‼️ 개인 학습 내용으로, 오류가 있을 수 있습니다.
논문 URL - https://arxiv.org/pdf/2401.15884
Experiments
Tasks, Datasets and Metrics
- CRAG는 네 가지 데이터셋(PopQA, Biography, PubHealth, Arc-Challenge)에서 평가되었다.
- 각 데이터셋은 단답형 생성, 장문 생성, 참/거짓 문제, 객관식 문제로 구성되어 있다.
- 평가 지표로는 PopQA, PubHealth, Arc-Challenge에는 정확도(accuracy)를, Biography에는 FactScore를 사용하였다.
- 이전 연구들과 동일한 평가 기준과 검색 결과를 사용하여 비교 가능성을 높였으며, 차이점은 검색 결과의 품질이 낮다고 판단될 때 이를 보정하는 전략을 추가했다는 점이다.
- 이는 기존 RAG(Retrieval-Augmented Generation) 방식에 보정 전략을 더해 성능을 개선하려는 시도라고 할 수 있다.
Baselines
-
Baselines without retrieval
- 공개 LLM: LLaMA2-7B/13B, Alpaca-7B/13B(지시 튜닝 적용)
- 반복적 개선 기법 적용 모델: CoVE65B(생성 사실성 향상)
- 상용 모델: LLaMA2-chat13B, ChatGPT
-
Standard RAG
- 공개 지시 튜닝 LLM: LLaMA2-7B/13B, Alpaca-7B/13B
- Self-RAG의 지시 튜닝 버전: LLaMA2-7B(Self-RAG 전용 튜닝)
-
Advanced RAG
- SAIL: Alpaca 지시 튜닝 데이터에 검색 문서를 추가해 튜닝
- Self-RAG: GPT-4가 레이블한 반성 토큰 포함 데이터로 LLaMA2 튜닝
- 비공개 데이터 기반: Ret-ChatGPT, Ret-LLaMA-chat, perplexity.ai(InstructGPT 기반)
Results
Table 1: 4개 Dataset에서의 평가 결과
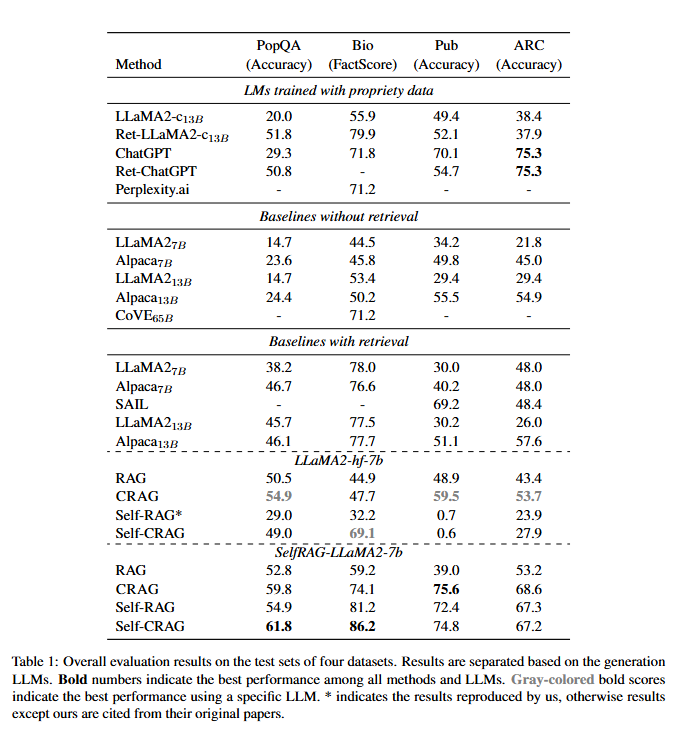
- 주요 결과
- CRAG는 표준 RAG와 Self-RAG 모두에서 성능을 크게 향상시켰다.
- CRAG는 다양한 생성 과제(단답형, 장문, 폐쇄형 문제 등)에서 일관되고 강력한 성능을 보여, 범용성과 일반화 능력을 입증했다.
- CRAG는 기반 LLM 교체에 유연하게 대응할 수 있다.
- SelfRAG-LLaMA2-7b에서 LLaMA2-hf-7b로 변경해도 CRAG는 경쟁력 있는 성능을 유지했으나, Self-RAG는 성능이 크게 하락해 일부 벤치마크에서는 표준 RAG보다도 낮은 성적을 보였다.
- 이는 Self-RAG가 특수 토큰 출력을 위해 별도의 지시 튜닝이 필요한 반면, CRAG는 이런 요구가 없기 때문이다.
- 향후 더 강력한 LLM이 등장해도 CRAG는 손쉽게 결합할 수 있는 'plug-and-play' 특성을 가진다.
Ablation Study
- Ablation Study? 모델의 성능에 가장 큰 영향을 미치는 요소를 찾기 위해 모델의 구성요소 및 feature들을 단계적으로 제거 하거나 변경해가며 성능의 변화를 관찰하는 방법
Table 2: PopQA 데이터셋으로 평가한 액션 제거 결과(정확도 측면에서 성능 변화)
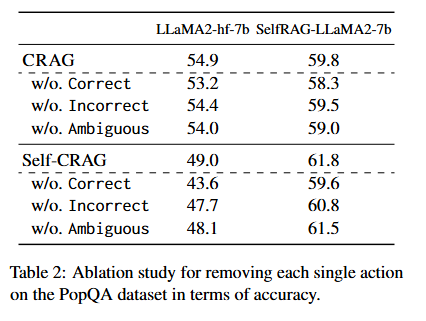
- 각 트리거 액션의 영향에 대해 검증하기 위해, 제안된 방법에서 각 액션을 하나씩 제거하는 ablation 테스트를 진행하였다.
- 실험은 PopQA 데이터셋에서 정확도를 기준으로 성능 변화를 평가하였다.
- Correct 또는 Incorrect 액션을 제거할 경우, 이 두 액션이 Ambiguous와 합쳐져 원래 Correct나 Incorrect로 분류됐던 비율이 Ambiguous로 분류되게 하였다.
- 반대로 Ambiguous 액션을 제거하면, 모든 입력 쿼리가 하나의 임계값에 따라 명확하게 Correct 또는 Incorrect로만 분류되게 하였다.
- 실험 결과, 어떤 액션을 제거하더라도 성능이 하락하는 것을 확인할 수 있었으며, 이는 각 액션이 생성의 견고성을 높이는 데 기여함을 보여준다.
- 추가적으로, 각 액션을 한 번씩만 트리거하는 실험도 진행하였고, 부록에 제시된 결과 역시 일관성을 증명한다.
Table 3: PopQA 데이터셋으로 평가한 연산 제거 결과(정확도 측면에서 성능 변화)
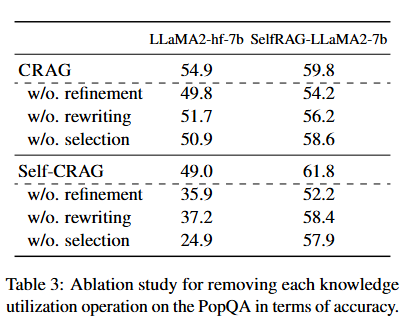
- 각 지식 활용 연산의 영향에 대해 살펴보기 위해, Table 3에서는 주요 지식 활용 연산을 하나씩 제거했을 때 성능이 어떻게 변화하는지 보여준다.
- PopQA 데이터셋에서 정확도를 기준으로, 문서 정제(document refinement), 검색 쿼리 재작성(search query rewriting), 외부 지식 선택(external knowledge selection) 연산을 각각 제거하여 평가를 진행하였다.
- 문서 정제를 제거하면 기존에 검색된 문서를 별도의 정제 없이 바로 생성기에 입력하게 된다.
- 검색 쿼리 재작성을 제거하면, 질문을 키워드로 구성된 쿼리로 변환하지 않고 그대로 지식 검색에 사용한다.
- 외부 지식 선택을 제거하면, 검색된 모든 웹 페이지의 내용을 별도의 선택 없이 외부 지식으로 간주한다.
- 실험 결과, 어떤 지식 활용 연산을 제거하더라도 최종 시스템의 성능이 하락하는 것을 확인할 수 있었으며, 이는 각 지식 활용 연산이 지식 활용도를 높이는 데 기여함을 보여준다.
Accuracy of the Retrieval Evaluator
Table 4: PopQA 데이터셋으로 평가한 모델별 검색 평가자 정확도

- 검색 평가자의 품질이 전체 시스템 성능에 큰 영향을 미친다.
- 문서 검색 결과를 바탕으로, 검색 평가자가 해당 결과의 전반적인 품질을 얼마나 정확하게 판단하는지 평가하였다.
- PopQA 데이터셋에서 검색 평가자와 상용 LLM인 ChatGPT의 평가 정확도를 Table 4에 제시하였다.
- 실험에 사용된 ChatGPT, ChatGPT-CoT, ChatGPT-few-shot 프롬프트는 부록 A 참고
- 결과적으로, 경량 T5 기반 검색 평가자가 모든 설정에서 경쟁 모델인 ChatGPT보다 훨씬 우수한 성능을 보였다.
Robustness to Retrieval Performance
Figure 3: PopQA 데이터셋에서 Self-RAG와 Self-CRAG의 성능 변화
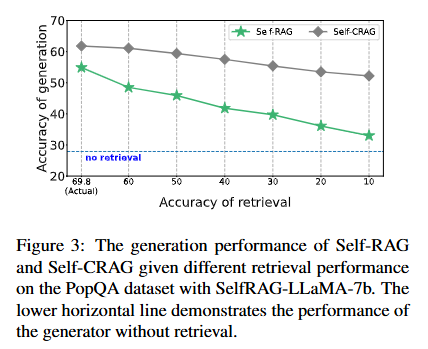
- 제안된 방법의 검색 성능에 대한 견고성을 추가로 검증하기 위해, 검색 성능이 달라질 때 생성 성능이 어떻게 변하는지 연구하였다.
- 낮은 품질의 검색기를 모방하기 위해 일부 정확한 검색 결과를 무작위로 제거하고, 성능 변화를 평가하였다.
- 검색 성능이 하락할수록 Self-RAG와 Self-CRAG 모두 생성 성능이 감소하는데, 이는 생성기가 검색기의 품질에 크게 의존함을 의미한다.
- 또한 검색 성능이 떨어질 때 Self-CRAG의 생성 성능 감소폭이 Self-RAG보다 더 완만하였다. - 이는 Self-CRAG가 Self-RAG보다 검색 성능 저하에 더 견고함을 시사한다.
Consistent Supplementation of Web Search Knowledge
Table 5: PopQA 데이터셋에서 CRAG, Self-CRAG, RAG, Self-RAG 정확도 성능 비교

- 초기 검색 결과가 관련성이 낮거나 신뢰할 수 없을 때, 추가 정보를 활용해 검색 맥락을 보강하는 것이 중요하다.
- 제안한 방법의 주요 성능 향상이 웹 검색을 통한 보조 정보 때문이 아니라, 자기 교정(self-correction) 메커니즘에서 비롯된 것임을 확인하는 것도 중요하다.
- 이를 입증하기 위해, RAG와 Self-RAG 모두 웹 검색 지식으로 꾸준히 보강하여 동일한 범위의 검색 지식에 접근할 수 있도록 하였다.
- Table 5의 결과에 따르면, RAG 또는 Self-RAG에 웹 검색 지식을 지속적으로 보강하면 대부분의 경우 성능이 향상되지만(원본 LLaMA2 모델을 사용하는 Self-RAG w. web은 예외), 그 향상폭은 제한적이다.
- 반면, RAG 또는 Self-RAG에 제안한 자기 교정 메커니즘을 적용하면, 웹 검색 지식만을 추가한 모델들보다 모든 경우에서 훨씬 더 뛰어난 성능을 보였다.
- 이 결과는 관찰된 주요 성능 향상이 제안한 자기 교정 메커니즘에 주로 기인함을 확인시켜준다.
Computational Overhead Analysis
Table 6: computational overhead 평가 결과
- 토큰 하나를 처리할 때 소요되는 연산량(TFLOPs)과 실제 실행 시간(초)을 비교
*FLOPs(Floating point Operations)는 부동소수점 연산의 총 횟수를 의미한다. 딥러닝에서는 주로 신경망 모델이 입력 하나를 처리할 때 필요한 곱셈, 덧셈, 나눗셈, 뺄셈 등 모든 부동소수점 연산의 양을 나타내며, 모델의 복잡성과 계산량을 평가하는 지표로 사용된다. FLOPs가 많을수록 연산량이 많아지고, 이는 학습이나 추론에 더 많은 시간이 소요됨을 의미한다.
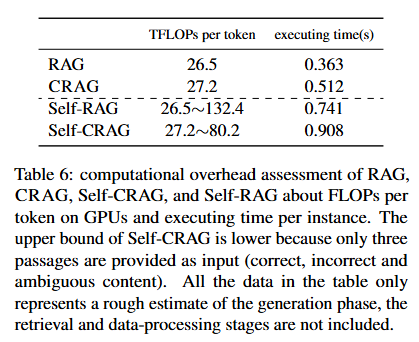
- 자체 수정 메커니즘이 다양한 RAG 기반 프레임워크에 경량 플러그앤플레이 솔루션으로 작동함을 보여주기 위해 계산 오버헤드(소요 자원)를 측정하였다.
- Self-RAG는 입력에 따라 생성 전략이 달라지는 적응적 특성 때문에 계산 오버헤드를 정확히 산출할 수 없어, 추정 범위로 제시하였다.
- 또한 PopQA에서 실제 인스턴스별 평균 실행 시간도 측정하였다.
- 실험 결과, 자체 수정 메커니즘은 성능을 크게 향상(연산량 증가 -> 실질적인 품질 개선으로 연결) 시키면서도 계산 오버헤드는 소폭 증가에 그쳐 경량적임이 입증되었다.

데이터 분석가