카카오 엔터프라이즈 SW아카데미 6기
Team Name : NILO
Project Name : GriDam
감정 기록 플랫폼 GriDam을 개발한 Team NILO입니다.
GriDam은 하루의 감정을 ‘그림처럼’ 기록하고, AI 분석을 통해 감정 통계와 피드백을 제공하는 감성 아카이빙 플랫폼입니다.


팀은 총 7명으로 구성되어 있으며, 백엔드, 프론트엔드, 인프라 AI 파트로 나뉘어 협업했습니다.
문제 정의
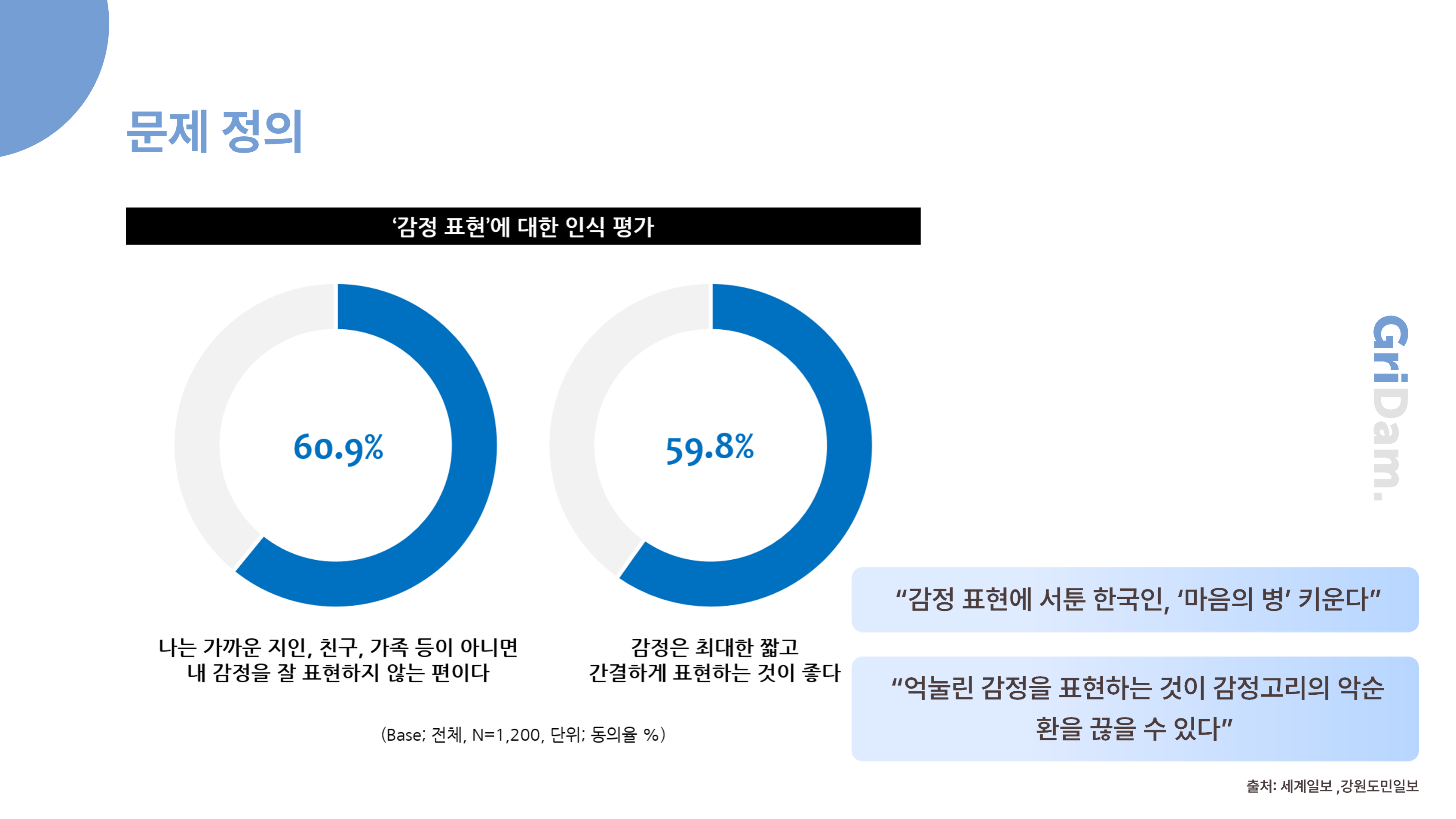
현대의 많은 사람들은 자신의 감정을 꾸준히 기록하거나 이해하는 데 어려움을 겪습니다
왼쪽 그래프에서 감정 표현에 대한 인식 평가를 살펴보면, 나는 가까운 사람이 아니면
감정을 잘 표현하지 않는 편이라는 설문 조사 결과가 있었습니다.
하지만 이렇게 감정을 억누르다 보면, 표출하지 못한 감정이 마음의 병으로 이어지는 악순환이 생길 수 있습니다.

이러한 상황 속에서 저희는 다음과 같은 사용자의 고민을 알 수 있었는데요,
감정을 꾸준히 기록하고 싶지만 동기부여가 부족하다
복잡한 감정을 정리하기 어렵다
이러한 사용자의 고민을 들을 수 있었습니다.

이에 따라 페르소나는 감성적이면서도 자아 성찰을 중요시하는 20대 여성,

그리고 실용적이면서도 감정도 통제하고 싶어하는 20대 후반 남성으로 분석해보았습니다.
프로젝트 소개
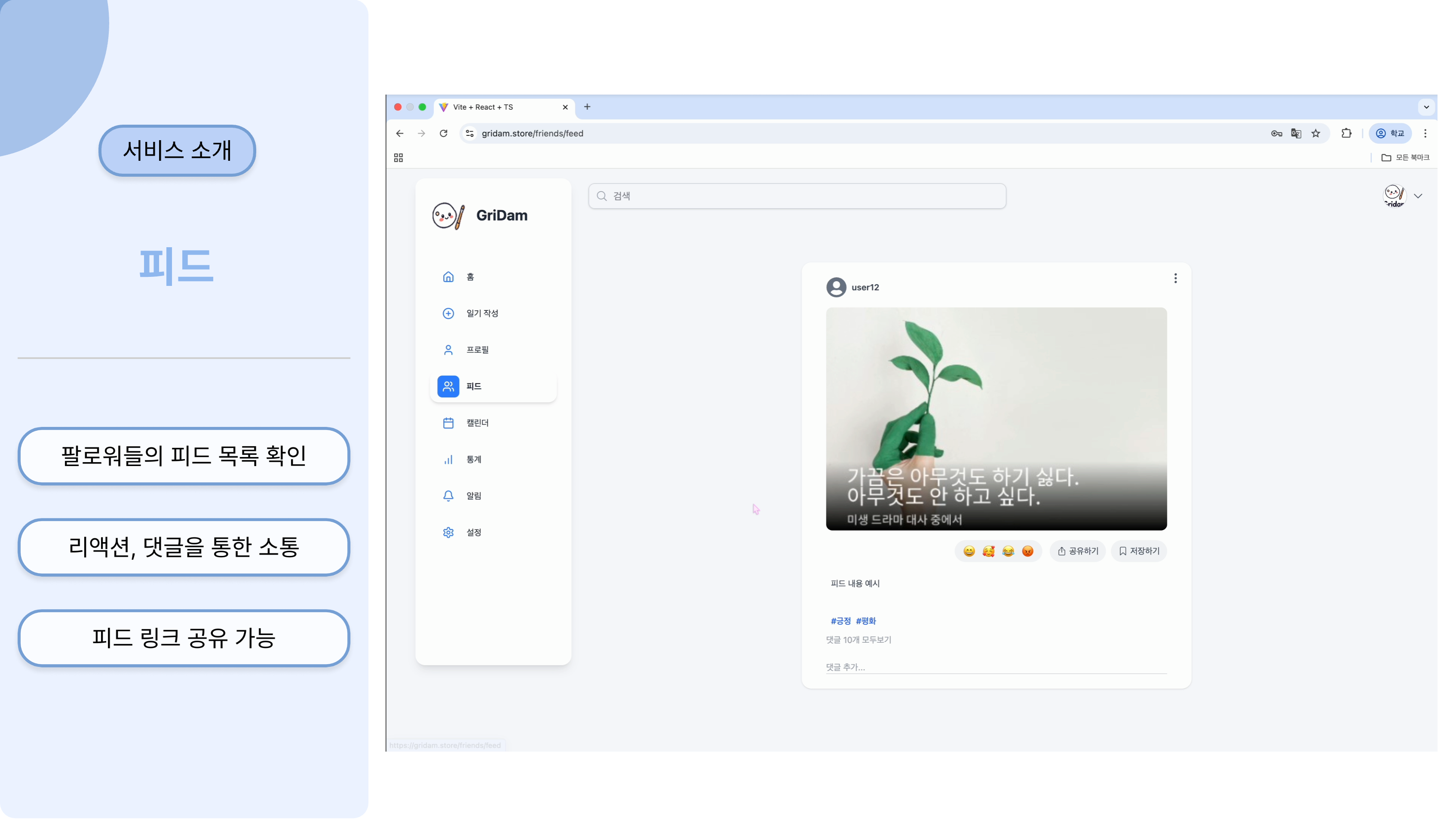
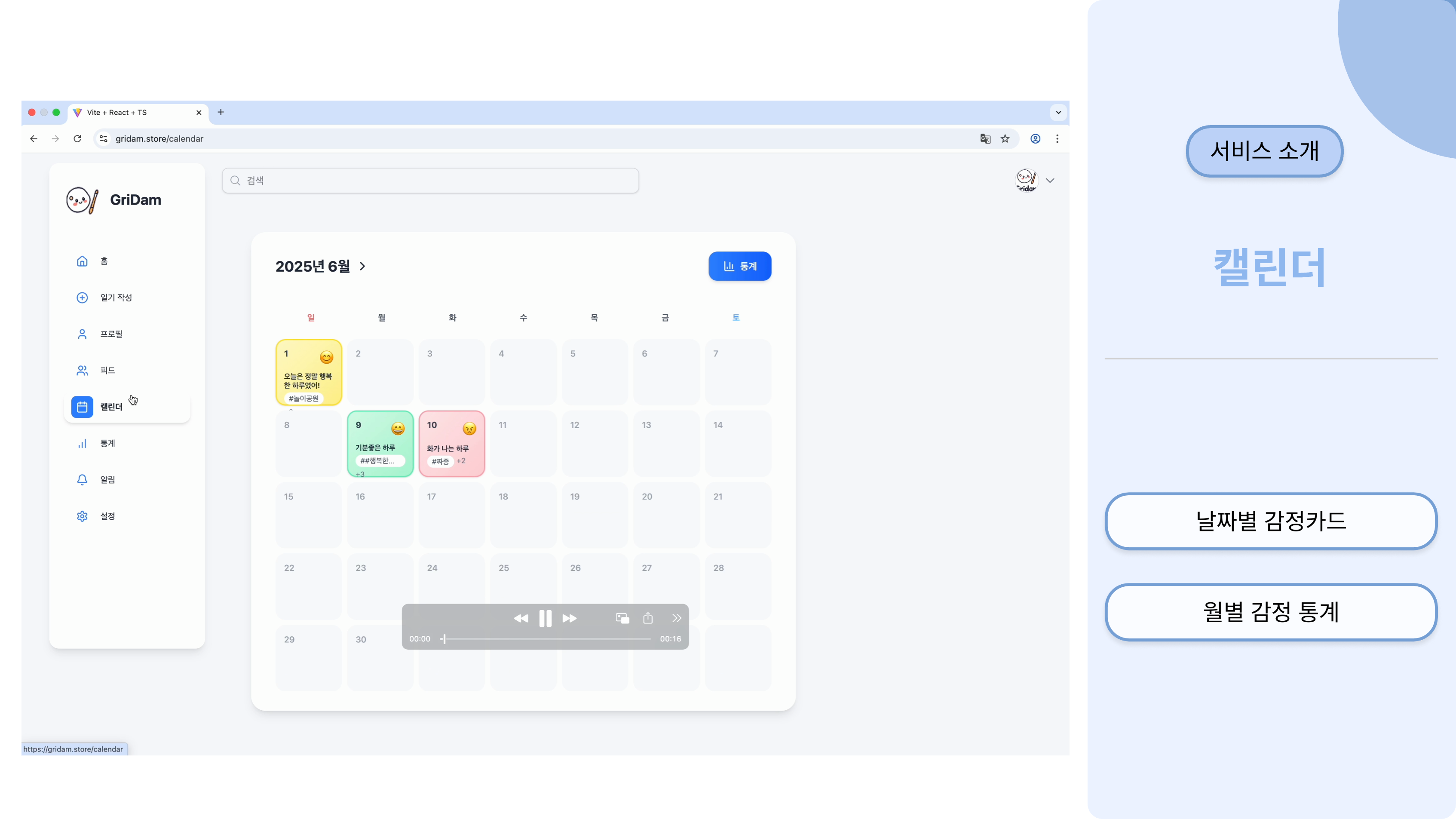
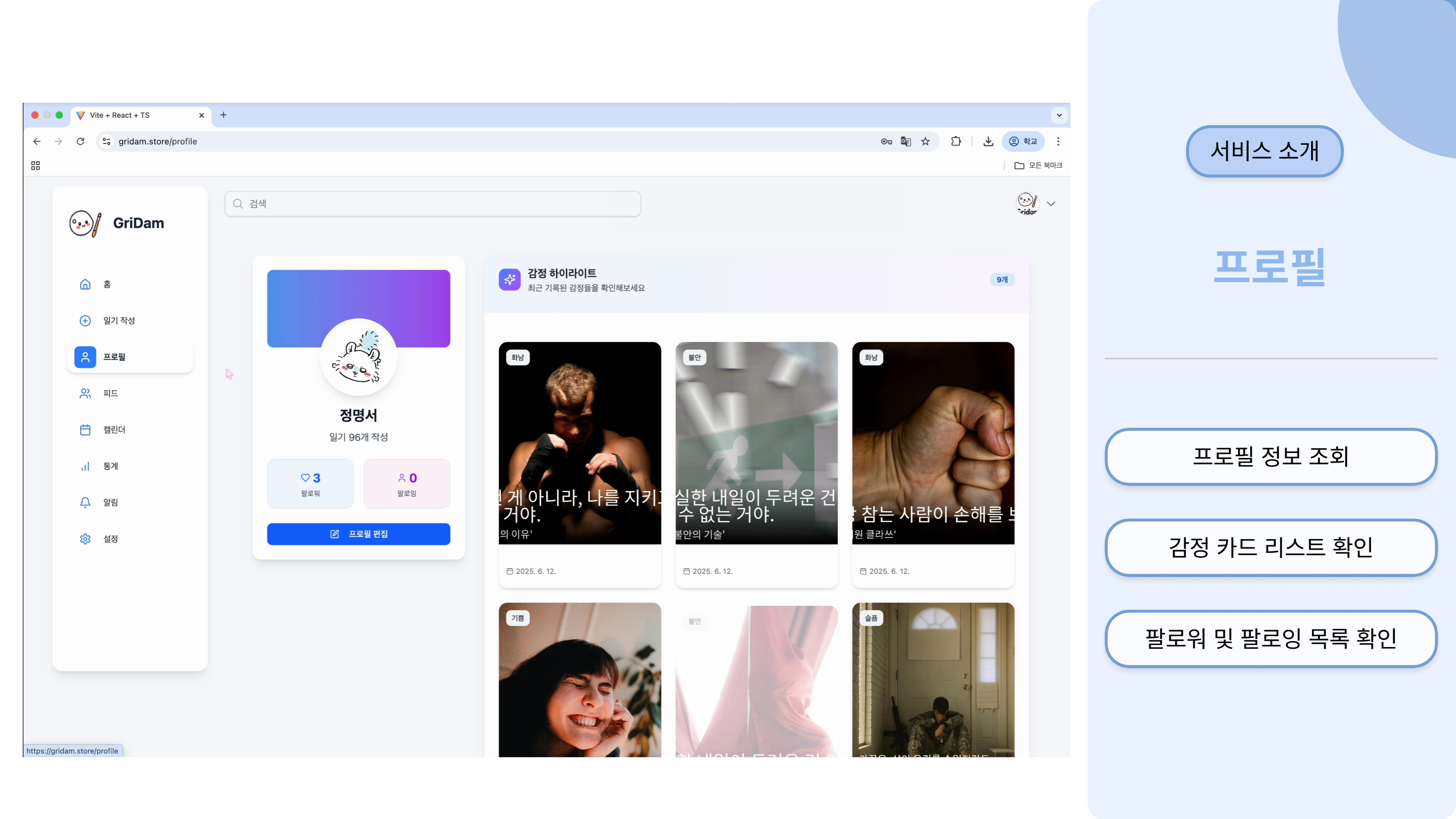
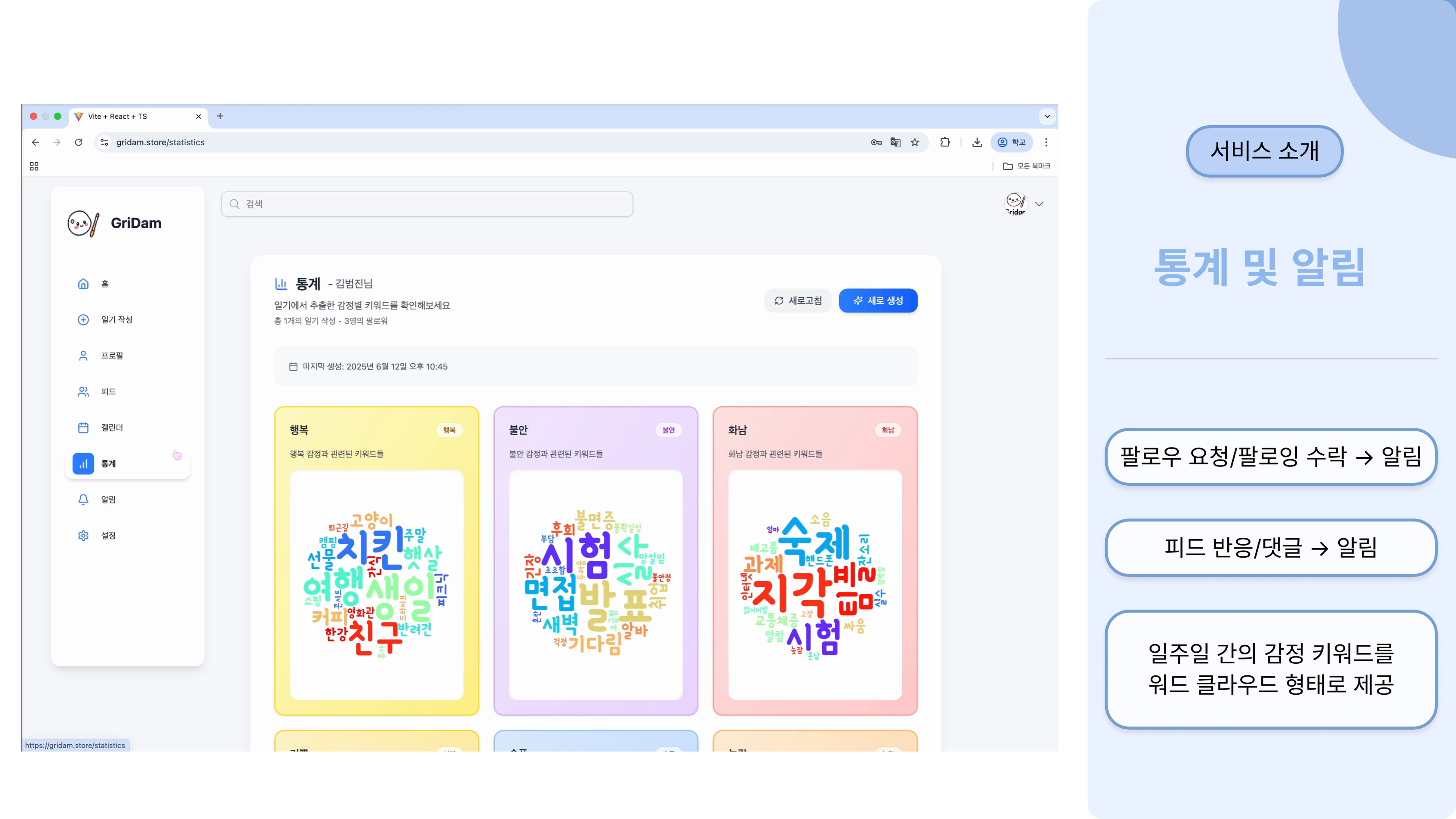
이러한 요구사항 속에서 저희는 하루의 기억과 감정을 기록하고 감정 카드의 형태로 공유할 수
있는 일기형 감성 플랫폼, 그리담을 제공하고자 하였습니다.
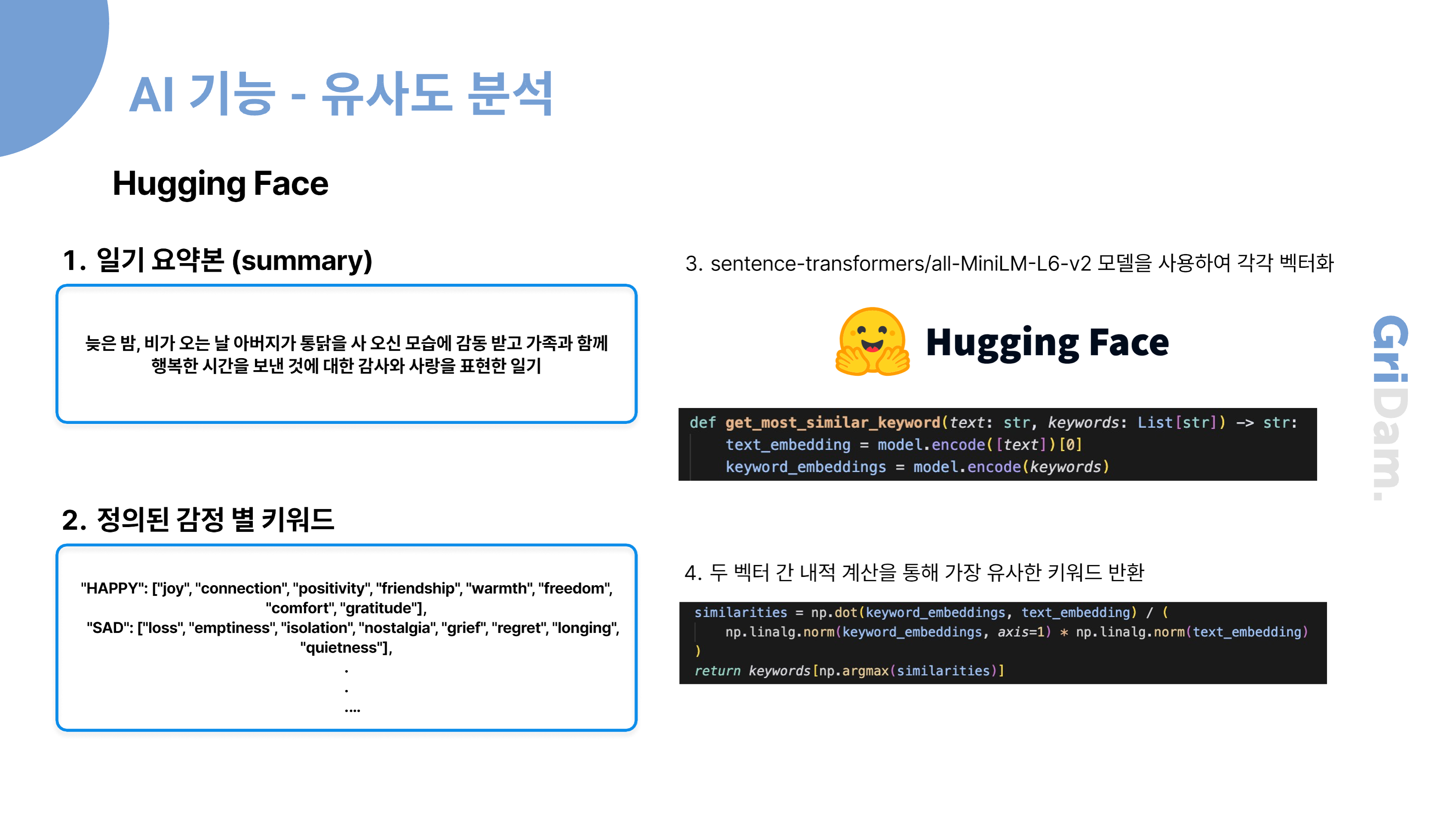
일기 작성을 통해 감정을 분석하고, 분석을 통해 알아낸 감정으로 나만의 감정 카드를 생성하는
기능을 제공합니다.
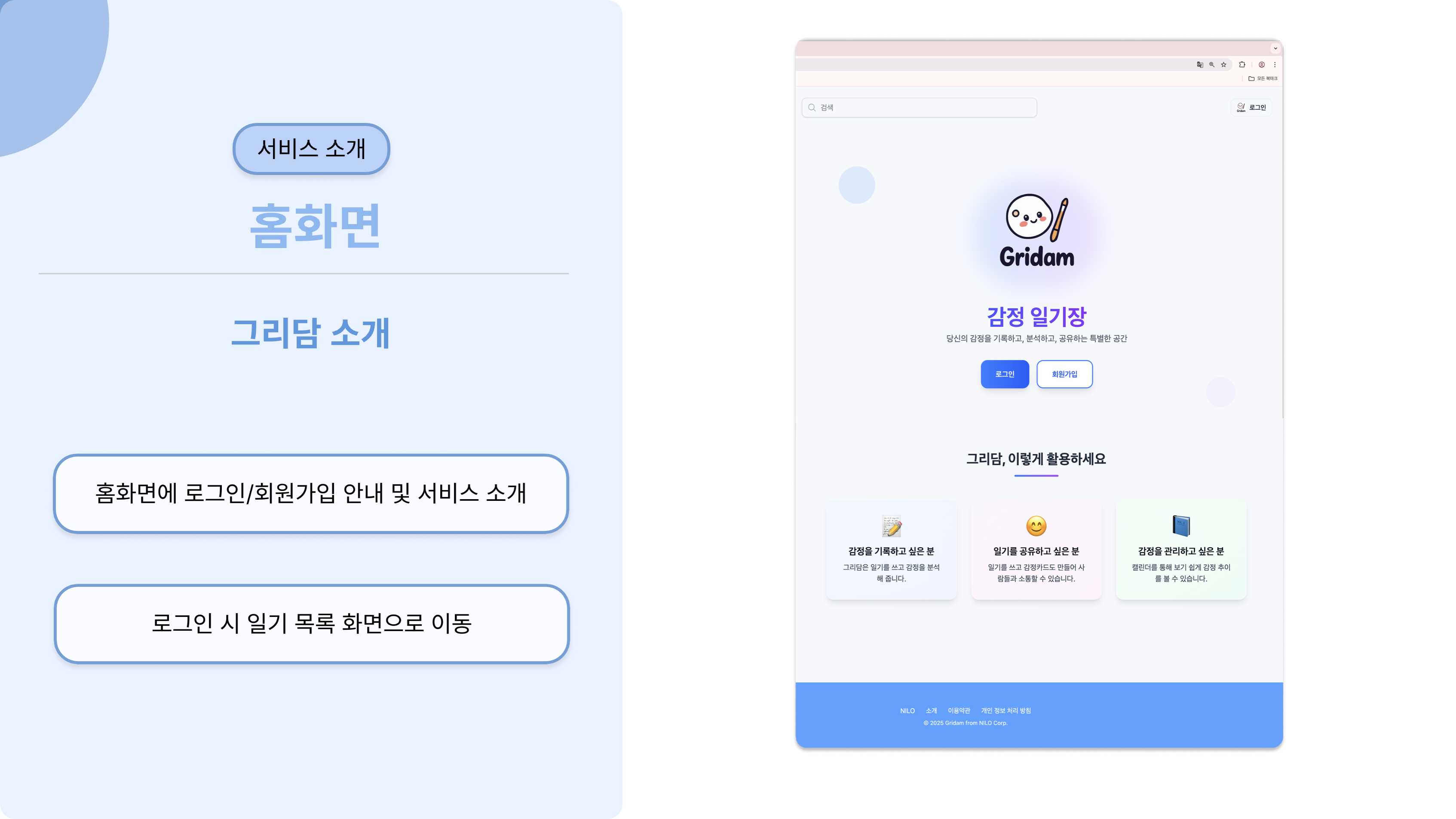
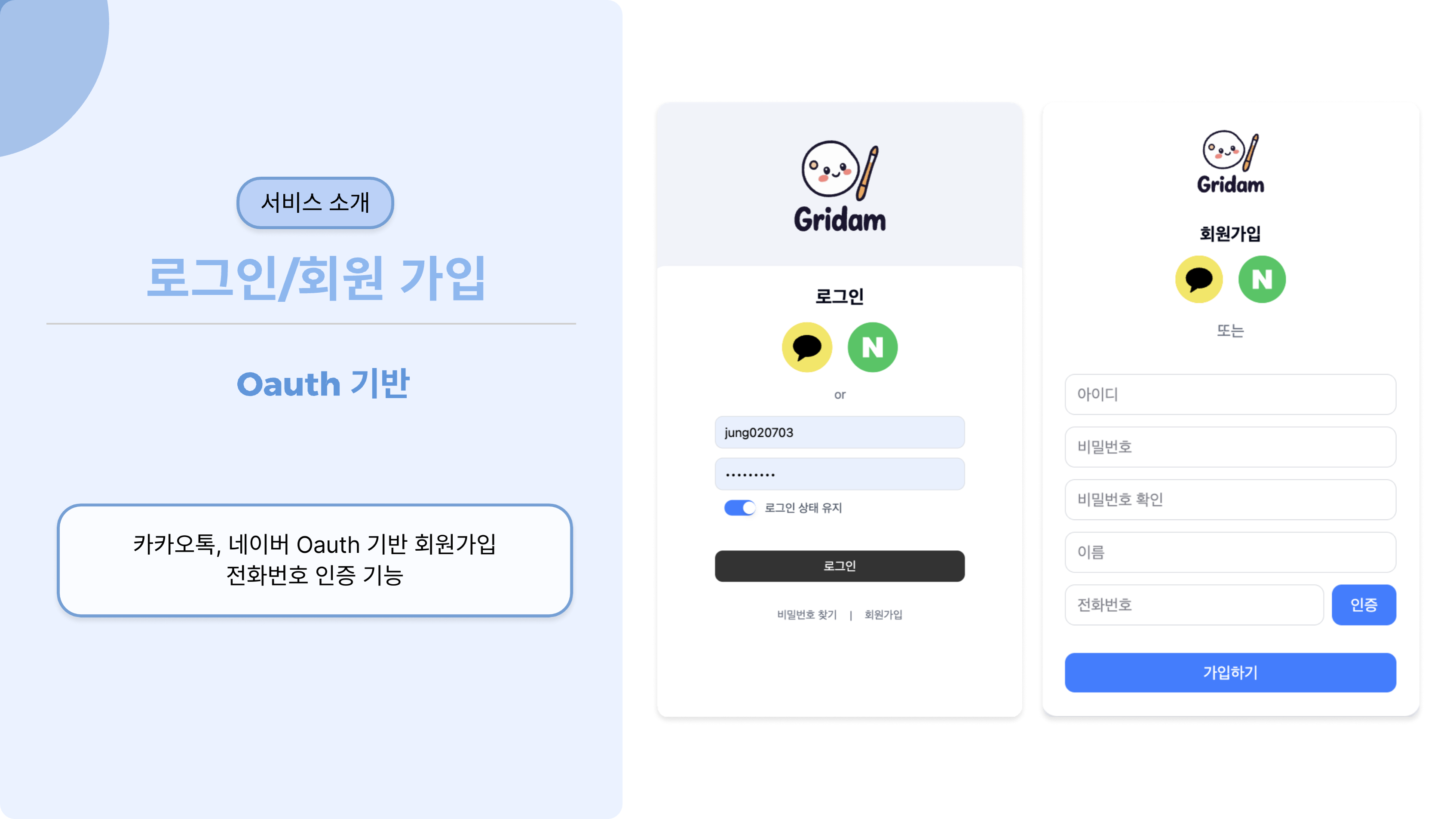
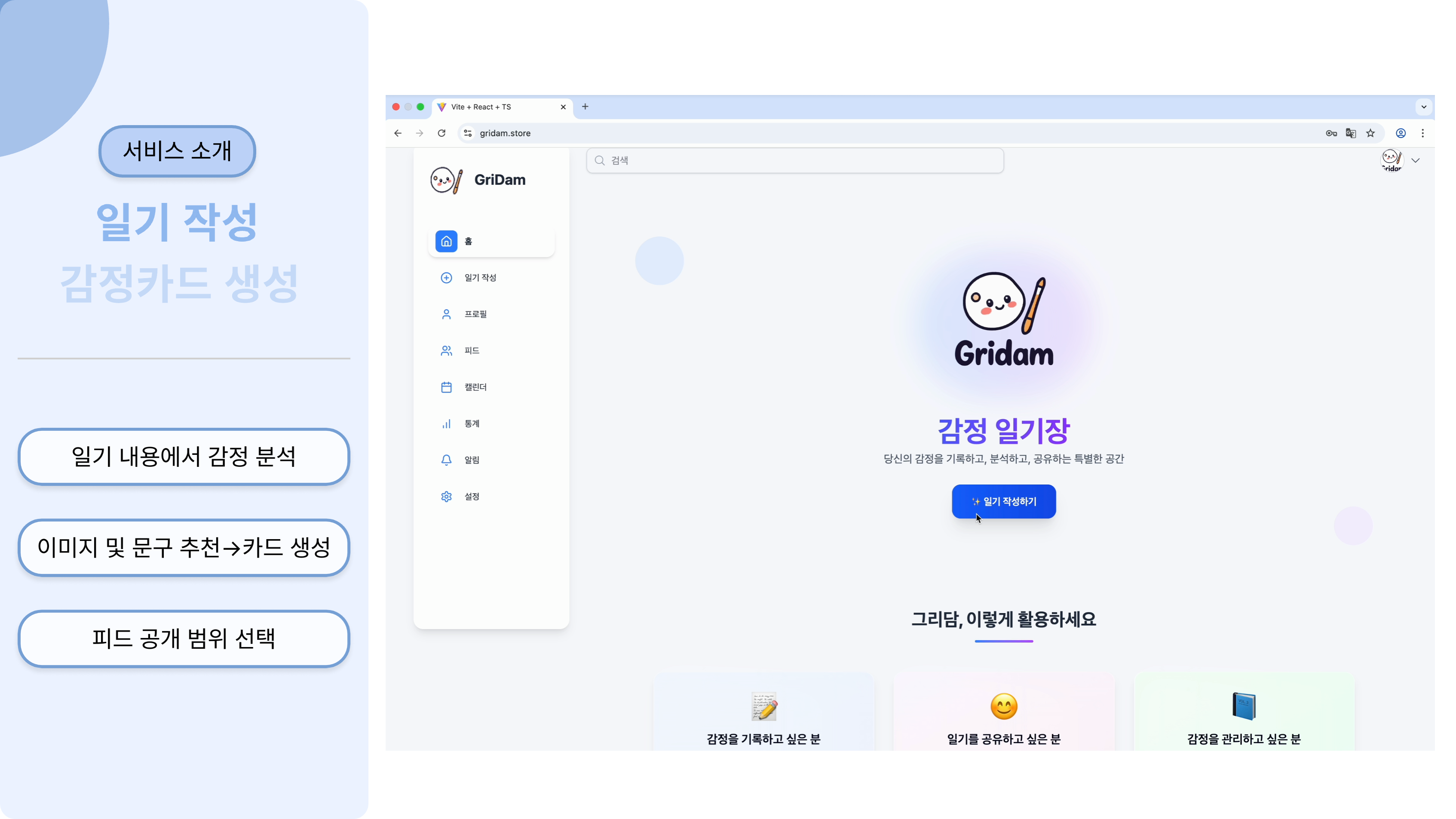
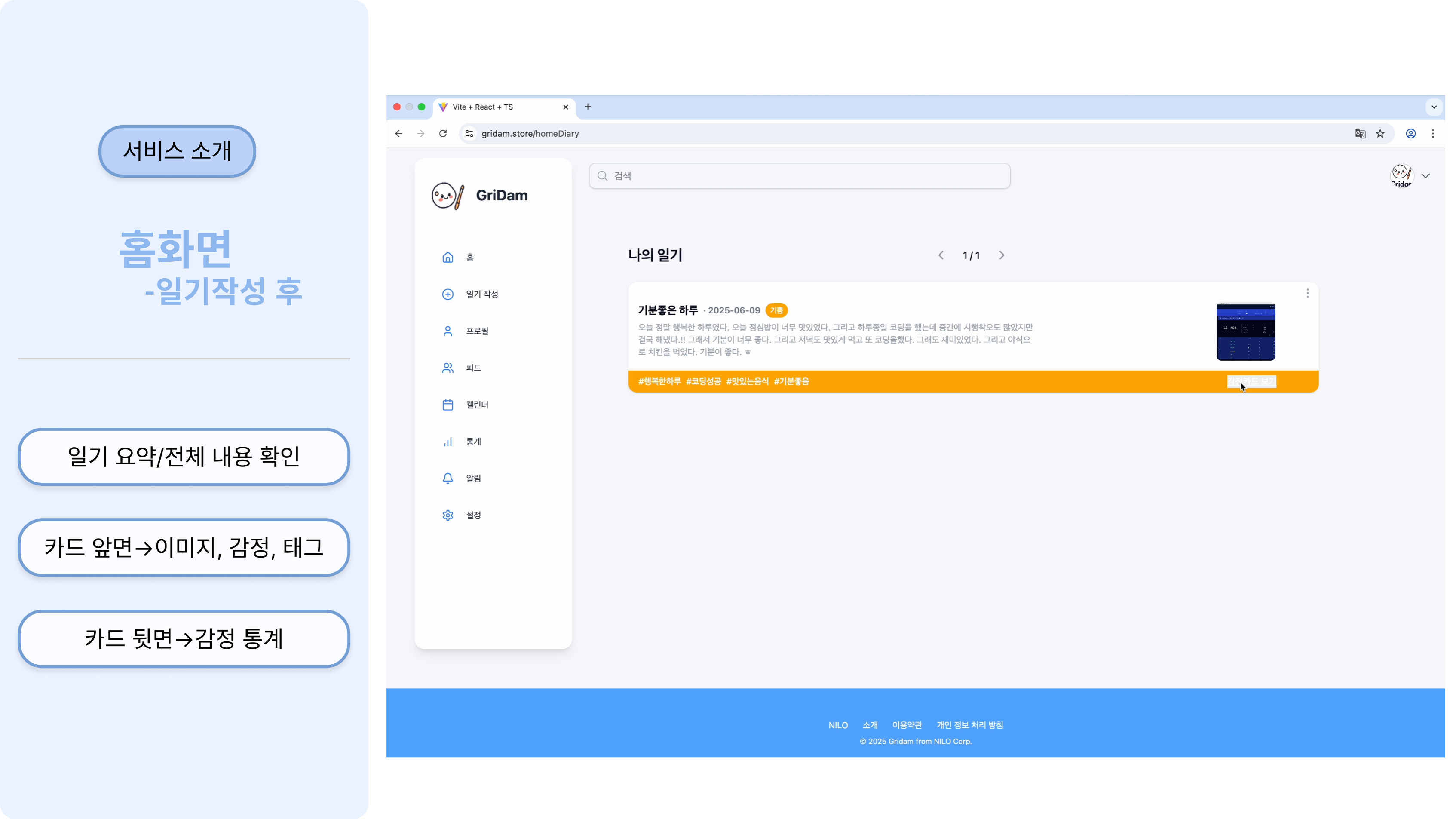
서비스 소개
(구현 데모 영상)
https://www.youtube.com/watch?v=JF7ztKUfB10
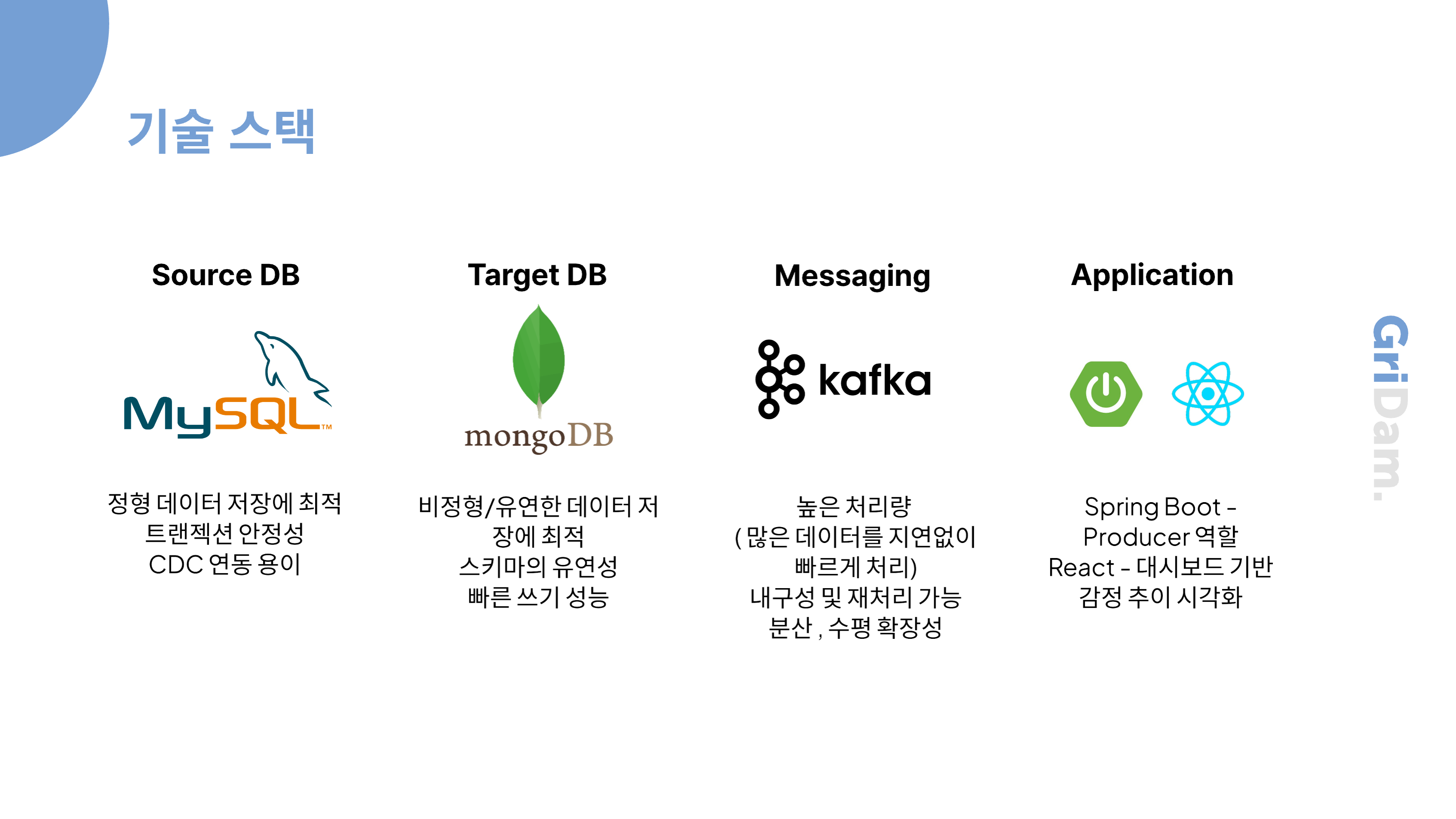
사용된 기술






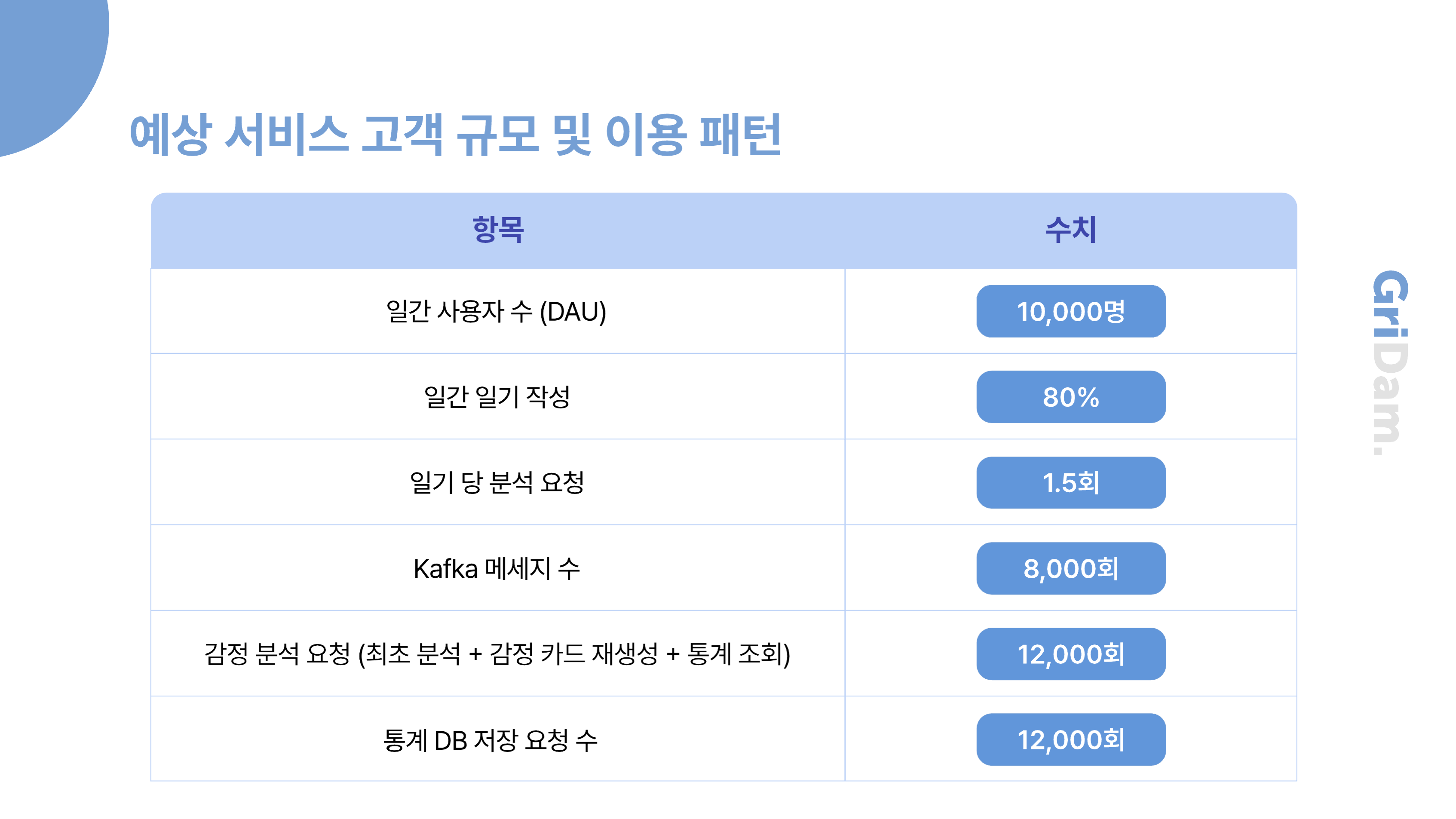
이 표는 저희 서비스의 일일 예상 사용자 규모와 함께, 일기 작성 및 감정 분석 요청량 등 주요 지표에 대한 예측 수치를 정리한 것입니다.
보시다시피, 일기, 감정 분석에 대한 트래픽이 많은 것을 볼 수 있습니다.
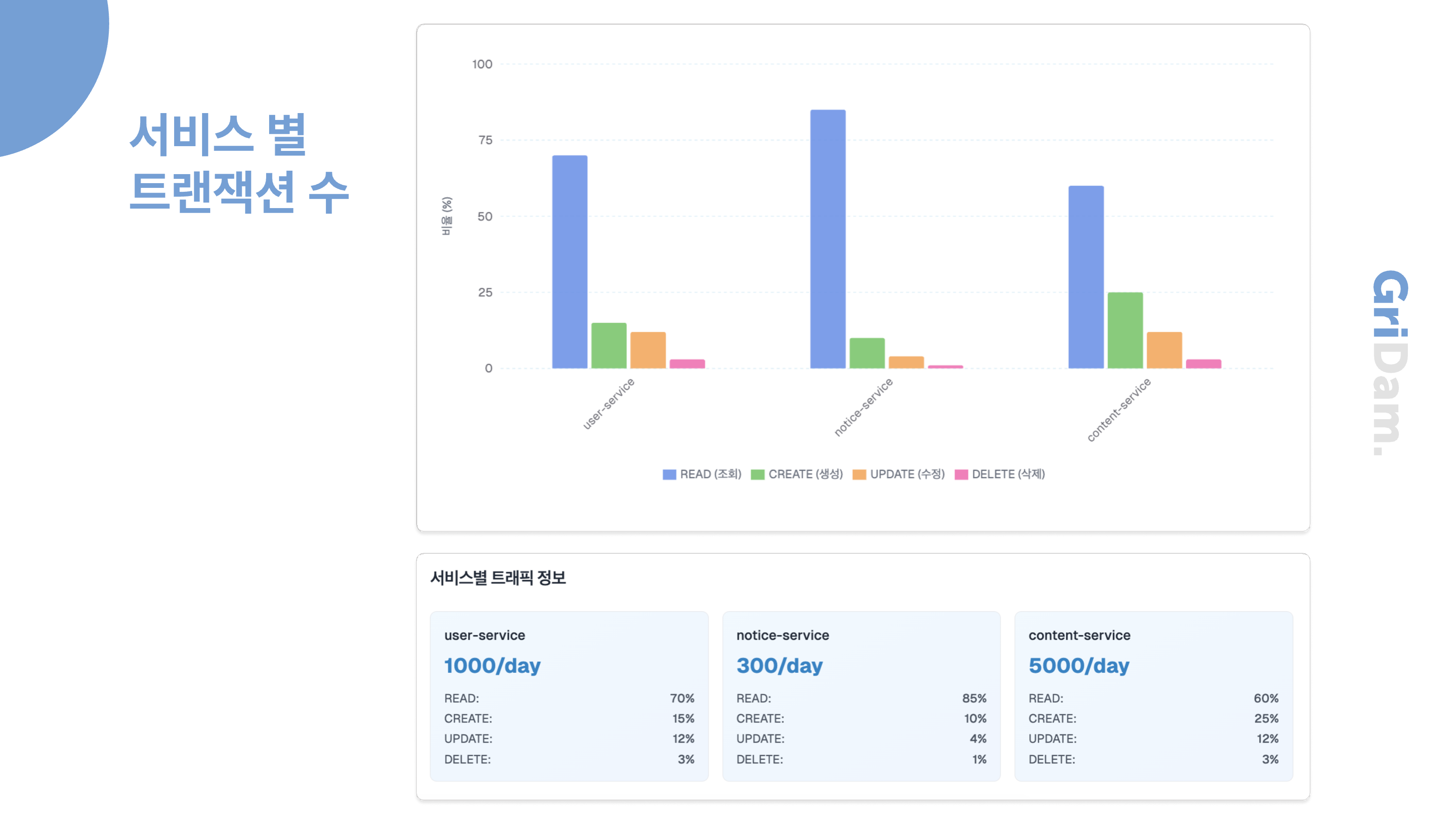
다른 서비스들보다 content-service 쪽에 트래픽이 집중되어 있는 모습입니다.
따라서 저희는 모놀리식에서 MSA 구조로 변경하여, 하나의 서비스에 집중되던 요청이 각 마이크로 서비스 별로 나뉘어 독립적으로 처리될 수 있게 하였습니다.

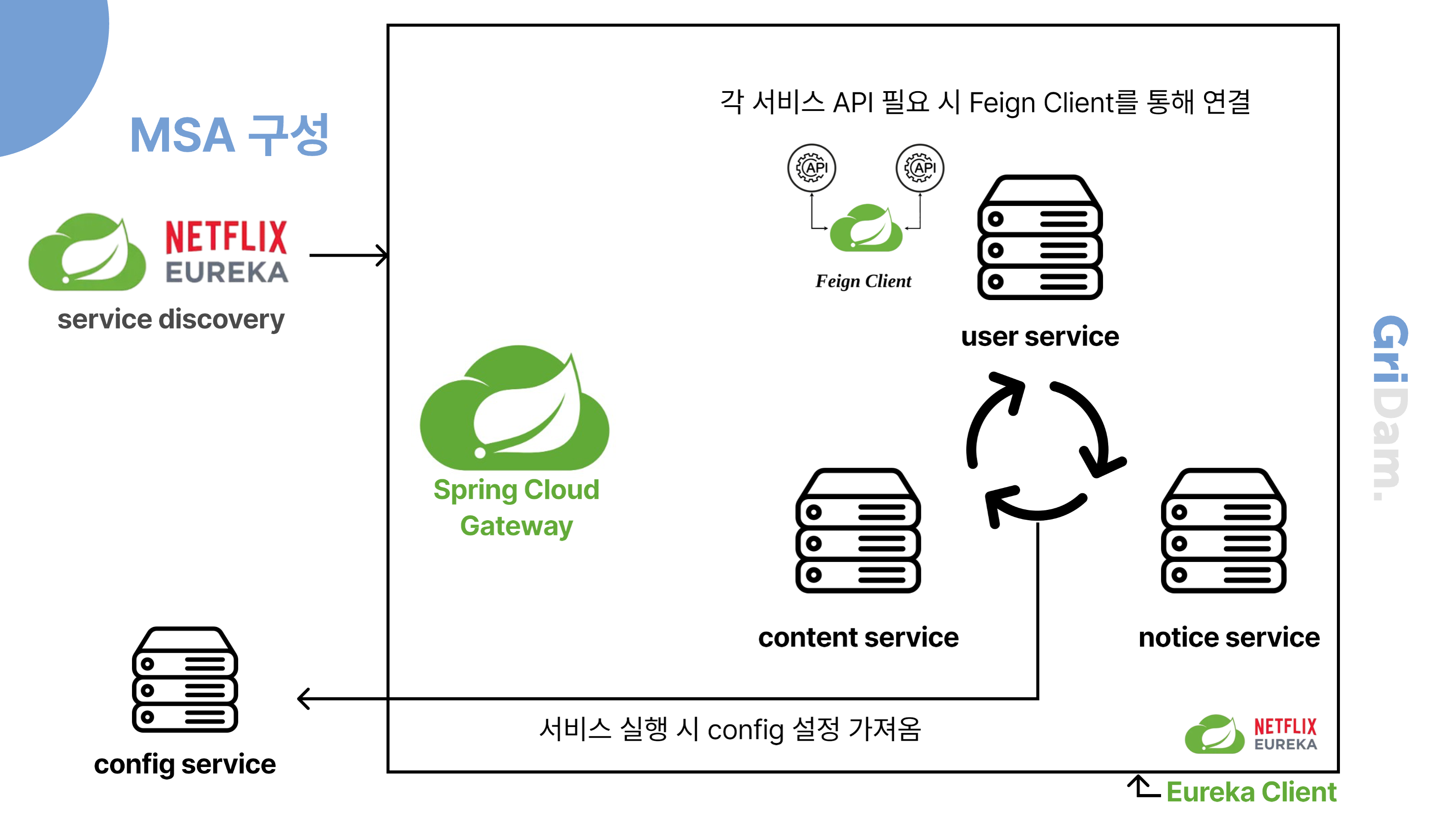
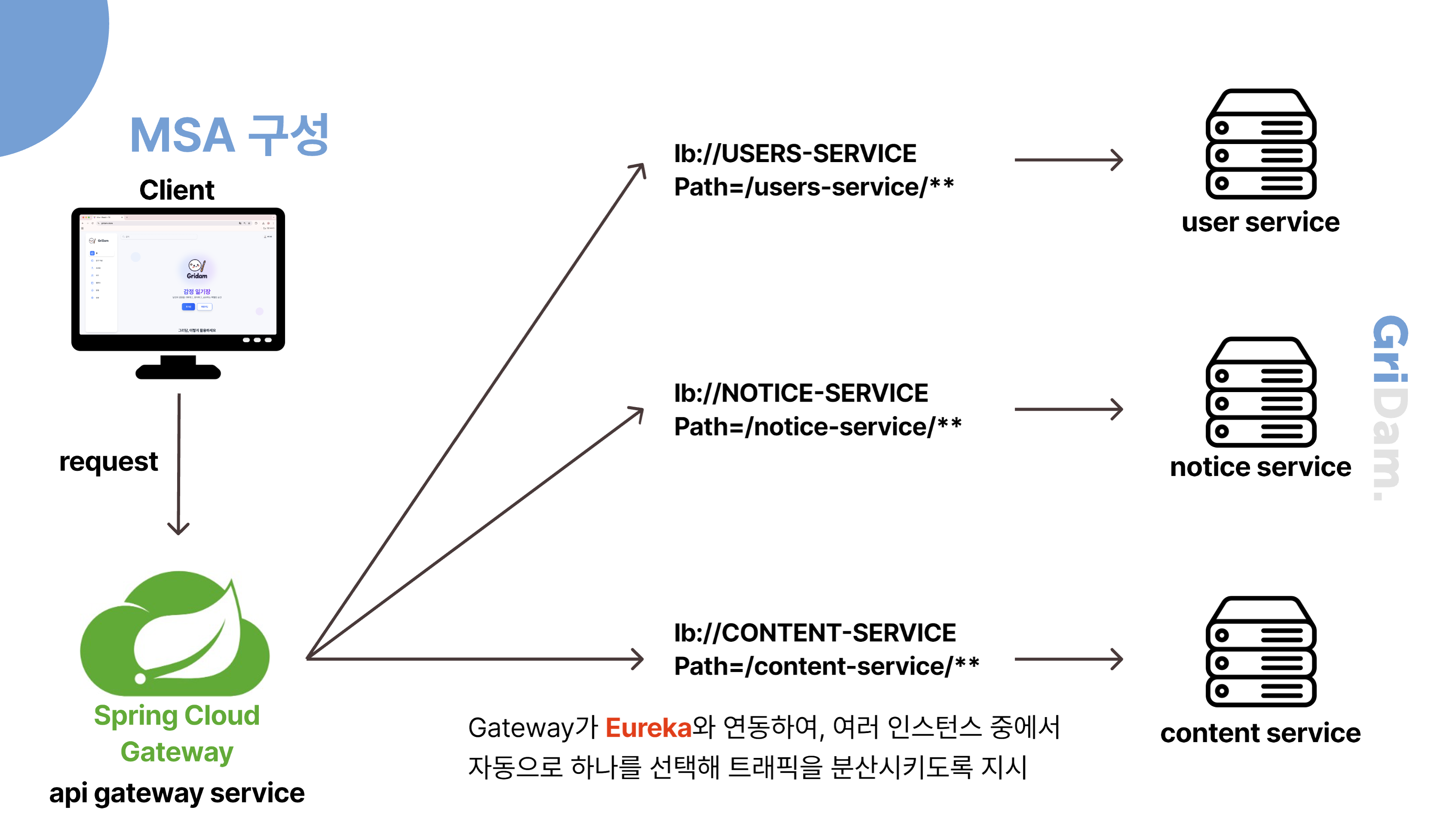








시스템 아키텍처
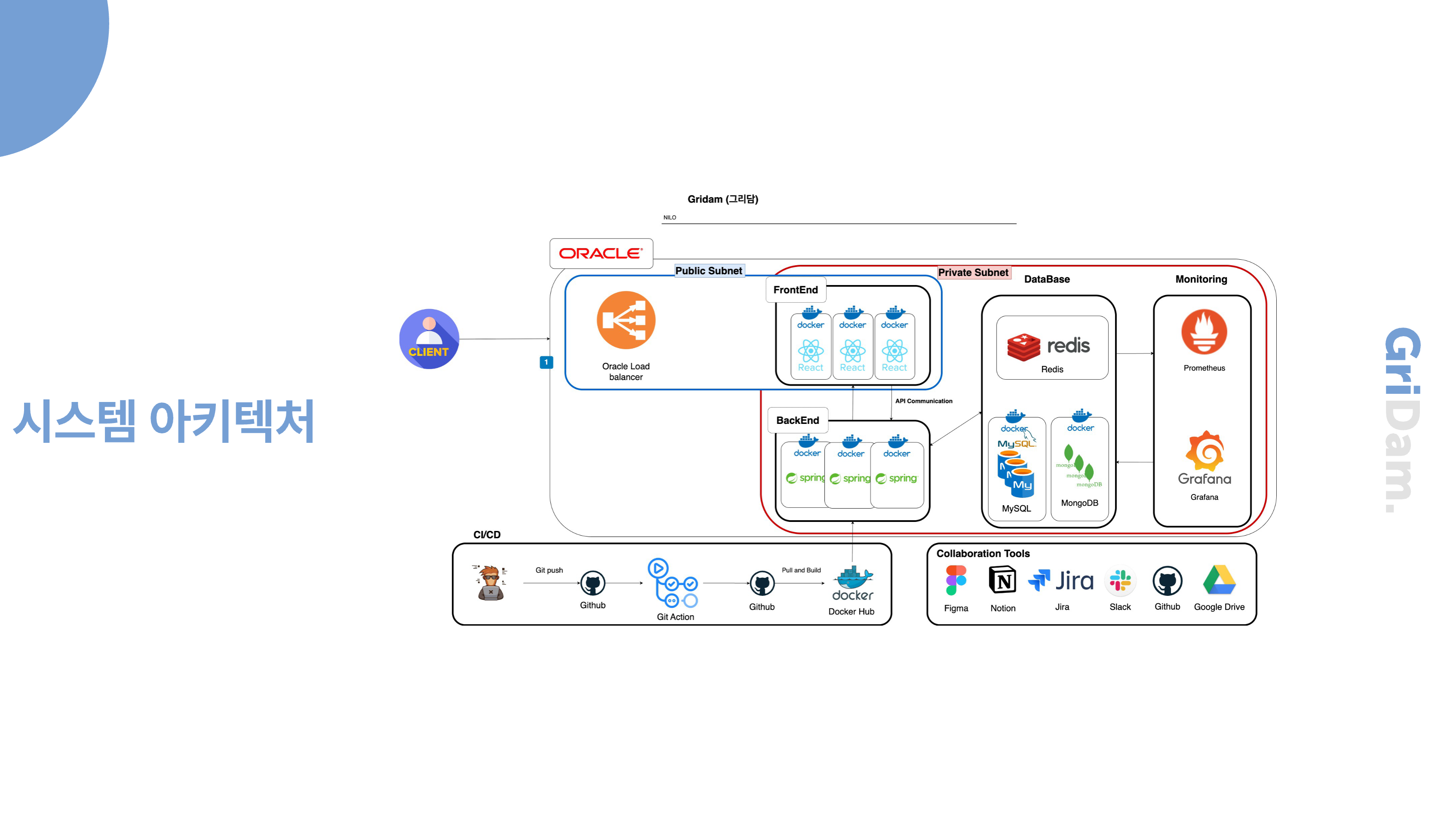
초기 아키텍처입니다. 서비스 규모가 크지 않기 때문에 VM 4개를 띄워 기능별로 각각 프론트, 백엔드, 데이터베이스, 모니터링을 Docker로 띄워 구성하고, Docker-compose로 관리를 하는것이 규모에 알맞는 배포 방법이라 생각했습니다. 초기에는 오라클 클라우드에 크레딧이 있어서 오라클 위주의 아키텍처를 구성하였습니다.
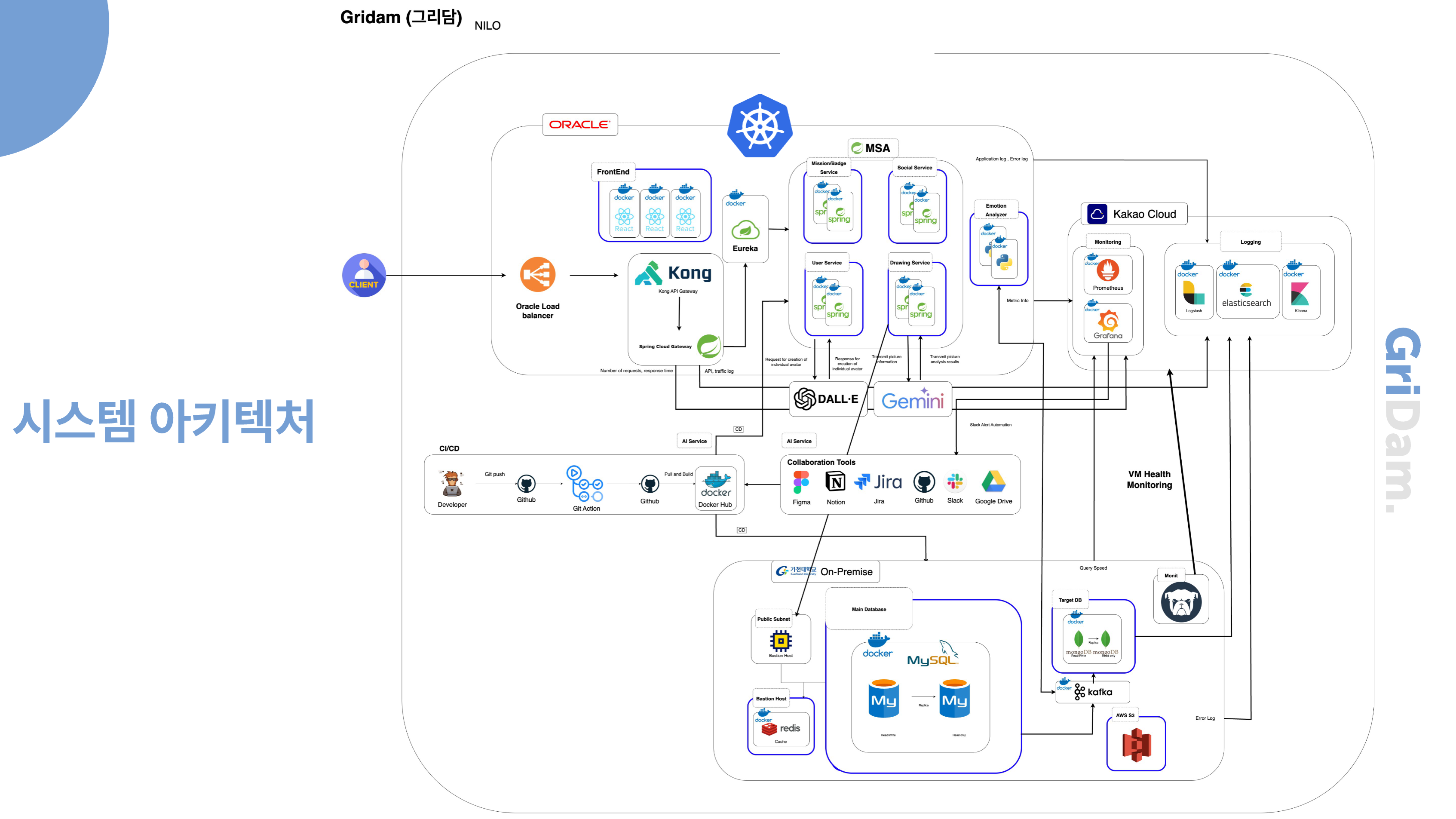
여러 AI 서비스가 들어오고 카카오 클라우드에 크레딧을 받게 되어 같은 2CPU 4GB의 VM은 오라클보다 카카오가 더 저렴하여 모니터링 쪽의 기능들을 카카오 클라우드로 이전하였습니다. 추가로 DB와 관련된 서비스들은 보안과 비용 절감을 위해 가천대 On-Premise환경에 배포하게 되었습니다. 또한 추후 서비스의 확장성을 위해 MSA로 배포하려고 했습니다. 하지만 MSA를 적용해 DB를 분산 데이터베이스로 나누는 것은 데이터 양이 많지 않기에 MSA를 서비스 단위로만 나누고 DB는 단일 데이터베이스만을 사용하게 했습니다. 하지만 On-Premise 환경이 불안정해져 쓰지 못하게 되었고, 비용이 더 저렴한 카카오 클라우드의 VM을 사용하여 DB를 docker로 배포하게 되었습니다.
여기까지가 8주차 까지의 기획과 구성이었으나.. 서비스 기획에 있어서 일기 데이터 수집의 문제로 서비스를 다시 구성하였습니다. 그에 따라 작업하던 아키텍처를 뒤로하고 새로운 서비스에 맞춰 다시 아키텍처를 설계하였습니다.
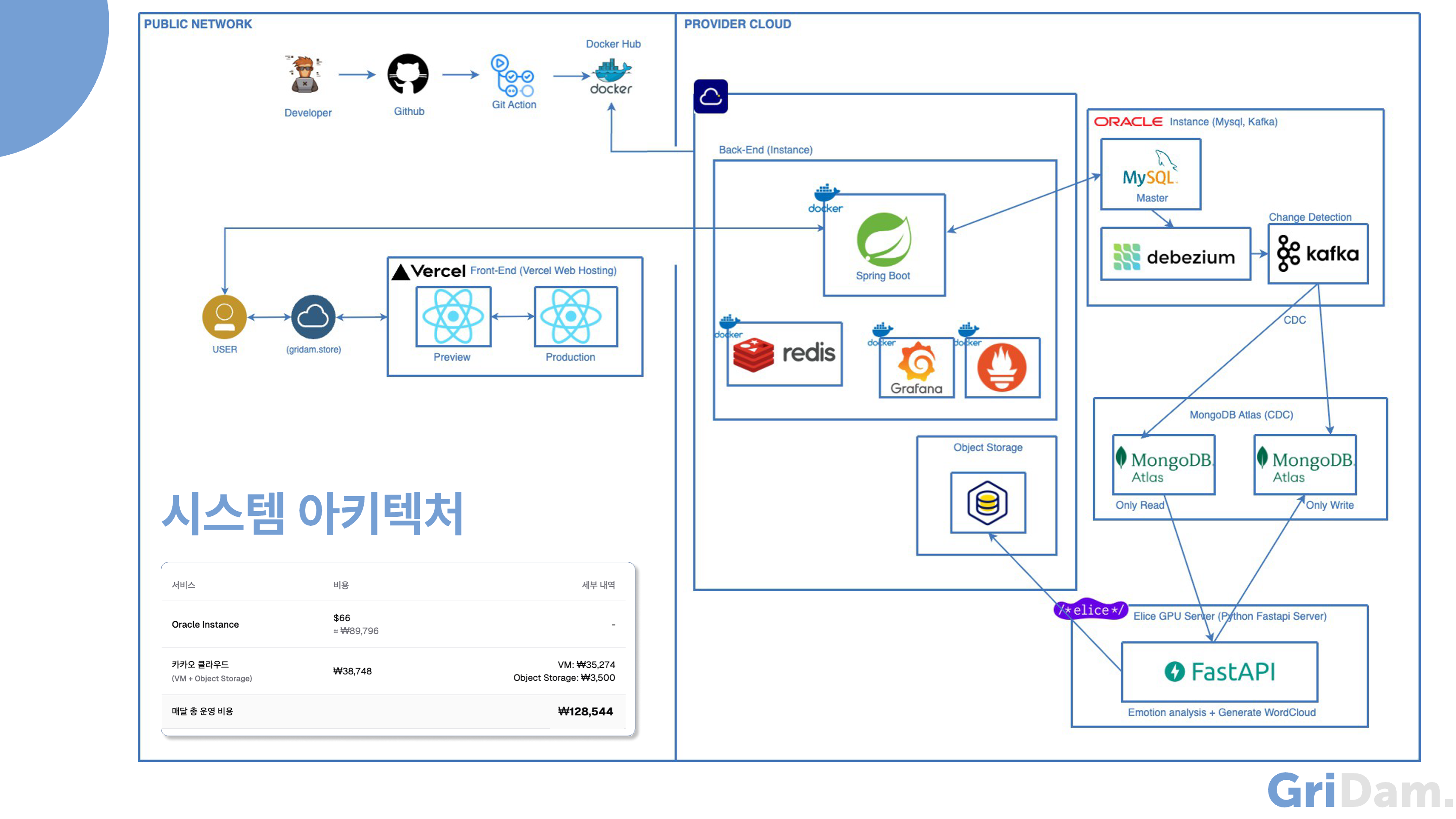
기획이 바뀌며 다시 아키텍처를 설계했을 때는, 서비스 규모가 작기 떄문에 모놀리식이 적합하다 판단하였습니다. 카카오 클라우드 VM 하나에 Spring, Redis, 모니터링을 Docker Compose로 배포했습니다. 그리고 오라클 클라우드 인스턴스에 DB와 관련된 파이프라인을 Docker Compose로 배포했습니다. 완전한 관리형 서비스인 MongoDB Atlas를 이용하여 Auto-Scaling과 모니터링 및 성능 분석 도구를 사용할 수 있었습니다. 하지만 백업 및 복원 기능은 유료로 결제해야 사용할 수 있다는 단점이 있었습니다. 추가로 앨리스 서버에서 크레딧을 지원 받아, GPU 연산을 지원하는 라이브러리를 활용할 수 있었습니다. 처음 짠 아키텍처의 한달 운영 비용은 GPU서버와 도메인값을 제외하여 약 13만원 입니다.
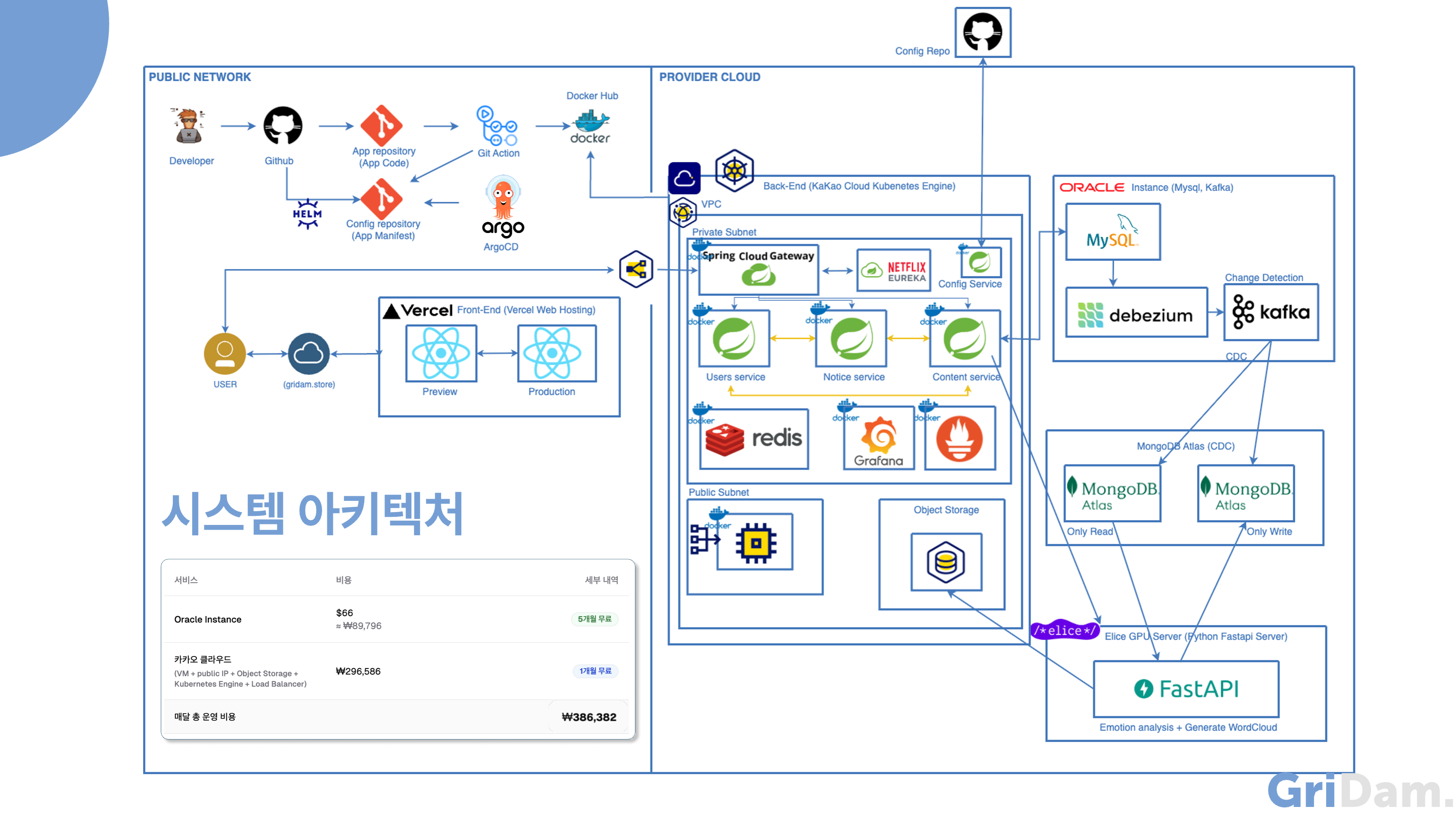
개발이 어느정도 끝났을 때 저희는 모놀리식 구성의 단점을 발견하게 되었습니다.
기존 모놀리식 구조에서는 모든 트래픽이 단일 애플리케이션으로 집중되어 성능 저하와 장애 전파의 위험이 컸지만, MSA 구조로 전환한 이후에는 서비스별로 요청이 분산되어, 각각의 서비스가 자신의 역할에 맞는 트래픽만을 처리하게 되어 전체 시스템의 안정성과 확장성이 크게 향상되었습니다.
각 서비스의 특성에 따라 서로 다른 확장 전략을 적용할 수 있고,
모놀리식 환경에서는 한 서비스의 트래픽 증가가 전체 성능 저하로 이어졌으나 현재는 MSA 구조 덕분에 트래픽 병목 현상이 발생해도 해당 서비스에 국한되어 전체 시스템 안정 유지가 가능하게 되었습니다.
MSA 아키텍처를 운영하는 데에는 한달에 약 39만원입니다. 서비스 확장성과 장애 대응성을 위해 여러 Node에 Pod를 분산시켜 배포하다보니 VM값이 많은 비중을 차지했습니다.
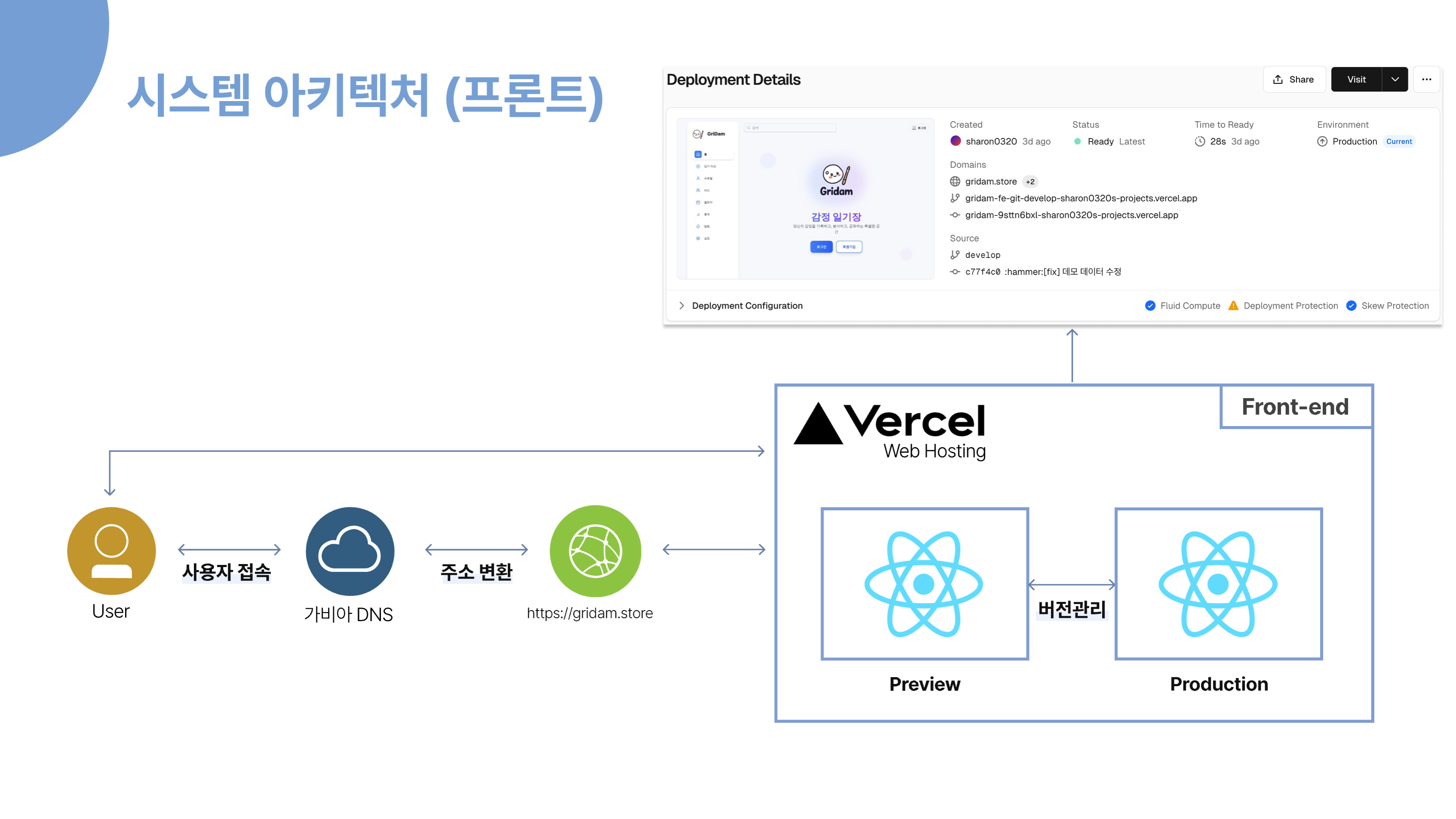
사용자가 보는 화면이 구현되어 있는 프론트 부분입니다.
사용자는 가비아에서 설정한 gridam.store 도메인을 통해 저희 서비스에 접근하며, 해당 요청은 Vercel에 배포된 React 기반 프론트엔드 애플리케이션으로 연결됩니다.
Vercel은 자체적으로 HTTPS 인증서(SSL)를 제공하고, 정적 파일 서빙 및 글로벌 CDN을 통해 빠르고 안정적으로 프론트를 제공합니다.
원래는 하나의 VM에서 Docker와 Nginx를 활용해 배포할 계획이었지만, 빠른 배포와 지속적인 통합/배포(CI/CD), 그리고 손쉬운 오류 로그 확인을 위해 Vercel을 선택하였습니다.
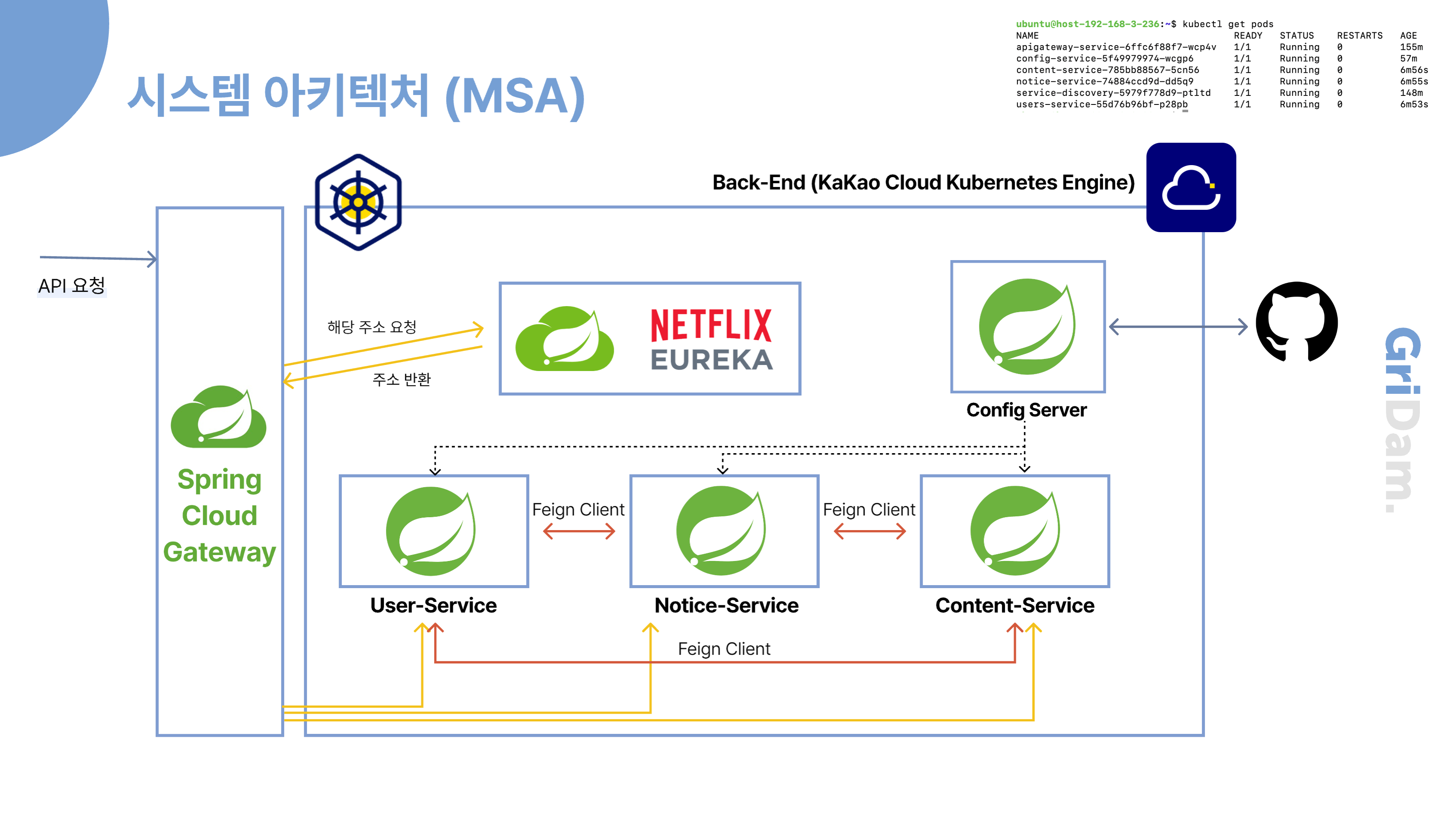
다음은 MSA 구조로 개발된 핵심 서비스들이 배포된 Kakao Cloud의 Kubernetes 환경입니다. 개발 작업은 같은 VPC 내에 위치한 public IP가 할당된 bastion host VM을 통해 이루어졌습니다. 외부에서 들어오는 API 요청은 Spring Cloud Gateway를 거쳐 Eureka를 통해 해당 서비스로 라우팅됩니다. 각 마이크로서비스 간의 통신은 Feign Client를 통해 이루어지며, 서비스 이름 기반으로 Eureka에서 위치를 조회해 안정적인 내부 호출이 가능하도록 구성되어 있습니다.
또한, 보안이 필요한 환경 변수나 인증 키 등은 Config Server에 저장되어, 각 서비스는 이를 통해 설정값을 불러와 실행됩니다. 아래는 서비스들이 각각의 Pod로 배포되어 있는 구조를 시각화한 예시입니다.
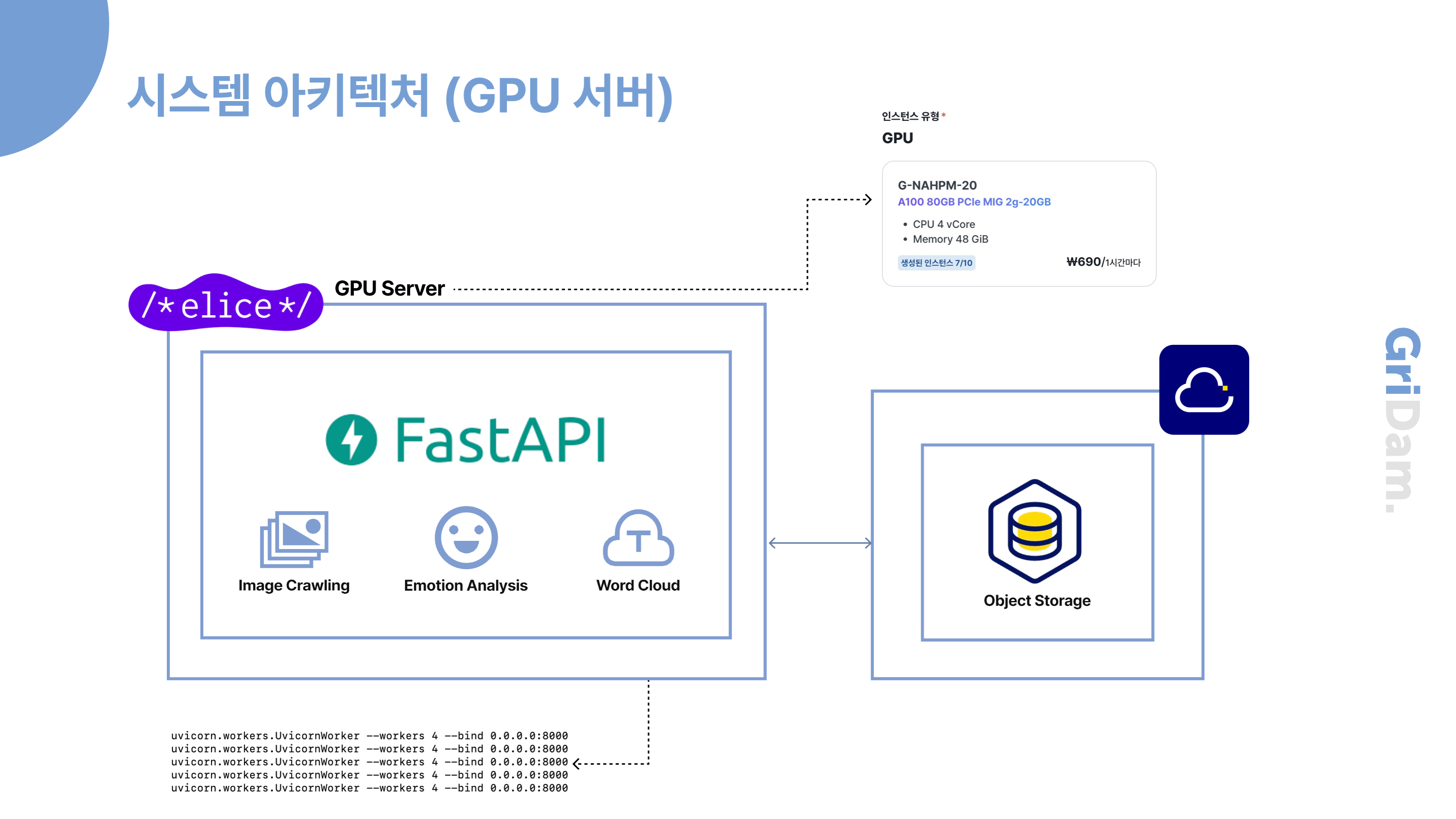
다음은 MSA 중 감정 분석 및 감정 카드 생성 서비스에 대한 설명입니다. 이 서비스는 GPU 가속이 적용된 가상머신(GPU VM)에 배포되어 있으며, systemd를 활용해 총 4개의 워커 노드 프로세스를 실행하여, 더 많은 요청을 병렬로 처리하고 응답 속도 및 처리량을 개선할 수 있도록 설계했습니다. 사실상 VM 인스턴스를 2개 배포하는 것이 처리 성능 측면에서는 더 효율적이지만, GPU VM은 1시간당 약 690원의 비용이 발생하여, 이를 지속적으로 운영할 경우 월 약 50만 원의 서버 비용이 들어갑니다. 따라서 인스턴스를 추가하는 대신, 하나의 인스턴스 내에서 효율을 극대화하는 방향으로 구성했습니다. 또한, 엘리스 서버 환경에서는 Docker를 사용할 수 없어, 자동화 도구 없이 하나하나 직접 스크립트를 작성하여 파이프라인을 구성해야 했습니다. 이를 통해 GPU 워커 서비스도 최소한의 자동화 환경에서 안정적으로 실행될 수 있도록 했습니다.
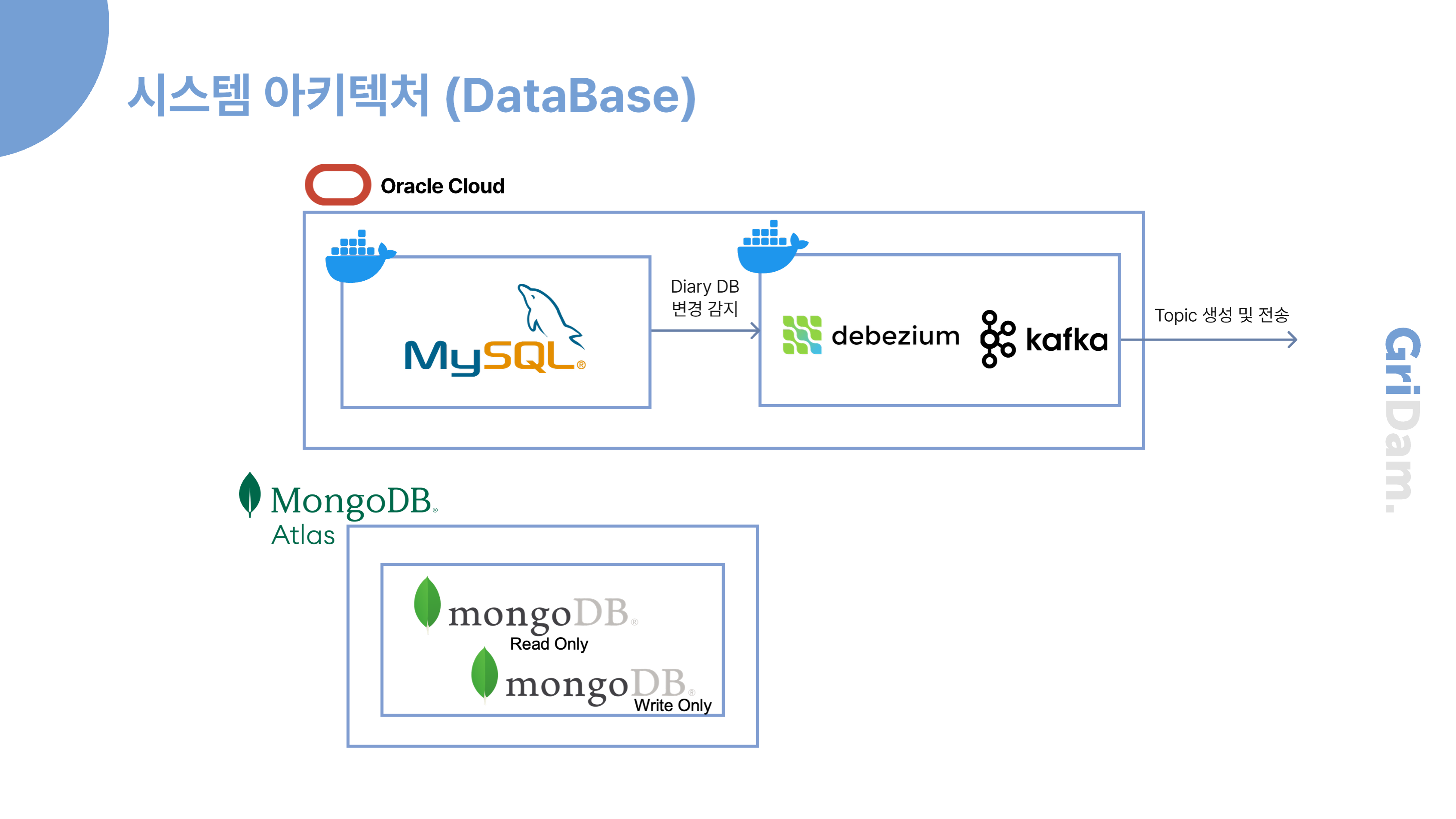
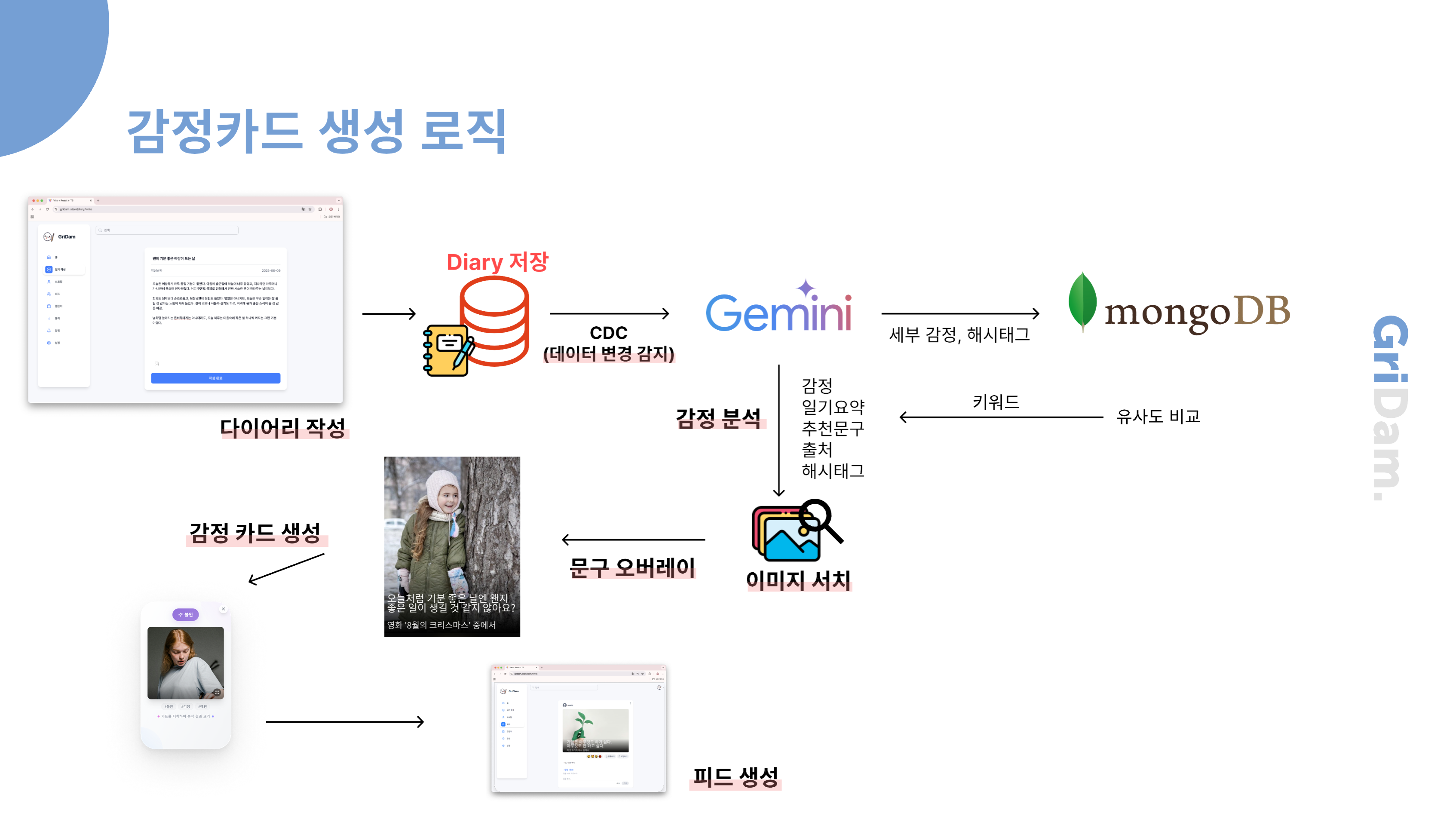
저희 시스템은 MySQL의 diary 테이블에 변화가 생기면, CDC(Change Data Capture) 기술을 활용해 이를 실시간으로 감지합니다. 감지된 데이터는 Kafka 메시지 큐를 통해 전달되고, 최종적으로 MongoDB에 저장됩니다.
이 과정에서 모든 컴포넌트를 Docker 컨테이너로 배포해 동일한 네트워크 내에서 운영합니다. 이렇게 하면 CDC와 백업, 모니터링 같은 확장 작업이 용이해지고, 컴포넌트 간 연동도 안정적이며 관리 효율성도 높일 수 있습니다
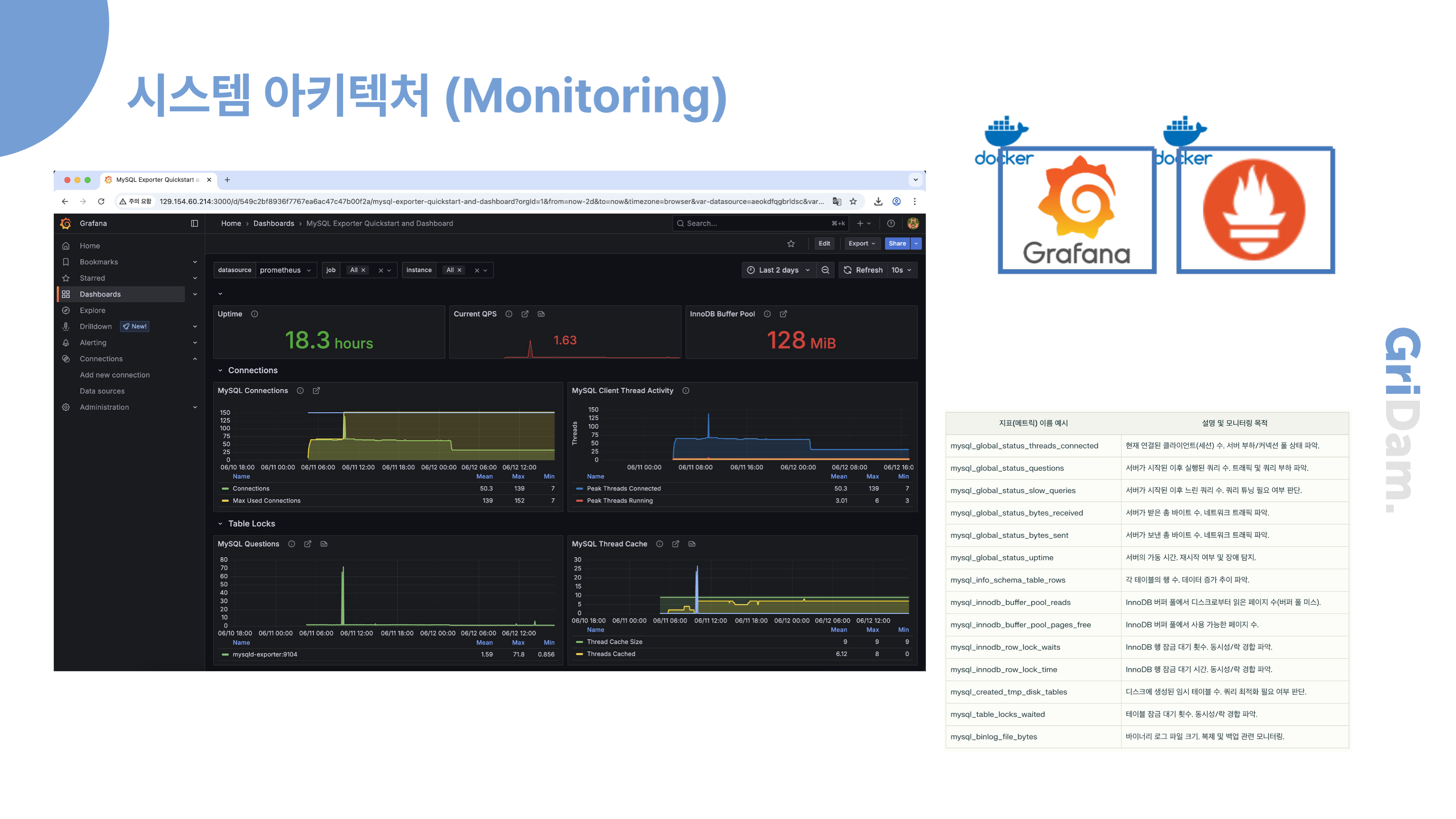
시스템 안정성을 높이기 위해 MySQL 데이터베이스와 애플리케이션 서버에 대해 모니터링을 구축했습니다. 구체적으로는 Prometheus를 이용해 서버와 데이터베이스의 주요 성능 지표를 수집하고, Grafana를 통해 이를 시각화했습니다. 덕분에 CPU 사용량, 메모리 상태, 쿼리 처리 속도 등 다양한 상태를 실시간으로 모니터링할 수 있고, 이상 징후를 빠르게 감지하여 신속하게 대응할 수 있습니다.
이와 같은 모니터링 체계는 전체 시스템의 안정적인 운영과 장애 예방에 도움이 되고 있습니다.
CICD
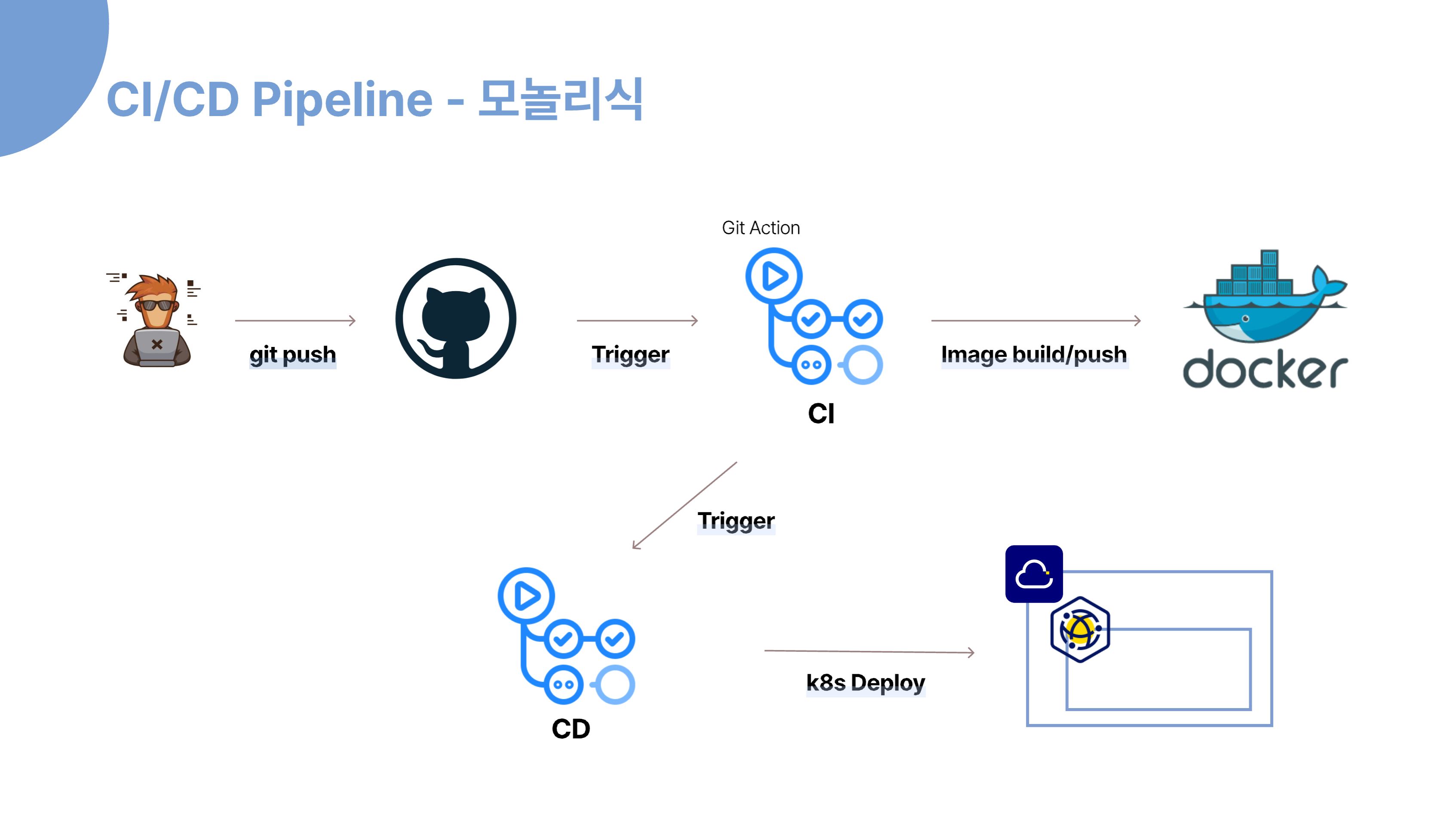
다음은 개발 초기의 모놀리식 CICD 파이프라인입니다.
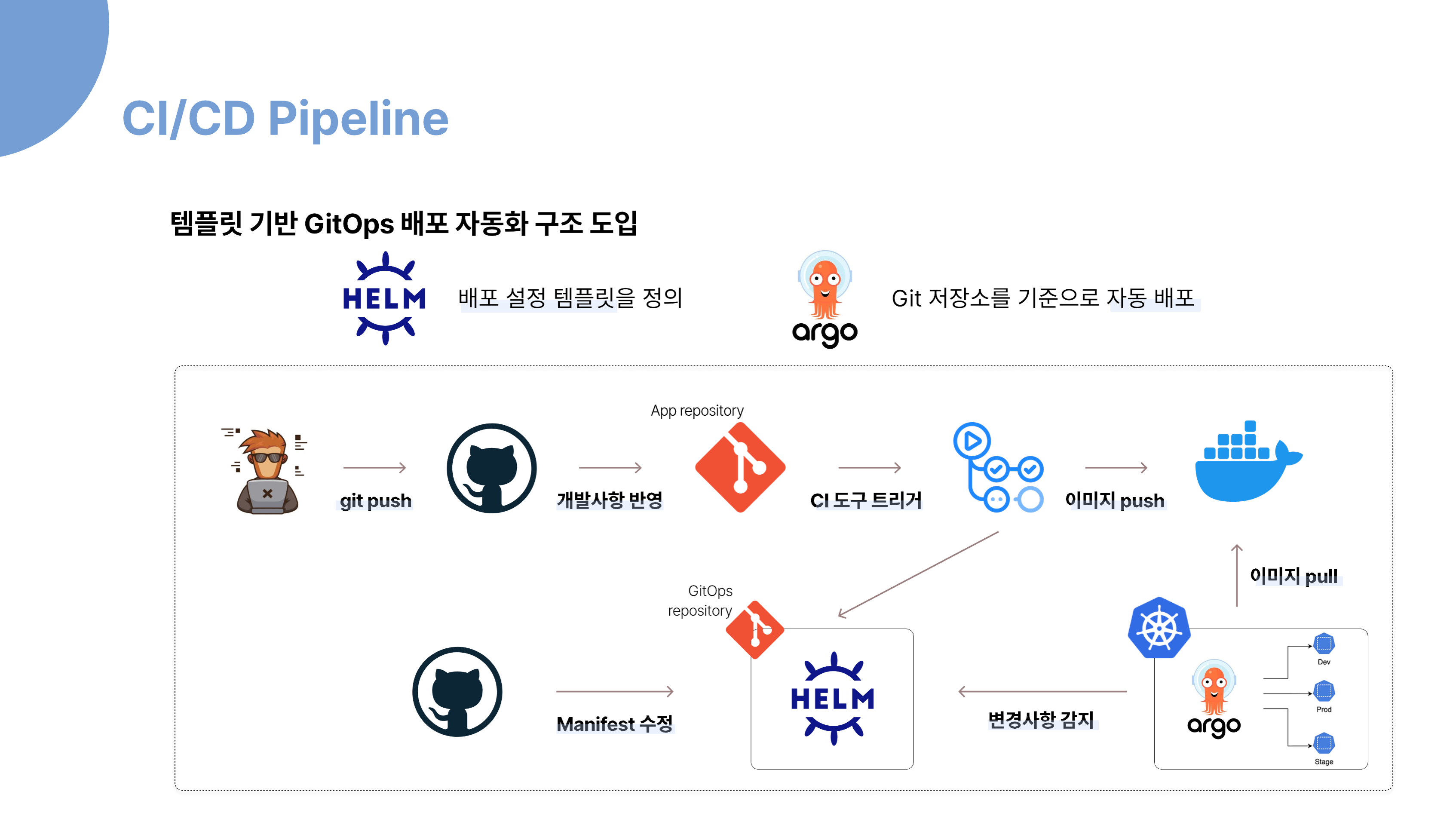
개선된 MSA CICD 파이프라인입니다.
템플릿 기반 GitOps 배포 자동화 구조에 대해 설명드리겠습니다.
먼저, Helm을 활용해 배포 설정 템플릿을 정의합니다. 개발자는 소스 코드를 수정하고 git push를 하면, GitHub에 변경 사항이 반영되고, CI 도구가 트리거되어 새로운 이미지를 빌드하고 레지스트리에 push합니다.
이후, Helm 템플릿이 포함된 GitOps 저장소의 Manifest 파일을 수정하면, ArgoCD가 Git 저장소의 변경 사항을 자동으로 감지합니다. ArgoCD는 Git에 정의된 상태를 기준으로 Kubernetes 클러스터에 자동으로 배포를 수행합니다. 이 과정에서 운영 환경의 일관성을 유지할 수 있고, 변경 이력 관리와 롤백도 수월해집니다.
즉, Helm은 ‘무엇’을 배포할지 정의하고, ArgoCD는 ‘어떻게’ 배포할지를 자동화하는 역할을 합니다. 이 구조를 통해 효율적이고 안정적인 배포 자동화를 실현할 수 있습니다.
향후 개선 방안
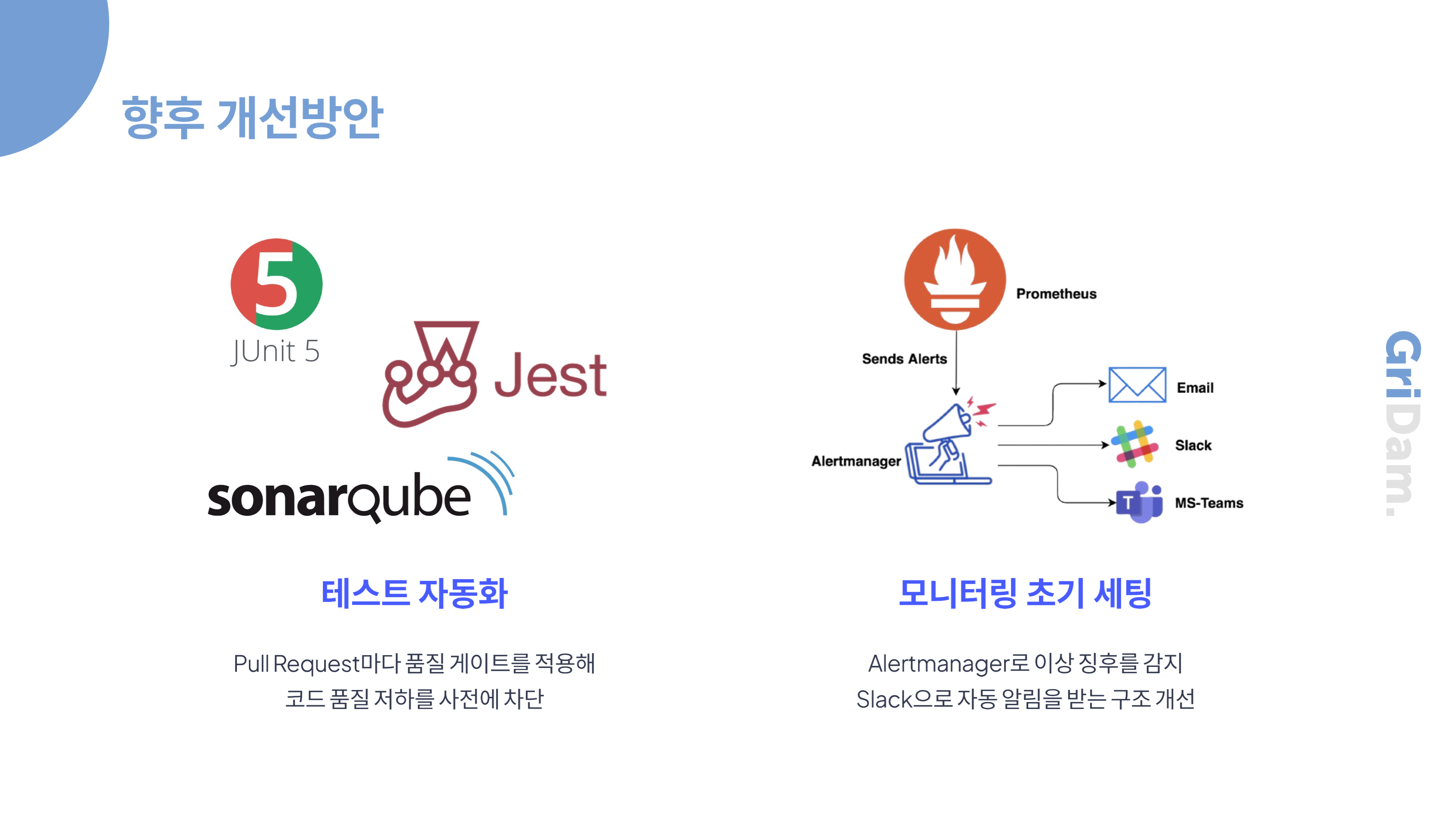
먼저, 테스트 자동화입니다. 앞으로는 Pull Request마다 자동화된 테스트와 품질 게이트를 적용해 코드 품질 저하를 사전에 차단할 계획입니다. 단위 테스트, 통합 테스트, 기능 테스트 등 다양한 레벨의 테스트를 자동으로 실행해, 코드 변경 시마다 버그를 빠르게 발견하고 개발자에게 즉각적으로 피드백을 제공할 수 있습니다. 이를 통해 반복적인 수작업을 줄이고, 테스트의 일관성과 신뢰성을 높이며, 개발 주기를 단축할 수 있습니다. 또한 테스트 결과와 커버리지, 결함률 등의 품질 지표를 시각화해 개발팀 전체가 품질 현황을 쉽게 파악할 수 있도록 하겠습니다.
다음은 모니터링 환경의 초기 구축입니다. 이번 프로젝트에서는 기획이 중간에 변경되면서 서비스 구현에 급급해, 모니터링을 초기에 세팅하지 못했습니다. 그 결과, VM이 죽거나 서비스에 오류가 발생했을 때 로그를 일일이 서버에 접속해 확인해야 했고, 장애 대응에 많은 시간이 소요됐습니다. 이런 경험을 바탕으로, 앞으로는 서비스 개발 초기 단계부터 모니터링 환경을 반드시 구축할 예정입니다.
특히, Prometheus와 Alertmanager를 활용해 시스템의 주요 지표와 이상 징후를 실시간으로 감지하고, Alertmanager가 Slack으로 자동 알림을 전송하는 구조로 개선하겠습니다. 예를 들어 CPU 사용량, 메모리, 네트워크 트래픽 등에서 비정상적인 상태가 감지되면, Alertmanager가 즉시 Slack 채널로 알림을 보내 담당자가 신속하게 문제를 인지하고 대응할 수 있도록 할 계획입니다. 이 구조는 단순히 모니터링 화면을 보는 것에 그치지 않고, 장애나 이상 상황이 발생하면 실시간으로 알림을 받아 빠르게 조치할 수 있다는 점에서, 서비스의 안정성과 운영 효율성을 크게 높여줍니다.
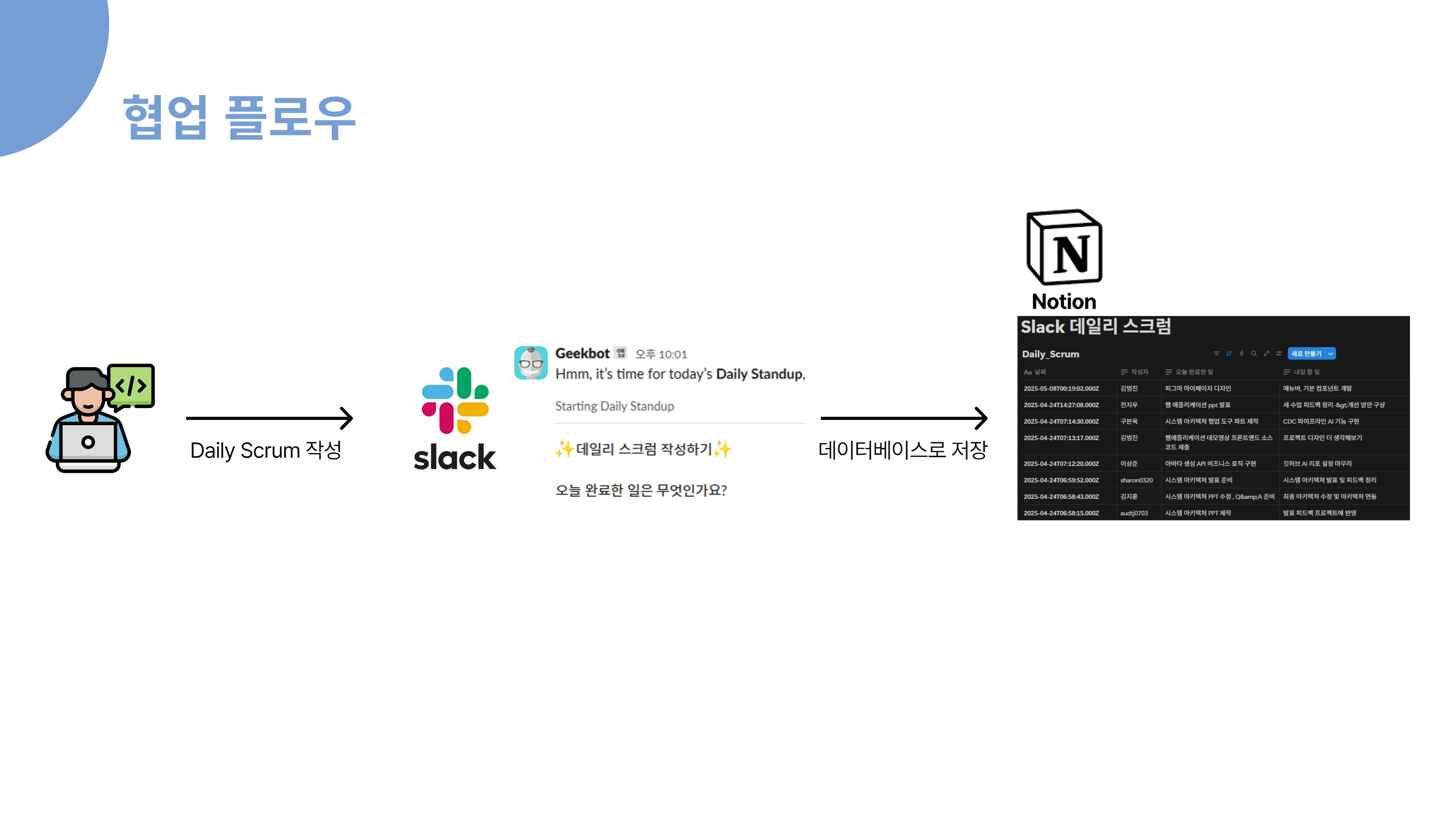
협업 툴 소개
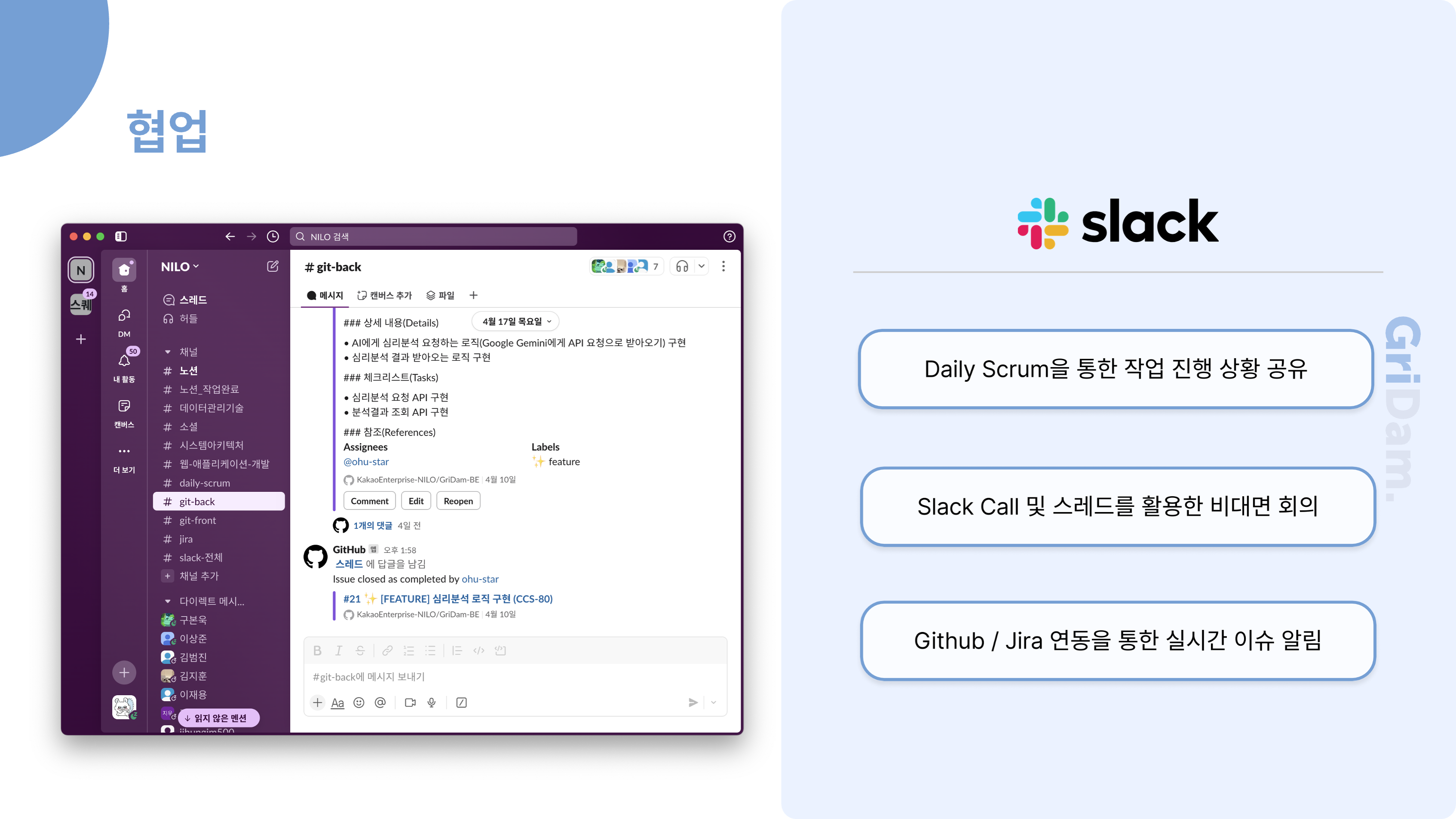
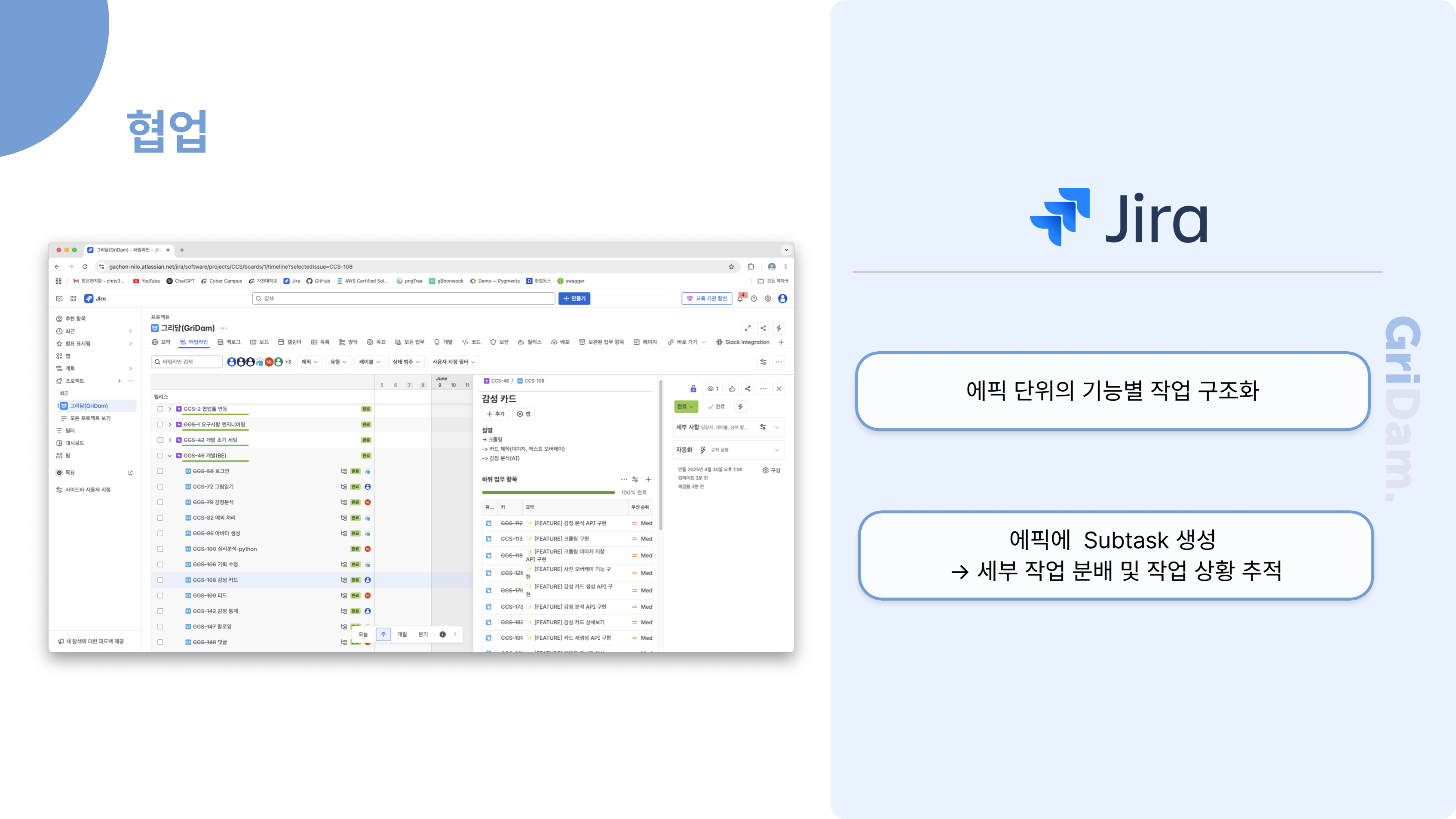
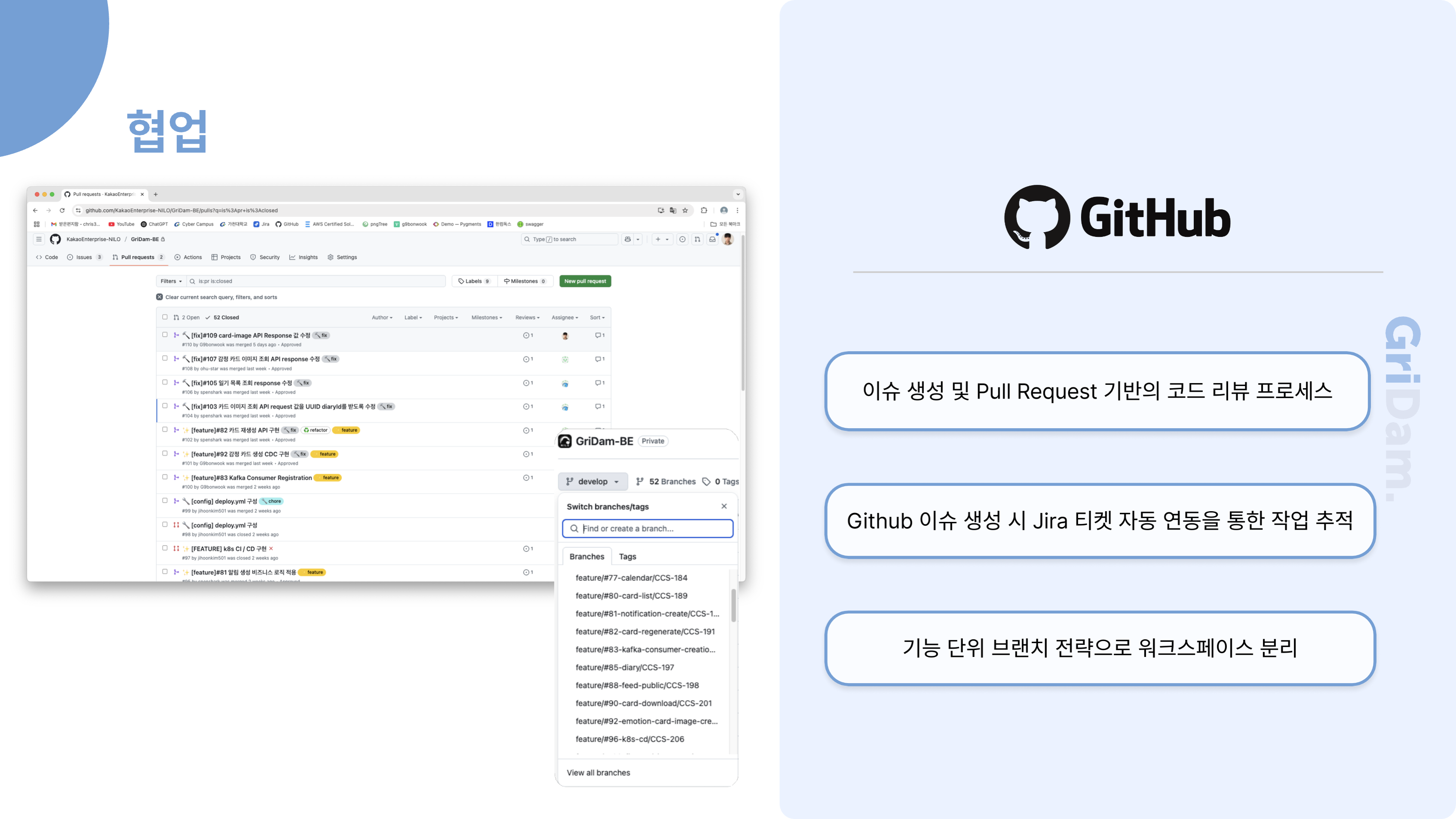
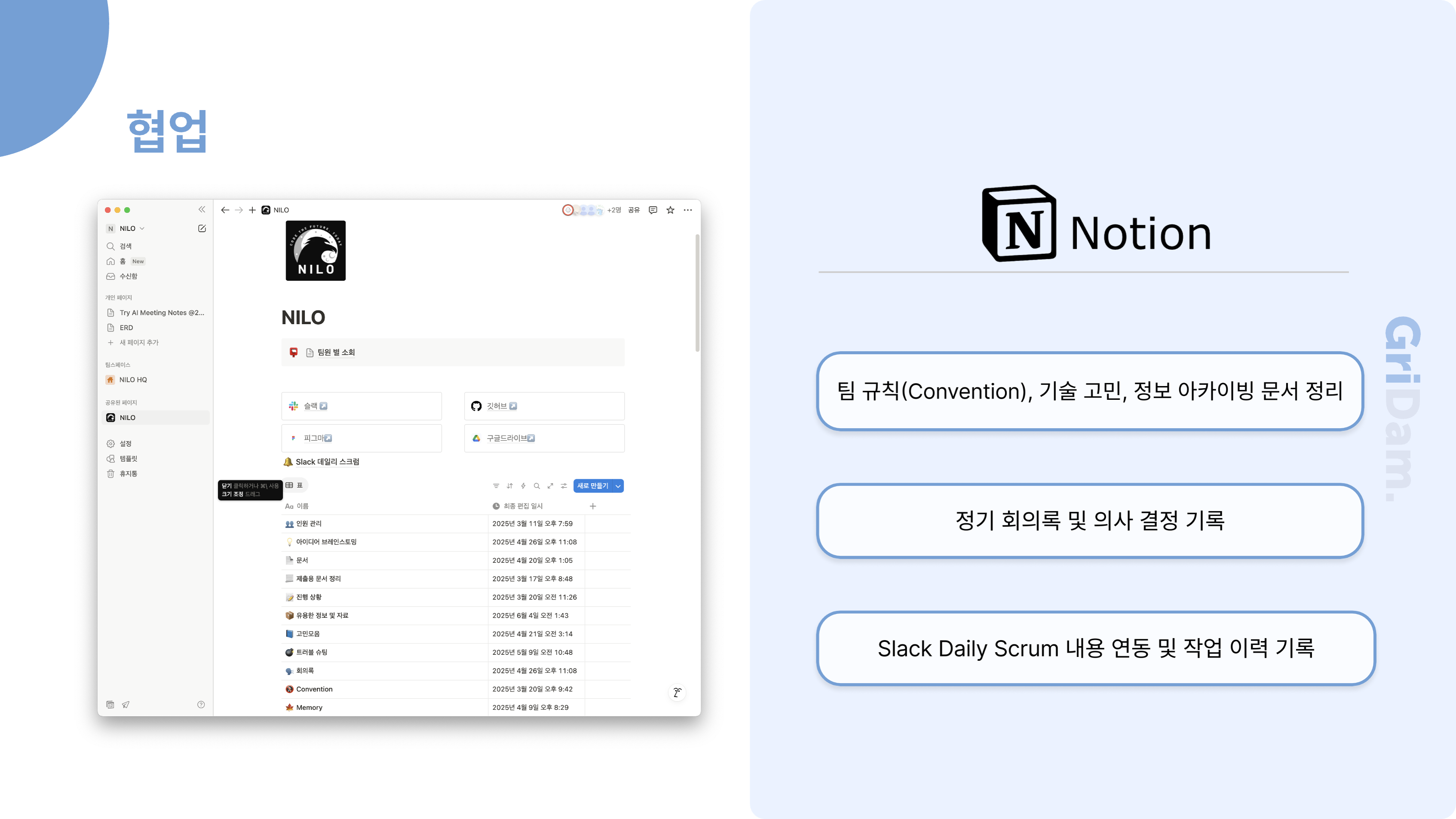
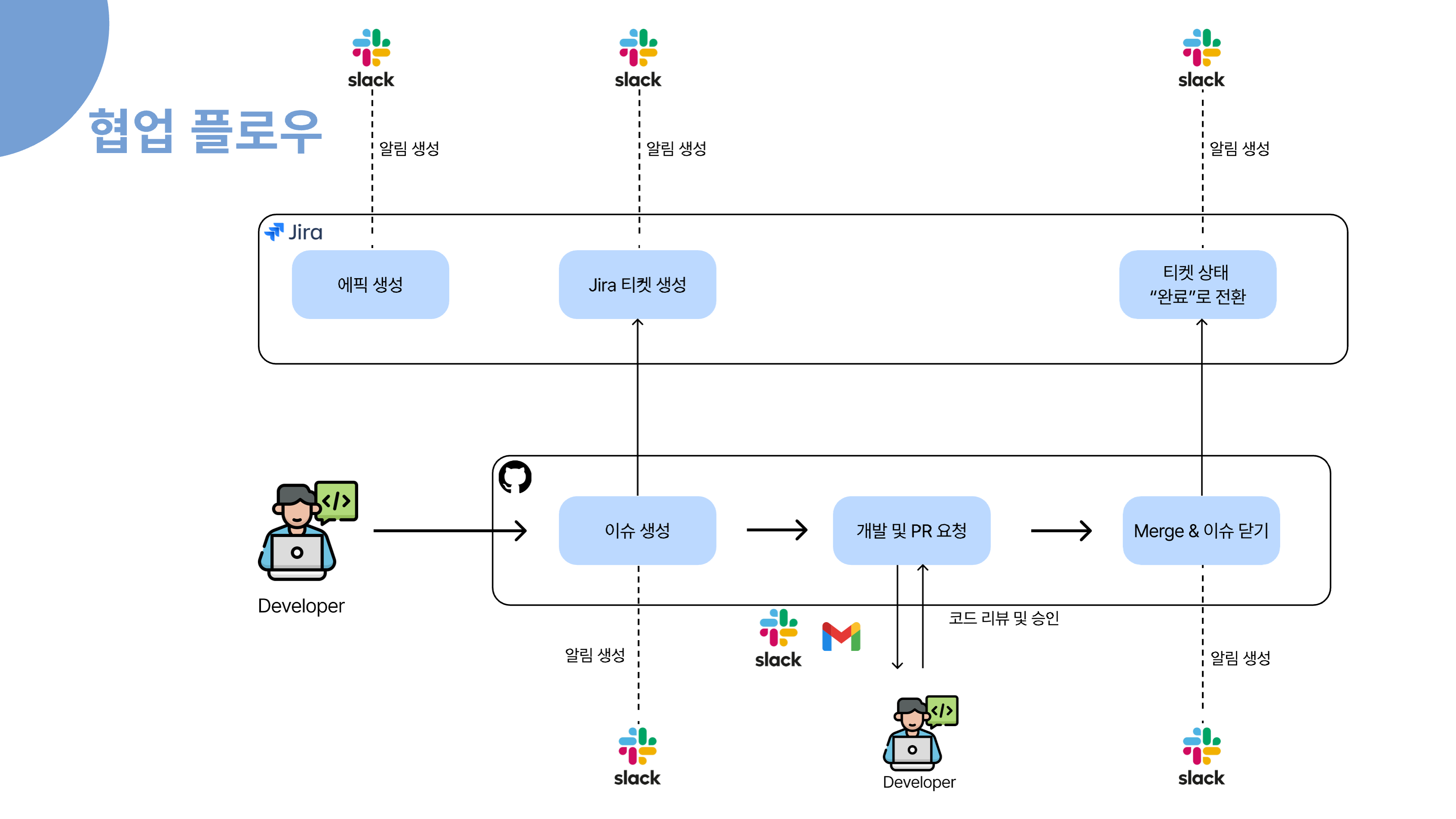
먼저, 전체 업무 관리는 Jira를 중심으로 이루어집니다. 새로운 프로젝트나 큰 기능이 필요할 때 Jira에서 에픽을 생성하고, 세부 작업은 티켓으로 관리합니다. 에픽이나 티켓이 생성되면 Slack으로 자동 알림이 발송되어 팀원 모두가 실시간으로 업무 상황을 인지할 수 있습니다.
개발자는 Jira 티켓을 기반으로 GitHub에서 이슈를 생성하고, 이 과정 역시 Slack을 통해 알림이 전달됩니다. 이슈가 생성되면 개발자가 실제로 개발을 진행하고, 완료된 후에는 Pull Request를 요청합니다. 이때 코드 리뷰 요청이 Slack과 Gmail로 자동 안내되어, 리뷰어가 신속하게 확인하고 피드백을 줄 수 있습니다.
코드 리뷰가 승인되면, PR이 Merge되고 관련 이슈가 자동으로 닫힙니다. 이 모든 과정에서 상태 변화가 있을 때마다 Slack으로 알림이 전송되어, 팀원 모두가 업무의 흐름을 투명하게 파악할 수 있습니다. 마지막으로 Jira 티켓의 상태가 "완료"로 전환되면, 다시 한 번 Slack 알림이 발송되어 업무 종료까지도 자연스럽게 공유됩니다.
이런 구조를 통해, 저희 팀은 Jira, GitHub, Slack, Gmail을 유기적으로 연동하여 업무의 시작부터 종료까지 모든 과정을 자동화하고, 실시간으로 소통하며 협업의 효율성과 투명성을 높이고 있습니다