‼️ 개인 학습 내용으로, 오류가 있을 수 있습니다.
논문 URL - https://arxiv.org/abs/2005.11401
Results
1. Open-domain Question Answering
-
RAG는 네 가지 오픈 도메인 QA 작업 모두에서 다른 모델보다 우수한 성능을 보임(SOTA)
-
"closed-book" 접근 방식(파라미터 기반)의 생성 유연성과 "open-book" 검색 기반 접근 방식의 성능을 결합
-
REALM과 T5+SSM과는 달리, RAG는 비용이 많이 드는 'salient span masking'* 사전 학습 없이도 우수한 성능을 보임
- 'salient span masking' : 언어 모델의 사전 학습 과정에서 특정한 의미를 가지는 연속된 단어 묶음(스팬)을 선택적으로 마스킹하는 기법. 주로 날짜, 이름과 같은 명시적이고 중요한 정보(e.g. "United Kingdom", "July 1969")를 마스킹 대상으로 삼는다.
-
RAG의 검색기는 Natural Questions와 TriviaQA에서 검색 감독을 사용하여 학습된 DPR(Dense Passage Retrieval)의 검색기를 초기화하여 사용
-
DPR QA 시스템(BERT 기반 "cross-encoder"를 사용해 문서를 재순위하고 추출적 리더를 포함)과 비교했을 때도 유리한 성능을 보이며 최고 성능을 달성하기 위해 재순위기(re-ranker)나 추출적 리더가 필요하지 않음을 입증
-
추출보다 생성이 더 효율적인 이유
1) 단서 기반 생성 가능성
추출 방식은 문서 내에 정답이 명시적으로 존재해야 하지만, RAG는 문서에 단서만 있어도 이를 종합하여 답변 생성 가능
2) 문서 외부 지식 활용
RAG는 검색된 문서에 정답이 없어도 사전 학습된 언어 모델의 지식과 결합하여 답변 생성
-> 실험 결과: NQ 데이터셋에서 RAG는 11.8%의 정확도를 보인 반면, 추출 모델은 0%
3) 효율적인 정보 통합
여러 문서의 단편적 정보를 조합하여 답변을 생성하므로, 단일 문서에 의존하는 추출 방식보다 더 넓은 맥락을 반영 가능
2. Abstractive Question Answering
-
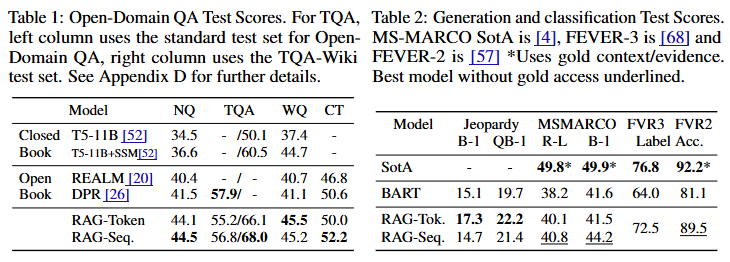
표 2 해석(RAG vs. 최신 모델의 성능 평가 비교)
- RAG-Sequence는 Open MS-MARCO 자연어 생성(NLG) 작업에서 BART를 BLEU 점수 기준으로 2.6점, ROUGE-L 점수 기준으로 2.6점 앞질렀다.
- RAG는 다음과 같은 조건에서도 SOTA 모델 성능에 근접한 결과를 보였다.
(i) 기존 모델들은 정답 생성에 필요한 특정 정보를 포함한 골드 패시지(gold passages)에 접근할 수 있었던 반면,
(ii) 많은 질문은 골드 패시지가 없으면 답변할 수 없으며,
(iii) 모든 질문이 Wikipedia만으로 답변 가능한 것은 아님
-
표 3 해석(RAG 모델이 생성한 답변 예시)
- RAG 모델이 생성한 답변 예시를 보여준다.
- RAG 모델은 BART대비
- hallucination이 적고,
- 더 사실적으로 정확한 텍스트를 생성하며,
- 더 다양한 답변을 생성함

3. Jeopardy Question Generation
- 표 2 해석
RAG-Token모델 vs.RAG-Sequence모델)- Jeopardy 질문 생성에서 RAG-Token이 더 나은 성능을 기록
- RAG-Token이 여러 문서의 내용을 결합하여 응답을 생성할 수 있기 때문에 가장 높은 성능을 발휘
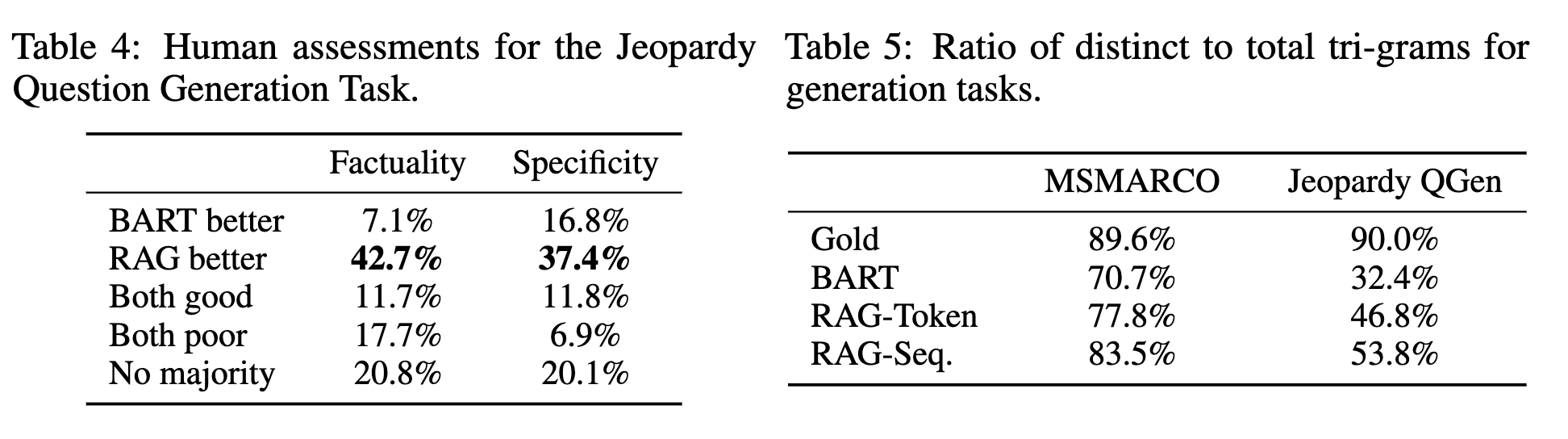
- RAG vs BART
- 인간 평가 결과, RAG가 BART보다 사실적이고 구체적인 응답을 더 자주 생성
- hallucination이 적고 정확도가 높음.
- 파라메트릭과 비파라메트릭 메모리의 조화(Figure 2 해석)
- 비파라메트릭 메모리가 검색된 문서를 통해 파라메트릭 지식을 보완하여 생성을 안내
- 특정 문서에 의존하지 않고 학습된 지식을 활용해 텍스트 완성 가능
- "Sun"이라는 답변을 생성할 때, 문서 2는 "The Sun Also Rises"를 언급하며 높은 사후 확률(posterior)을 가짐
- "A Farewell to Arms"를 생성할 때 문서 1이 우세.
- 각 책 제목의 첫 번째 토큰이 생성된 후에는 문서의 사후 확률이 균등해지는(flatten) 경향을 보임
- 이를 뒷받침하는 증거로, BART 모델에 "The Sun"이라는 부분적인 디코딩 결과를 입력하면 "The Sun Also Rises is a novel by this author of The Sun Also Rises"라는 완전한 문장을 생성. -> 제목 "The Sun Also Rises"가 BART의 파라미터에 저장되어 있음을 의미.
BART는 "The Sun Also Rises is a novel by this author of A"라는 입력을 받으면 "A Farewell to Arms"로 문장을 완성.
-> parametric memory와 non-parametric memory의 상호방식을 알려줌. 비매개변수적 메모리 구성 요소는 매개변수적 메모리에 저장된 특정 지식을 끌어내어 생성을 안내하는 역할을 한다.
- 특정 문서에 의존하지 않고 학습된 지식을 활용해 텍스트 완성 가능
- 비파라메트릭 메모리가 검색된 문서를 통해 파라메트릭 지식을 보완하여 생성을 안내

4. Fact Verification
-
표 2 해석(FEVER 데이터셋에서의 3-way 분류 성과 비교)
- 3-way 분류(지원, 반박, 정보 부족) 작업에서 RAG는 SOTA 모델 대비 4.3% 낮은 성능을 기록
- SOTA 모델은 도메인 특화 아키텍처와 복잡한 파이프라인 시스템을 사용하며, 검색 과정에서 중간 단계의 지도 학습(intermediate retrieval supervision)을 포함
- 반면, RAG는 이러한 지도 학습 없이도 높은 성능을 달성
-
표 3 해석(FEVER 데이터셋에서의 2-way 성과 비교)
- FEVER 데이터셋의 2-way 분류(참/거짓 판단) 과제에서, RAG 모델은 gold evidence 문장을 제공받은 RoBERTa 모델과 비교해 2.7% 차이로 근접한 정확도를 달성.
- RAG가 gold evidence 없이 자체 검색한 문서만을 사용했음에도 불구하고 높은 성과를 달성
5. Additional Results
- 다양한 생성 - BART보다 사실적, 구체적
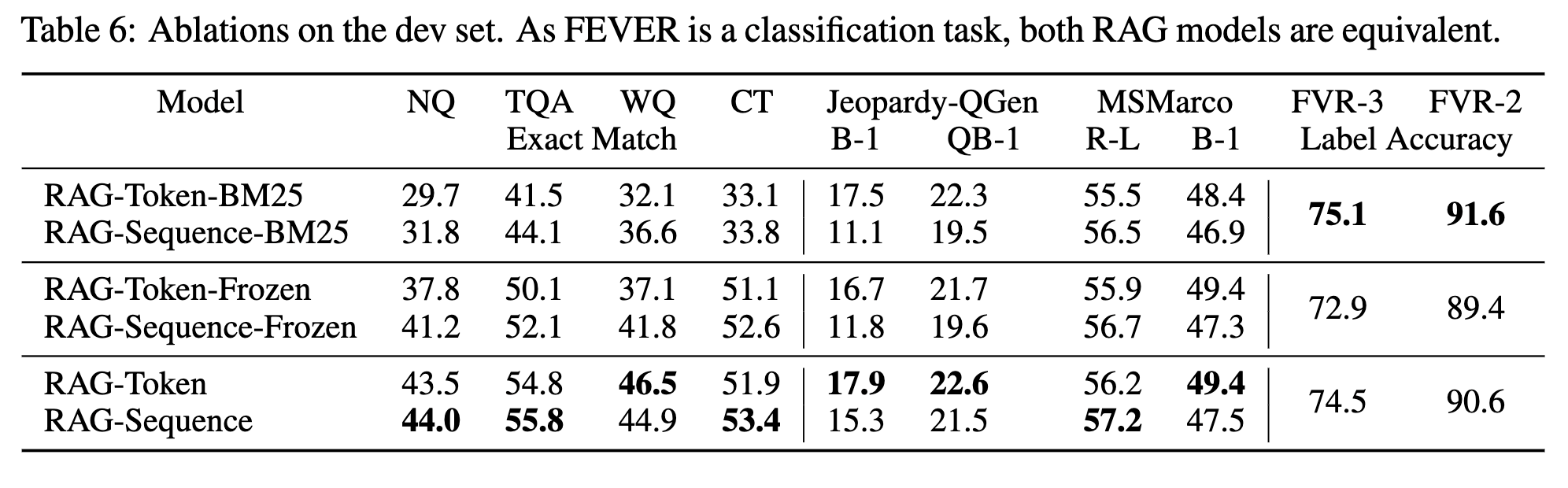
- 표 5 해석(distinct n-gram 대비 전체 n-gram 비율)
RAG-Sequence가RAG-Token보다 더 다양한 출력을 생성- 두 RAG 모델 모두 별도의 다양성 증진 디코딩 기법 없이도 BART보다 월등히 높은 다양성을 보임
- 표 6 해석(RAG의 검색 메커니즘 평가)
- RAG의 핵심 기능은 작업에 적합한 정보를 검색하는 능력 -> 이를 검증하기 위해 학습 중 검색기를 고정(ablation)한 실험을 수행 -> 결과, 학습된 검색 방식이 모든 작업에서 성능을 향상
- Index hot-swapping - 비매개변수적 메모리를 교체하는 것으로 데이터 업데이트 가능(반면, T5나 BART와 같은 파라미터릭 모델은 세계 변화에 따라 동작을 업데이트하려면 추가 학습 필요)
Related Work
Single-Task Retrieval
- 기존 연구가 특정 작업에 국한된 검색 아키텍처를 제안한 반면, 본 연구(RAG)는 단일 통합 아키텍처로 다중 작업(Open-Domain QA, 팩트 검증, 문서 생성 등)에 걸쳐 강력한 성능을 달성함을 입증했다.(검색 기반 모델의 확장성)
General-Purpose Architectures for NLP
- NLP를 위한 범용적 구조
- RAG는 사전학습된 생성형 언어 모델에 검색 모듈을 통합함으로써 가능한 작업 범위를 확장한다.(단일 통합 구조로 지식 집약적 NLP 과제를 해결)
Learned Retrieval
- 기존 연구가 단일 작업에 특화된 검색 아키텍처와 최적화 기법에 집중한 반면, RAG는 단일 검색 기반 아키텍처로 다중 작업에 걸쳐 강력한 성능을 달성함을 입증했다.
- 파인튜닝을 통해 다양한 NLP 과제(오픈 도메인 QA, 팩트 검증, 문서 생성 등)에 적용 가능한 통합 프레임워크를 제시했다.
Memory-based Architectures
-
메모리 네트워크와의 유사성
RAG의 문서 인덱스는 신경망이 참조할 수 있는 대규모 외부 메모리로 기능하며, 이는 메모리 네트워크와 개념적으로 유사하다. 같은 시기 다른 연구는 입력 내 개체별로 훈련된 임베딩을 검색하는 방식을 채택한 반면, RAG는 원시 텍스트(raw text) 자체를 검색한다는 점에서 차별화된다. -
사실 기반 생성 향상
대화 모델의 사실적 텍스트 생성 능력을 개선하기 위한 연구가 사실 임베딩(fact embeddings)에 주목하는 동안, RAG는 두 가지 핵심 특징을 가진 원시 텍스트 기반 메모리를 구현했다:- 인간 가독성: 분산 표현(distributed representations) 대신 원시 텍스트 사용으로 모델 해석 가능성 보장
- 인간 작성 가능성: 문서 인덱스 편집을 통해 모델 메모리를 동적으로 업데이트 가능
-
지식 집약적 응용
TF-IDF 기반 검색으로 획득한 텍스트에 직접 조건화된(knowledge-intensive dialog) 생성기에 이 접근법이 적용된 사례가 존재하지만, RAG는 종단간 학습(end-to-end learnt retrieval) 방식을 채택해 진화된 프레임워크를 제시한다. 이는 외부 지식 활용과 모델 업데이트 유연성 측면에서 실용적인 장점을 지닌다.
Retrieve-and-Edit approaches
| 구분 | 기존 검색-편집 접근법 | RAG 접근법 | 차이점 |
|---|---|---|---|
| 기본 원리 | 유사한 학습 입력-출력 쌍을 검색 후 편집 | 여러 검색 문서의 내용을 통합 | 단일 항목 편집 대신 다중 문서 통합 |
| 적용 분야 | 기계 번역, 의미 구문 분석 | 개방형 질의응답, 사실 검증 | 도메인 확장성 |
| 검색 대상 | 학습 데이터 내 유사 쌍 | 외부 지식 문서(위키피디아 등) | 학습 쌍 대신 증거 문서 |
| 편집 방식 | 경량 편집(light editing) | 강조 잠재 검색(latent retrieval) 학습 | 표면적 수정 대신 의미적 통합 |
| 주요 특징 | 특정 작업에 최적화, 출력 품질 제한적 | 동적 지식 통합, 사실성 향상 | 확장성과 유연성 |
