 후보 시퀀스 유지 → 확률 기반 경로 탐색
- 체크포인트 평균화
모델 변형
표3 해석 - Transformer architecture 변형
- 평가 조건
- 데이터셋 : WMT 영-독 번역 개발 세트(newstest2013)
- 메트릭 계산 방식
- 퍼플렉서티: 워드피스(wordpiece) 단위 (바이트 페어 인코딩 적용)
- 단, 일반 단어(word) 단위 퍼플렉서티와 직접 비교 불가
- 기술적 설명
- 실험 설계
- 기본 모델에서 특정 파라미터만 변경하여 변형 모델 구성
- 비교 평가를 위해 다른 조건은 통제
- 워드피스 퍼플렉서티 특성
- 서브워드 토큰화(BPE)로 인해 전통적 단어 단위 메트릭과 수치 차이 발생(예: "transformer" → "trans", "##former"로 분할되어 계산)
- 연구적 의미
- 아키텍처 구성 요소(레이어 수, 어텐션 헤드 등)가 번역 품질에 미치는 영향 분석
- 하이퍼파라미터 최적화를 위한 체계적 접근 방식을 보여줌
- 실험 설계
-
실험 결과
(A) 어텐션 헤드 수 및 차원 변환 실험
- 실험 조건: Section 3.2.2에 따라 계산량을 고정한 상태에서 변경
- 어텐션 헤드 수와 key/value 차원 동시 조정
- 결과
- 단일 헤드(single-head) 사용 시 최적 설정 대비 BLEU 0.9 하락
- 헤드 수 과도하게 증가 시에도 성능 저하 발생 → "적정 헤드 수" 존재 확인(B) 어텐션 Key 차원(dk) 감소 실험
- 관측 결과 : dk 축소 시 모델 품질 하락
- 시사점: 내적(dot product) 기반 호환성 판단이 쉽지 않음 → 향후 더 정교한 호환성 함수 개발 필요(C)/(D) 모델 규모 및 드롭아웃 영향
- C(모델 크기): 대형 모델일수록 우수한 성능 → 규모의 이점 확인
- D(드롭아웃): 과적합 방지에 매우 효과적 → 정규화의 중요성 재확인(E) 위치 인코딩 비교 실험
- 방법: 사인파 위치 인코딩 → 학습형 위치 임베딩으로 교체
- 결과: 기본 모델과 거의 동일한 성능
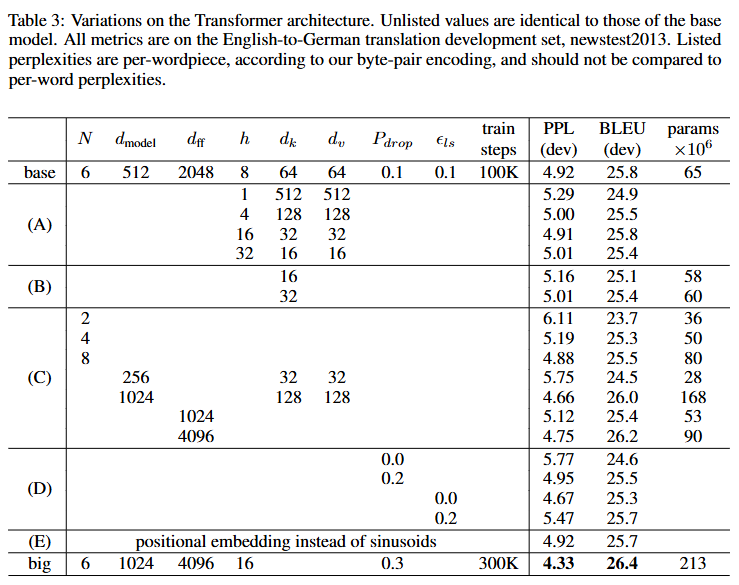
영어 성분 구문 분석(Constituency Parsing)
- 트랜스포머 아키텍처의 다중 작업 일반화 능력 검증
- 주요 결과 (표 4 기준)
- WSJ 전용 학습
- RNN 기반 BerkeleyParser 대비 성능 향상
- 의외성: 과적합 없이 40K 소량 데이터로도 우수한 성능
- 준지도 학습
- Recurrent Neural Network Grammar 제외 모든 기존 모델 능가- 준지도 학습으로 추가 성능 향상 확인
- 계산 효율성 : 4층 구조로 92+ F1(92.7) 달성 → 깊은 RNN 대비 계층 효율성 입증
- 준지도 적응력 :
WSJ only, discriminative(91.3) 대비 추가 데이터(17M 문장) 활용 시 성능 1.4↑ → 확장성 검증 - 한계점 : 생성적 접근법(
generative) 대비 0.6 낮음 → 구문 트리 생성 방식 개선 필요성 시사
- WSJ 전용 학습