후 시붕..
내가 정리하자고 시작한 노트 복습이지만....
시험 끝나고 2일동안 계속 타닥타닥거리고 있으니까 정신 나갈 것 같다 ㄹㅇ
얼른 끝내고 놀아...공부해야지...
이제 데이터 모델과 성능을 볼 차례인데, 여기서 정규화랑 반정규화가 나온다.
반정규화는 SQLD 시험에서 빠졌지만, 실무에선 상당히 중요한 것 같다.
실무에서 정규화를 완벽하게 수행하는 것은 거의 불가능에 가깝다고 하더라.
와 오늘 아침부터 퇴근 전까지 앉아 있던 적이 없다 ㄹㅇ
퇴근하고 바로 기절했다가 이제야 글을 쓴다...
성능 데이터 모델링
- 정규화
- 반정규화
- 테이블 통합 및 분할
- 조인 구조
- PK/FK 설정
와 중요한 것들 밖에 없네요 개같은거
성능 데이터 모델링 진행 순서
(순서를 외우진 않았지만, 실무에서 참고되지 않을까 싶어서 메모)
- 정규화를 정확하게 수행
- 주요 관심사별로 테이블을 분산시킴 - 데이터베이스 용량산정 수행
- 각 엔터티에 어느 정도의 트랜잭션이 들어오는지 파악 - 데이터베이스에 발생되는 트랜잭션의 유형 파악
- CRUD 매트릭스 활용 - 용량과 트랜잭션의 유형에 따라 반정규화 수행
- 테이블, 속성, 관계 변경 - 이력모델의 조정, 인덱스를 고려한 PK/FK의 순서 조정, 슈퍼타입/ 서브타입 조정 등 수행
- 성능 관점에서 데이터 모델 최종 검증
Relational Model Constraints
- 도메인 제약
- 키 제약
릴레이션의 모든 튜플은 서로 식별 가능해야 함 - 개체 무결성 제약
기본키는 (NOT NULL & UNIQUE)이어야 함 - 참조 무결성 제약
정규화는 왜 하는가?
삽입/삭제/갱신 이상현상 방지
3NF 이상의 정규화는 잘 없다고 교수님께서 말씀하셨다.
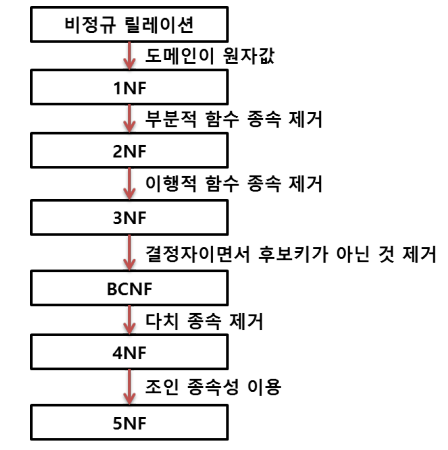
1차 정규형은 도메인이 원자값을 만족하고,
2차 정규형은 부분적 함수 종속성이 없고,
3차 정규형은 이행적 함수 종속성이 없다는 것이 정규화의 기본이다.
그래서 정규화하면 뭐가 좋은데
정규화를 수행하면
1. 데이터 중복 감소 -> 성능 향상
2. 데이터가 관심사별로 묶임 -> 성능 향상
3. 조회 질의에서 조인이 많이 발생 -> 성능 저?하 향?상
4. 정규화를 통해 일반적으로 성능이 향상되나, 조회의 경우 처리 조건에 따라 성능이 향상되거나 저하됨
정규화 하니까 성능 떨어졌는데 이거 어캄
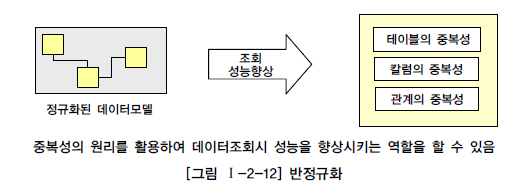
그렇다면 반정규화를 해보자.
정규화된 엔터티,속성,관계에 대해 성능 향상을 목적으로 중복, 통합, 분리를 수행하는 데이터 모델링 기법이다.
- 칼럼 반정규화
- 중복 칼럼 추가- 파생 칼럼 추가
- 데이블 반정규화
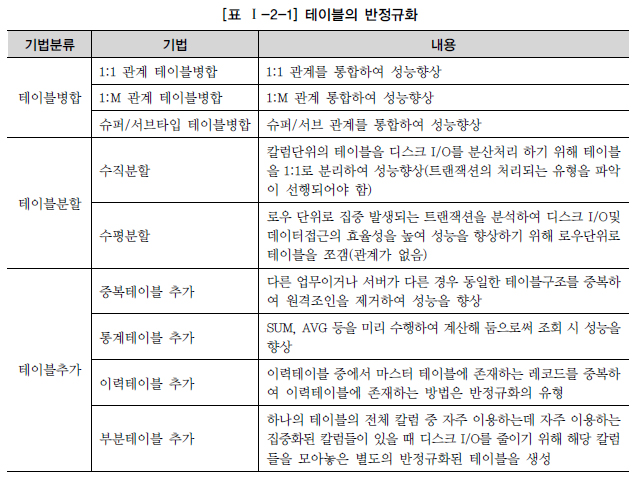
- 테이블 병합: 관계 병함, 슈퍼/서브타입 병합- 테이블 분할: 수직 분할, 수평 분할
- 관계 반정규화