OCR(Optical Character Recognition)

OCR이란
" 광학 문자 인식(Optical character recognition; OCR)은 사람이 쓰거나 기계로 인쇄한 문자의 영상을 이미지 스캐너로 획득하여 기계가 읽을 수 있는 문자로 변환하는 것이다. " - 위키백과
쉽게 말하자면, 사진에서 글자를 인식해 해당 문자로 변환하는 것을 뜻한다.
OCR 구조
초기 파이프라인
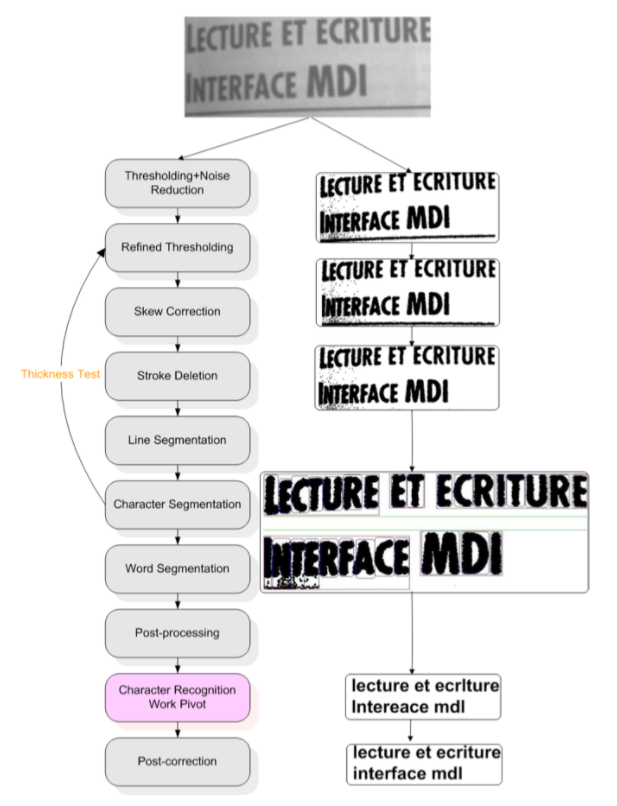
(출처: C' eline THILLOU, 'Degraded Character Recognition', 2003~2004.)
OCR의 초기 파이프라인은 다음과 같다.
텍스트 라인을 찾는 모듈, 텍스트를 단어 단위로 구분하는 모듈 등 여러 모듈이 존재하는데, 원래 OCR이 딥러닝을 위한 모델이 아니었기 때문에 비교적 복잡한 구조를 갖고 있다.
딥러닝과 OCR
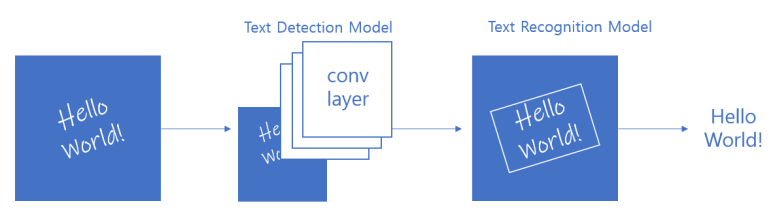
OCR은 딥러닝을 거치면서 점점 발전하기 시작했다. 그 이유는 CNN이다.
딥러닝의 핵심이라고 할 수 있는 CNN(Convolution Neural Networks)에서는 이미지에서 그 특징을 추출해 분류한다.
이 과정에서 기존의 OCR 구조에선 필수적이었던, 개발자가 직접 설정해주어야 했던 feature 인식 모듈이 필요하지 않게 되었다.
그래서 위 이미지와 같은 보다 간단한 구조를 갖게 되었다.
현재 OCR은 딥러닝과 접목하면서 두 단계 (2 steps)로 구성된 구조를 가지고 있다.
1. Text Detection Model: 글자의 영역을 탐지하는 모델
2. Text Recognition Model: 해당 영역에서 글자를 인식하는 모델
이렇게 두 단계로 나눔으로써 OCR은 다양한 데이터를 활용한 원활한 학습이 가능해졌고, 자원의 효율성과 언어별 정확도를 향상시킬 수 있게 되었다.
OCR 진행 과정을 조금 더 자세히 보자면 다음과 같다.
1) Data Pre-Processing
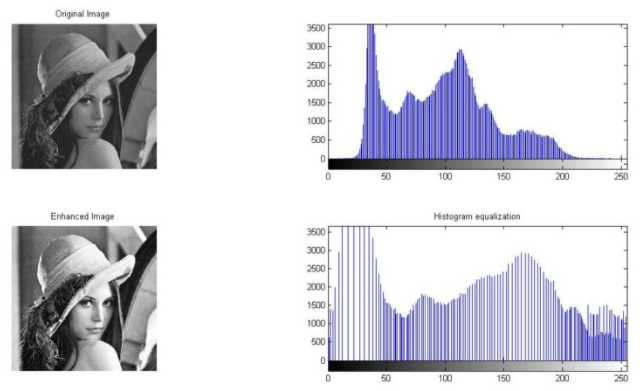
인간은 자라면서 글을 배우기 때문에 자연스럽게 문자를 보면 그것이 문자임을 알고, 이미 알고있는 언어라면 그것이 어떤 문자인지도 알 수 있다.
그러나 컴퓨터는 인간과 다르게 이미지와 글자를 구분하여 인식하지 않는다.
이미지와 글자, 둘 다 비슷한 색의 픽셀이 연속으로 이어져있어 이를 감지할 뿐이다.
(그렇기 때문에 Object Detection과 유사한 부분이 많다.)
이러한 특성 때문에 음영의 손상, 왜곡 등으로 이미지의 quality가 떨어지면 텍스트 인식률 및 정확도가 매우 낮아진다.
그러나 이는 Data Pre-Processing (전처리) 과정을 거치면 어느 정도 해결할 수 있다.
위 그림도 이미지 데이터를 전처리하는 것을 표현한 그림인데, 여기는 '히스토그램 정규화'라는 방법을 통해 이미지의 명암을 재분배해 이미지의 구성 요소를 정확하게 구분할 수 있도록 한 것이다.
2) Text Detection Model
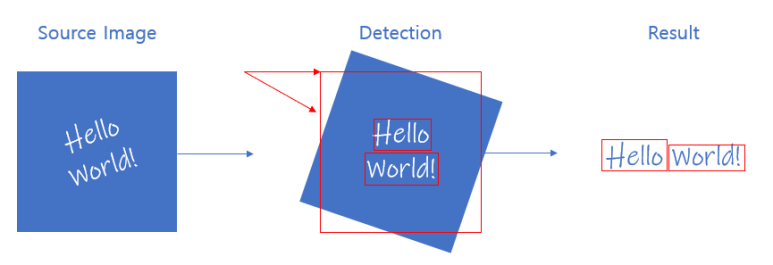
Data Pre-Processing을 거친 후에는, Text Detection 단계로 넘어간다.
여기선 이미지를 CNN에 넣은 후 이미지의 feature를 추출한다.
여기서 얻는 feature data는 텍스트의 영역과 각도이다.
먼저 텍스트가 존재하는 영역을 찾은 뒤, 이 영역의 각도가 수평이 되도록 각도를 조절하고, 이 후에 이미지를 텍스트 단위로 분할한다.
3) Text Recognition Model

Text Detection을 통해 텍스트를 분할하고 나면, 분할한 텍스트가 어떤 글자인지 인식하는 단계인 Text Recognition 단계로 넘어간다.
이를 위해선 사전에 model 학습이 필요하다.
이미지를 CNN에 입력해 해당 텍스트 이미지가 어떤 글자인지 파악할 수 있도록 학습한다.
(Text Recognition의 CNN != Text Detection의 CNN)
충분히 학습되었다면 원하는 결과를 반환할 것이다.
그러나 문자는 필기체와 같이 개개인마다 달라 학습이 어려운 경우가 있으며, 영어와 달리 초성/중성/종성으로 이루어져 있는 한글과 같은 문자 또한 난이도가 높은 편이다.
대표적인 OCR 모델
사람들이 많이 사용하고, fine tuning 또한 많이 하는 모델로는
- Tesseract
- EasyOCR
- Keras-OCR
등이 있다.
이 모델들은 대부분 오픈되어 있어 라이브러리처럼 사용할 수 있다.
한글 OCR 모델 및 CRNN
앞에서 말했지만, 한글 OCR은 OCR 중에서도 난이도가 높은 편이다. OCR 모델들을 찾아봐도 대부분 영어를 인식하는 모델이지, 한글을 인식하는 모델들은 그 수가 현저히 적고, 정확도 또한 높지 않은 것을 볼 수 있다.
그나마 한글 인식을 위한 모델로는 EasyOCR을 많이 사용하는 듯 하다. 대부분 인식하려는 이미지를 규격화해 이를 바탕으로 fine tuning을 진행한다.
그러나 우리가 인식할 target 이미지는 '부동산 임대차계약서'다. 그 어떤 이미지보다 높은 정확도가 요구되기 때문에 기존 라이브러리 모델을 fine tuning 하는 대신, 직접 코드를 구현해 모델 학습을 시키기로 결정했다.
CRNN
알아본 바로, 보통 Text Detection Model로는 SSD, Text Recognition Model로는 CRNN을 선택하는 거 같다.
이 중에서 우리는 '한글'을 제대로 인식해야 하는 문제를 해결해야 하기 때문에 Text Recognition Model인 CRNN을 학습시키기로 결정했다.
CRNN 구조
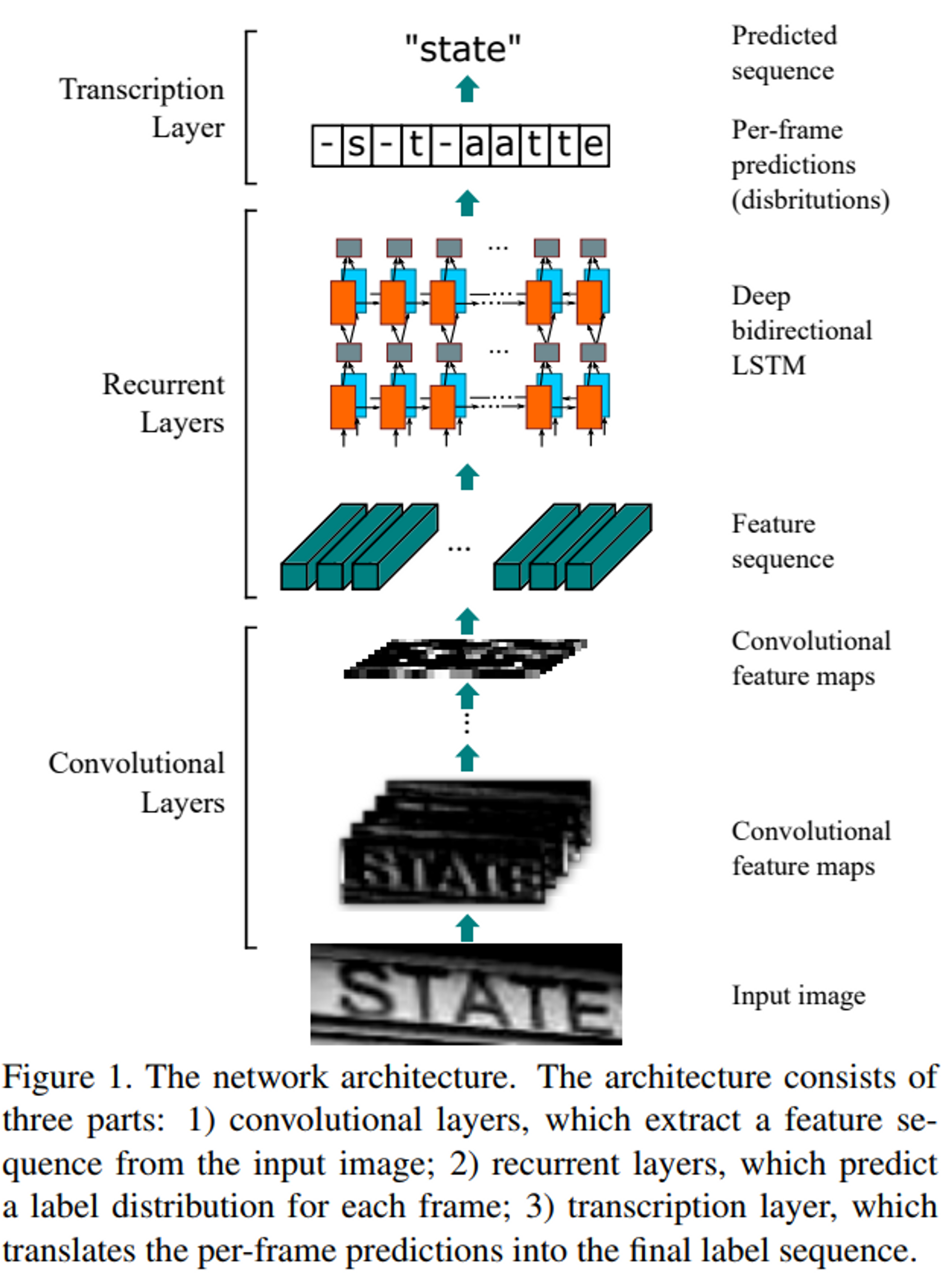
CRNN 구조는 위 이미지와 같다.
Convolution Layers + Recurrent Layers + Transcription Layers
총 3가지 Layers로 구성되어 있는데, 다음은 각 Layer의 특징이다.
- Convolution Layers : 입력 이미지로부터 feature 시퀀스 추출 ( -> CNNs )
- Recurrent Layers : 각 프레임마다 라벨 예측 ( -> RNNs )
- Transcriptional Layers : 프레임마다의 예측을 최종 라벨 시퀀스로 변경
CRNN 모델의 backbone model 함수
- backbone 역할을 하는 함수: VGG-16 model 구현
- CNN Layer + LSTM(RNN) Layer
- CNN Layer
: 마지막에 있는 2개의 Fully-Connected Layer 층은 CNN층으로 변경 - LSTM(RNN) Layer
: LSTM 사용 -> gru = False
: GRU 사용 -> gru = True
1. CRNN parameter
- input_shape: (256, 32, 1)
- num_classes: 87 <- 라벨로 사용되는 class 수
2. CRNN model output_shape (train, predict model 각각 존재)
[Model Architecture]
CNN(6) + RNN(LSTM)(2) + FC(1) + Activation(Softmax) = x
- model_train
Model (inputs=[image_input, labels, input_length, label_length], outputs=ctc_loss)
>> output_shape: (None, 1)
>> train model) input parameter가 4개로 늘어나고, output 값이 ctc_loss를 적용한 값이 나온다. - model_pred
Model(image_input, x)
>> Model의 output은 softmax를 통과하고 나옴
>> output_shape: (None, 62, 87)
3. Model.summary(): 각 model에서 공통으로 가지는 부분 (model_predicton과 동일)
- Input
(None, 256, 21, 1) - (#samples, width, height, channel) - Conv1_1 * MaxPooling
(None, 128, 16, 64) - 128 * 16 크기의 feature map 64개 생성 - Conv2_1 * MaxPooling
(None, 64, 8, 128) - 64 * 8 크기의 feature map 128개 생성 - Conv3_1 * Conv3_2 * MaxPooling
(None, 64, 4, 256) - 64 * 4 크기의 feature map 256개 생성 - Conv4_1 * BatchNormalization
(None, 64, 4, 512) - 64 * 4 크기의 feature map 512개 생성 - Conv5_1 * BatchNormalization * MaxPooling
(None, 64, 2, 512) - 64 * 2 크기의 feature map 512개 생성 - Conv6_1
(None, 64, 1, 512) - 64 * 1 크기의 feature map 512개 생성 - Reshape
(None, 64, 512) - reshape(-1, 512)로 모양 변경 - Bidirectional LSTM * Bidirectional LSTM
(None, 64, 512) - Dense
(None, 64, 87) - Softmax
(None, 64, 87)
이 기본 구조는 model_prediction 할 때도 사용된다.
model_train과의 차이점은, train 시킬 땐 기존 이미지 input에 3개의 input이 더 추가되고, output value가 ctc loss라는 점이다.
데이터 전처리 (Data Pre-Processing)
데이터 생성
우리가 인식할 대상인 '표준임대차계약서'는 개인정보가 포함되어 있어 그 데이터를 구하기가 어려웠다.
그래서 직접 데이터를 만들기로 했는데, 지금은 OCR 모델 test용이라서 데이터를 많이 만들지 않았다.

부동산 임대차계약서를 검색해보면 다양한 양식이 나오는데, 그 중 이 양식을 제일 많이 사용하는 거 같아서 이 데이터를 활용했다.
우리가 조사한 바로, 표준임대차계약서에서 가장 문제가 되는 부분은 특약사항 부분이었다.
그래서 OCR 모델도 일단은 특약사항 부분을 먼저 인식하고, 그 다음에 확장시키는 방향으로 나아가기로 했다.
그래서 다양한 특약사항들이 적힌 표준임대차계약서 이미지 30장을 만들었다.
직접 만든 데이터 중 하난데, 이런 식으로 여러 특약사항을 입력했다.
데이터 전처리
만든 이미지 데이터를 OCR 학습에 활용하려면, 해당 이미지에서 어느 부분이 어느 text value를 가지고 있는지 직접 설정해줘야 한다.
이 annotation 작업은 VGG Image Annotator를 사용해 진행했다.

이런 식으로 특약사항들을 문장 단위로 끊어, text value들을 입력해주었고,
작업이 끝난 후에는 이 데이터들을 JSON 파일로 export 해줬다.
AI HUB '한국어 글자체 이미지'
https://www.aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100
그리고 AI HUB에 '한국어 글자체 이미지' 데이터셋이 있다.
이 데이터셋에는 필기체, 인쇄체, 그리고 text in the wild라는 실사 데이터가 들어있다.
우선 우리는 표준임대차계약서가 모두 인쇄체로 되어있다는 가정 하에 학습을 진행하기로 했으므로, 이 데이터셋에서 인쇄체 데이터만 다운 받았다. (여력이 된다면, 후에 필기체까지 적용시킨 model를 구현하기로 했다.)
참고로, 데이터셋에는 인쇄체랑 인쇄체 증강데이터가 있다. 그리고 그냥 인쇄체 데이터만 해도 4만장이 넘는다.
나는 test용이라는 학습 목적과 학습 시간을 고려해 4만장의 인쇄체 데이터만 활용했다.
Data Augmentation
CRNN model 학습을 할 때 input data를 train data와 validation data로 나누었다.
이 때, train data에는 AI HUB에서 받은 '한국어 글자체 이미지 데이터'를, validation data에는 '표준임대차계약서 이미지 데이터'를 사용했다.
그런데 이 때 train data는 4만 개가 넘는 반면 validation data는 50개도 되지 않는다. imbalance가 발생한다.
이 두 dataset 사이의 격차를 확실하게 줄이기는 어렵지만, 그래도 조금이라도 gap을 줄여보자는 마음으로 validation data에 대해 augmentation 작업을 진행했다.
# data_augmentation.ipynb
import scipy
from scipy import ndimage
import matplotlib.pyplot as plt
import cv2
import os
path = r'/content/sample_data'
imgName = '010001.jpg'
img = cv2.imread(os.path.join(path, imgName))
f = img
print(f.shape) #32, 256
blurred_f = ndimage.gaussian_filter(f, 1)
filter_blurred_f = ndimage.gaussian_filter(blurred_f, 4)
alpha = 3
sharpened = blurred_f + alpha * (blurred_f - filter_blurred_f)
plt.figure(figsize=(50, 30))
plt.subplot(131)
plt.imshow(f, cmap=plt.cm.gray)
plt.axis('off')
plt.subplot(132)
plt.imshow(blurred_f, cmap=plt.cm.gray)
plt.axis('off')
plt.subplot(133)
plt.imshow(sharpened, cmap=plt.cm.gray)
plt.axis('off')
plt.tight_layout()
plt.show()이 코드는 원본 이미지를 블러 & 샤프닝 처리하는 코드이다.
나는 예를 들기 위해 원본 이미지로는 다음과 같은 이미지를 사용했다.

위에 있는 임대차계약서 이미지에서 특약사항의 일부분을 자른 것이다.
이 이미지를 input으로 augmentation code를 실행하면 다음과 같은 output이 나온다.

순서대로 원본 이미지 > blur 처리한 이미지 > sharpening 처리한 이미지 이다.
blur 처리한 이미지를 자세히 보면 이렇게 생겼다.

그리고 sharpening 처리한 이미지를 자세히 보면 이렇게 생겼다.

CRNN Model Train
1. JSON data 확인
[임대차계약서 데이터]
import os
import json
gt_path = '/content/sample_data/'
with open(os.path.join(gt_path, 'via_project_18Nov2022_9h40m_json.json')) as f:
gt_data = json.load(f)
print(gt_data)
id_list = []
for id in gt_data.keys():
id_list.append(id)
print(gt_data[id_list[0]])
[한국어 이미지 데이터]
import os
import json
gt_path = '/content/sample_data/'
with open(os.path.join(gt_path, 'printed_data_info.json')) as f:
gt_data = json.load(f)print(gt_data['images'])
print(gt_data['annotations'])
2. GTUtility(BaseGTUtility) 함수 작성
JSON 파일을 받아서 아용하기 좋게 데이터를 정제하는 utility
[임대차계약서 데이터]
import numpy as np
import json
import os
from PIL import Image
class GTUtility(BaseGTUtility):
def __init__(self, data_path, validation=False, only_with_label=True):
test=False
self.data_path = data_path
gt_path = data_path
image_path = os.path.join(data_path, 'images')
self.gt_path = gt_path
self.image_path = image_path
self.classes = ['Background', 'Text']
self.image_names = []
self.data = []
self.text = []
with open(os.path.join(gt_path, 'via_project_18Nov2022_9h40m_json.json')) as f:
gt_data = json.load(f)
for img_id in gt_data.keys(): # images
if len(img_id) > 0:
img_data = gt_data[img_id]
image_name = img_data['filename']
image = Image.open('/content/sample_data/images/' + image_name)
width, height = image.size
img_width = width
img_height = height
boxes = []
text = []
for region in img_data['regions']: # boxes
shape_info = region['shape_attributes']
bbox = []
bbox.append(shape_info['x'])
bbox.append(shape_info['y'])
bbox.append(shape_info['width'])
bbox.append(shape_info['height'])
x, y, w, h = np.array(bbox, dtype=np.float32)
box = np.array([x, y, x+w, y+h])
txt = region['region_attributes']['text']
boxes.append(box)
text.append(txt)
if len(boxes) == 0:
continue
boxes = np.asarray(boxes)
boxes[:,0::2] /= img_width
boxes[:,1::2] /= img_height
# append classes
boxes = np.concatenate([boxes, np.ones([boxes.shape[0],1])], axis=1)
self.image_names.append(image_name)
self.data.append(boxes)
self.text.append(text)
self.init()
if __name__ == '__main__':
gt_util = GTUtility('/content/sample_data/', validation=False, only_with_label=True)
print(gt_util.data)
[한국어 이미지 데이터]
import numpy as np
import json
import os
class GTUtility(BaseGTUtility):
def __init__(self, data_path, validation=False, only_with_label=True):
test=False
self.data_path = data_path
gt_path = data_path
image_path = os.path.join(data_path, 'images')
self.gt_path = gt_path
self.image_path = image_path
self.classes = ['Background', 'Text']
self.image_names = []
self.data = []
self.text = []
with open(os.path.join(gt_path, 'handwriting_data_info_clean.json')) as f:
gt_data = json.load(f)
image_id = list(data['id'] for data in gt_data['images'])
for img_id in image_id: # images
if len(img_id) > 0:
image_name = next((item['file_name'] for item in gt_data['images'] if item['id'] == img_id), None)
img_width = next((item['width'] for item in gt_data['images'] if item['id'] == img_id), None)
img_height = next((item['height'] for item in gt_data['images'] if item['id'] == img_id), None)
boxes = []
text = []
box = np.array([0, 0, 1, 1])
boxes.append(box)
txt = next((item['text'] for item in gt_data['annotations'] if item['id'] == img_id), None)
text.append(txt)
if len(boxes) == 0:
continue
boxes = np.asarray(boxes)
# append classes
boxes = np.concatenate([boxes, np.ones([boxes.shape[0],1])], axis=1)
self.image_names.append(image_name)
self.data.append(boxes)
self.text.append(text)
self.init()
if __name__ == '__main__':
gt_util = GTUtility('/content/sample_data/', validation=False, only_with_label=True)
print(gt_util.data)3. Pickle file 생성
[임대차계약서 데이터]
import pickle
gt_util = GTUtility('/content/sample_data/', validation = False)
file_name = 'contract_image_data.pkl'
pickle.dump(gt_util, open(file_name, 'wb'))
print(gt_util)[한국어 이미지 데이터]
import pickle
gt_util = GTUtility('/content/sample_data/', validation = False)
file_name = 'gt_util_handwriting_data.pkl'
pickle.dump(gt_util, open(file_name, 'wb'))
print(gt_util)4. 라벨 (Target Value) 생성
: 임대차계약서 데이터 & 한국어 이미지 데이터 (공통 적용)
from itertools import chain
from sklearn.feature_extraction.text import CountVectorizer
import re
gt_util = GTUtility('/content/sample_data')
text = gt_util.text
text = list(chain(*text))
vect = CountVectorizer(analyzer='char').fit(text)
charset = list(vect.vocabulary_.keys())
pattern = '[^가-힣]' #한글이 아닌 문자는 공백으로 바꿔준다
charset_dict = [re.sub(pattern, "", char) for char in charset]
charset_dict2 = [x for x in charset_dict if x!= '']
str = "".join(charset_dict2)
contract_dict(printed_dict) = str그리고 마지막에
korean = contract_dict + printed_dict로 각 데이터의 라벨값들을 합쳐주면 target value가 완성된다.
[ E x ]

-> 한국어 이미지 데이터의 라벨 데이터로, 이런 식으로 값이 반환된다.
5. 라이브러리 호출
필요한 라이브러리들을 미리 호출한다.
import numpy as np
import matplotlib.pyplot as plt
import os
import editdistance
import pickle
import time
from keras.optimizers import SGD
from crnn_model import CRNN
from crnn_data import InputGenerator
from crnn_utils import decode
from utils.training import Logger, ModelSnapshot6. 생성한 pickle 파일 불러오기
# Train
file_name1 = '/content/sample_data/gt_util_printed.pkl'
with open(file_name1, 'rb') as f:
gt_util_train = pickle.load(f)
# Validation
file_name2 = '/content/sample_data/gt_util_contract.pkl'
with open(file_name2, 'rb') as f:
gt_util_val = pickle.load(f)앞에서 말했듯이, train data 와 val data로 미리 나누어줬다.
7. Model의 input parameter 정의
input_width = 256
input_height = 32
batch_size = 128
input_shape = (input_width, input_height, 1)
8. Freeze할 Layer층 결정 (For fine-tuning)
freeze = ['conv1_1',
'conv2_1',
'conv3_1', 'conv3_2',
'conv4_1',
'conv5_1'
]9. Model 및 버전명 정의
model, model_pred = CRNN(input_shape, len(korean_dict))
experiment = 'crnn_korean_contract_v1'10. input을 위한 generator 생성
max_string_len = model_pred.output_shape[1]
gen_train = InputGenerator(gt_util_train, batch_size, alphabet, input_shape[:2],
grayscale=True, max_string_len=max_string_len, concatenate=False)
gen_val = InputGenerator(gt_util_val, batch_size, alphabet, input_shape[:2],
grayscale=True, max_string_len=max_string_len, concatenate=False)지금은 처음 학습시키는 거라 코드가 여기서 끝났지만 만약 전에 학습시킨 결과에 이어 학습시키고 싶으면, 그 때의 가중치를 불러오면 된다.
11. 학습 과정 저장
checkdir = './checkpoints/' + time.strftime('%Y%m%d%H%M') + '_' + experiment
if not os.path.exists(checkdir):
os.makedirs(checkdir)
with open(checkdir+'/source.py','wb') as f:
source = ''.join(['# In[%i]\n%s\n\n' % (i, In[i]) for i in range(len(In))])
f.write(source.encode())12. Optimizer 설정
optimizer = SGD(learning_rate=0.0001, decay=1e-6, momentum=0.9, nesterov=True, clipnorm=5)optimizer로는 SGD(경사하강법)을 사용했다.
learning rate는 0.0001 로 지정했는데, 0.0001로 설정했을 때 성능이 가장 좋다고 알려져 있어 이 값으로 설정했다.
지금은 test 단계지만 본격적으로 학습을 시키면, learning rate를 0.01부터 0.0001까지 다양한 값으로 설정하고 그 중 best값을 선택할 계획이다.
13. 설정한 Layer의 가중치 동결
for layer in model.layers:
layer.trainable = not layer.name in freeze14. Compile Model
model.compile(loss={'ctc': lambda y_true, y_pred: y_pred}, optimizer=optimizer)15. Train Model
from keras.callbacks import ModelCheckpoint
hist = model.fit(gen_train.generate(), # batch_size here?
steps_per_epoch=gt_util_train.num_objects // batch_size,
epochs=1,
validation_data=gen_val.generate(), # batch_size here?
validation_steps=gt_util_val.num_objects // batch_size,
callbacks=[
ModelCheckpoint(checkdir+'/weights.{epoch:03d}.h5', verbose=1, save_weights_only=True),
Logger(checkdir),
],
initial_epoch=0)test가 목적이므로 epochs는 1로 설정했다.
실제 학습을 시킬 땐 50 ~ 100 사이의 값으로 설정시킬 예정이다.
16. 학습 결과
학습한 모델의 output을 확인해보기 위해 학습할 때 사용하지 않은 임대차계약서 이미지 하나를 input으로 넣었다.
이미지는 google에 '임대차계약서 예시'라고 검색했을 때, 가장 첫 번째로 나오는 이미지를 선택했다.
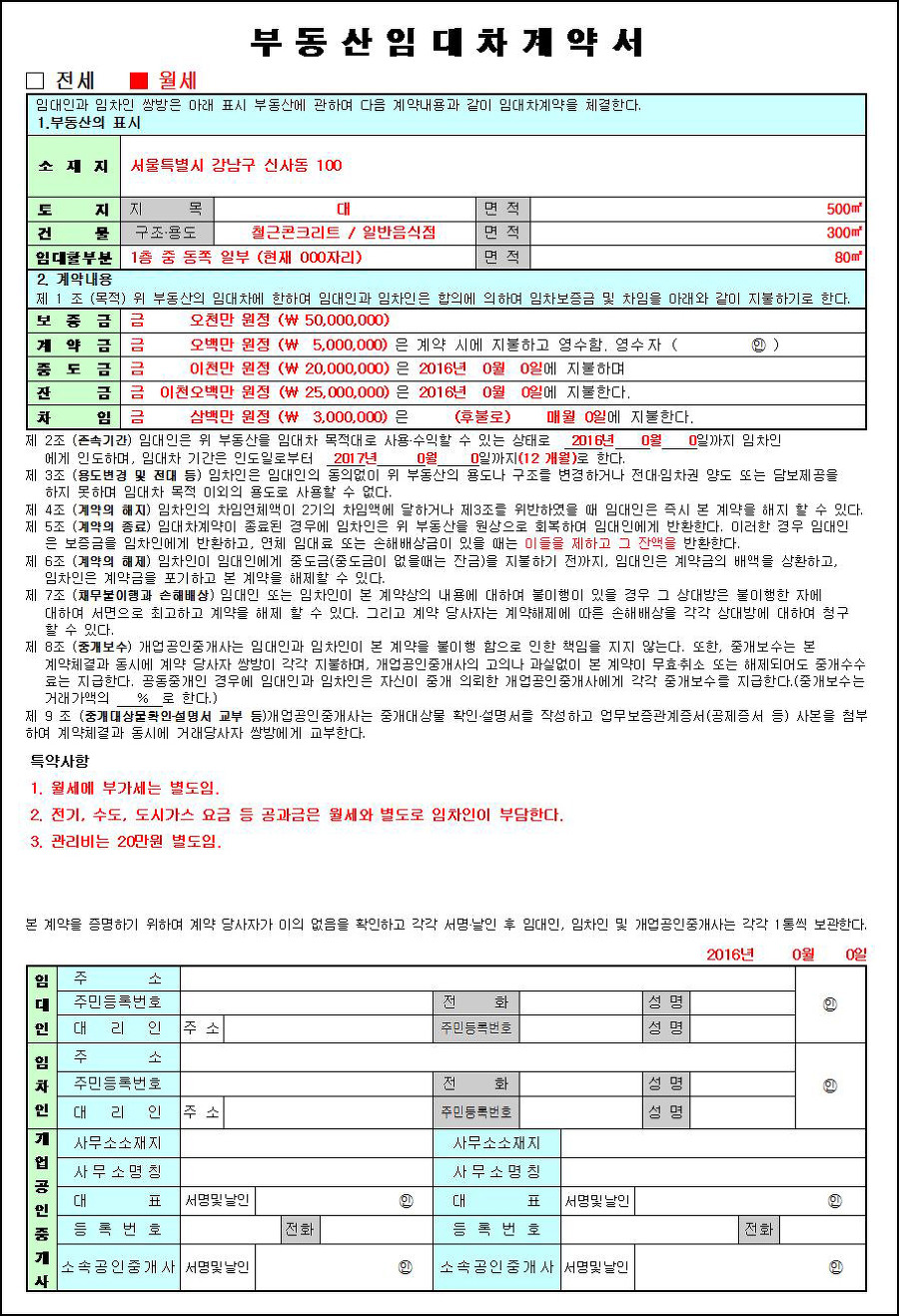
보다시피 계약서 이미지는 인식해야 할 글자가 굉장히 많다. 그래서 모든 글자를 정확하게 인식하도록 학습시키려면 굉장히 많은 시간과 비용이 든다.
학습 데이터도 '특약사항' 위주로 가공했듯이, 학습 결과도 '특약사항' 위주로 보면 다음과 같다.

결과만 보면 만족스러운 결과는 아니다.
'월세'를 '월서'로 인식하고, '임차인'을 '입치인'으로 인식하는 등 계약서에서 가장 핵심적인 키워드들의 인식 결과가 좋지 않다.
그러나 앞서 말했듯이, 이번 학습은 단지 test를 위한 용도이므로 epochs를 1로 설정해 결과가 좋지 않을 수밖에 없다. 오히려 학습을 한 번밖에 안 시켰는데 생각보다 결과가 좋아서 놀랐다.
그래서 데이터를 좀 더 생성하고, 라벨에 숫자 데이터도 추가해 데이터를 다듬고, epochs도 보다 높은 값으로 설정해 학습을 돌려볼 계획이다.
[출처]
https://soyoung-new-challenge.tistory.com/m/category/DeepLearning/OCR_
https://www.datamaker.io/posts/63/
https://github.com/mvoelk/ssd_detectors

잘 읽었어요~